在All in Cloud的云计算时代,业务和应用正在不断“云化”,在此过程中云原生(Cloud Native)理念应运而生。作为云化改造的重要部分,云数据库因其天生的弹性扩展能力以及灵活、易用等特点,让其在面对爆炸性增长的数据量和愈加繁复的数据类型时表现的更加游刃有余。
面对业务及应用的“云原生化”,数据库技术究竟面临了怎样的挑战及发展趋势?为此巨杉科技特别举办了“云时代的数据库架构设计与演进”深圳站活动,邀请多位数据库领域专家带来精彩纷呈的技术干货、分享实实在在的应用实践经验,让现场数百位开发者收获满满。

云架构下分布式数据库设计实践
作为第一位分享嘉宾, 巨杉数据库研发副总裁许建辉在主题为“云架构下分布式数据库设计实践”的分享中表示,云架构对数据库的要求最先产生于应用程序的变革。“很早之前,过去的应用开发并没有如此多的快速服务帮助,当时的数据开发模式如何?所有的企业应该都有平台部,负责开发一套与所有数据库打交道的中间件,负责与所有的数据库读取、存储、前端应用等做业务方面的链接。我们发现,在这种模式下数据库是一个集中存储的状态,比较耦合。”

随着互联网业务的快速兴起以及云架构逐渐普及,进而产生了微服务应用体系。在微服务架构下,我们看到了对数据库访问模式发生的变迁。据了解,目前业界有三种情况,首先基于微服务并不需要做太多调整,采用集中数据库存储,这样每个微服务的数据接口访问并不需要做很多变化,可以达成快速适配。
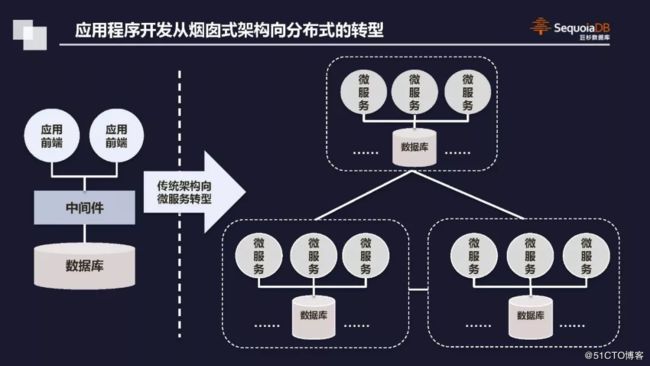
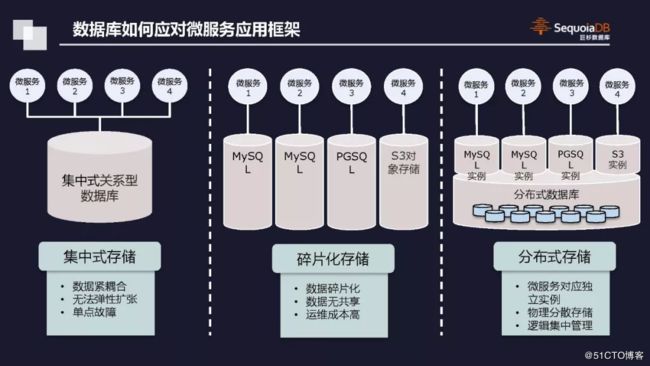
但相对之下也有很多不足,比方说数据集中存储在后端数据库中,数据的解耦合对每个微服务都有影响,分别是数据读取本身以及资源,毕竟数据访问的模式有差别,需求不同。此外在集中存储后,数据的弹性扩张出现问题。毕竟微服务的模式对数据扩张并不排斥,但存储不行,不弹性没商量;如果涉及到更换数据库也必然会对所有微服务架构产生干扰。
“应对这种情况,现在主流的玩法是每个微服务都有一个独立存储,这样开发起来比较简单,但同样会带来几方面的问题,例如每个微服务都具备独立数据库存储之后,每个企业都会有成千上百的微服务,如何做到统一治理、统一的数据视图很重要,当然管理成本是个需要前期考量的大问题,避免数据产生严重的碎片化很重要。”他总结道。
这种情况需要什么好办法来解决?通常采用分布式数据库平台。对于上层,对所有微服务体系可以抽象出许多数据库实例,主要用来做接口兼容与转换。在分享中,许建辉提到,如果需要PostgreSQL,就可以创建PostgreSQL数据库实例,S3也是如此。对每个实例来说,底层在一个分布式数据库上所承载的物理机数量,上层并不 “关心”;从数据弹性扩张上来说也完全没有限制。还有一点,在微服务的发展过程中,在数据访问方面,同一份数据的不同业务模型其访问能力是有差异的。
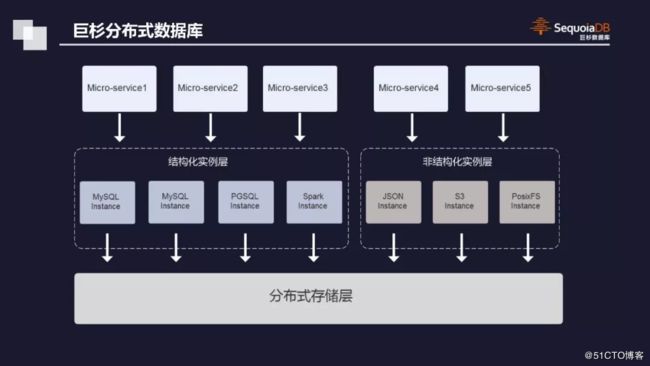
目前巨杉数据库主要面对三大业务场景,第一是联机交易,替换传统数据库,例如MySQL、PostgreSQL、DB2等,可以进行交易场景的处理,让接口完全兼容等;第二就是数据中台,将每一部分业务分享出的数据进行统一管理,主要以大并发的读写为主;此外局势内容管理了,比方说数据分片能力、水平扩张以及弹性伸缩等分区操作。
谈及MySQL接口的兼容,巨杉数据库可以百分百兼容MySQL数据库和PostgreSQL数据库。从兼容层面来讲,首先涉及到语法的兼容,其中包括语法库的兼容;其次是通讯协议,不仅可以做到应用接口的兼容,还要保证体系工具方向,例如第三方MySQL有很多监控、管理和解析分析能力,必然要保证整个体系可以使用;再次就是访问计划,要对访问计划进行兼容,其中包括统计信息的收集、访问结构等。
分布式数据库智能运营平台—TDSQL扁鹊的架构实现与实践
会上,腾讯TDSQL智能运营平台负责人赵东志也应邀来到现场,从云数据库以及分布式数据库更细化的运维场景出发并积极探索。在“分布式数据库智能运营平台—TDSQL扁鹊的架构实现与实践”中,我们初步了解到,TDSQL是腾讯金融云针对金融场景推出的高一致性分布式数据库,基于MySQL基础上进行的二次开发;目前在腾讯内部涉及 到 90%的金融和交易,一般情况下交易类型不允许丢数据,所以腾讯海量数据体制要求其具备足够的扩展能力等。
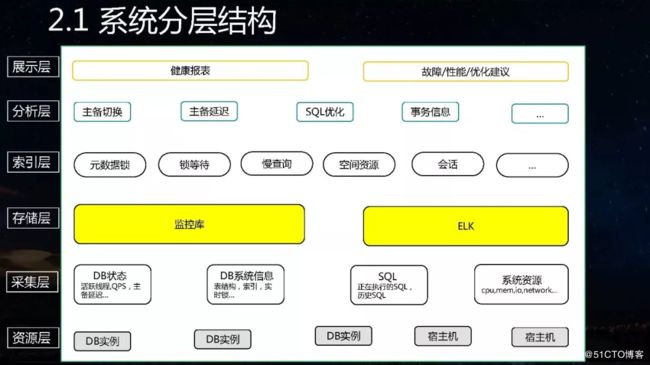
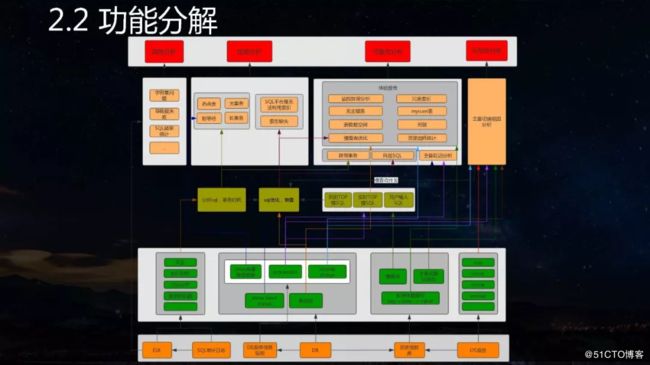
“我们针对数据库云化的痛点构建了扁鹊平台,目的很明确,就是希望这个平台在数据库出现故障时可以告诉我们该怎么解决;如果没有出现故障,是否可以通过一些有效的巡检方式来评估 出现在数据库中的潜在风险等。总之,有了这样一个平台可以让我们将多年的运维经验沉淀到体系中,一定程度上减缓重复劳动的消耗。”赵东志总结道。
如今数据库确实面临很多问题,可以大致区分为可用性问题、性能问题以及可靠性问题等。TDSQL作为金融级数据库,有高可用的配置,例如在每个实例上都会模拟Agent,定期向DB实例中插入数据;此外切换本身对数据是无损的,但在金融场景中并不希望有过多的切换,主要是因为时间上的影响。更加常见的、用户自身对数据库的用法不太合理所导致的问题,一方面是InnoDB并发线程的问题,另外一方面是Binlog的问题。

对此他认为:“如果用户有大量慢查询,他们就会长期循环占用工作线程,结果会导致阻塞到InnoDB。如果用户有大量,例如并发执行100个会话,也会有问题出现;众所周知,MySQL金融场景要求Binlog,数据写入之前,Binlog做主备同步,相当于Binlog和InnoDB要一致,Binlog负责主备同步关系。我一直觉得任何一个数据库无法完美应用各种场景,都有最大的适用范围。如果想更高效发挥数据库的能力,就要遵守数据库的规则。”
分布式搜索和分析引擎—阿里云Elasticsearch架构设计与演进
“谈到Elasticsearch,大家会想到ELK,这是比较流行的组合。Elasticsearch是基于Lucene的开源分布式搜索和分析引擎,可以根据Logstash做数据过滤、修改和收集,其中Kibana主要用于数据展示和报表。此外做日志分析的企业用Elasticsearch也比较多,还 有些客户可能会去做指标数据的分析或者安全类应用的分析。”阿里巴巴搜索技术专家欧阳楚才在“分布式搜索和分析引擎—阿里云Elasticsearch架构设计与演进”的主题中说。

据了解,Elasticsearch用Java语言开发,而使用Java语言都会遇到内存垃圾回收的问题。这样就导致如果应用并发量特别高,每一个请求都会占用一定的内存,如果Java虚拟机处理不及时,很有可能会导致JVM虚拟机的宕机。
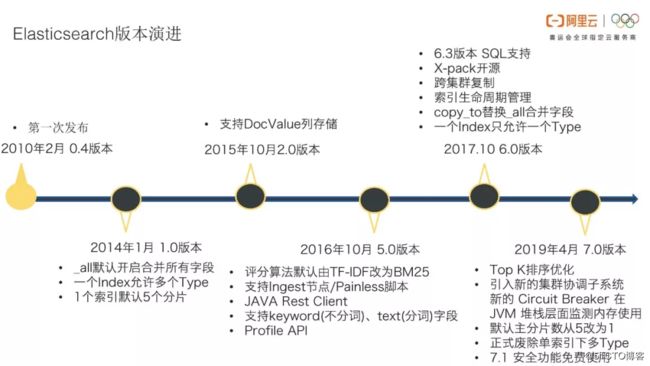
2019年4月,Elasticsearch发布7.0版本加并入了Top K排序,7.0版本后,Elasticsearch本身会监测实际请求的使用量并配置熔断,例如查询请求对JVM使用内存超过40%则直接停止请求等。经常在关系型数据库中做查询或比较耗时的请求,可能会把数据库“拖慢”。如果可以提前识别出这样的请求,提前中断,就可以高效保证其他请求正常运行。伴随技术迭代与升级,在7.1版本里,Elasticsearch公司把商业版特性、安全特性开始免费,而这个特性特别有用,因为原来开源版本没有账号密码和认证,这个版本后把账号密码安全认证功能免费使用起来。
欧阳楚才还补充道,Elasticsearch本身可从一个节点扩展到上百个节点,最开始开发自测阶段可以在本机搭建单节点集群并完成数据的写入和查询,且推送到生产环境,通常会按角色拆分不同角色的节点,分别负责不同的功能模块。更重要的是,Elasticsearch有Master节点,负责集群元数据信息的管理、索引的分片管理;DataNode节点主要负责数据存储和查询;还有一个节点类型叫做客户端节点或者协调服务器节点,负责接收用户的查询请求,把查询和写入请求分发给数据节点。

阿里云从2017年开始与Elasticsearch合作,把Elasticsearch搬到阿里云上提供托管式服务,针对写入、查询做了性能上的调优。如今,阿里云Elasticsearch规模有超过3000个集群,节点数超过1万+,存储数量超过5PB,其最重要的工作是保证数据安全。“对此我们在外面加了一层X-pack安全认证,必须创建用户名密码,通过用户名密码实现访问,另外还可以配置IP段来访问Elasticsearch服务,避免******。”
有时候,很多用户自己搭建Elasticsearch时会遇到一些问题,尤其是新手部署集群时没有专门配置专有主节点,导致集群里的节点通讯出现问题等。他提出,在阿里云上,一般推荐专门配置三个专有主节点来负责数据管理和分片管理。当然不排除有一些金融行业客户对数据的安全要求特别高,要求多个机房上任意一个机房掉电或者光纤被挖断的情况下,服务都可以做到高可用。在易用性方面,阿里云支持X-pack、监控告警、机器学习等功能。“管理Elasticsearch集群实例比较方便,可以自定义安装自研或者开源的插件,也可以用自研的分词。阿里云的安全团队在Kibana上做了很多定制化开发,方便用户使用。”
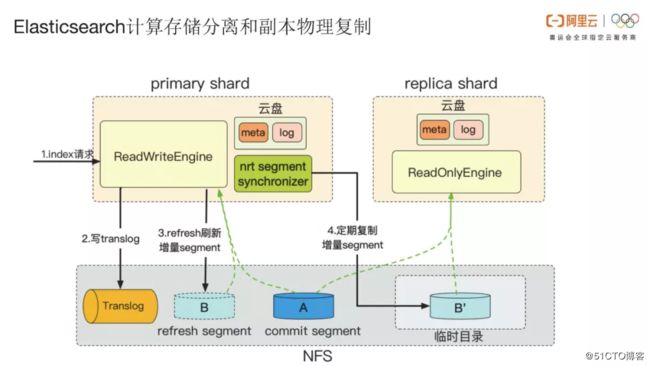
“在Elasticsearch内核方面我们做了很多工作,支持分布式存储读写。在软件层面,我们团队有工程师专门研究Elasticsearch索引分片机制,让所有分片可以弹性扩建或者缩容。基于Elasticsearch做的应用案例,众安保险在今年四月份Elasticsearch发布会上介绍过他们在阿里云上使用Elasticsearch的经验等。”
SequoiaDB分布式集群生态工具及容器化部署实战
技术分享逐渐接近尾声,巨杉技术社区杜蓉带来“SequoiaDB分布式集群生态工具及容器化部署实战”的演讲。她提出,巨杉数据库生态工具中,一种是管理工具,另一种是数据备份、迁移、导入工具。支持MySQL Workbench,以及很多MySQL周边的工具。像Workbench一样,可以查到它对应的表;可以通过图形化进行监控,也可以通过工具对集群的系统信息进行批量修改。


此外关于备份,分别涉及到数据库集的备份、集群级备份和文件系统级备份三种。所谓集群级备份,设有集群备份的指令,根据指令选择全量备份还是增量备份;此外集群级备份的数据量比较大。复制方面,异步复制比较简单,支持的实例比较多,可以用MySQL、DB2、Informix、Oracle等,用自身导入到处工具;准同步复制,MySQL用自己的工具把日志实施写入管道中,通过ApacheStorm做标准化的修改,修改成DML或者DDL命令。

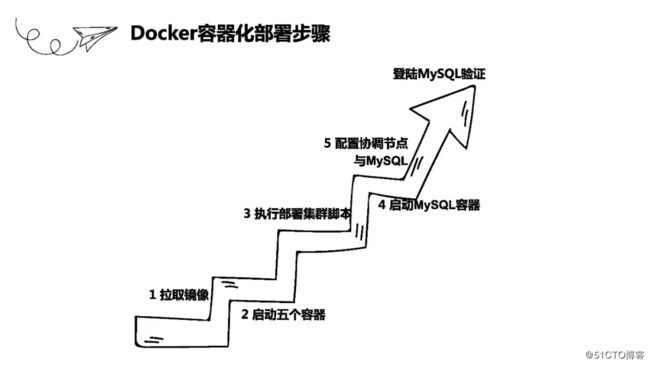
另外,杜蓉还在现场为开发者们列举了三种安装数据库的方式:首先就是安装包,直接安装在机器上;其次就是通过VMWare导入虚拟机镜像;另外就是Docker镜像等。
一键直达:巨杉Tech | SequoiaDB Docker镜像使用教程
尽管针对云时代的数据库架构设计与演进精彩技术分享已暂时告一段落,但关于面对业务及应用的“云原生化”,数据库技术究竟面临了怎样的挑战及发展趋势的系列问题探讨依旧在火热进行中,敬请继续关注巨杉TechDay技术沙龙的后续活动。
PS:关注公众号,发送“0721”,或按图示操作,即可获取PPT~