目录
1. 算法
1.1 各种容器的 iterators 的 iterator_category
1.2 iterator_category 对算法的影响
1.3 算法源代码剖析
2. 仿函数 functors
2.1 仿函数的使用方法
2.2 仿函数 functors 的可适配(adaptable)条件
3. Adapter(适配器)
3.1 ☆函数适配器:binder2nd
3.2 新型适配器,bind
3.3 迭代器适配器:revers_iterator
3.4 迭代器适配器:inserter
3.5 X适配器:ostream_iterator
3.6 X适配器:istream_iterator
1. 算法(Algorithm)

template
Algorithm(Iterator itr1, Iterator itr2)
{
...
}
template
Algorithm(Iterator itr1, Iterator itr2, Cmp comp)
{
...
}
一般情况算法都有两个版本,一个是两个参数的,一个是有三个参数的版本。前面两个参数是迭代器,用来让算法知道需要操作的对象的范围,第三个参数是算法遵循的准则,可以增加算法的弹性,满足用户的不同需求,比如:sort 函数,默认是从小到大排序,如果加上第三个参数(比如从大到小的准则),那么 sort 就会将数据按照指定的方式排序。
算法是看不见容器的,对其一无所知,一切信息都是从 iterator 那得到,iterator 就是算法和容器之间的桥梁。
1.1 各种容器的 iterators 的 iterator_category
STL 中有五种 iterator_category 分别是:

- struct input_iterator_tag {};
- struct output_iterator_tag {};
- struct forward_iterator_tag: public input_iterator_tag {};
- struct bidirectional_iterator_tag: public forward_iterator_tag {};
- struct random_access_iterator_tag: public bidirectional_iterator_tag {};
不同容器中迭代器的类型:
Array,Vector,Deque 这三种容器支持随机访问,是连续空间(deque模仿出连续的假象),使用的是 random_access_iterator_tag
list(双向链表)是序列式容器,set,map,multiset,multimap 是关联式容器,它们都不支持随机访问,使用的是 bidirectional_iterator_tag
forward_list(单向链表),unordered_set,unordered_map,unordered_multiset,unordered_multimap 都是单向连续性空间,不支持随机访问,使用的是 forward_iterator_tag
istream_iterator,ostream_iterator 分别使用的是 input_iterator_tag,output_inerator_tag
typeid(iter).name(),可以直接得到对象的类型名称
1.2 iterator_category 对算法的影响
1.2.1 distance 函数(求得一个容器头尾迭代器之间的距离)
template
inline iterator_traits::difference_type // 返回类型,编译通过时就知道了具体类型
distance(InputIterator first, InputIterator last)
{
typedef typename iterator_traits::iterator_category category;
return __distance(first, last, category()); // 对象加 `()` 就是临时对象,只为了区分类型,调用不同的算法
}
当传入 vector.begin() 和 vector.end() 函数,通过萃取机 iterator_traits 得到他的 iterator_category 类型:random_access_iterator,然后去调用:
template
inline iterator_traits::difference_type
__distance(RandomAccessIterator first, RandomAccessIterator last, random_access_iterator_tag)
{
return last - first;
}
因为连续空间的容器,所以直接首尾相减,就能得到距离,速度非常快。
当传入的是 list.begin() 和 list.end() 函数,通过萃取机 iterator_traits 得到它们的 iterator_category 类型:bidrectional_iterator,然后去调用:
template
inline iterator_traits::difference_type
__distance(InputIterator first, InputIterator last, input_iterator_tag)
{
iterator_traits::difference_type n = 0;
while(first != last)
{
++first;
++n;
}
return n;
}
因为是非连续空间容器,所以只能通过累加的方式,一个一个向后偏移得到距离,速度很慢。
问:只有两个版本的函数怎么办?
答:因为继承的特性(is a),forward_iterator 和 bidirectional_iterator
都会调用 input_iterator 版本的函数!
1.2.2 advance 函数(从指定迭代器开始前进指定长度)

1.2.3 copy 函数(复制指定头尾之间的内容并输出)

1.2.4 destroy 函数(销毁对象)
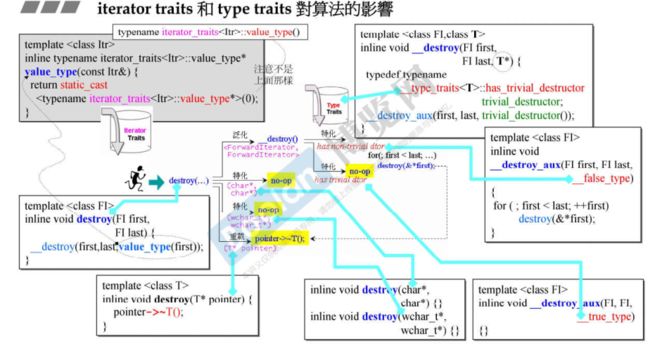
1.2.5 __unique_copy 函数应用于「输出迭代器」(output_iterator)

1.2.6 算法源码中对 iterator_category 的「暗示」

模板中模板类型参数写为有含义的字符串,方便理解与维护
1.3 算法源代码剖析

1.3.1 算法 accumulate(累计算)

1.3.2 算法 for_each(遍历每个元素,都进行同样的操作)

1.3.3 算法 replace,replace_if,replace_copy(值替换,条件替换,值替换到新区间)

1.3.4 算法 count,count_if(条件式计数)

1.3.5 算法 find,find_if(条件式查找)

1.3.6 算法 sort

1.3.7 逆向迭代器(reverse iterator)

1.3.8 算法 binary_search(调用 lower_bound)

2. 仿函数 functors
仿函数其实是一个类重载了 ( ) 运算符,它只为算法服务,主要类型有三种:

2.1 仿函数的使用方法

less
2.2 仿函数 functors 的可适配(adaptable)条件

STL规定每一个 Adaptable Function 都要挑选适当的基类来继承,因为Function Adapter 将会提问问题,例如:
template
class binder2nd: public unary_function
{
protected: Operation op;
// 这里就是function adapter在问问题
typename Operation::second_argument_type value;
public:
// ....
};
typename Operation::second_argument_type value;
这一句就是在问仿函数问题,你的第二个参数类型是什么,如果这一句可以编译通过,那么函数适配器就得到了仿函数的第二个参数类型,仿函数就可以被改造。
一个仿函数想要能被 STL 中的适配器改造,就需要继承适当的类融入
STL。
3. Adapter(适配器)

STL 的算法可以让用户提供第三参数,用于给用户自定义算法处理数据的方式,上面讲述了可以使用仿函数作为第三参数,仿函数可以被适配器改造,下面就来看一下适配器是如何改造仿函数的。
之前学过的 stack 和 queue 从实现角度上来说其实就是两种容器适配器:

接口变少也算改造(把内含的容器换一个风貌)
3.1 ☆函数适配器:binder2nd
以在 count_if 函数中第三参数应用 binder2nd 改变判断条件为例来说明函数适配器的工作原理:

适配器:把该记的东西先记起来,待日后要用时再取用。
能回答这 3 个问题,才说明是 adaptable:
- first_argument_type
- second_argument_type
- result_type
在 bind2nd 中返回的是一个 binder2nd 类型的临时对象,bind2nd 函数其实是一个中间层,因为 binder2nd 类模板不可以自动推导类型参数,只有模板函数可以,所以使用中间层给类模板指定模板参数 Operation 。
当在 count_if 中传入第三参数 bind2nd(less
bind2nd 函数,函数确定 Operation 和 T 的类型函数变成如下:
template
inline binder2nd> bind2nd(const less& op, const int& x)
{
typedef less::second_argument_type arg2_type;
return binder2nd>(op, arg2_type(x));
}
然后先让 class binder2nd 确定模板参数
template
class binder2nd
: public unary_function::fist_argument_type, less::result_type>
{
protected:
less op;
less::second_argument_type value;
public:
binder2nd(const less& x, const less::second_argument_type& y)
:op(x), value(y)
{ }
less::result_type operator () (const less::first_argument_type& x) const
{
return op(x, value);
}
}
再在函数内部调用 class binder2nd 的构造函数,实例化一个 binder2nd
类型的临时对象,将 less
最后 count_if 的第三个参数就得到一个 binder2nd 类型的临时对象,其中包涵了 less
template
typename iterator_traits::difference_type
count_if(InputIterator first, InputIterator last, Predicate pred)
{
// 以下定义一个初值为 0 的计数器
typename iterator_traits::difference_type n = 0;
for(; first != last; ++first) // 遍历
{
if(pred(*first)) // 如果元素代入 pred 的结果为 true,计数器累加1
{
++n;
}
} return n;
}
在 count_if 中调用 pred 这个仿函数时(pred 就是 binder2nd 类型的临时对象的别名),会触发 class binder2nd 中的 operator( ),在 operator( ) 中 op(x, 40); 里的 40 就被绑定到 less
3.2 新型适配器,bind
尽量使用新版设计来替代老版内容:


_表示占位符,它和 bind 的奇妙结合过于复杂高深,就不展开讲解了。
cbegin( ) 表示 const,不可改变的头部迭代器
3.3 迭代器适配器:reverse_iterator

3.4 迭代器适配器:inserter
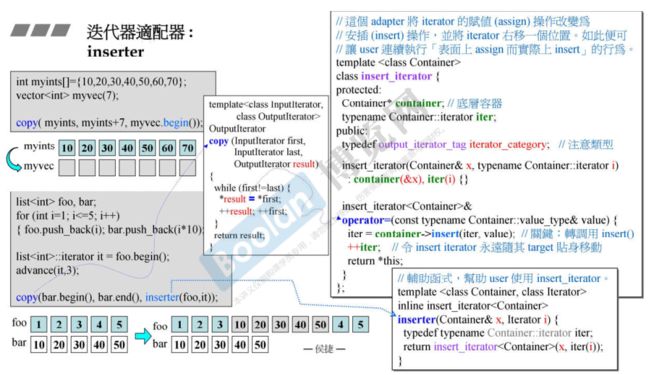
当我们想用copy函数进行容器间的拷贝动作时,一种是提前将空间预留
int myints[] = {10, 20, 30, 40, 50, 60, 70};
vector myvec(7);
copy(myints, myints+7, myvec.begin());
提前预留空间是因为 copy 函数只是单纯的移动迭代器,向迭代器所指的地方插入数据,源码如下:
template
OutputIterator copy(InputIterator first, InputIterator last, OutputIterator result)
{
while(first != last)
{
result = *first;
++result;
++first;
}
return result;
}
假设我们的容器其中本来就有数据,没有预留空间,那么直接使用 copy 函数会造成一颗定时炸弹(越界访问),在这种时候就需要使用适配器来改造拷贝动作。
将 copy 的第三参数改写成迭代适配器:
copy(myints, myints+7, inserter(myvec, iter)); //iter为迭代器,指向容器内任意地方
inserter 源码如下:
template
inline insert_iterator
insert(Container& x, Iterator i)
{
typedef typename Container::iterator iter;
return insert_iterator(x, iter(i));
}
inserter 与 bind2nd 一样,也是一个辅助函数,帮助 class insert_iterator确定模板参数。
class insert_iterator 源码如下:
template
class insert_iterator
{
protected:
Container* container;
typename Container::iterator iter;
public:
typedef output_iterator_tag iterator_category;
insert_iterator(Container& x, typename Container::iterator i)
:container(&x), iter(i)
{ }
insert_iterator&
operator = (const typename Container::value_type& value)
{
iter = container->insert(iter, value);
return *this;
}
typename Container::iterator& operator ++ ()
{
return ++iter;
}
};
inserter 函数返回一个 insert_iterator 类型的临时对象,在这个临时对象中,容器 myvec 被记录到了容器指针 container 中,myvec 的迭代器 iter
被记录到了临时对象中的的 iter 里,当 copy 函数在执行:
result = *first;
++result;
以上两个操作的时候,会触发 class insert_iterator 里的两个操作符重载函数。
这样 copy 函数从原来一个傻傻的,只会一个一个拷贝的底层函数,摇身一变成了一个智能的插入拷贝函数(C++技术相当奇妙,这就是操作符重载的好处)。
3.5 X 适配器:ostream_iterator
标准库定义有提供给输入输出使用的 iostream iterator,称为istream_iterator 和 ostream_iterator,他们分别支持单个元素的读取和写入。它们不属于上述三种适配器分类中的任何一种,暂命名为 X(未知的,不确定的)。

3.6 X适配器:istream_iterator


// 定义一个指向输入流结束位置的迭代器
istream_iterator eos;
// 定义一个指向标准输入的迭代器
istream_iterator iit(cin)
当 iit = eos 时,说明流中的数据已经全部读取结束,操作 iit 让其加一,可以让迭代器指向下一个流中的数据
#include
#include
using namespace std;
int main()
{
double value1, value2;
cout << "please insert two value: ";
istream_iterator eos;
istream_iterator iit(cin);
if(iit != eos)
{
value1 = *iit;
}
++iit;
if(iit != eos)
{
value2 = *iit;
}
cout << value1 << ' ' << value2 << endl;
return 0;
}
- 这里值得注意的是,当我们把
cout << "please insert two value: ";写到istream_iterator后面,在执行程序的时候,我们发现,当输入第一个数字之后,cout 这句输出才会被打印出来,造成这样的原因是,当定义了 iit 之后,其构造函数已经对 iit 加一,读取已经开始,所以 cout 的输出被放在后面。iit(cin); - 通过适配器、操作符重载等,能让已经「写死」的 copy 函数实现完全不一样的功能,太奇妙!