https://zhuanlan.zhihu.com/p/30149571
这篇文章是介绍用R做信用(申请)评分卡,包含了常用的数据处理方法,代码快为如下部分
1. 数据导入
2.数据清洗
3.特征筛选
4.模型训练
5.效果评估
6.评分卡转化
Step 1. 数据导入
示例数据选用klaR包中的GermanCredit,数据太干净了就人为加了少量异常值以便演示数据处理。变量credit_risk代表是否违约 -- ‘good’ 未违约, ‘bad’ 违约。
# 1.数据导入
df <- read.csv("C:/Users/YXS/Desktop/GermanCredit.csv", stringsAsFactors = F)
# tips: 设置参数strngsAsFactor可防止字符型被自动转为因子型,方便数据处理
## 若从txt导入 read.table()
## 若从数据库直接读取 library(RJDBC); dbConnect()

Step 2. 数据探查与清洗
# 2.0 数据粗探
head(df) # 查看前5行
str(df) # 查看各变量类型
summary(df) # 查看各变量的基础统计信息
# 变量重赋值 -- credit_risk取值为字符型,出于习惯将它转化为y标签值0,1
df$credit_risk <- ifelse(df$credit_risk == 'bad', 1, 0) # credit_risk是否违约
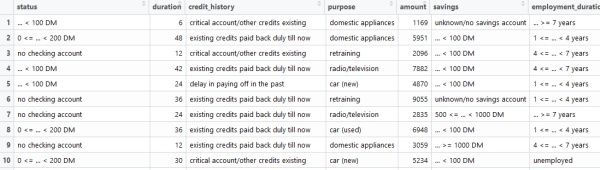
# 2.1检查缺失值
na_num <- apply(df, 2, function(x) sum(is.na(x))) # 检查每列的缺失情况
sort(na_num, decreasing = T) / nrow(df) # 缺失百分比
subset(df, is.na(job)) # 发现job变量有缺失,具体看下存在缺失的观测值
# 也可以加载sqldf以sql的方式做数据处理与探查工作,减少学习成本
# library(sqldf); sqldf('select * from df where job is null ')
# 常用的缺失值可视化拓展包有VIM,mice
# library(VIM); aggr(df)
# library(mice) ; md.pattern(df)
# 2.2 缺失值处理
## 缺失值赋众数 -- 将job有缺失的值附众值
df[is.na(df$job), 'job'] <- names(table(df$job)[which.max(table(df$job))])
sum(is.na(df$job))
## 其它常用缺失值处理方法:
## 缺失值赋均值
#df[which(is.na(df$age), 'age')] <- mean(df$age, na.rm=T) # na.rm
## 缺失值赋特定值
# for(i in 1:ncol(df)){
# if(is.character(df[,i])){
# df[is.na(df[ ,i]), i] <- "missing"
# }
# if(is.numeric(df[,i])){
# df[is.na(df[ ,i]), i] <- -9999
# }
# }
## 缺失值插补法
# library(DMwR)
# DMwR::knnImputation(data, k = 10, scale = T, meth = "weighAvg", distData = NULL)
# library(mice)
# mice(data, m=5)
# 2.3 查看特征取值个数
val_num <- data.frame() # 建立空矩阵用于存储后续数据
for (i in 1:ncol(df)){
t1 <- length(unique(df[,i])) # dplyr::n_distinct()
t2 <- names(df)[i]
val_num <- rbind(data.frame(variable = t2, num = t1, type = mode(df[,i]),
stringsAsFactors = F), val_num)
}
rm(i,t1,t2); gc() # garbage collection
## tips:在数据量大的情况下循环非常占资源,R中的循环基本都能用apply做向量化运算。为便于理解本文均采用for循环写法。
# apply(df, 2, function(x) length(unique(x))) 可取代上面的for循环
# 2.3.1 转换数据类型 -- 发现某些离散型变量的数据类型为数值型,将这些转为字符型处理
convert_cols <- val_num[which(val_num$num < 5),'variable']
df[,convert_cols] <- sapply(df[,convert_cols], as.character)
str(df[, val_num[val_num$num < 5, 'variable']])
# 2.4 查看数据分布
# 2.4.1 连续型变量查看各变量分位数
num_distribution <- c(); temp_name <- c()
for(i in names(df)){
if(is.numeric(df[,i])){
temp <- quantile(df[,i], probs=c(0,0.10,0.25,0.50,0.75,0.90,0.95,0.98,0.99,1), na.rm = T, names = T)
temp_name <- c(temp_name, i)
num_distribution <- rbind(num_distribution, temp)
}
}
row.names(num_distribution) <- temp_name
num_distribution <- as.data.frame(num_distribution)
num_distribution$variable <- temp_name
rm(i, temp, temp_name)
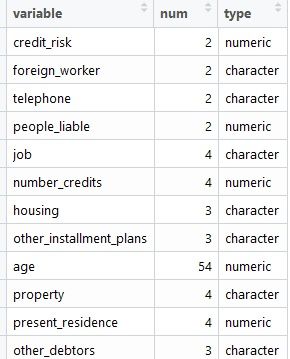
# 2.4.2 离散型变量查看各取值占比
char_distribution <- data.frame(stringsAsFactors = F)
for(i in names(df)){
if(!is.numeric(df[, i])){
temp <- data.frame(Variable = i, table(df[, i]), stringsAsFactors = F)
char_distribution <- rbind(char_distribution, temp)
}
}
char_distribution$Per <- char_distribution$Freq / nrow(df)
rm(i,temp)
# 异常值删除 -- 在变量分布中发现age最小值为0为异常值,这边做删除处理
age_0 <- subset(df, age==0); age_0
df <- df[- which(df$age==0), ]
rm(age_0)
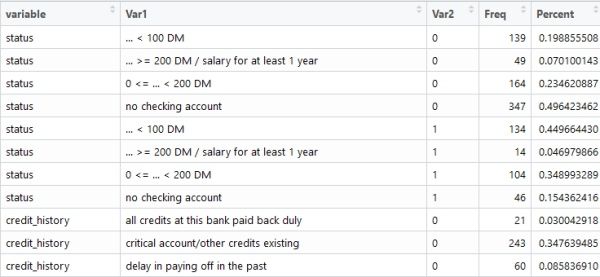
# 2.4.3 查看自变量与应变量联合分布
xy_distribution <- data.frame()
for(i in names(df)){
if(!is.numeric(df[, i])){
temp <- data.frame(variable = i, table(df[, i], df$credit_risk), stringsAsFactors = F)
xy_distribution <- rbind(xy_distribution, temp)
}
}
xy_distribution <- transform(xy_distribution, Percent= xy_distribution$Freq / ifelse(xy_distribution$Var2 == 0, 699, 298))
rm(i,temp)


Step 3. 变量离散化(分箱)
主要用smbinning包的smbinnig进行分箱
library(smbinning)
# 3.1 字符转因子型 -- smbinning包要求离散型变量的数据类型为字符型
for ( i in names(df)){
if(i != 'credit_risk' & is.character(df[,i])) {
df[, i] <- as.factor(df[, i])}
}
str(df)
# 3.2 分箱
data_bak <- df
df$credit_risk <- as.numeric(df$credit_risk) # 要求y值为数值型
bin_iv <- data.frame(); bin_var <- c()
var_name <- names(df)
for(i in var_name) {
if(is.numeric(df[,i]) & i != 'credit_risk'){
bin_tbl <- smbinning(df, y='credit_risk', x= i) -- 连续变量用smbinning分箱
bin_iv <- rbind(bin_iv, data.frame(bin_tbl$ivtable, variable=i))
new_var <- paste('bin',i, sep='_')
bin_var <- c(bin_var, new_var)
df <- smbinning.gen(df, bin_tbl, new_var) # 生成离散后的数据
}
if(is.factor(df[,i])){
# 离散变量用smbinning.factor,主要是计算woe、iv值
bin_tbl <- smbinning.factor(df, y='credit_risk', x= i)
bin_iv <- rbind(bin_iv, data.frame(bin_tbl$ivtable, variable=i))
new_var <- paste('bin',i, sep='_')
bin_var <- c(bin_var, new_var)
df <- smbinning.factor.gen(df, bin_tbl, new_var) # 生成离散后的数据
}
}
rm(i, new_var);
write.csv(bin_iv, file='C:/Users/YXS/Desktop/bin_iv.csv') # 存储分箱信息
save(df, file='C:/Users/YXS/Desktop/data_after_bin.rdata') # 数据存储备份
df<- df[, c('credit_risk', bin_var)]
rm(bin_tbl, data_bak, var_name)

Step 4. 特征筛选
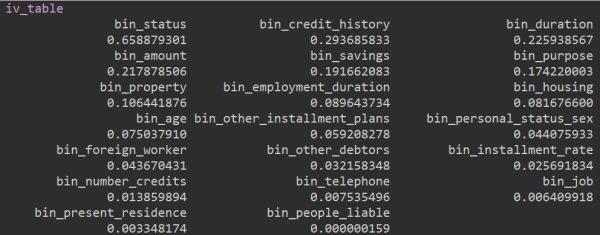
# 4.1 通过IV值筛选
library(klaR)
woe_model <- woe(as.factor(df$credit_risk)~., data=df, zeroadj =0.5) # 计算各段woe值
iv_table <- sort(woe_model$IV, decreasing = T) # woe_model$IV返回IV值,奖序
iv_var <- names(iv_table[iv_table > 0.02]) # 选取iv > 0.02的变量
woe_model <- woe(as.factor(df$credit_risk)~., data = df[, c('credit_risk', iv_var)], zeroadj =0.5, appont =T)
traindata <- predict(woe_model, newdata=df[, c('credit_risk', iv_var)]) # 用woe值代替原来的变量取值
# 4.2 逐步回归筛选
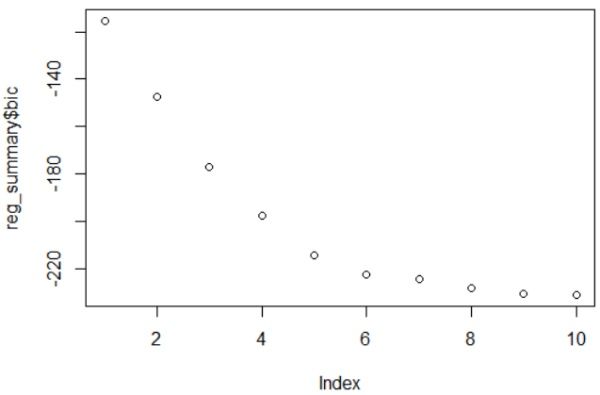
library(leaps)
regfit <- regsubsets(credit_risk~., data = traindata, method = 'back', nvmax = 10) #向后逐步回归
reg_summary <- summary(regfit)
plot(reg_summary$bic) # 9个变量后bic就基本不下降了,选最好的9个变量入模
reg_summary
# 筛选入模变量
feature_in <- c('bin_status', 'bin_credit_history', 'bin_duration'
,'bin_savings','bin_purpose','bin_personal_status_sex',
'bin_other_debtors', 'bin_installment_rate')
feature_in <- paste('woe', feature_in, sep='.')

Step 5. Logistic 模型训练
# 5. 逻辑回归训练
glmodel <- glm(credit_risk~., traindata[,c('credit_risk', feature_in)], family = binomial)
summary(glmodel)
# 5.1 相关性检验
corelation <- cor(traindata[,feature_in])
library(lattice)
levelplot(corelation)
rm(corelation)
# 5.2 VIF 共线性检验
library(car)
vif(glmodel, digits =3 )



Step 6. 模型评估
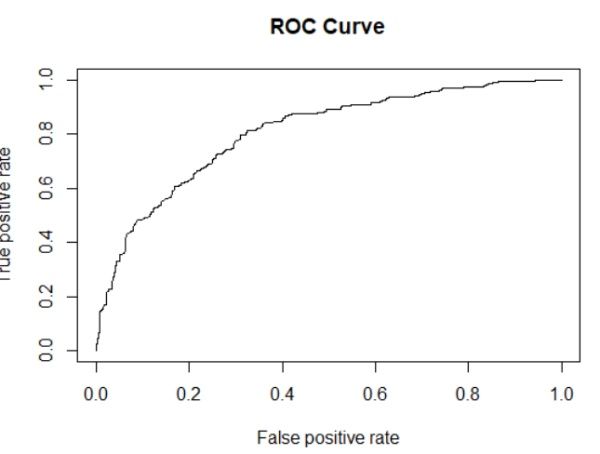
# 6.3 模型评估
# ROC/AUC
pred <- predict(glmodel, newdata = traindata,type = "response")
library(ROCR)
t <- prediction(pred, traindata[, 'credit_risk'])
t_roc <- performance(t, 'tpr', 'fpr')
plot(t_roc)
t_auc <- performance(t, 'auc')
title(main = 'ROC Curve')
# KS 值
ks <- max(attr(t_roc, "y.values")[[1]] - (attr(t_roc, "x.values")[[1]])); print(ks)

Step 7. 制作评分卡
# 7.1 计算factor和offset
# 620 = offset + factor * log(15*2)
# 600 = offset + factor * log(15) # 按好坏比15为600分, 翻一番加20
factor <- 20/log(2) # 比例因子
offset <- 600-factor*log(15) # 偏移量
# 7.2提取所需 woe、逻辑回归系数、截距项、特征个数
glm_coef <- data.frame(coef(glmodel))
NamesWoE <- row.names(glm_coef)[-1] <- gsub('woe.', replacement = '', row.names(glm_coef)[-1])
a = glm_coef[1,1] # 截距
Beta <- glm_coef$coef.glmodel.[-1] # 系数
names(Beta) <- row.names(glm_coef)[-1]; Beta # 系数名
glm_coef$Variables <- row.names(glm_coef)
feature_num <- nrow(glm_coef) - 1 # 特征数目
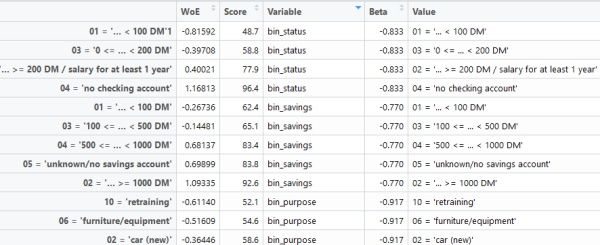
Score_card <- data.frame()
# Score_card <- data.frame(WoE = c(NA), Score = c(NA), Variable = c(NA), Beta = c(1), Band = c(NA))
# Score_card <- na.omit(Score_card) # delte na cases
# 7.3 计算最终评分
for (i in NamesWoE) # 循环变量,计算每个变量取值下的分数
{
WoEEE <- data.frame(woe_model$woe[i])
# 评分公式
Score <- data.frame(-(Beta[i]*WoEEE + a/(feature_num)) * factor + offset/(feature_num))
Temp <- cbind(WoEEE, Score)
Temp$Variable <- i
Temp$Beta <- Beta[i]
Temp$Value <- row.names(Temp)
names(Temp)[1] <- "WoE"
names(Temp)[2] <- "Score"
Score_card <- rbind(Temp, Score_card)
}
rm(i,WoEEE, NamesWoE, feature_num, glm_coef, Temp, Score)
write.table(Score_card, file='C:/Users/YXS/Desktop/Scorecard.csv', sep = ", ", col.names = NA)
数据源与整体code见iking8023/Score-Card