三次握手四次挥手
半连接池: 限制的是同一时刻的请求数,而非连接数
这是三次握手

syn_sent是客户端发送请求时的状态
listen是服务端一开始的接听状态
syn_rcvd是服务端收到请求后的状态
established是客户端建立连接后的状态(客户端到服务端这端的管道建立)
eatablished是服务端建立连接后的状态(服务端到客户端这端的管道建立)
seq = x 请求的时候附带的序列号(暗号)
ack = x+1 是回复请求, 并把刚刚拿到的序列号+1
四次挥手

C/S B/S
client<---基于网络通信--->server
browser<---基于网络通信--->server
server端(服务端)必须满足的条件:
1、稳定运行(网络、硬件、操作系统、服务端应用软件),对外一直提供服务
2、服务端必须绑定一个固定的地址什么是互联网
两大要素:
1、底层的物理连接介质,是为通信铺好道路的
2、一套统一的通信标准---》互联网通信协议
互联网协议就是计算机界的英语自定义协议(后面将会有自定义报头解决tcp协议的粘包现象)
任何一种通信协议都必须包含两部分:
1 报头:必须是固定长度(如果不固定长度,会有粘包现象)
2 数据: 数据可以用字典的形式来传.比如 数据的名字,大小,内容,描述标识地址的方式
ip+mac就能标识全世界范围内独一无二的一台计算机
ip+mac+port就能标识全世界范围内独一无二的一个基于网络通信的应用软件
url地址:标识全世界范围内独一无二的一个资源
DHCP 默认端口是 67
DNS 默认端口 53为何建立连接要三次而断开连接却需要四次
三次握手是为了建立连接,建立连接时并没有数据产生
四次挥手断开连接是因为客户端与服务端已经产生了数据交互,
这时客户端发送请求只断开了客户端与服务端的连接,
而服务端说不定还有别的数据没有传送完毕,所有一定要四次为何tcp协议是可靠协议,而udp协议是不可靠协议
tcp调用的操作系统,操作系统发出数据,接受到对方传来的确认信息时才会清空数据
优点: 数据安全 缺点: 工作效率低
udp是直接发送, 发完就删
优点: 效率高 缺点: 数据不安全-
为何tcp协议会有粘包问题?
因为tcp想优化效率,里面有个叫nagle算法.这个算法规定了tcp协议在传输数据的时候会将数据较小,传输间隔较短的多条数据合并成一条发送
而tcp是通过操作系统来发送数据的,操作系统想什么时候发就什么时候发,应用层管不到操作系统, tcp把数据交给操作系统是告诉了操作系统一件事,让操作系统把数据较小,传输间隔较短的多条数据合并成一条发送.就造成了粘包现象模块补充:strcuct模块
import struct import json header_dic={ 'filename':'a.txt', 'total_size':11112313123212222222222222222222222222222222222222222222222222222221111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111131222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222223, 'hash':'asdf123123x123213x' } header_json=json.dumps(header_dic) #将字典序列化成字符串 header_bytes=header_json.encode('utf-8') #转换成bytes obj=struct.pack('i',len(header_bytes)) #用i模式固定长度(固定的长度为4 print(obj,len(obj)) res=struct.unpack('i',obj) # 用i模式解开obj print(res) 输出结果如下: 507 b'\xfb\x01\x00\x00' 4 (507,)模拟ssh远程执行命令
客户端
from socket import *
import struct
import json
phone = socket(AF_INET, SOCK_STREAM)
phone.connect(('127.0.0.1', 8080))while True:
cmd = input(">>>>").strip()
if not cmd:
continue
phone.send(cmd.encode('utf-8'))dahler_len = struct.unpack('i', phone.recv(4))[0] # 先接收报头长度 dahler_bytes = phone.recv(dahler_len) # 在接收bytes类型的字典 dahler_str = dahler_bytes.decode('utf-8') dahler_dic = json.loads(dahler_str) # 把bytes类型的字典转换成字典,通过字典拿到自己想要的 total_size = dahler_dic['total_size'] # 接受的文件总大小 recv_size = 0 # 接收默认值 为0 res = b'' # 拼接 while recv_size < total_size: # 结束条件 data = phone.recv(1024) res += data recv_size += len(data) print(res.decode('gbk'))
服务端
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 建立服务器
phone.getsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
phone.bind(('127.0.0.1', 8080)) # 绑定IP,port
phone.listen(5) # 监听状态
while True:
conn, client_addr = phone.accept() # 接发数据
while True:
try:
data = conn.recv(1024) # 读收到的文件 最大限制为1024字节
if len(data) == 0:
break
print(data)
boj = subprocess.Popen(
data.decode('utf-8'),
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout_res = boj.stdout.read()
stderr_res = boj.stderr.read()
total_size = len(stderr_res)+len(stdout_res)
haderl_dic = {
'file': 'a.txt',
'total_size': total_size,
'hashlib': 'adasd1dfad311r'
}
haderl_str = json.dumps(haderl_dic) # 用json把字典转换成一个字典形式的字符串
haderl_bytes = haderl_str.encode('utf-8') # 把字符串转换成二进制
conn.send(struct.pack('i', len(haderl_str))) # 先发报头长度
conn.send(haderl_bytes) # 再发报头字典
conn.send(stderr_res) # 在发内容
conn.send(stdout_res)
except ConnectionResetError as e:
print(e)
break
conn.close()进程
- 1、什么是进程
进程指的就是一个正在运行的程序,或者说是程序的运行过程,即进程是一个抽象的概念
进程是起源于操作系统的,是操作系统最核心的概念,操作系统所有其他的概念都是围绕进程展开的
其中就有了多道技术的来由
用进程就是为了实现并发 -
操作系统(现代操作系统):
操作系统是位于计算机硬件于软件之间的控制程序
作用:
1、将硬件的复杂操作封装成简单的接口,给用户或者应用程序使用
2、将多个应用程序对硬件的竞争变的有序 -
进程
一个正在运行的程序,或者说是一个程序的运行过程 -
串行、并发、并行
串行:一个任务完完整运行完毕,才执行下一个
并发:多个任务看起来是同时运行的,单核就可以实现并发
并行:多个任务是真正意义上的同时运行,只有多核才能实现并行 -
多道技术
背景:想要再单核下实现并发(单核同一时刻只能执行一个任务(每起一个进程就会产生一把GIL全局解释器锁))
并发实现的本质就:切换+保存状态
多道技术:
1、空间上的复用=》多个任务共用一个内存条,但占用内存是彼此隔离的,而且是物理层面隔离的
2、时间上的复用=》多个任务共用同一个cpu
切换:
1、遇到io切换
2、一个任务占用cpu时间过长,或者有另外一个优先级更高的任务抢走的cpu开启进程的两种方式
方式一:
from multiprocessing import Process def task(x): print('%s is running' %x) time.sleep(3) print('%s is done' %x) if __name__ == '__main__': # Process(target=task,kwargs={'x':'子进程'}) p=Process(target=task,args=('子进程',)) # 如果args=(),括号内只有一个参数,一定记住加逗号 p.start() # 只是在操作系统发送一个开启子进程的信号 print('主') # 导入from multiprocessing import Process # 相当于在windows系统中调用了CreateProcess接口 # CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。 # p.start() # 只是在操作系统发送一个开启子进程的信号方式二:
from multiprocessing import Process import time class Myprocess(Process): def __init__(self,x): super().__init__() self.name=x def run(self): print('%s is running' %self.name) time.sleep(3) print('%s is done' %self.name) if __name__ == '__main__': p=Myprocess('子进程1') p.start() #p.run() print('主')进程间的内存空间是彼此隔离的
from multiprocessing import Process import time x = 100 def task(): global x x = 0 print('done') if __name__ == '__main__': p = Process(target=task) p.start() time.sleep(500) # 让父进程在原地等待,等了500s后,才执行下一行代码 print(x)进程的方法与属性:
-
join:
让父进程在原地等待,等到子进程运行完毕后(会触发wait功能,将子进程回收掉),才执行下一行代码 - terminate:
终止进程,应用程序给操作系统发送信号,让操作系统把这个子程序干掉 ,至于多久能干死,在于操作系统什么时候执行这个指令 - is_alive:
查看子进程是否存在,存在返回True,否则返回False - os.getpid:
导入os模块,查看自己的门牌号 - os.getppid:
导入os模块,查看父的门牌号 -
current_process().name:
导入from multiprocessing import Process,current_process
查看子进程的名字
主进程等子进程是因为主进程要给子进程收尸
进程必须等待其内部所有线程都运行完毕才结束孤儿进程:
在父进程被干掉的情况下会编程孤儿进程,无害,会被孤儿院((linux的孤儿院)init)回收
僵尸进程:父进程没死,子进程死了,这时候的子进程就是僵尸进程
正常情况下无害(会调用wait()方法进行回收操作), 父进程无限循环,且不被回收的情况下会无限制的生成子进程从而占用大量的操作系统资源
当操作系统被大量僵尸进程占满内存后,操作系统就无法在启动其他的程序实例:
from multiprocessing import Process,current_process import time def task(): print('子进程[%s]运行。。。。' %current_process().name) time.sleep(2) if __name__ == '__main__': p1=Process(target=task,name='子进程1') p1.start() # print(p1.is_alive()) # p1.join() # print(p1.is_alive()) p1.terminate() # 终止进程,应用程序给操作系统发送信号,让操作系统把这个子程序干掉 # 至于多久能干死,在于操作系统什么时候执行这个指令 time.sleep(1) print(p1.is_alive()) # 查看子进程是否存在,有返回值. True则存在,False则不存在 print('主')## 守护进程 -
1、守护进程
守护进程其实就是一个“子进程”
守护进程会伴随主进程的代码运行完毕后而死掉
进程:
当父进程需要将一个任务并发出去执行,需要将该任务放到一个子进程里
守护:
当该子进程内的代码在父进程代码运行完毕后就没有存在的意义了,就应该
将该子进程设置为守护进程,会在父进程代码结束后死掉
实例:
from multiprocessing import Process
import time,osdef task(name): print('%s is running' %name) time.sleep(3) if __name__ == '__main__': p1=Process(target=task,args=('守护进程',)) p2=Process(target=task,args=('正常的子进程',)) p1.daemon = True # 一定要放到p.start()之前 p1.start() p2.start() print('主')互斥锁
-
互斥锁:可以将要执行任务的部分代码(只涉及到修改共享数据的代码)变成串行
实例
from multiprocessing import Process,Lock # Lock 互斥锁模块 import json import os import time import random def check(): time.sleep(1) # 模拟网路延迟 with open('db.txt','rt',encoding='utf-8') as f: dic=json.load(f) print('%s 查看到剩余票数 [%s]' %(os.getpid(),dic['count'])) def get(): with open('db.txt','rt',encoding='utf-8') as f: dic=json.load(f) time.sleep(2) if dic['count'] > 0: # 有票 dic['count']-=1 time.sleep(random.randint(1,3)) with open('db.txt','wt',encoding='utf-8') as f: json.dump(dic,f) print('%s 购票成功' %os.getpid()) else: print('%s 没有余票' %os.getpid()) def task(mutex): # 查票 check() #购票 mutex.acquire() # 互斥锁不能连续的acquire,必须是release以后才能重新acquire get() mutex.release() # 关闭互斥锁 # with mutex: # 开启与关闭互斥锁一种简单的写法 # get() if __name__ == '__main__': mutex=Lock() for i in range(10): p=Process(target=task,args=(mutex,)) p.start()
IPC机制:进程间通信,有两种实现方式
1、pipe:管道(前面已经说过)
2、queue:pipe+锁
from multiprocessing import Queue
q=Queue(3) #先进先出
#注意:
#1、队列占用的是内存空间,默认是与内存同一大小
#2、不应该往队列中放大数据,应该只存放数据量较小的消息
q.put('first')
q.put({'k':'sencond'})
q.put(['third',])
# q.put(4) # 如果前面的没有被取走,会一直等待,直到前面有一个数据被取走才会把这个数据放进去
print(q.get())
print(q.get())
print(q.get())
print(q.get()) # 取, 如果队列中没有就会一直等待,直到有数据进入队列中,才会取走-
了解点
q=Queue(3) #先进先出
# q.put('first',block=True,timeout=3) # q.put({'k':'sencond'},block=True,timeout=3) # q.put(['third',],block=True,timeout=3) # print('===>') # # q.put(4,block=True,timeout=3) # # # print(q.get(block=True,timeout=3)) # print(q.get(block=True,timeout=3)) # print(q.get(block=True,timeout=3)) # print(q.get(block=True,timeout=3)) # q=Queue(3) #先进先出 # q.put('first',block=False,) # q.put({'k':'sencond'},block=False,) # q.put(['third',],block=False,) # print('===>') # # q.put(4,block=False,) # 队列满了直接抛出异常,不会阻塞 # # print(q.get(block=False)) # print(q.get(block=False)) # print(q.get(block=False)) # print('get over') # print(q.get(block=False)) # q=Queue(3) #先进先出 q.put_nowait('first') #q.put('first',block=False,) q.put_nowait(2) q.put_nowait(3) # q.put_nowait(4) # 队列满了不会等待,直接抛出异常 print(q.get_nowait()) print(q.get_nowait()) print(q.get_nowait()) print(q.get_nowait()) # 队列里没有数据了不会等待,直接抛出异常生产者与消费者模型
-
1 什么是生产者消费者模型
生产者:比喻的是程序中负责产生数据的任务
消费者:比喻的是程序中负责处理数据的任务生产者->共享的介质(队列)<-消费者 -
2 为何用
实现了生产者与消费者的解耦和,生产者可以不停地生产,消费者也可以不停地消费
从而平衡了生产者的生产能力与消费者消费能力,提升了程序整体运行的效率什么时候用? 当我们的程序中存在明显的两类任务,一类负责产生数据,另外一类负责处理数据 此时就应该考虑使用生产者消费者模型来提升程序的效率实例:
from multiprocessing import Queue,Process
import time
import os
import randomdef producer(q):
for i in range(10):
res='包子%s' %i
time.sleep(random.randint(1,3))往队列里丢
q.put(res) print('\033[45m%s 生产了 %s[0m' %(os.getpid(),res)) q.put(None)def consumer(q):
while True:
#从队列里取走
res=q.get()
if res is None:break
time.sleep(random.randint(1,3))
print('\033[46m%s 吃了 %s[0m' %(os.getpid(),res))if name == 'main':
q=Queue()生产者们
p1=Process(target=producer,args=(q,)) # 消费者们 c1=Process(target=consumer,args=(q,)) p1.start() c1.start() print('主')线程
-
什么是线程
进程其实不是一个执行单位,进程是一个资源单位
每个进程内自带一个线程,线程才是cpu上的执行单位如果把操作系统比喻为一座工厂 在工厂内每造出一个车间===》启动一个进程 每个车间内至少有一条流水线===》每个进程内至少有一个线程 线程=》单指代码的执行过程(每个进程里都有一个线程) 进程-》资源的申请与销毁的过程(向操作系统申请内存空间)开启线程的两种方式
方法一
from threading import Thread import time def task(name): print('%s is running' %name) time.sleep(3) print('%s is done' %name) if __name__ == '__main__': t=Thread(target=task,args=('子线程',)) t.start() print('主')方法二
from threading import Thread
import timeclass Mythread(Thread):
def run(self):
print('%s is running' %self.name)
time.sleep(3)
print('%s is done' %self.name)if name == 'main':
t=Mythread()
t.start()
print('主')线程VS进程
1、 内存共享or隔离 多个进程内存空间彼此隔离 同一进程下的多个线程共享该进程内的数据 2、创建速度 造线程的速度要远远快于造进程1、线程的开启速度快
from threading import Thread
from multiprocessing import Process
import timedef task(name):
print('%s is running' %name)
time.sleep(3)
print('%s is done' %name)if name == 'main':
t=Thread(target=task,args=('子线程',))t=Process(target=task,args=('子进程',))
t.start() print('主')2、同一进程下的多个线程共享该进程内的数据
from threading import Thread
import timex=100
def task():
global x
x=0if name == 'main':
t=Thread(target=task,)
t.start()time.sleep(3)
t.join() print('主',x)输出结果为: 主 0
线程对象的其他方法和属性:进程的方法线程也都有
#主进程等子进程是因为主进程要给子进程收尸
#进程必须等待其内部所有线程都运行完毕才结束
from threading import Thread
import timedef task(name):
print('%s is running' %name)
time.sleep(3)
print('%s is done' %name)
if name == 'main':
t=Thread(target=task,args=('子线程',))
t.start()
print('主')
输出结果:
子线程 is running
主
子线程 is done守护线程:守护线程会在本进程内所有非守护的线程都死掉了才跟着死,即:守护线程其实守护的是整个进程的运行周期(进程内所有的非守护线程都运行完毕)
实例如下:
from threading import Thread import time def foo(): print(123) time.sleep(3) print("end123") def bar(): print(456) time.sleep(1) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------") 输出结果: ''' 123 456 main------- end456 '''互斥锁:将多个任务对共享数据修改的那一部分代码由并发变成“串行”,牺牲了效率保证数据安全
from threading import Thread,Lock
import timemutex=Lock()
x=100
def task():
global xmutex.acquire() # 加锁
temp=x time.sleep(0.1) x=temp-1 # mutex.release() # 释放锁if name == 'main':
t_l=[]
start=time.time()
for i in range(100):
t=Thread(target=task)
t_l.append(t)
t.start()for t in t_l: t.join() stop=time.time() print(x,stop-start) #打印结果为 99 0.1123046875 #这说明同一进程下的线程数据是共享的 #加了锁后 x = 0死锁现象与递归锁
-
死锁现象:
from threading import Thread,Lock,active_count
import timemutexA=Lock() # 锁1
mutexB=Lock() # 锁2class Mythread(Thread):
def run(self):
self.f1()
self.f2()def f1(self): mutexA.acquire() print('%s 拿到A锁' %self.name) mutexB.acquire() print('%s 拿到B锁' %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 拿到B锁' %self.name) time.sleep(1) mutexA.acquire() print('%s 拿到A锁' %self.name) mutexA.release() mutexB.release()if name == 'main':
for i in range(10):
t=Mythread()
t.start()
#print(active_count())
#死锁现象: 线程1拿到一把锁,线程2也拿到一把锁,线程1想要线程2的锁,线程2想要线程1的锁,于是就阻塞了,这说明 2把锁不能同时acquire -
解决方案
from threading import Thread,Lock,active_count,RLock
import time# mutexA=Lock() # mutexB=Lock() obj=RLock() #递归锁的特点:可以连续的acquire.其本质其实还是一把锁,只是把一把锁转换成了2把而已 mutexA=obj mutexB=obj class Mythread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print('%s 拿到A锁' %self.name) mutexB.acquire() print('%s 拿到B锁' %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 拿到B锁' %self.name) time.sleep(1) mutexA.acquire() print('%s 拿到A锁' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=Mythread() t.start() # print(active_count())信号量
-
信号量:限制的是同一进程下并发执行的任务数(其本质也是锁,同一时间可以运行多个任务)
而互斥锁同一时间只能运行一个任务# 信号量是控制同一时刻并发执行的任务数 from threading import Thread,Semaphore,current_thread import time,random sm=Semaphore(5) # 控制同一个时刻并发运行的多个任务个数,默认是电脑的CPU数量 * 5 def task(): with sm: # with sm 其意思是:sm.acquire() (上锁) sm.release()(解锁) print('%s 正在上厕所' %current_thread().name) time.sleep(random.randint(1,4)) if __name__ == '__main__': for i in range(20): t=Thread(target=task) t.start() #输出结果是一次先有5个任务执行,然后完成几个就在来几个GIL全局解释器锁
-
1 什么是GIL
GIL本质就是一把互斥锁,那既然是互斥锁,原理都一样,都是让多个并发线程同一时间只能
有一个执行
即:有了GIL的存在,同一进程内的多个线程同一时刻只能有一个在运行,意味着在Cpython中
一个进程下的多个线程无法实现并行===》意味着无法利用多核优势(运算)
但不影响并发的实现GIL可以被比喻成执行权限,同一进程下的所以线程 要想执行都需要先抢执行权限 - 2、为何要有GIL
因为Cpython解释器自带垃圾回收机制不是线程安全的,也就是说如果没有GIL的情况下,在给一个值
赋值的情况下如果被垃圾回收机制回收了,那就会出现错误 - 3 有两种并发解决方案:
多进程:计算密集型
多线程:IO密集型(因为我们以后用的都是基于网络通信的套接字,而基于网络通信就存在大量IO,于是我们用的最多的都是多线程的方式) -
IO密集型实例:
from multiprocessing import Process
from threading import Thread
import os,time
def work1():
time.sleep(5)def work2(): time.sleep(5) def work3(): time.sleep(5) def work4(): time.sleep(5) if __name__ == '__main__': l=[] # print(os.cpu_count()) #本机为4核 start=time.time() #p1=Process(target=work1) # 多进程 #p2=Process(target=work2) #p3=Process(target=work3) #p4=Process(target=work4) p1=Thread(target=work1) # 多线程 p2=Thread(target=work2) p3=Thread(target=work3) p4=Thread(target=work4) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() stop=time.time() print('run time is %s' %(stop-start)) #run time is 5.162574291229248 # run time is 5.002141714096069 -
计算密集型实例:
from multiprocessing import Process
from threading import Thread
import os,time
def work1():
res=0
for i in range(100000000):
res*=idef work2(): res=0 for i in range(100000000): res*=i def work3(): res=0 for i in range(100000000): res*=i def work4(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': l=[] # print(os.cpu_count()) #本机为4核 start=time.time() # p1=Process(target=work1) # 开启多进程 # p2=Process(target=work2) # p3=Process(target=work3) # p4=Process(target=work4) p1=Thread(target=work1) # 开启多线程 p2=Thread(target=work2) p3=Thread(target=work3) p4=Thread(target=work4) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() stop=time.time() print('run time is %s' %(stop-start)) #6.484470367431641(多线程的运行时间) # run time is 17.391708850860596 # 多进程的运行时间定时器: 多久时间后运行
实例如下:
from threading import Timer,current_thread def task(x): print('%s run....' %x) print(current_thread().name) if __name__ == '__main__': t=Timer(3,task,args=(10,)) # 第一个参数指定的是多久以后执行,第二个参数是执行的函数 # 第三个是函数需要传参的参数(括号里必须是元组) t.start() print('主')线程queque:import queue
-
队列:先进先出
q=queue.Queue(3)
q.put(1)
q.put(2)
q.put(3)print(q.get()) print(q.get()) print(q.get()) - 堆栈:先进后出
q=queue.LifoQueue()
q.put(1)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
print(q.get()) -
优先级队列:优先级高先出来,数字越小,优先级越高
q=queue.PriorityQueue()
q.put((3,'data1'))
q.put((-10,'data2'))
q.put((11,'data3'))print(q.get()) print(q.get()) print(q.get()) 输出结果如下: (-10, 'data2') (3, 'data1') (11, 'data3')进程池与线程池
池的功能是限制启动的进程数或线程数,
什么时候应该限制???
当并发的任务数远远超过了计算机的承受能力时,即无法一次性开启过多的进程数或线程数时
就应该用池的概念将开启的进程数或线程数限制在计算机可承受的范围内同步:提交完任务后(用'串行'的方式运行)就在原地等待,直到任务运行完毕后拿到任务的返回值,再继续运行下一行代码
实例如下:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os
import time
import randomdef task(n): print('%s run...' %os.getpid()) time.sleep(10) return n**2 def parse(res): print('...') if __name__ == '__main__': pool=ProcessPoolExecutor(4) # pool.submit(task,1) # pool.submit(task,2) # pool.submit(task,3) # pool.submit(task,4) l=[] for i in range(1,5): future=pool.submit(task,i) l.append(future) # print(future) # print(future.result()) pool.shutdown(wait=True) #shutdown关闭进程池的入口 for future in l: # print(future.result()) parse(future.result()) print('主')异步:提交完任务(绑定一个回调函数)后根本就不在原地等待,直接运行下一行代码,等到任务有返回值后会自动触发回调函数
-
用多进程实现异步:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import os,time,randomdef task(n): print('%s run...' %os.getpid()) time.sleep(5) return n**2 def parse(future): time.sleep(1) res=future.result() print('%s 处理了 %s' %(os.getpid(),res)) if __name__ == '__main__': pool=ProcessPoolExecutor(4) start=time.time() for i in range(1,5): future=pool.submit(task,i) future.add_done_callback(parse) # parse会在futrue有返回值时立刻触发, # 并且将future当作参数传给parse, # 由主进程来回调函数,运行时间为 9.163417339324951 pool.shutdown(wait=True) stop=time.time() print('主',os.getpid(),(stop - start)) -
用多线程实现异步:
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from threading import current_thread
import os
import time
import randomdef task(n): print('%s run...' %current_thread().name) time.sleep(5) return n**2 def parse(future): time.sleep(1) res=future.result() print('%s 处理了 %s' %(current_thread().name,res)) if __name__ == '__main__': pool=ThreadPoolExecutor(4) start=time.time() for i in range(1,5): future=pool.submit(task,i) future.add_done_callback(parse) # parse会在futrue有返回值时立刻触发, # 并且将future当作参数传给parse pool.shutdown(wait=True) # 哪个线程有时间了哪个线程就取回调函数,运行时间为 6.003463268280029 stop=time.time() print('主',current_thread().name,(stop - start))协程:只有遇到io才切换到其他任务的协程才能提升单线程的执行效率
-
1、协程只有遇到io才切换到其他任务的协程才能提升
单线程实现并发
在应用程序里控制多个任务的切换+保存状态(协程只有在IO在单线程下切换到另外一个任务才能提升效率)
优点:
应用程序级别切换的速度要远远高于操作系统的切换
缺点:
多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地
该线程内的其他的任务都不能执行了一旦引入协程,就需要检测单线程下所有的IO行为, 实现遇到IO就切换,少一个都不行,因为一旦一个任务阻塞了,整个线程就阻塞了, 其他的任务即便是可以计算,但是也无法运行了 -
2、协程序的目的:
想要在单线程下实现并发
并发指的是多个任务看起来是同时运行的
并发=切换+保存状态
实例: 协程 服务端: pip3 install gevent
from gevent import spawn,monkey;monkey.patch_all() # 相当于给下面的代码都打上标记,就都能识别
from socket import *
from threading import Threaddef talk(conn): while True: try: data=conn.recv(1024) if len(data) == 0:break conn.send(data.upper()) except ConnectionResetError: break conn.close() def server(ip,port,backlog=5): server = socket(AF_INET, SOCK_STREAM) server.bind((ip, port)) server.listen(backlog) print('starting...') while True: conn, addr = server.accept() spawn(talk, conn,) # 起一个协程,只要这个协程不死掉,进程也不会结束 if __name__ == '__main__': g=spawn(server,'127.0.0.1',8080) # 起一个进程 g.join() # 只要这个协程不死掉,进程也不会结束客户端:
from threading import Thread,current_thread
from socket import *
import osdef task(): client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg='%s say hello' %current_thread().name client.send(msg.encode('utf-8')) data=client.recv(1024) print(data.decode('utf-8')) if __name__ == '__main__': for i in range(500): t=Thread(target=task) t.start()IO模型

网络IO:
recvfrom:
wait data:
conn.recv(1024)等待客户端产生数据——》客户端OS--》网络--》服务端操作系统缓存
copy data:由本地操作系统缓存中的数据拷贝到应用程序的内存中send:
也要经历copy data这个过程,从应用程序拷贝到本地操作系统中,在由操作系统
调用网卡基于网络传输给服务端的网卡,传输到服务端的操作系统,对方的操作系统在
从本地操作系统缓存中拷贝数据到应用程序的内存中阻塞IO模型: 网络IO就是阻塞IO
非阻塞IO模型:
用户进程不断的主动询问操作系统数据准备好了没有
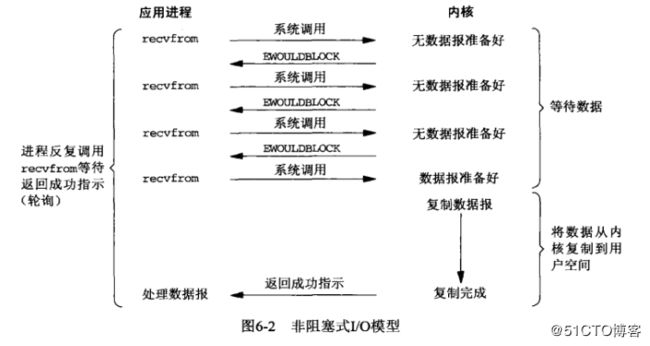
服务端:
from socket import *
import time缺陷在于如果这个列表里有1亿个连接,那么就会让客户明显的感觉到等待
# 对CPU无效的占有率够高 server = socket(AF_INET, SOCK_STREAM) # 绑定协议(tcp) server.bind(('127.0.0.1',8080)) # 绑定IP 和 port server.listen(5) # 半连接池: 限制的是请求数而非连接数 server.setblocking(False) # 让操作系统给一个回复信息 conn_l=[] while True: try: print('总连接数[%s]' % len(conn_l)) conn,addr=server.accept() conn_l.append(conn) # 把每个建立的连接放到列表里面 except BlockingIOError: # 如果没有数据产生就会报错,所有我们需要用捕捉异常让它不因为报错而停止运行 del_l=[] for conn in conn_l: # 从conn_l列表里遍历出来通讯 try: data=conn.recv(1024) if len(data) == 0: del_l.append(conn) # 把遍历出来断了连接的连接加入到del_l列表里面 continue conn.send(data.upper()) except BlockingIOError: # 需要捕捉异常 pass except ConnectionResetError: # 把遍历出来断了连接的连接加入到del_l列表里面 del_l.append(conn) for conn in del_l: # 遍历del_l列表,把断开的连接一个一个的删除掉 conn_l.remove(conn)客户端:
from socket import *
import osclient=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg='%s say hello' %os.getpid() client.send(msg.encode('utf-8')) data=client.recv(1024) print(data.decode('utf-8'))
多路复用IO模型
当用户进程调用了select,那么整个进程会被block,而同时,操作系统会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从操作系统拷贝到用户进程。
“多路”指的是多个网络连接,“复用”指的是复用同一个线程
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗
利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
服务端:
from socket import *
import select
server = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
server.setblocking(False)
data_dic={}
read_list=[server,]
write_list=[]
print('start....')
while True:
rl,wl,xl=select.select(read_list,write_list,[]) #read_list=[server,conn1,conn2,conn3,conn4]
# print('read_list:%s rl:%s wl:%s ' %(len(read_list),len(rl),len(wl))) #rl=[conn1,conn2]
# select的第四个参数指定的是时间,这个时间指的是在这个时间内如果没有消息过来一样也会执行下一行代码
# 但是这样的运行毫无意义.
# select给操作系统发送一个请求, 操作系统去遍历所有连接
# 如果有select就会拿到, 然后运行下一行代码, 如果没有就会原地阻塞
for sk in rl:
if sk == server:
conn,addr=sk.accept() # 建立一个连接
read_list.append(conn) # 放到列表里面
else:
# sk.recv(1024)
# print(sk)
data=sk.recv(1024) # 有消息的列表,读消息
write_list.append(sk) # 把消息放到要读的空列表里面.
# 因为如果文件过大就会让用户感觉到明显的等待,因为内存空间只有那么大,超过内存空间的大小就会一点点的读
data_dic[sk]=data # 用k:vlua的形式把消息存起来
for sk in wl:
sk.send(data_dic[sk].upper()) # 循环消息列表,通过k拿到消息返回给客户端
data_dic.pop(sk) # 删除字典里的k
write_list.remove(sk) # 删除列表里的消息.因为这个消息已经读过了客户端:
from socket import *
import os
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg='%s say hello' %os.getpid()
client.send(msg.encode('utf-8'))
data=client.recv(1024)
print(data.decode('utf-8'))异步IO
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从操作系统的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,操作系统会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,操作系统会给用户进程发送一个signal,告诉它read操作完成了
IO分两阶段:
1.数据准备阶段
2.内核空间复制回用户进程缓冲区阶段