数据结构与算法--最小生成树之Prim算法
加权图是一种为每条边关联一个权值或称为成本的图模型。所谓生成树,是某图的一棵含有全部n个顶点的无环连通子图,它有n - 1条边。最小生成树(MST)是加权图的一棵权值和(所有边的权值相加之和)最小的生成树。
要注意以下几点:
- 最小生成树首先是一个生成树,所以我们研究的是无环连通分量;
- 边的权值可能是0也可能是负数
- 边的权值不一定表示距离,还可以是费用等
加权无向图的实现
之前图的实现都没有考虑权值,而权值存在于边上,所以最好是将“边”这个概念抽象出来,用一个Edge类来表示。如下
package Chap7;
public class Edge implements Comparable {
private int either;
private int other;
private double weight;
public Edge(int either, int other, double weight) {
this.either = either;
this.other = other;
this.weight = weight;
}
public double weight() {
return weight;
}
public int either() {
return either;
}
public int other(int v) {
if (v == either) {
return other;
} else if (v == other) {
return either;
} else throw new RuntimeException("该边无此顶点!");
}
@Override
public int compareTo(Edge that) {
return Double.compare(this.weight, that.weight);
}
@Override
public String toString() {
return "(" +
either +
"-" + other +
" " + weight +
')';
}
}
Edge类实现了Comparable,使得Edge本身可以进行比较(就像Double类那样)而比较的依据是边上的权值。Edge类中的other(int v)方法,接收一个顶点,如果v在该边中,返回该边的另一个顶点,否则抛出异常。
接下来是加权无向图的实现。
package Chap7;
import java.util.*;
public class EdgeWeightedGraph- {
private int vertexNum;
private int edgeNum;
// 邻接表
private List
> adj;
// 顶点信息
private List- vertexInfo;
public EdgeWeightedGraph(List
- vertexInfo) {
this.vertexInfo = vertexInfo;
this.vertexNum = vertexInfo.size();
adj = new ArrayList<>();
for (int i = 0; i < vertexNum; i++) {
adj.add(new LinkedList<>());
}
}
public EdgeWeightedGraph(List
- vertexInfo, int[][] edges, double[] weight) {
this(vertexInfo);
for (int i = 0; i < edges.length;i++) {
Edge edge = new Edge(edges[i][0], edges[i][1], weight[i]);
addEdge(edge);
}
}
public EdgeWeightedGraph(int vertexNum) {
this.vertexNum = vertexNum;
adj = new ArrayList<>();
for (int i = 0; i < vertexNum; i++) {
adj.add(new LinkedList<>());
}
}
public EdgeWeightedGraph(int vertexNum, int[][] edges, double[] weight) {
this(vertexNum);
for (int i = 0; i < edges.length;i++) {
Edge edge = new Edge(edges[i][0], edges[i][1], weight[i]);
addEdge(edge);
}
}
public void addEdge(Edge edge) {
int v = edge.either();
int w = edge.other(v);
adj.get(v).add(edge);
adj.get(w).add(edge);
edgeNum++;
}
// 返回与某个顶点依附的所有边
public Iterable
adj(int v) {
return adj.get(v);
}
public List edges() {
List edges = new LinkedList<>();
for (int i = 0; i < vertexNum; i++) {
for (Edge e: adj(i)) {
// i肯定是边e的一个顶点,我们只取other大于i的边,避免添加重复的边
// 比如adj(1)中的1-3边会被添加,但是adj(3)中的3-1就不会被添加
if (e.other(i) > i) {
edges.add(e);
}
}
}
return edges;
}
public int vertexNum() {
return vertexNum;
}
public int edgeNum() {
return edgeNum;
}
public Item getVertexInfo(int i) {
return vertexInfo.get(i);
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(vertexNum).append("个顶点, ").append(edgeNum).append("条边。\n");
for (int i = 0; i < vertexNum; i++) {
sb.append(i).append(": ").append(adj.get(i)).append("\n");
}
return sb.toString();
}
public static void main(String[] args) {
List vertexInfo = Arrays.asList("v0", "v1", "v2", "v3", "v4");
int[][] edges = {{0, 1}, {0, 2}, {0, 3},
{1, 3}, {1, 4},
{2, 4}};
double[] weight = {30.0, 40.0, 20.5, 10.0, 59.5, 20.0};
EdgeWeightedGraph graph = new EdgeWeightedGraph<>(vertexInfo, edges, weight);
System.out.println("该图的邻接表为\n"+graph);
System.out.println("该图的所有边:"+ graph.edges());
}
}
edges()方法可以返回图中的所有边。下面的判断比较关键
for (Edge e: adj(i)) {
if (e.other(i) > i) {
edges.add(e);
}
}
i肯定是边e的一个顶点,我们只取other大于i的边,避免添加重复的边。 比如adj(1)中的1-3边会被添加,但是adj(3)中的3-1就不会被添加。
这份代码只实现了部分方法,像获取某个顶点的度,图的平均度数,这些实现起来都很简单,而且可以直接照搬无权图的代码,我们讨论的重点是最小生成树,所以就不贴那些代码了。
最小生成树有两个经典的算法,一个是Prim算法,另外一个是Kruskal算法,接下来会依次介绍它们。
Prim算法
该算法的主要思想是:从生成树邻近的边中,选出一条权值最小的,加入到树中;如果选出的边会导致成环,舍弃之,选择下一条权值最小的边。
首先我们需要一个优先队列存放顶点的邻接边,一个布尔数组标记已经访问过的顶点,一个队列存储最小生成树的边。
- 从某一个顶点开始(不妨假设从顶点0开始),标记它,并将它邻接表中的边全部加入到队列中;
- 从队列中选出并删除权值最小的那条边,先检查这条边的两个顶点是否都已经被标记过,若是,加入这条边会导致成环。跳过这条边,选择并删除下一个权值最小的边,直到某条边的两个顶点不是都被标记过,然后将其加入到MST中,将该边的另一个顶点标记,并将所有与这个顶点相邻且未被标记的顶点的边加入队列。
- 重复上述步骤,直到列表中的元素都被删除。
package Chap7;
import java.util.*;
public class LazyPrim {
private boolean marked[];
Queue edges;
private Queue mst;
public LazyPrim(EdgeWeightedGraph graph) {
marked = new boolean[graph.vertexNum()];
edges = new PriorityQueue<>();
mst = new LinkedList<>();
// 从顶点0开始访问
visit(graph, 0);
// 只要边还没被删除完,就循环
while (!edges.isEmpty()) {
// 优先队列,将权值最小的选出并删除
Edge edge = edges.poll();
int v = edge.either();
int w = edge.other(v);
// 这样的边会导致成环,跳过
if (marked[v] && marked[w]) {
continue;
}
// 加入到MST中
mst.offer(edge);
// 因为edges中的边肯定是有一个顶点已经visit过了,但是不知道是either还是other
// 如果v没被标记,那么访问它;否则v被标记了,那么w肯定没被标记(marked[v] && marked[w]的情况已经被跳过了)
if (!marked[v]) {
visit(graph, v);
} else {
visit(graph, w);
}
}
}
private void visit(EdgeWeightedGraph graph, int v) {
marked[v] = true;
for (Edge e : graph.adj(v)) {
// v的邻接边中,将另一个顶点未被标记的边加入列表中。若另一个顶点标记了还加入,就会重复添加
if (!marked[e.other(v)]) {
edges.offer(e);
}
}
}
public Iterable edges() {
return mst;
}
public double weight() {
return mst.stream().mapToDouble(Edge::weight).sum();
}
public static void main(String[] args) {
List vertexInfo = Arrays.asList("v0", "v1", "v2", "v3", "v4", " v5", "v6", "v7");
int[][] edges = {{4, 5}, {4, 7}, {5, 7}, {0, 7},
{1, 5}, {0, 4}, {2, 3}, {1, 7}, {0, 2}, {1, 2},
{1, 3}, {2, 7}, {6, 2}, {3, 6}, {6, 0}, {6, 4}};
double[] weight = {0.35, 0.37, 0.28, 0.16, 0.32, 0.38, 0.17, 0.19,
0.26, 0.36, 0.29, 0.34, 0.40, 0.52, 0.58, 0.93};
EdgeWeightedGraph graph = new EdgeWeightedGraph<>(vertexInfo, edges, weight);
LazyPrim prim = new LazyPrim(graph);
System.out.println("MST的所有边为:" + prim.edges());
System.out.println("最小成本和为:" + prim.weight());
}
}
/* Outputs
MST的所有边为:[(0-7 0.16), (1-7 0.19), (0-2 0.26), (2-3 0.17), (5-7 0.28), (4-5 0.35), (6-2 0.4)]
最小成本和为:1.81
*/
上述代码,mst是一个队列,用来存放MST中的边(按照加入的顺序)。edges是一个优先队列,每次访问一个点,就将它的邻接边中,另一顶点未被标记的那些边加入。每次要从edges里选出权值最小的边删除...解释代码始终让人头晕,还是结合图来看下最小生成树的那些边是怎么选出来的。
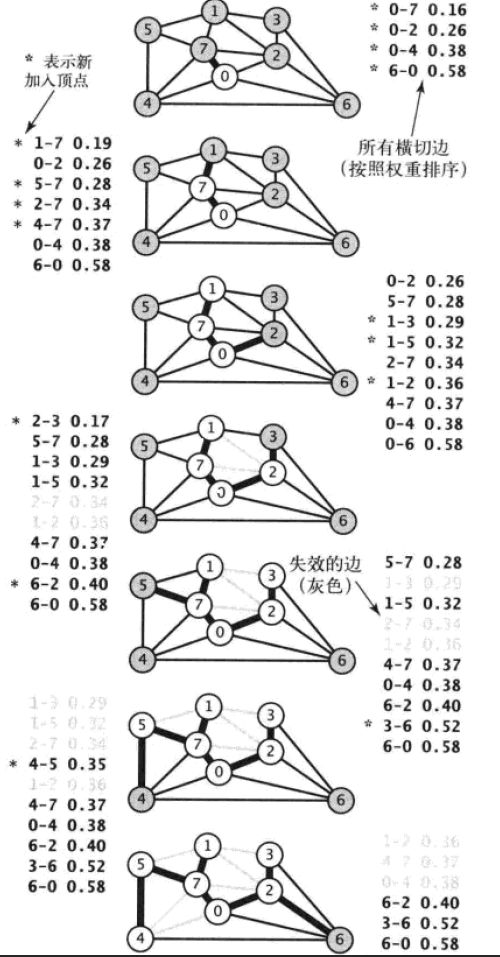
- 从顶点0开始,标记它,并将0-7, 0-2, 0-6, 0-4加入edges。这体现在一开始的
visit(graph, 0)中 - 此时edges不为空,只要edges不为空,while循环就一直持续下去。选择并删除第一个元素(也就是权值最小的边0-7),加入到MST中。
- 接着访问顶点7,将其所有邻接边加入到edges中,选出1-7这条权值最小的边,加入到MST中。然后访问顶点1,将除了1-7外的其他和1邻接的边都加入到edges中,从edges中选出权值最小的边为0-2加入到MST,2的邻接边中2-7, 1-2由于会导致成环,所以不加入edges,将2-3, 2-6加入。
- 选择权值最小的2-3,加入MST。将3-6加入到edges。
- 选出权值最小的5-7加入MST,4-5加入edges。
- 接下来1-3,1-5,2-7由于两个顶点都被标记过,所以被跳过。选择4-5加入MST,同时6-4加入edges。
- 1-2, 4-7,0-4连个顶点被标记,跳过。选择6-2加入MST。至此n个顶点和n - 1条边都被加入到MST中,最小生成树完成了。
- 后续工作,edges中剩余的边,因为两个顶点都标记过,所以一直跳过直到edges为空,程序结束。
可以看到,我们依次选出了(0-7 0.16), (1-7 0.19), (0-2 0.26), (2-3 0.17), (5-7 0.28), (4-5 0.35), (6-2 0.4)这些边,他们的总和(最小权值和)为1.81。
Prim算法的优化
上述Prim算法是延时实现,因为它在列表中保留了无效的边(会导致成环的边),每次都要判断并跳过,甚至最小生成树完成后,还要历经后续的检查。究其原因,是因为每次访问一个顶点几乎将其所有邻接边都加入了edges列表里面。我们对此进行优化,优化的版本称为Prim算法的即时实现。如下图

0为起点,一开始,0-4、0-7、0-2、0-6会加入到edges,然后选出权值最小的0-7边。关键来了,延时实现中,会将7-1, 7-2, 7-5, 7-4全加入edges。我们知道7-2和7-4最后因为是无效边会被跳过。0和7都已经在MST中,那么7-4和0-4两条边不可能被同时选出作为MST的边,否则成环;所以两者只能有一条有可能成为MST的边,自然选权值小的那条啊!所以到顶点4的边应该选7-4,但是0-4已经被加入到edges中,我们要做的就是用7-4取代0-4;再看另一边,同样7-2和0-2也是只有一条有可能作为MST的边,但是已经加入edges的0-2权值本来就比7-2要小,所以7-2不能加入到edges。优化后的Prim算法在这一步中只将7-1和7-5存入,加上一次将0-4修改为7-4的操作。
上面的意思其实就是说:MST以及一个MST外的顶点,我们总是选择该顶点到MST各个顶点权值最小的那条边。
基于此思想,我们来实现Prim算法的即时版本,首先要了解到,由于我们要时常更新存入的边,所以改用一个edgeTo[]存放到某顶点权值最小的那条边,distTo[]存放到该顶点的最小权值,也就是说distTo[w] = edgeTo[w].weight()。使用一个Map代替原来的edges,用来存放顶点和到该顶点的最小权值,使用Map是因为顶点和到该顶点的最小权值存在一对一的映射关系,而且顶点作为键,本来就不存在重复的说法,可以放心用。
package Chap7;
import java.util.*;
public class Prim {
private boolean marked[];
private Edge[] edgeTo;
private double[] distTo;
private Map minDist;
public Prim(EdgeWeightedGraph graph) {
marked = new boolean[graph.vertexNum()];
edgeTo = new Edge[graph.vertexNum()];
distTo = new double[graph.vertexNum()];
minDist = new HashMap<>();
// 初始化distTo,distTo[0]不会被赋值,默认0.0正好符合我们的要求,使余下的每个值都为正无穷,
for (int i = 1; i < graph.vertexNum(); i++) {
distTo[i] = Double.POSITIVE_INFINITY; // 1.0 / 0.0为INFINITY
}
visit(graph, 0);
while (!minDist.isEmpty()) {
visit(graph, delMin());
}
}
private int delMin() {
Set> entries = minDist.entrySet();
Map.Entry min = entries.stream().min(Comparator.comparing(Map.Entry::getValue)).get();
int key = min.getKey();
minDist.remove(key);
return key;
}
private void visit(EdgeWeightedGraph graph, int v) {
marked[v] = true;
for (Edge e: graph.adj(v)) {
int w = e.other(v);
if (marked[w]) {
continue;
}
if (e.weight() < distTo[w]) {
distTo[w] = e.weight();
edgeTo[w] = e;
if (minDist.containsKey(w)) {
minDist.replace(w, distTo[w]);
} else {
minDist.put(w, distTo[w]);
}
}
}
}
public Iterable edges() {
List edges = new ArrayList<>();
edges.addAll(Arrays.asList(edgeTo).subList(1, edgeTo.length));
return edges;
}
public double weight() {
return Arrays.stream(distTo).reduce(0.0, Double::sum);
}
public static void main(String[] args) {
List vertexInfo = Arrays.asList("v0", "v1", "v2", "v3", "v4", " v5", "v6", "v7");
int[][] edges = {{4, 5}, {4, 7}, {5, 7}, {0, 7},
{1, 5}, {0, 4}, {2, 3}, {1, 7}, {0, 2}, {1, 2},
{1, 3}, {2, 7}, {6, 2}, {3, 6}, {6, 0}, {6, 4}};
double[] weight = {0.35, 0.37, 0.28, 0.16, 0.32, 0.38, 0.17, 0.19,
0.26, 0.36, 0.29, 0.34, 0.40, 0.52, 0.58, 0.93};
EdgeWeightedGraph graph = new EdgeWeightedGraph<>(vertexInfo, edges, weight);
Prim prim = new Prim(graph);
System.out.println("MST的所有边为:" + prim.edges());
System.out.println("最小成本和为:" + prim.weight());
}
}
/* Outputs
MST的所有边为:[(1-7 0.19), (0-2 0.26), (2-3 0.17), (4-5 0.35), (5-7 0.28), (6-2 0.4), (0-7 0.16)]
最小成本和为:1.8099999999999998
*/
一开始将distTo[]初始化,除了distTo[0]因为永远也访问不到,其余都初始化为正无穷。然后开始访问顶点0,visit方法基本和延时实现差不多,只是多了判断,如果有到w权值更小的边,就更新edgeTo数组和distTo数组,现在edgeTo数组存的是到顶点w权值最小的边,除了edgeTo[0]永远不会被访问到,其值为null外,里面存的分别是到顶点1、2、3...n -1的权值最小的边,共n - 1条。只要始终维护这个数组,保证到程序结束时到每个顶点的还是权值最小的那条边,那么由这些边组成的就是我们要求的最小生成树。上面有提到,加了判断后可避免一些迟早会成无效的边加入。
再看delMin()方法,该方法选出字典中value(也就是权值)最小的那个键值对,获得key(也就是顶点),删除该键值对,紧接着访问key顶点。和延时实现操作一样。
最后字典为空时,edgeTo数组也随之确定好了,不存在后续检查步骤。输出那么一长串,是double的锅,精确值其实为1.81,使用BigDecimal可以得到精确值。
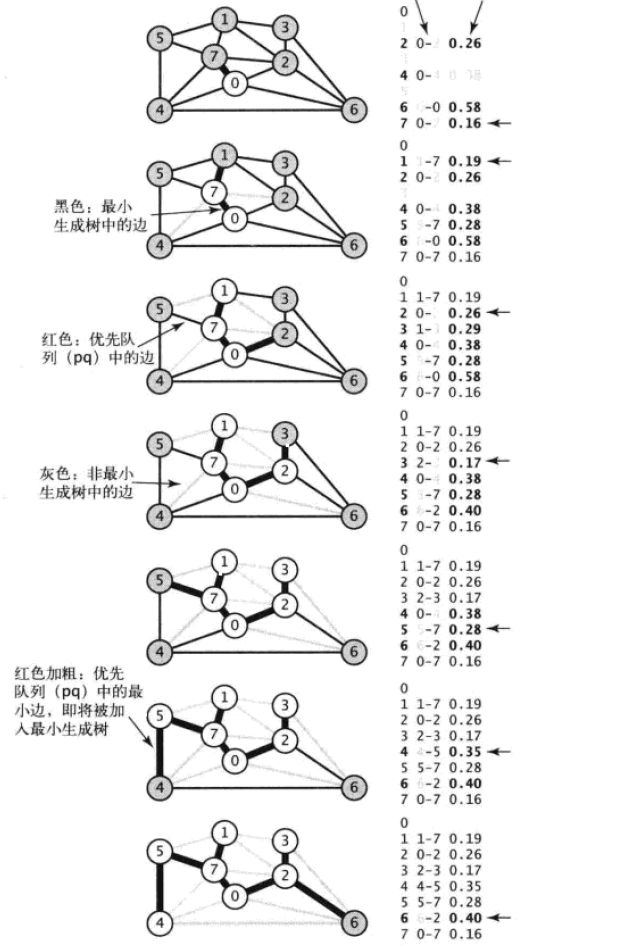
我们来详细地走一遍。
- 首先访问顶点0,边0-7, 0-2, 0-4, 0-6被加入Map中,因为这些边是目前(唯一)MST外顶点与MST连接的最小权值边,也就是说edgeTo[7] = 0-7、edgeTo[2] = 0-2、edgeTo[4] = 0-4、edgeTo[6] = 0-6。
- 然后删除权值最小的边0-7,并开始访问顶点7,将7-5, 7-1加入Map,7-4因为比0-4权值小(更靠近MST),所以edgeTo[4] 改为 7-4;7-2不加入Map因为0-2的权值本来就比7-2小。现在edgeTo[5] = 7-5, edgeTo[1] = 7-1;
- 删除边7-1,并访问顶点1。将1-3加入Map,1-5不加入因为7-5的权值本来就比它小。edgeTo[3] = 1-3
- 删除0-2,并访问顶点2,2-3的权值比1-3小,所以更新edgeTo[3] = 2-3,2-6权值小于0-6,更新edgeTo[6] = 2-6
- 删除2-3,并访问顶点3,3-6不加入Map因为2-6权值本来就比它小。
- 删除5-7,5-4权值比7-4小,更新edgeTo[4] = 5-4
- 删除4-5,访问顶点4,4-6不加入Map,因为2-6的权值本来就比它小
- 删除6-2,至此所有顶点都已访问过,且Map为空,最小生成树完成。
Prim算法,就好比:从一株小树苗开始,不断从附近找到离它最近的一根树枝,安在自己身上,小树慢慢长大成大树,最后找到n-1条树枝后就成了最小生成树。
上面说的太有画面感了...由于篇幅原因,Kruskal算法在下一节中介绍。
by @sunhaiyu
2017.9.21