Structured Streaming 编程指南
概述
快速示例
Programming Model (编程模型)
基本概念
处理 Event-time 和延迟数据
容错语义
API 使用 Datasets 和 DataFrames
创建 streaming DataFrames 和 streaming Datasets
Input Sources (输入源)
streaming DataFrames/Datasets 的模式接口和分区
streaming DataFrames/Datasets 上的操作
基础操作 - Selection, Projection, Aggregation
Window Operations on Event Time (事件时间窗口操作)
处理 Late Data (迟到数据)和 Watermarking (水印)
Join 操作
Streaming Deduplication (Streaming 去重)
Arbitrary Stateful Operations (任意有状态的操作)
不支持的操作
开始 Streaming Queries
Output Modes (输出模式)
Output Sinks (输出接收器)
使用 Foreach
管理 Streaming Queries
监控 Streaming Queries
Interactive APIs
Asynchronous API
Recovering from Failures with Checkpointing (从检查点恢复故障)
从这里去哪儿
概述
Structured Streaming (结构化流)是一种基于 Spark SQL 引擎构建的可扩展且容错的 stream processing engine (流处理引擎)。您可以以静态数据表示批量计算的方式来表达 streaming computation (流式计算)。 Spark SQL 引擎将随着 streaming data 持续到达而增量地持续地运行,并更新最终结果。您可以使用 Scala , Java , Python 或 R 中的Dataset/DataFrame API来表示 streaming aggregations (流聚合), event-time windows (事件时间窗口), stream-to-batch joins (流到批处理连接) 等。在同一个 optimized Spark SQL engine (优化的 Spark SQL 引擎)上执行计算。最后,系统通过 checkpointing (检查点) 和 Write Ahead Logs (预写日志)来确保 end-to-end exactly-once (端到端的完全一次性) 容错保证。简而言之,Structured Streaming 提供快速,可扩展,容错,end-to-end exactly-once stream processing (端到端的完全一次性流处理),而无需用户理解 streaming 。
在本指南中,我们将向您介绍 programming model (编程模型) 和 APIs 。首先,我们从一个简单的例子开始 - 一个 streaming word count 。
快速示例
假设您想要保持从监听 TCP socket 的 data server (数据服务器) 接收的 text data (文本数据)的运行的 word count 。 让我们看看如何使用 Structured Streaming 表达这一点。你可以在Scala/Java/Python/R之中看到完整的代码。 Let’s say you want to maintain a running word count of text data received from a data server listening on a TCP socket. Let’s see how you can express this using Structured Streaming. You can see the full code inScala/Java/Python/R。 并且如果您下载 Spark,您可以直接运行这个例子。在任何情况下,让我们逐步了解示例并了解它的工作原理。首先,我们必须导入必要的 classes 并创建一个本地的 SparkSession ,这是与 Spark 相关的所有功能的起点。
Scala
Java
Python
R
importorg.apache.spark.sql.functions._importorg.apache.spark.sql.SparkSessionvalspark=SparkSession.builder.appName("StructuredNetworkWordCount").getOrCreate()importspark.implicits._
接下来,我们创建一个 streaming DataFrame ,它表示从监听 localhost:9999 的服务器上接收的 text data (文本数据),并且将 DataFrame 转换以计算 word counts 。
Scala
Java
Python
R
// 创建表示从连接到 localhost:9999 的输入行 stream 的 DataFramevallines=spark.readStream.format("socket").option("host","localhost").option("port",9999).load()// 将 lines 切分为 wordsvalwords=lines.as[String].flatMap(_.split(" "))// 生成正在运行的 word countvalwordCounts=words.groupBy("value").count()
这个linesDataFrame 表示一个包含包含 streaming text data (流文本数据) 的无边界表。此表包含了一列名为 “value” 的 strings ,并且 streaming text data 中的每一 line (行)都将成为表中的一 row (行)。请注意,这并不是正在接收的任何数据,因为我们只是设置 transformation (转换),还没有开始。接下来,我们使用.as[String]将 DataFrame 转换为 String 的 Dataset ,以便我们可以应用flatMap操作将每 line (行)切分成多个 words 。所得到的wordsDataset 包含所有的 words 。最后,我们通过将 Dataset 中 unique values (唯一的值)进行分组并对它们进行计数来定义wordCountsDataFrame 。请注意,这是一个 streaming DataFrame ,它表示 stream 的正在运行的 word counts 。
我们现在已经设置了关于 streaming data (流数据)的 query (查询)。剩下的就是实际开始接收数据并计算 counts (计数)。为此,我们将其设置为在每次更新时将完整地计数(由outputMode("complete")指定)发送到控制台。然后使用start()启动 streaming computation (流式计算)。
Scala
Java
Python
R
// 开始运行将 running counts 打印到控制台的查询valquery=wordCounts.writeStream.outputMode("complete").format("console").start()query.awaitTermination()
执行此代码之后, streaming computation (流式计算) 将在后台启动。query对象是该 active streaming query (活动流查询)的 handle (句柄),并且我们决定使用awaitTermination()来等待查询的终止,以防止查询处于 active (活动)状态时退出。
要实际执行此示例代码,您可以在您自己的Spark 应用程序编译代码,或者简单地运行示例一旦您下载了 Spark 。我们正在展示的是后者。您将首先需要运行 Netcat (大多数类 Unix 系统中的一个小型应用程序)作为 data server 通过使用
$ nc -lk 9999
然后,在一个不同的终端,您可以启动示例通过使用
Scala
Java
Python
R
$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost9999
然后,在运行 netcat 服务器的终端中输入的任何 lines 将每秒计数并打印在屏幕上。它看起来像下面这样。
# 终端 1:# 运行 Netcat$ nc -lk9999apache sparkapache hadoop...
Scala
Java
Python
R
# 终端 2: 运行 StructuredNetworkWordCount$ ./bin/run-example org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount localhost9999-------------------------------------------Batch:0-------------------------------------------+------+-----+|value|count|+------+-----+|apache|1||spark|1|+------+-----+-------------------------------------------Batch:1-------------------------------------------+------+-----+|value|count|+------+-----+|apache|2||spark|1||hadoop|1|+------+-----+...
Programming Model (编程模型)
Structured Streaming 的关键思想是将 live data stream (实时数据流)视为一种正在不断 appended (附加)的表。这形成了一个与 batch processing model (批处理模型)非常相似的新的 stream processing model (流处理模型)。您会将您的 streaming computation (流式计算)表示为在一个静态表上的 standard batch-like query (标准类批次查询),并且 Spark 在unbounded(无界)输入表上运行它作为incremental(增量)查询。让我们更加详细地了解这个模型。
基本概念
将 input data stream (输入数据流) 视为 “Input Table”(输入表)。每个在 stream 上到达的 data item (数据项)就像是一个被 appended 到 Input Table 的新的 row 。
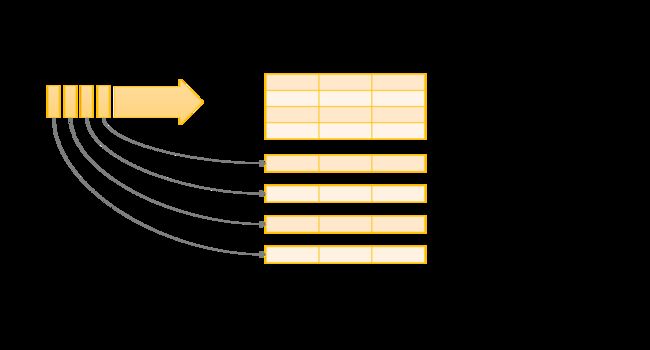
对输入的查询将生成 “Result Table” (结果表)。每个 trigger interval (触发间隔)(例如,每 1 秒),新 row (行)将附加到 Input Table ,最终更新 Result Table 。无论何时更新 result table ,我们都希望将 changed result rows (更改的结果行)写入 external sink (外部接收器)。
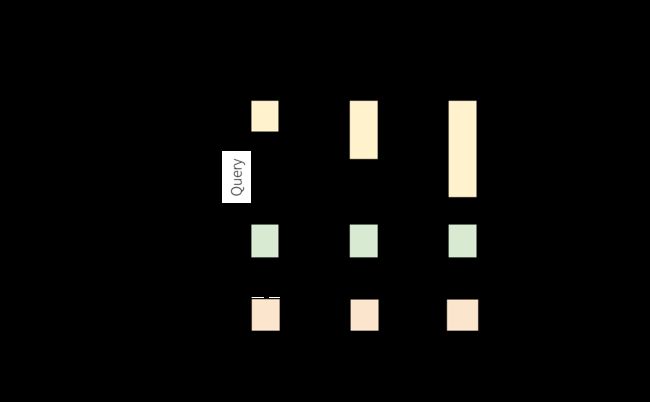
“Output(输出)” 被定义为写入 external storage (外部存储器)的内容。可以以不同的模式定义 output :
Complete Mode(完全模式)- 整个更新的 Result Table 将被写入外部存储。由 storage connector (存储连接器)决定如何处理整个表的写入。
Append Mode(附加模式)- 只有 Result Table 中自上次触发后附加的新 rows(行) 将被写入 external storage (外部存储)。这仅适用于不期望更改 Result Table 中现有行的查询。
Update Mode(更新模式)- 只有自上次触发后 Result Table 中更新的 rows (行)将被写入 external storage (外部存储)(从 Spark 2.1.1 之后可用)。请注意,这与 Complete Mode (完全模式),因为此模式仅输出自上次触发以来更改的 rows (行)。如果查询不包含 aggregations (聚合),它将等同于 Append mode 。
请注意,每种模式适用于特定模型的查询。这将在later详细讨论。
为了说明这个模型的使用,我们来了解一下上面章节的快速示例。第一个linesDataFrame 是 input table ,并且最后的wordCountsDataFrame 是 result table 。请注意,streaminglinesDataFrame 上的查询生成wordCounts是exactly the same(完全一样的)因为它将是一个 static DataFrame (静态 DataFrame )。但是,当这个查询启动时, Spark 将从 socket 连接中持续检查新数据。如果有新数据,Spark 将运行一个 “incremental(增量)” 查询,它会结合以前的 running counts (运行计数)与新数据计算更新的 counts ,如下所示。

这种模式与许多其他 stream processing engines (流处理引擎)有着显著不同。许多 streaming systems (流系统)要求用户本身保持运行 aggregations (聚合),因此必须要考虑容错,和数据一致性(at-least-once(至少一次), at-most-once (最多一次),exactly-once (完全一次))。在这个模型中,当有新数据时, Spark 负责更新 Result Table ,从而减轻用户对它的考虑。举个例子,我们来看一下这个模型如何处理对于基于 event-time 的处理和 late arriving (迟到)的数据。
处理 Event-time 和延迟数据
Event-time 是数据本身 embedded (嵌入)的时间。对于很多应用程序,您可能需要在此 event-time 进行操作。例如,如果要每分钟获取 IoT devices (设备)生成的 events 数,则可能希望使用数据生成的时间(即数据中的 event-time ),而不是 Spark 接收到它们的时间。这个 event-time 在这个模型中非常自然地表现出来 – 来自 devices (设备)的每个 event 都是表中的一 row(行),并且 event-time 是 row (行)中的 column value (列值)。这允许 window-based aggregations (基于窗口的聚合)(例如每分钟的 events 数)仅仅是 event-time 列上的特殊类型的 group (分组)和 aggregation (聚合) – 每个 time window 是一个组,并且每一 row (行)可以属于多个 windows/groups 。因此,可以在 static dataset (静态数据集)(例如来自 collected device events logs (收集的设备事件日志))以及 data stream 上一致地定义 event-time-window-based aggregation queries (基于事件时间窗口的聚合查询),从而使用户的使用寿命更加容易。
此外,这个模型自然地处理了比预计将根据它的 event-time 到达的数据晚到的数据。由于 Spark 正在更新 Result Table , Spark 有完整的控制对当有迟到的数据时 updating old aggregates (更新旧的聚合),以及清理 old aggregates (旧聚合) 以限制 intermediate state data (中间体状态数据)的大小。自 Spark 2.1 以来,我们对于 watermarking 进行了支持,允许用户指定 late data 的阈值,并允许引擎相应地清理旧状态。这些将在后面的Window Operations部分解释。
容错语义
提供 end-to-end exactly-once semantics (端到端的完全一次性语义)是 Structured Streaming 设计背后的关键目标之一。为了实现这一点,我们设计了 Structured Streaming sources , sinks 和 execution engine (执行引擎),以可靠的跟踪处理确切进度,以便它可以通过 restarting and/or reprocessing (重新启动和/或重新处理)来处理任何类型的故障。假设每个 streaming source 都具有 offsets (偏移量)(类似于 Kafka offsets 或 Kinesis sequence numbers (Kafka 偏移量或 Kinesis 序列号))来跟踪 stream 中的 read position (读取位置)。引擎使用 checkpointing (检查点)并 write ahead logs (预写日志)记录每个 trigger (触发器)中正在处理的数据的 offset range (偏移范围)。 streaming sinks 设计为处理后处理的 idempotent (幂等)。一起使用 replayable sources (可重放源)和 idempotent sinks (幂等接收器), Structured Streaming 可以确保在任何故障下end-to-end exactly-once semantics(端对端完全一次性语义)。
API 使用 Datasets 和 DataFrames
自从 Spark 2.0 , DataFrame 和 Datasets 可以表示 static (静态), bounded data(有界数据),以及 streaming , unbounded data (无界数据)。类似于 static Datasets/DataFrames ,您可以使用常用的 entry point (入口点)SparkSession(Scala/Java/Python/R文档) 来从 streaming sources 中创建 streaming DataFrames/Datasets ,并将其作为 static DataFrames/Datasets 应用相同的操作。如果您不熟悉 Datasets/DataFrames ,强烈建议您使用DataFrame/Dataset 编程指南来熟悉它们。
创建 streaming DataFrames 和 streaming Datasets
可以通过DataStreamReader的接口 (Scala/Java/Python文档 )来创建 Streaming DataFrames 并由SparkSession.readStream()返回。在R中,使用read.stream()方法。与创建 static DataFrame 的 read interface (读取接口)类似,您可以指定 source - data format (数据格式), schema (模式), options (选项)等的详细信息。
Input Sources (输入源)
在 Spark 2.0 中,有一些内置的 sources 。
File source(文件源)- 以文件流的形式读取目录中写入的文件。支持的文件格式为 text , csv , json , parquet 。有关更多的 up-to-date 列表,以及每种文件格式的支持选项,请参阅 DataStreamReader interface 的文档。请注意,文件必须以 atomically (原子方式)放置在给定的目录中,这在大多数文件系统中可以通过文件移动操作实现。
Kafka source(Kafka 源)- 来自 Kafka 的 Poll 数据。它与 Kafka broker 的 0.10.0 或者更高的版本兼容。有关详细信息,请参阅Kafka Integration 指南。
Socket source (for testing) (Socket 源(用于测试))- 从一个 socket 连接中读取 UTF8 文本数据。 listening server socket (监听服务器 socket)位于 driver 。请注意,这只能用于测试,因为它不提供 end-to-end fault-tolerance (端到端的容错)保证。
某些 sources 是不容错的,因为它们不能保证数据在使用 checkpointed offsets (检查点偏移量)故障之后可以被重新使用。参见前面的部分fault-tolerance semantics。以下是 Spark 中所有 sources 的详细信息。
SourceOptions(选项)Fault-tolerant(容错)Notes(说明)
File source(文件源)path: 输入路径的目录,并且与所有文件格式通用。
maxFilesPerTrigger: 每个 trigger (触发器)中要考虑的最大新文件数(默认是: 无最大值)
latestFirst: 是否先处理最新的新文件,当有大量积压的文件时有用(默认: false)
fileNameOnly: 是否仅根据文件名而不是完整路径检查新文件(默认值: false)。将此设置为 `true` ,以下文件将被视为相同的文件,因为它们的文件名 "dataset.txt" 是相同的:
· "file:///dataset.txt"
· "s3://a/dataset.txt"
· "s3n://a/b/dataset.txt"
· "s3a://a/b/c/dataset.txt"
有关特定于 file-format-specific (文件格式)的选项,请参阅DataStreamReader(Scala/Java/Python/R) 中的相关方法。例如,对于 "parquet" 格式选项请参阅DataStreamReader.parquet()Yes支持 glob 路径,但是不支持多个逗号分隔的 paths/globs 。
Socket Source(Socket 源)host: 连接到的 host ,必须指定
port: 连接的 port (端口),必须指定No
Kafka Source(Kafka 源)请查看Kafka Integration 指南.Yes
这里有一些例子。
Scala
Java
Python
R
valspark:SparkSession=...// 从 socket 读取 textvalsocketDF=spark.readStream.format("socket").option("host","localhost").option("port",9999).load()socketDF.isStreaming// 对于有 streaming sources 的 DataFrame 返回 TruesocketDF.printSchema// 读取目录内原子写入的所有 csv 文件valuserSchema=newStructType().add("name","string").add("age","integer")valcsvDF=spark.readStream.option("sep",";").schema(userSchema)// 指定 csv 文件的模式.csv("/path/to/directory")// 等同于 format("csv").load("/path/to/directory")
这些示例生成无类型的 streaming DataFrames ,这意味着在编译时不会检查 DataFrame 的模式,仅在运行时在 query is submitted (查询提交)的时候进行检查。像map,flatMap等这样的操作需要在编译时知道这个类型。要做到这一点,您可以使用与 static DataFrame 相同的方法将这些 untyped (无类型)的 streaming DataFrames 转换为 typed streaming Datasets (类型化的 streaming Datasets )。有关详细信息,请参阅SQL 编程指南。此外,有关支持的 streaming sources 的更多详细信息将在文档后面讨论。
streaming DataFrames/Datasets 的模式接口和分区
默认情况下,基于文件的 sources 的 Structured Streaming 需要您指定 schema (模式),而不是依靠 Spark 自动 infer 。这种 restriction 确保了 consistent schema (一致的模式)将被用于 streaming query (流式查询),即使在出现故障的情况下也是如此。对于 ad-hoc use cases (特殊用例),您可以通过将spark.sql.streaming.schemaInference设置为true来重新启用 schema inference (模式接口)。
当存在名为/key=value/的子目录并且列表将自动递归到这些目录中时,会发生 Partition discovery (分区发现)。如果这些 columns (列)显示在用户提供的 schema 中,则它们将根据正在读取的文件路径由 Spark 进行填充。 构成 partitioning scheme (分区方案)的目录 must be present when the query starts (必须在查询开始时是存在的),并且必须保持 static 。例如,当/data/year=2015/存在时,可以添加/data/year=2016/,但是更改 partitioning column (分区列)是无效的(即通过创建目录/data/date=2016-04-17/)。
streaming DataFrames/Datasets 上的操作
您可以对 streaming DataFrames/Datasets 应用各种操作 - 从 untyped (无类型), SQL-like operations (类似 SQL 的操作)(例如select,where,groupBy) 到 typed RDD-like operations (类型化的类似 RDD 的操作)(例如map,filter,flatMap)。有关详细信息,请参阅SQL 编程指南。让我们来看看可以使用的几个示例操作。
基础操作 - Selection, Projection, Aggregation
streaming 支持 DataFrame/Dataset 上的大多数常见操作。不支持的少数操作discussed later将在本节中讨论(稍后讨论)。
Scala
Java
Python
R
caseclassDeviceData(device:String,deviceType:String,signal:Double,time:DateTime)valdf:DataFrame=...// streaming DataFrame with IOT device data with schema { device: string, deviceType: string, signal: double, time: string }valds:Dataset[DeviceData]=df.as[DeviceData]// streaming Dataset with IOT device data// Select the devices which have signal more than 10df.select("device").where("signal > 10")// using untyped APIsds.filter(_.signal>10).map(_.device)// using typed APIs// Running count of the number of updates for each device typedf.groupBy("deviceType").count()// using untyped API// Running average signal for each device typeimportorg.apache.spark.sql.expressions.scalalang.typedds.groupByKey(_.deviceType).agg(typed.avg(_.signal))// using typed API
Window Operations on Event Time (事件时间窗口操作)
通过 Structured Streaming , sliding event-time window (滑动事件时间窗口)的 Aggregations (聚合)很简单,与 grouped aggregations (分组聚合)非常相似。在 grouped aggregation (分组聚合)中,为 user-specified grouping column (用户指定的分组列)中的每个唯一值维护 aggregate values (聚合值)(例如 counts )。在 window-based aggregations (基于窗口的聚合)的情况下,针对每个窗口的 event-time 维持 aggregate values (聚合值)。让我们用一个例子来理解这一点。
想象一下,我们的快速示例被修改,并且 stream 现在包含生成 line 的时间的 line 。不运行 word counts ,我们想 count words within 10 minute windows (在 10 分钟内的窗口计数单词),每 5 分钟更新一次。也就是说,在 10 minute windows (10 分钟的窗口之间)收到的 word counts 12:00 - 12:10, 12:05 - 12:15, 12:10 - 12:20 等。请注意, 12:00 - 12:10 表示数据在 12:00 之后但在 12:10 之前抵达。现在,考虑在 12:07 收到一个 word 。这个 word 应该增加对应于两个窗口的计数 12:00 - 12:10 和 12:05 - 12:15 。因此, counts 将被二者分组, grouping key (分组秘钥)(即 word)和 window (窗口)(可以从 event-time 计算)来 indexed (索引)。
result tables 将如下所示。
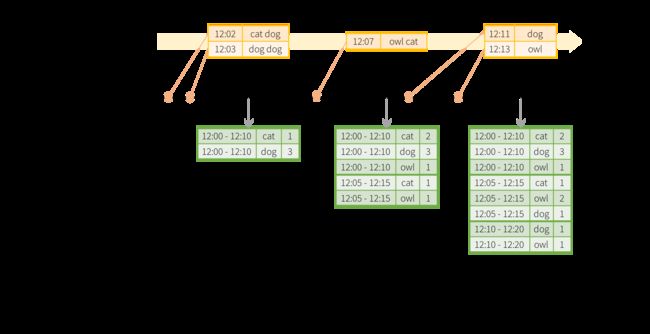
由于这个 windowing (窗口)类似于 grouping (分组),在代码中,您可以使用groupBy()和window()操作来表示 windowed aggregations (窗口化的聚合)。您可以看到以下示例Scala/Java/Python的完整代码。
Scala
Java
Python
importspark.implicits._valwords=...// streaming DataFrame of schema { timestamp: Timestamp, word: String }// Group the data by window and word and compute the count of each groupvalwindowedCounts=words.groupBy(window($"timestamp","10 minutes","5 minutes"),$"word").count()
处理 Late Data (迟到数据)和 Watermarking (水印)
现在考虑以下如果其中一个 event 迟到应用程序会发生什么。例如,想象一下,在 12:04 (即 event time )生成的 word 可以在 12:11 被接收申请。应用程序应该使用 12:04 而不是 12:11 来更新 window12:00 - 12:10的较旧 counts 。发生这种情况自然就是在我们 window-based grouping (基于窗口的分组中) - Structured Streaming 可以保持intermediate state 对于部分 aggregates (聚合)长时间,以便后期数据可以 update aggregates of old windows correctly (更新聚合)旧窗口正确,如下图所示。
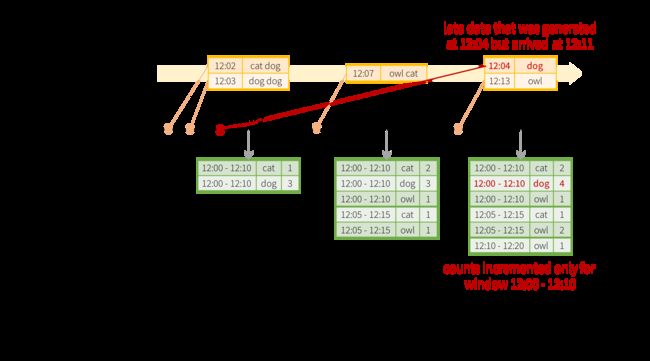
但是,要运行此查询几天,系统必须绑定 the amount of intermediate in-memory state it accumulates (中间状态累积的数量)。这意味着系统需要知道什么时候 old aggregate (老聚合)可以从内存中的状态丢失,因为这个应用程序不会在继续接收 aggregate (该聚合)的更多late data (后期的数据)。为了实现这一点,在 Spark 2.1 中,我们介绍了watermarking(水印),让引擎自动跟踪数据中的 current event time (当前事件时间)并试图相应地清理旧状态。您可以定义查询的 watermark 指定 event time column (事件时间列)和数据预期的延迟阈值 event time (事件时间)。对于从T时间开始的特定窗口,引擎将保持状态并允许 late data (延迟数据)更新状态直到(max event time seen by the engine - late threshold > T)。换句话说, threshold (阈值)内的 late data (晚期数据)将被 aggregated ,但数据晚于阈值将被丢弃。让我们以一个例子来理解这一点。我们可以使用withWatermark()可以轻松地定义上一个例子的 watermarking (水印),如下所示。
Scala
Java
Python
importspark.implicits._valwords=...// streaming DataFrame of schema { timestamp: Timestamp, word: String }// Group the data by window and word and compute the count of each groupvalwindowedCounts=words.withWatermark("timestamp","10 minutes").groupBy(window($"timestamp","10 minutes","5 minutes"),$"word").count()
在这个例子中,我们正在定义查询的 watermark 对 “timestamp” 列的值,并将 “10 minutes” 定义为允许数据延迟的阈值。如果这个查询以 Update output mode (更新输出模式)运行(稍后在Output Modes部分中讨论),引擎将不断更新 Result Table 中窗口的 counts ,直到 window is older than the watermark (窗口比水印较旧),它滞后于 current event time (当前事件时间)列 “timestamp” 10分钟。这是一个例子。

如图所示,maximum event time tracked (引擎跟踪的最大事件时间)是蓝色虚线,watermark 设置为(max event time - '10 mins')在每个触发的开始处是红线。例如,当引擎观察数据(12:14, dog)时,它为下一个触发器设置 watermark 为12:04。该 watermark 允许 engine 保持 intermediate state (中间状态)另外 10 分钟以允许延迟 late data to be counted (要计数的数据)。例如,数据(12:09, cat)是 out of order and late (不正常的,而且延迟了),它落在了 windows12:05 - 12:15和12:10 - 12:20。因为它仍然在 watermark12:04之前的触发器,引擎仍然将 intermediate counts (中间计数)保持为状态并正确 updates the counts of the related windows (更新相关窗口的计数)。然而,当 watermark 更新为12:11时,window(12:00 - 12:10)的中间状态被清除,所有 subsequent data (后续数据)(例如(12:04, donkey))被认为是 “too late” ,因此被忽视。请注意,每次触发后,写入 updated counts (更新的计数)(即紫色行)作为 trigger output 进行 sink ,如下 Update mode 所示。
某些 sinks (接收器)(例如 文件)可能不支持更新模式所需的 fine-grained updates (细粒度更新)。 与他们一起工作,我们也支持 Append Mode (附加模式),只有final counts(最终计数)被写入 sink 。这如下所示。
请注意,在 non-streaming Dataset (非流数据集)上使用withWatermark是不可行的。 由于 watermark 不应该以任何方式影响任何批处理查询,我们将直接忽略它。
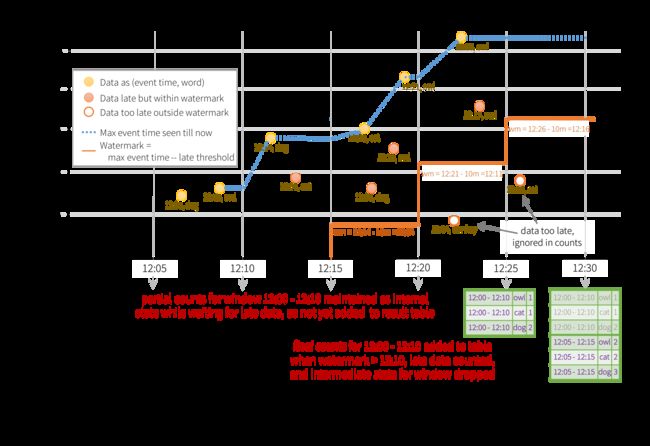
与之前的 Update Mode 类似,引擎维护 intermediate counts for each window (每个窗口的中间计数)。但是,partial counts (部分计数)不会更新到 Result Table ,也不是写入 sink 。 引擎等待迟到的 “10 mins” 计数,然后删除 window < watermark 的 intermediate state (中间状态),并追加最终 计数到 Result Table/sink 。 例如, window12:00 - 12:10的最终计数是仅在水印更新为12:11之后附加到 Result Table 。
Conditions for watermarking to clean aggregation state(watermarking 清理聚合状态的条件)重要的是要注意,watermarking 必须满足以下清理聚合查询中的状态的条件(从 Spark 2.1.1 开始,将来会更改)。
Output mode must be Append or Update.(输出模式必须是追加或者更新)Complete mode 要求保留所有 aggregate data (聚合数据),因此不能使用 watermarking 去掉 intermediate state (中间状态)。参见Output Modes部分,详细说明每种输出模式的语义。
aggregation (聚合)必须具有 event-time column (事件时间列)或 event-time column 上的window。
withWatermark必须被调用与聚合中使用的 timestamp column (时间戳列)相同的列。例如,df.withWatermark("time", "1 min").groupBy("time2").count()在 Append output mode 是无效的,因为 watermark 是从聚合列在不同的列上定义的。
在使用 watermark details 的 aggregation (聚合)之前必须调用withWatermark。例如,df.groupBy("time").count().withWatermark("time", "1 min")在 Append output mode 中是无效的。
Join 操作
Streaming DataFrames 可以与 static DataFrames 连接,以创建新的 streaming DataFrames 。 这里有几个例子。
Scala
Java
Python
valstaticDf=spark.read....valstreamingDf=spark.readStream....streamingDf.join(staticDf,"type")// inner equi-join with a static DFstreamingDf.join(staticDf,"type","right_join")// right outer join with a static DF
Streaming Deduplication (Streaming 去重)
您可以使用 events 中的 unique identifier (唯一标识符)对 data streams 中的记录进行重复数据删除。 这与使用唯一标识符列的 static 重复数据消除完全相同。 该查询将存储先前记录所需的数据量,以便可以过滤重复的记录。 与 aggregations (聚合)类似,您可以使用带有或不带有 watermarking 的重复数据删除功能。
With watermark(使用 watermark )- 如果重复记录可能到达的时间有上限,则可以在 event time column (事件时间列)上定义 watermark ,并使用 guid 和 event time columns 进行重复数据删除。 该查询将使用 watermark 从以前的记录中删除旧的状态数据,这些记录不会再受到任何重复。 这界定了查询必须维护的状态量。
Without watermark (不适用 watermark )- 由于当重复记录可能到达时没有界限,查询将来自所有过去记录的数据存储为状态。
Scala
Java
Python
valstreamingDf=spark.readStream....// columns: guid, eventTime, ...// Without watermark using guid columnstreamingDf.dropDuplicates("guid")// With watermark using guid and eventTime columnsstreamingDf.withWatermark("eventTime","10 seconds").dropDuplicates("guid","eventTime")
Arbitrary Stateful Operations (任意有状态的操作)
许多用例需要比 aggregations 更高级的状态操作。例如,在许多用例中,您必须 track (跟踪) data streams of events (事件数据流)中的 sessions (会话)。对于进行此类 sessionization (会话),您必须将 arbitrary types of data (任意类型的数据)保存为 state (状态),并在每个 trigger 中使用 state using the data stream events (数据流事件对状态)执行 arbitrary operations 。自从 Spark 2.2 ,可以使用mapGroupsWithState操作和更强大的操作flatMapGroupsWithState来完成。这两个操作都允许您在 grouped Datasets (分组的数据集)上应用用户定义的代码来更新用户定义的状态。有关更具体的细节,请查看 API文档(Scala/Java) 和例子 (Scala/Java)。
不支持的操作
streaming DataFrames/Datasets 不支持一些 DataFrame/Dataset 操作。其中一些如下。
streaming Datasets 不支持 Multiple streaming aggregations (多个流聚合) (i.e. a chain of aggregations on a streaming DF)(即 streaming DF 上的聚合链)
streaming Datasets 不支持 Limit and take first N rows 。
streaming Datasets 上的 Distinct operations 不支持。
只有在 aggregation 和 Complete Output Mode 下,streaming Datasets 才支持排序操作。
有条件地支持 streaming 和 static Datasets 之间的 Outer joins 。
不支持使用 streaming Dataset 的 Full outer join
不支持在右侧使用 streaming Dataset 的 Left outer join
不支持在左侧使用 streaming Dataset 的 Right outer join
不支持两种 streaming Datasets 之间的任何种类的 joins 。
此外,还有一些 Dataset 方法将不适用于 streaming Datasets 。他们是立即运行查询并返回结果的操作,这在 streaming Dataset 上没有意义。相反,这些功能可以通过显式启动 streaming query 来完成(参见下一节)。
count()- 无法从 streaming Dataset 返回 single count 。 而是使用ds.groupBy().count()返回一个包含 running count 的 streaming Dataset 。
foreach()- 而是使用ds.writeStream.foreach(...)(参见下一节).
show()- 而是使用 console sink (参见下一节).
如果您尝试任何这些操作,您将看到一个AnalysisException,如 “operation XYZ is not supported with streaming DataFrames/Datasets” 。虽然其中一些可能在未来版本的 Spark 中得到支持,还有其他一些从根本上难以有效地实现 streaming data 。例如, input stream 的排序不受支持,因为它需要保留 track of all the data received in the stream (跟踪流中接收到的所有数据)。 因此从根本上难以有效率地执行。
开始 Streaming Queries
一旦定义了 final result DataFrame/Dataset ,剩下的就是让你开始 streaming computation 。 为此,您必须使用DataStreamWriter(Scala/Java/Python文档)通过Dataset.writeStream()返回。您将必须在此 interface 中指定以下一个或多个。
Details of the output sink ( output sink 的详细信息):Data format, location, etc.
Output mode (输出模式):指定写入 output sink 的内容。
Query name (查询名称):可选,指定用于标识的查询的唯一名称。
Trigger interval (触发间隔):可选,指定触发间隔。 如果未指定,则系统将在上一次处理完成后立即检查新数据的可用性。 如果由于先前的处理尚未完成而导致触发时间错误,则系统将尝试在下一个触发点触发,而不是在处理完成后立即触发。
Checkpoint location (检查点位置):对于可以保证 end-to-end fault-tolerance (端对端容错)能力的某些 output sinks ,请指定系统将写入所有 checkpoint (检查点)信息的位置。 这应该是与 HDFS 兼容的容错文件系统中的目录。 检查点的语义将在下一节中进行更详细的讨论。
Output Modes (输出模式)
有几种类型的输出模式。
Append mode (default) (附加模式(默认))- 这是默认模式,其中只有 自从 last trigger (上一次触发)以来,添加到 Result Table 的新行将会是 outputted to the sink 。 只有添加到 Result Table 的行将永远不会改变那些查询才支持这一点。 因此,这种模式 保证每行只能输出一次(假设 fault-tolerant sink )。例如,只有select,where,map,flatMap,filter,join等查询支持 Append mode 。
Complete mode (完全模式)- 每次触发后,整个 Result Table 将被输出到 sink 。 aggregation queries (聚合查询)支持这一点。
Update mode (更新模式)- (自 Spark 2.1.1 可用) 只有 Result Table rows 自上次触发后更新将被输出到 sink 。更多信息将在以后的版本中添加。
不同类型的 streaming queries 支持不同的 output modes 。 以下是兼容性矩阵。
Query Type(查询类型)
Supported Output Modes(支持的输出模式)Notes(说明)
Queries with aggregation (使用聚合的查询)Aggregation on event-time with watermark (使用 watermark 的 event-time 聚合 )Append, Update, Complete (附加,更新,完全)Append mode 使用 watermark 来降低 old aggregation state (旧聚合状态)。 但输出 windowed aggregation (窗口聚合)延迟在 `withWatermark()` 中指定的 late threshold (晚期阈值)模式语义,rows 只能在 Result Table 中添加一次在 finalized (最终确定)之后(即 watermark is crossed (水印交叉)后)。 有关详细信息,请参阅Late Data部分。
Update mode 使用 watermark 删除 old aggregation state (旧的聚合状态)。
Complete mode (完全模式)不会删除旧的聚合状态,因为从定义这个模式 保留 Result Table 中的所有数据。
Other aggregations (其他聚合)Complete, Update (完全,更新)由于没有定义 watermark(仅在其他 category 中定义),旧的聚合状态不会删除。
不支持 Append mode ,因为 aggregates (聚合)可以更新,从而违反了这种模式的语义。
Queries withmapGroupsWithStateUpdate (更新)
Queries withflatMapGroupsWithStateAppend operation mode (附加操作模式)Append (附加)flatMapGroupsWithState之后允许 Aggregations (聚合)。
Update operation mode (更新操作模式)Update(更新)flatMapGroupsWithState之后不允许 Aggregations (聚合)。
Other queries (其他查询)Append, Update (附加,更新)不支持 Complete mode ,因为将所有未分组数据保存在 Result Table 中是不可行的 。
Output Sinks (输出接收器)
有几种类型的内置输出接收器。
File sink (文件接收器)- 将输出存储到目录中。
writeStream.format("parquet")// can be "orc", "json", "csv", etc..option("path","path/to/destination/dir").start()
Foreach sink- 对 output 中的记录运行 arbitrary computation 。 有关详细信息,请参阅本节后面部分。
writeStream.foreach(...).start()
Console sink (for debugging) (控制台接收器(用于调试))- 每次触发时,将输出打印到 console/stdout 。 都支持 Append 和 Complete 输出模式。 这应该用于低数据量的调试目的,因为在每次触发后,整个输出被收集并存储在驱动程序的内存中。
writeStream.format("console").start()
Memory sink (for debugging) (内存 sink (用于调试))- 输出作为 in-memory table (内存表)存储在内存中。都支持 Append 和 Complete 输出模式。 这应该用于调试目的在低数据量下,整个输出被收集并存储在驱动程序的存储器中。因此,请谨慎使用。
writeStream.format("memory").queryName("tableName").start()
某些 sinks 是不容错的,因为它们不能保证输出的持久性并且仅用于调试目的。参见前面的部分容错语义。以下是 Spark 中所有接收器的详细信息。
Sink (接收器)Supported Output Modes (支持的输出模式)Options (选项)Fault-tolerant (容错)Notes (说明)
File Sink (文件接收器)Append (附加)path: 必须指定输出目录的路径。
有关特定于文件格式的选项,请参阅 DataFrameWriter (Scala/Java/Python/R) 中的相关方法。 例如,对于 "parquet" 格式选项,请参阅DataFrameWriter.parquet()Yes支持对 partitioned tables (分区表)的写入。按时间 Partitioning (划分)可能是有用的。
Foreach SinkAppend, Update, Compelete (附加,更新,完全)None取决于 ForeachWriter 的实现。更多详细信息在下一节
Console Sink (控制台接收器)Append, Update, Complete (附加,更新,完全)numRows: 每个触发器需要打印的行数(默认:20)
truncate: 如果输出太长是否截断(默认: true)No
Memory Sink (内存接收器)Append, Complete (附加,完全)None否。但是在 Complete Mode 模式下,重新启动的查询将重新创建完整的表。Table name is the query name.(表名是查询的名称)
请注意,您必须调用start()来实际启动查询的执行。 这将返回一个 StreamingQuery 对象,它是连续运行的执行的句柄。 您可以使用此对象来管理查询,我们将在下一小节中讨论。 现在,让我们通过几个例子了解所有这些。
Scala
Java
Python
R
// ========== DF with no aggregations ==========valnoAggDF=deviceDataDf.select("device").where("signal > 10")// Print new data to consolenoAggDF.writeStream.format("console").start()// Write new data to Parquet filesnoAggDF.writeStream.format("parquet").option("checkpointLocation","path/to/checkpoint/dir").option("path","path/to/destination/dir").start()// ========== DF with aggregation ==========valaggDF=df.groupBy("device").count()// Print updated aggregations to consoleaggDF.writeStream.outputMode("complete").format("console").start()// Have all the aggregates in an in-memory tableaggDF.writeStream.queryName("aggregates")// this query name will be the table name.outputMode("complete").format("memory").start()spark.sql("select * from aggregates").show()// interactively query in-memory table
使用 Foreach
foreach操作允许在输出数据上计算 arbitrary operations 。从 Spark 2.1 开始,这只适用于 Scala 和 Java 。为了使用这个,你必须实现接口ForeachWriter(Scala/Java文档) 其具有在 trigger (触发器)之后生成 sequence of rows generated as output (作为输出的行的序列)时被调用的方法。请注意以下要点。
writer 必须是 serializable (可序列化)的,因为它将被序列化并发送给 executors 执行。
所有这三个方法,open,process和close都会在执行器上被调用。
只有当调用open方法时,writer 才能执行所有的初始化(例如打开连接,启动事务等)。请注意,如果在创建对象时立即在类中进行任何初始化,那么该初始化将在 driver 中发生(因为这是正在创建的实例),这可能不是您打算的。
version和partition是open中的两个参数,它们独特地表示一组需要被 pushed out 的行。version是每个触发器增加的单调递增的 id 。partition是一个表示输出分区的 id ,因为输出是分布式的,将在多个执行器上处理。
open可以使用version和partition来选择是否需要写入行的顺序。因此,它可以返回true(继续写入)或false( 不需要写入 )。如果返回false,那么process不会在任何行上被调用。例如,在 partial failure (部分失败)之后,失败的触发器的一些输出分区可能已经被提交到数据库。基于存储在数据库中的 metadata (元数据), writer 可以识别已经提交的分区,因此返回 false 以跳过再次提交它们。
当open被调用时,close也将被调用(除非 JVM 由于某些错误而退出)。即使open返回 false 也是如此。如果在处理和写入数据时出现任何错误,那么close将被错误地调用。您有责任清理以open创建的状态(例如,连接,事务等),以免资源泄漏。
管理 Streaming Queries
在启动查询时创建的StreamingQuery对象可用于 monitor and manage the query (监视和管理查询)。
Scala
Java
Python
R
valquery=df.writeStream.format("console").start()// get the query objectquery.id// get the unique identifier of the running query that persists across restarts from checkpoint dataquery.runId// get the unique id of this run of the query, which will be generated at every start/restartquery.name// get the name of the auto-generated or user-specified namequery.explain()// print detailed explanations of the queryquery.stop()// stop the queryquery.awaitTermination()// block until query is terminated, with stop() or with errorquery.exception// the exception if the query has been terminated with errorquery.recentProgress// an array of the most recent progress updates for this queryquery.lastProgress// the most recent progress update of this streaming query
您可以在单个 SparkSession 中启动任意数量的查询。 他们都将同时运行共享集群资源。 您可以使用sparkSession.streams()获取StreamingQueryManager(Scala/Java/Python文档) 可用于管理 currently active queries (当前活动的查询)。
Scala
Java
Python
R
valspark:SparkSession=...spark.streams.active// get the list of currently active streaming queriesspark.streams.get(id)// get a query object by its unique idspark.streams.awaitAnyTermination()// block until any one of them terminates
监控 Streaming Queries
有两个用于 monitoring and debugging active queries (监视和调试活动查询) 的 API - interactively 和 asynchronously 。
Interactive APIs
您可以直接获取活动查询的当前状态和指标使用streamingQuery.lastProgress()和streamingQuery.status()。lastProgress()返回一个StreamingQueryProgress对象 在Scala和Java和 Python 中具有相同字段的字典。它有所有的信息在 stream 的最后一个触发器中取得的 progress - 处理了哪些数据,处理率是多少,延迟等等。streamingQuery.recentProgress返回最后几个进度的 array 。
另外,streamingQuery.status()返回一个StreamingQueryStatus对象在Scala和Java和 Python 中具有相同字段的字典。它提供有关的信息立即执行的查询 - 触发器是否 active ,数据是否正在处理等。
这里有几个例子。
Scala
Java
Python
R
valquery:StreamingQuery=...println(query.lastProgress)/* Will print something like the following.{"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109","runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a","name" : "MyQuery","timestamp" : "2016-12-14T18:45:24.873Z","numInputRows" : 10,"inputRowsPerSecond" : 120.0,"processedRowsPerSecond" : 200.0,"durationMs" : {"triggerExecution" : 3,"getOffset" : 2},"eventTime" : {"watermark" : "2016-12-14T18:45:24.873Z"},"stateOperators" : [ ],"sources" : [ {"description" : "KafkaSource[Subscribe[topic-0]]","startOffset" : {"topic-0" : {"2" : 0,"4" : 1,"1" : 1,"3" : 1,"0" : 1}},"endOffset" : {"topic-0" : {"2" : 0,"4" : 115,"1" : 134,"3" : 21,"0" : 534}},"numInputRows" : 10,"inputRowsPerSecond" : 120.0,"processedRowsPerSecond" : 200.0} ],"sink" : {"description" : "MemorySink"}}*/println(query.status)/* Will print something like the following.{"message" : "Waiting for data to arrive","isDataAvailable" : false,"isTriggerActive" : false}*/
Asynchronous API
您还可以 asynchronously monitor (异步监视)与SparkSession相关联的所有查询 通过附加一个StreamingQueryListener(Scala/Javadocs) 。一旦你使用sparkSession.streams.attachListener()附加你的自定义StreamingQueryListener对象,当您启动查询和当有活动查询有进度时停止时,您将收到 callbacks (回调)。 这是一个例子,
Scala
Java
Python
R
valspark:SparkSession=...spark.streams.addListener(newStreamingQueryListener(){overridedefonQueryStarted(queryStarted:QueryStartedEvent):Unit={println("Query started: "+queryStarted.id)}overridedefonQueryTerminated(queryTerminated:QueryTerminatedEvent):Unit={println("Query terminated: "+queryTerminated.id)}overridedefonQueryProgress(queryProgress:QueryProgressEvent):Unit={println("Query made progress: "+queryProgress.progress)}})
Recovering from Failures with Checkpointing (从检查点恢复故障)
如果发生 failure or intentional shutdown (故障或故意关机),您可以恢复之前的查询的进度和状态,并继续停止的位置。 这是使用 checkpointing and write ahead logs (检查点和预写入日志)来完成的。 您可以使用 checkpoint location (检查点位置)配置查询,并且查询将保存所有进度信息(即,每个触发器中处理的偏移范围)和正在运行的 aggregates (聚合)(例如quick example中的 woed counts ) 到 checkpoint location (检查点位置)。 此检查点位置必须是 HDFS 兼容文件系统中的路径,并且可以在starting a query时将其设置为DataStreamWriter 中的选项。
Scala
Java
Python
R
aggDF.writeStream.outputMode("complete").option("checkpointLocation","path/to/HDFS/dir").format("memory").start()
从这里去哪儿
示例: 查看并运行Scala/Java/Python/R示例。
Spark Summit 2016 Talk -深入 Structured Streaming
我们一直在努力
apachecn/spark-doc-zh
原文地址: http://spark.apachecn.org/docs/cn/2.2.0/structured-streaming-programming-guide.html
网页地址: http://spark.apachecn.org/
github: https://github.com/apachecn/spark-doc-zh(觉得不错麻烦给个 Star,谢谢!~)