学习BeetlSQL总结(2)
经过上节的学习,我们已经了解了BeetlSQL的基础,接下来我们深入的学习BeetlSQL
一.BeetlSQL说明
1.获得SQLManager是系统的核心,它提供了所有的dao方法,获得SQLManager,可以直接构造SQLManager,并通过单例获取
ConnectionSource source = ConnectionSourceHelper.getSimple(mysqlDriver, url, userName, password);
DBStyle mysql = new MySqlStyle();
// SQL语句放于classpath的sql目录下
SQLLoader loader = new ClasspathLoader("/sql");
// 数据库命名和java命名一样,所以采用DefaultNameConversion,还有一个UnderlinedNameConversion下划线风格的
UnderlinedNameConversion nc = new UnderlinedNameConversion();
// 最后,创建一个SQLManager,DebugInterceptor,不是必须的,但可以通过它查看SQL的执行情况
SQLManager sqlManager = new SQLManager(mysql, loader, source, nc, new Interceptor[] { new DebugInterceptor() });如果已经有了Datasource,创建ConnectionSource可以采用如下代码:
ConnectionSource source = ConnectionSourceHelper.getSingle(datasource);如果是主从Datasource:
ConnectionSource source = ConnectionSourceHelper.getMasterSlave(master,slaves)2.查询API
(1)简单查询(自动生成sql)
·public T unique(Class clazz,Object pk)根据主键查询,如果未找到,抛出异常
·public T single(Class clazz,Object pk)根据主键查询,如果没找到,返回null
·public List all(Class clazz)查询所有结果集
·public List all(Class clazz,int start,int size)翻页
·public int allCount(Class clazz)总数
(2)单表查询
SQLManager提供了Query类可以实现单表查询操作
//7.单表查询
System.out.println("开始执行单表查询");
List list =
sqlManager.query(User.class).andEq("name","曼斯坦因").orderBy("create_date").select();
System.out.println("打印查询结果:");
for(User user1:list) {
System.out.println(user1);
} 其中sql.query(User.class)返回了Query类用于单表查询
执行结果: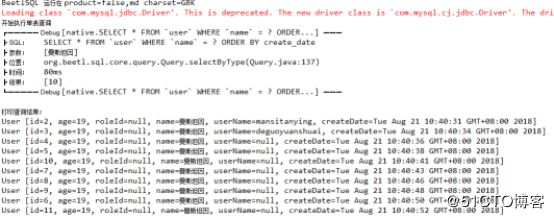
如果是java8,则可以使用lamdba表示列名
List list1 = sql.lambdaQuery(User.class).andEq(User::getName, "hi").orderBy(User::getCreateDate).select(); (3)template查询
·public T template(T t)根据模板查询返回所有符合这个模板的数据库,同上,mapper可以提供额外的映射,如处理一对一,一对多
·public T templateOne(T t)根据模板查询,返回一条结果,如果没有找到,返回null
·public List template(T t,int start,int size)同上,可以翻页
·public long templateCount(T t)获取符合条件的个数
·public List template(Class target,Object paras,long start,long size)模板查询,参数是paras,可以是Map或者普通对象
·public long templateCount(Class target,Object paras)获取符合条件的个数
翻页的start,系统默认从一开始,为了兼容各个系统的数据库,会自动翻译为数据库习俗,比如start为1,会认为mysql,postgres从0开始(从start-1开始),oracle,sqlserver,db2从1开始(start-0)开始
然而,如果你只用特定的数据库,可以按照特定的数据库习俗来,比如你只用mysql,satrt为0代表起始记录,需要配置
OFFSET_START_ZERO = true这样翻页参数传入0即可
注意:template查询方法根据模板查询不包含时间段查询,也不包含排序,然而,可以通过pojo class上使用@Table Template()或者日期字段的getter方法上使用@DataTemplate(来定制),如下:
用户登录验证:
//8.使用template方法查询
User template=new User();
template.setUserName("zhukefu");
template.setPassword("123456");
template.setStatus(1);执行结果:
User user2=sqlManager.templateOne(template);
System.out.println("打印template查询结果:"+user2);执行结果:
(4)通过sqlid查询,sql语句在md文件中
·public List select(String sqlId,Class clazz,Map
·public List select(String sqlId,Class clazz,Object paras)根据sqlId来查询,参数是个pojo
·public List select(String sqlId,Class clazz)根据sqlId来查询,无参数
·public T selectDSingle(String sqlId,Object paras,Class target)根据sqlid查询,输入的是pojo,将对应的唯一值映射成target对象,如果未找到则返回空,需要注意的是有时候需要的结果集本身为空,这时候建议使用unique
·public T selectDSingle(String sqlId,Map
·public T selectUnipue(String sqlId,Object paras,Class target)根据sqlid查询,输入的是map或者pojo,将对应的唯一值映射成target对象,如果未找到则抛出异常
·public T selectUnipue(String sqlId,Map
· public Interger intValue(String id,Object paras)查询结果映射为Interger,如果找不到,返回null,输入object
·public Interger intValue(String id,Map paras)查询结果映射为Interger,如果找不到,返回null,输入map,其他还有longValue,bigDecimalValue
注意:对于Map来说,有一个特殊的key叫着_root,代表了查询根对象,sql语句中未能找到的变量都会试图从_root中查找
(5)指定范围查询
·public List select(String sqlId,Class clazz,Map
·public List select(String sqlId,Class clazz,Object paras,int start,int size)查询指定范围
注意:
Beetlsql默认从1开始,自动翻译为目标数据库的起始行,如mysql的0,oracle的1,如果你想从0开始,需要配置beetlsql
例:(sql使用的是3.翻页查询中的sql语句)
// 9.使用sqlid查询
List list1 = sqlManager.select("user.queryUser", User.class);
for (User user3 : list1) {
System.out.println(user3);
} 查询结果:
3.翻页查询API
public void pageQuery(String sqlId,Class clazz,PageQuery query) BeetlSQL提供了一个pageQuery对象,用于web应用的翻页查询,BeetSQL假定有sqlId和sqlId$count,两个sqlid,并用这个来翻页和查询结果的总数:如
Sql代码:
queryUser
====
select * from user order by id desc
queryCountUser
====
select count(1) from user查询代码:
// 10.翻页查询
PageQuery query1 = new PageQuery();
sqlManager.pageQuery("user.queryCountUser", User.class, query1);
System.out.println(query1.getTotalPage());
System.out.println(query1.getTotalRow());
System.out.println(query1.getPageNumber()); 结果:

4.更新API
(1)自动生成sql
·public void insert(Object paras)插入paras到paras关联的表
· public void insert(Object paras,boolean autoAssignKey)插入paras对象到paras对象关联的表,并且指定是否自动将数据库主键赋值到paras里,适用于对于自增或者序列类数据库产生的主键
·public void insertTemplate(Object paras)插入paras到paras关联的表,忽略null值或者为空值的属性
·public void insertTemplate(Object paras,boolean autoAssignKey)插入paras到paras关联的表,并且指定是否自动将数据库主键赋值到paras里,忽略null值或者为空值的属性,适用于对主键自增的数据库产生的主键
·public void insert(Class clazz,Object paras) 插入paras到clazz关联的表
·public void insert(Class clazz,Object paras,KeyHolder holder)插入paras到clazz关联的表
,如果需要主键,则调用KeyHolder方法来获取主键,调用此方法主键必须自增
·public int insert((Class clazz,Object paras,boolean autoAssignKey)插入paras到clazz关联的表,并且指定是否自动将数据库主键赋值到paras里,调用此方法主键必须自增
·public int updateById(Object obj)根据主键更新,所有值参与更新
·public int updateTemplate(Object obj)根据主键更新,属性为null不会更新
·public int updateBatchTemplateById(Class clazz,List list)批量根据主键更新,属性为null的不会更新
·public int updateTemplateById(Class clazz,Map paras)根据主键更新,组件通过clazz的annottion表示,如果没有,则认为属性Id是主键,属性为null的不会更新
·public int[] updateByIdBatch(List list)批量更新
·public void insertBatch(Class clazz,List list)批量插入数据
(2)根据sqlId更新(删除)
·public int insert(String sqlId,Object paras,KeyHolder holder)根据sqlId插入,并返回主键,主键id由对象所指定,调用此方法,对应的数据库表必须自增主键
·public int insert(String sqlId,Object paras,KeyHolder holder,String keyName)同上,主键由keyName指定
·public int insert(Strint sqlId,Map paras,KeyHolder holder,String keyName)同上,参数通过map提供
·public int update(String sqlId,Object obj)根据sqlid更新
·public int update(String sql Id,Map
·public int[] updateBatch(Stirng sqlId,List list)批量更新
·public int updateBatch(String sqlId,Map
5.直接执行SQl模板
(1)直接执行sql模板语句
·public List execute(String sql,Classs clazz,Object paras)
·public List execute(String sql,Class clazz,Map paras)
·public int executeUpdate(String sql,Object paras)返回成功执行条数
·public int executeUpdate(String sql,Map paras)返回成功执行条数
(2)直接执行JDBC的sql语句
·查询public List execute(SQLReady p,Classs clazz)SQLReady包含了需要执行的sql语句和参数,clazz是查询结果,如:
//11. 直接执行sql语句
List list4 = sqlManager.execute(
new SQLReady("select * from user where username=? and password=?","zhukefu", "123456"),
User.class);
System.out.println("打印list:"+list4);
执行结果:

·public PageQuery execute(SQLReady p,Class clazz,PageQuery pageQuery)
例:
//12.直接执行sql语句分页查询
PageQuery query3=new PageQuery(1,8);
String jdbcSql="select * from user order by id";
sqlManager.execute(new SQLReady(jdbcSql), User.class, query3);
List list3=query3.getList();
for(User user3:list) {
System.out.println(user3);
} 执行结果: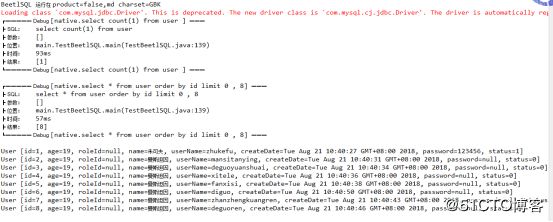
注意:参数通过SQLReady传递,而不是pageQuery
·更新public int executeUpdate(SQLReady p)SQLReady包含了需要执行的sql语句和参数,返回新的结果
·直接使用Connection public T executeOnConnection(OnConnection call)使用者需要实现onConnection方法的call方法,如调用存储过程
【本次总结完毕】