baiyan
全部视频:https://segmentfault.com/a/11...
源视频地址:http://replay.xesv5.com/ll/24...
引入及基本概念
- 变量本质上就是给一段内存空间起了个名字
- 如果让我们自己基于C语言设计一个存储如$a = 1变量的数据结构,应该如何设计?
- 变量的基本要素是类型与值,其中部分类型还有其他的描述字段(如长度等)
- 首先应该定义一个结构体作为基本的数据结构
- 第一个问题:变量类型如何存储? 答:用一个unsigned char类型的字段存足够,因为unsigned char类型最多能够表示2^8 = 256种类型。
- PHP7中以zval表示所有的变量,它是一个结构体。先看zval的基本结构:
typedef unsigned char zend_uchar;
struct _zval_struct {
zend_value value; /* 存储变量的zhi*/
union {
struct {
ZEND_ENDIAN_LOHI_4( //大小端问题,详情看"PHP内存管理3笔记”
zend_uchar type, //注意这里就是存放变量类型的地方,char类型
zend_uchar type_flags, //类型标记
zend_uchar const_flags, //是否是常量
zend_uchar reserved) //保留字段
} v;
uint32_t type_info;
} u1;
union {
uint32_t next; /* 数组模拟链表,在下文链地址法解决哈希冲突时使用 */
uint32_t cache_slot; /* literal cache slot */
uint32_t lineno; /* line number (for ast nodes) */
uint32_t num_args; /* arguments number for EX(This) */
uint32_t fe_pos; /* foreach position */
uint32_t fe_iter_idx; /* foreach iterator index */
uint32_t access_flags; /* class constant access flags */
uint32_t property_guard; /* single property guard */
uint32_t extra; /* not further specified */
} u2;
};- 注意关注中文注释的部分,PHP就是利用C语言的unsigned char类型,存储了所有变量的类型。
- 在PHP中,所有变量的类型如下:
/* regular data types */
#define IS_UNDEF 0
#define IS_NULL 1
#define IS_FALSE 2
#define IS_TRUE 3
#define IS_LONG 4
#define IS_DOUBLE 5
#define IS_STRING 6
#define IS_ARRAY 7
#define IS_OBJECT 8
#define IS_RESOURCE 9
#define IS_REFERENCE 10
/* constant expressions */
#define IS_CONSTANT 11
#define IS_CONSTANT_AST 12
/* fake types */
#define _IS_BOOL 13
#define IS_CALLABLE 14
#define IS_ITERABLE 19
#define IS_VOID 18
/* internal types */
#define IS_INDIRECT 15
#define IS_PTR 17
#define _IS_ERROR 20- 第二个问题:变量的值如何存储? 答:如果是a是1用int;如果是1.1,用double;是'1'用char *等等,但是变量的值的类型只有1种,不可能同时用到多种类型去存值,故我们可以把这一大堆东西放到1个union里面即可,源码中存储变量类型的联合体叫做zend_value:
typedef union _zend_value {
zend_long lval; //存整型值
double dval; //存浮点值
zend_refcounted *counted; //存引用计数值
zend_string *str; //存字符串值
zend_array *arr; //存数组值
zend_object *obj; //存对象值
zend_resource *res; //存资源值
zend_reference *ref; //存引用值
zend_ast_ref *ast; //存抽象语法树
zval *zv; //内部使用
void *ptr; //不确定类型,取出来之后强转
zend_class_entry *ce; //存类
zend_function *func;//存函数
struct {
uint32_t w1;
uint32_t w2;
} ww; //这个union一共8B,这个结构体每个字段都是4B,因为所有联合体字段共用一块内存,故相当于取了一半的union
} zend_value;- 由于某些类型的变量需要额外的一些描述信息(如字符串、数组),其复杂度更高,为了节省空间,就只在zend_value结构体中存了一个结构体指针,其真正的值在zend_string、zend_array这些结构体中(下面会讲)。
- zend_value类型是一个联合体,共占用8B。因为变量只有一种类型,所以就可以利用联合体共用一块内存的特性,来存储变量的类型。注意最后一个结构体是一个小技巧,通过取ww结构体的其中一个字段,可以取到联合体变量高4位或者低4位,这样就不用手动编写多余代码去取了。
- 在PHP7中,zend_value占用8B,而u1占用4B,u2占用4B,经过内存对齐,一个zval占用16B,相较PHP5,占用的内存大幅减少。
利用gdb查看变量底层存储情况
- 示例代码:
- 首先在ZEND_ECHO_SPEC_CV_HANDLER打一个断点。在PHP虚拟机中,一条指令对应一个handler,这里对应的就是echo的语法。首先我们执行到了$a = 1处,打印这个z变量的值,可以看到lval = 1,它就是用来存放$a的值的。然后再关注联合体u1中的type字段的值为4,对照上文类型对照表,正好对应IS_LONG类型。记录下它的地址0x7ffff381c080,下文将要使用。
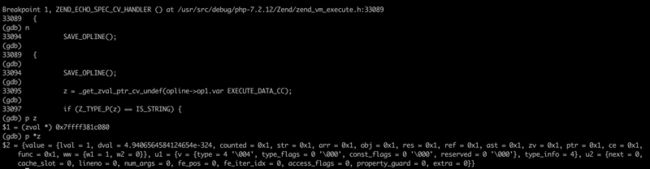
- 用c命令回到PHP代码继续执行到$b = 1.1处,打印zval的情况:

- 可以看到double类型的值被存放到了dval变量中,这里存在精度问题(不展开),且u1的type是5,对应IS_DOUBLE类型。这里的地址是0x7ffff381c090,正好与上一个$a的地址0x7ffff381c080相差16B,即一个zval的大小,验证了zval是16B的结论。
- 使用c命令继续往下执行,到了$c = "hello“处:

- 可以看到这个zval中u1中type字段为6,即IS_STRING类型。遇到字符串类型会取value中的str字段,它是一个zend_string类型(专门用来存字符串,下面会讲)的结构体指针。
首先思考一个问题,如果让我们自己基于C语言设计一个zend_string,应该如何设计?
-
- 存放字符串值的字符数组
- 存放长度
- 这样好像差不多就够了,那么思考一个问题:如果想临时给字符串追加或减少应该如何处理,如让hello变成hello world?因为C语言中的字符数组是固定的空间大小,并不能自动扩容。那么如何高效地将字符数组扩容或缩小呢?那就要使用C语言结构体中的柔性数组了。
- 我们先来看一下zend_string类型的结构:
struct _zend_string {
zend_refcounted_h gc;
zend_ulong h; /* 冗余的hash值 */
size_t len;
char val[1];
};- gc字段表示引用计数,与引用计数和垃圾回收相关,它也是一个结构体类型,这里不展开。
- h字段表示字符串的哈希值,在数组的key中有用,方便快速定位。这里是以空间换时间的思想,将这个值记录下来,就不用每次用的时候都去计算字符串的哈希值,提升了性能。
- len字段表示字符串长度
- 这里char val[1] 就是一个柔性数组,在redis等源码中也被大量使用。它的大小是不确定的,必须放在结构体的尾部。它可以被当做一个占位符,是紧跟着结构体的一块连续内存空间。如果这里存的是一个char *的话,就会指向一块随机的内存,而并不是紧跟着结构体的连续内存。
- 继续c命令往下执行,到了$d = [1,2,3];处。我们可以看到u1.v.type的值是7,即IS_ARRAY类型,接下来查看arr字段的内容:

PHP数组源码分析展开
- 我们具体看一下这个数组的结构:
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
uint32_t nTableMask;
Bucket *arData; //实际存储数组元素的bucket
uint32_t nNumUsed;
uint32_t nNumOfElements;
uint32_t nTableSize;
uint32_t nInternalPointer;
zend_long nNextFreeElement;
dtor_func_t pDestructor;
};
typedef struct _zend_array HashTable;- 这是数组的基本数据结构,其中包括一些描述数组大小以及用于遍历的指针等,它的别名又叫HashTable。
- 我们主要关注*arData字段,我们往数组中插入的数据就放在bucket中,每一个bucket中存了一个key-value对,还有一个冗余的哈希值:
typedef struct _Bucket {
zval val; //元素的值
zend_ulong h; //冗余的哈希值
zend_string *key; //元素的key
} Bucket;- 要想将任意key值)(如字符串)映射到一段固定长度大小的数组空间中,那么最适合的就是哈希算法(PHP中用的是time33算法),但是它不能正好映射到数组大小范围之内,且存在哈希冲突问题。
- 在PHP中,其实在实际存储数据的bucket前面,额外申请了一部分内存,就是用来解决上述问题。
- 我们将第一步由time33哈希算法求出来的h值,将其与nTableMask(也就是数组的size - 1)做或运算得到bucket的索引下标,这样可以保证最终的索引下标在[-n, -1]范围之内,这里称之为slot,它的具体计算公式为:
nIndex = h | nTableMask- 相同hash值计算出来的nIndex(即slot)的值是相同的。
-
然后在slot的对应空间内存上第一个bucket对应的索引下标,然后将元素存入对应索引下标的bucket数组中。查找过程也是类似的(下面会细讲),它们都是O(1)的时间复杂度,但是这样就会出现哈希冲突,解决哈希冲突通常有两种算法:
- 开放定址法
- 链地址法
-
比较常用的是链地址法,但如果同一个hash值上的链表过长,会把同一个hash值上的所有链表节点都遍历一遍,时间复杂度会退化为O(n)。PHP5中有一个漏洞,攻击者不断让你的链表变长,使得数组查询变慢,不断消耗服务器性能,最终QPS会下降的非常之快。要解决链地址法的哈希冲突所带来的性能下降问题,有如下思路:
- 扩容,重新进行哈希运算(rehash)
- 将链表换成红黑树/跳表...(O(1)退化成O(logn))问题的本质是链表的效率较低,故用其他数据结构代替链表
- PHP7中的链表是一种逻辑上的链表。每一个bucket维护下一个bucket在数组中的索引,而不通过指针维护上下游关系。上文提到的在bucket之前额外申请的内存在这个地方亦要派上用场了。由于相同hash值经过或运算得到的slot值也是相同的,其slot中的值就指向第一个bucket,然后第一个bucket中的val字段中的u2联合体中的next字段(如arData[0].val.u2.next字段)又指向了下一个相同slot的bucket单元......最终实现了头插法版本的数组模拟链表。
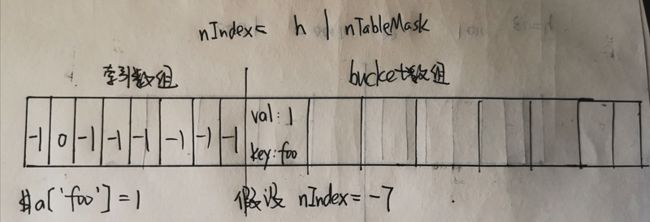
- 下面举一个PHP代码的例子来描述数组的插入与查找过程:
$a['foo'] = 1;
$a[] = 2;
$a['s'] = 3;
$a['x'] = 4;-
这是一个非常简单的几个数组赋值语句,我们具体看一下它们的插入过程:
- $a['foo'] = 1;这里的key和value如果是字符串,需要单独在zend_string结构中存储其真实的值和长度,这里做了简化。
- $a[] = 2;
- $a['s'] = 3; 这里注意需要先修改索引数组,保证索引数组中第一个指向的bucket数组单元是最后插入bucket数组的值(头插法),并且修改val.u2.next指针(因为所有val都是zval类型),指向上一个具有相同hash值的元素。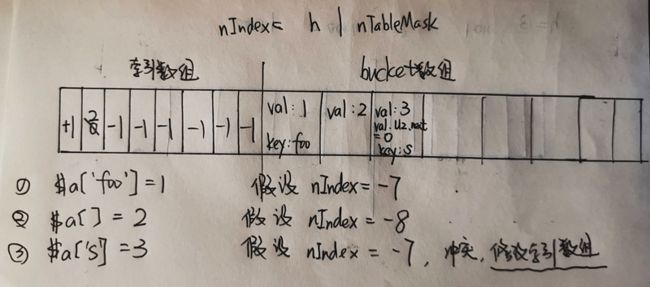
- $a['x'] = 4;同上
-
再来看一个数组查询过程,例如访问$a['s']的值:
- 经过time33哈希算法算出哈希值h
- 计算出索引数组的nIndex = h | nTableMask = -7(假设)
- 访问索引数组,取出索引为-7位置上的元素值为3
- 访问bucket数组,取出索引为3位置上的key,为x,发现并不等于s,那么继续查找,访问val.u2.next指针,为2
- 取出索引为2位置上的key,为s,发现正好是我们要找的那个key
- 取出对应的val值3
下面我们再看一段PHP代码:
=0; $i--) {
$arr2[$i] = $i;
}- 思考:这两段代码占用的内存是否相同?
- 答:第一个for循环占用的内存更少。
-
那么为什么会这样呢?先看两个概念:packed array与hash array
-
packed array的特点:
- key是数字,且顺序递增
- 位置固定,如访问key是0的元素,即$arr1[0],就直接访问bucket数组的第0个位置即可(即arData[0])
- 因为可以直接访问,不需要使用前面额外的索引数组,PHP中只使用了2个数组单元并赋值为初始的-1
- 由此可见,第一个循环就是以packed array的形式存储的,由于不用索引数组,索引节省了200000 - 2 个内存单元
- 如果不满足上述条件,就是一个hash array
- 我们看第二个for循环,如果想访问key是200000的元素,若按照packed array的方法,直接访问bucket数组的第200000元素(即arData[200000]),就会得到错误的值0(因为$arr2[200000] = 200000),所以只能通过使用索引数组来间接访问元素
- 因为索引数组需要索引到bucket数组的所有位置,所以其大小等于bucket数组的大小,多使用了200000 - 2个内存单元,故占用的内存更多,所以在工作中,尽量使用packed array,来减少对服务器内存的使用量。
-
- 思考:如果一个packed array中间空出来许多元素,即:
$arr = [
0 => 0,
1 => 1,
2 => 2,
100000 => 3
];- 显然这样如果使用packed array会浪费许多bucket数组的空间,在这种情况下,可能用hash array的效率就会更高一些,在这里,PHP内核就需要做出权衡,经过比较之后,选择一种最优化的方案。