本文首发于 vivo互联网技术 微信公众号
作者:Doug Turnbull
译者:林寿怡
目录:
一、衡量搜索的好坏
二、用机器学习生成 ranking 函数
三、单文档 机器学习排序 (point-wise learning to rank)
四、文档列表方法(LIST-WISE),文档对方法(PAIR-WISE)
五、直接用 w/ListNet 优化列表
六、使用 RankSVM 优化文档对方法
七、RankSVM 与 List-Wise 方法
八、结论
机器学习排序(Learning to rank)将搜索转化为机器学习问题,在本文中,我想找出搜索与其他机器学习问题不同的原因,如何将搜索排名作为机器学习或者是分类和回归问题?我们将通过两种方法,对机器学习排序方法的评估有个直观的认识。
一、衡量搜索的好坏
目标是搜索和经典机器学习问题的根本区别,更具体地说,如何量化搜索的好坏。例如股价预测系统的准确性,取决于我们有多少预测数据是来自真实的公司股价。如果我们预测亚马逊的股价是123.57美元,实际上是125美元,我们会说这非常接近。假设按均值来说,我们的预测跟实际股价的误差在1美元到2美元之间,我们可以认为系统预测的很好。
这种情况下的误差我们称之为残差,即实际值与预测值之间的差异:实际值-预测值。(实际上,残留^2才是最小化,但在这里保持通俗易懂。)
训练期间,回归系统通过如何量化好坏来得到最优解。我们可以尝试公司不同的量化特征,例如员工人数、收入、手头现金、或者其他任何有助于减少股价误差的特征。它可能会使最小二乘回归(least-squares regression)学习为线性公式,例如:股价= 0.01员工人数+0.9收入+0.001*手头现金,作为减少误差的最佳方式。
搜索结果的好坏(或介于两者之间)却完全不一样。股价预测系统完全是为了减少实际值-预测值的误差,但搜索系统是尽量接近搜索查询的理想排序。换句话说,目标是减小理想排序到结果项集合的距离,排序的优先反映出搜索者感知搜索的好坏。
例如,电子商务用户搜索“dress shoes”,我们定义一个粗略的理想排序:
-
Best-selling dress shoes
-
Low-performing dress shoes
-
Other kinds of shoes
- Ladies dresses (if at all)
以此我们可以想象一些场景,并猜测他们距离理想结果有多远。至少需要向“dress shoes”的搜索者在展示衣服前优先展示一些鞋子 - 但这一点都不完美。这就像预测亚马逊的股价是150美元而不是125美元:下面的结果接近吗?
-
A pair of tennis shoes
-
Meh Dress Shoes
- A ladies dress
另一方面,优先于其他鞋子并在best-selling dress shoes前一个位置展示meh dress shoes,这样可能会非常接近,但也并不完美。这可能与预测亚马逊的股价为123美元相当:
-
Meh pair of dress shoes
-
Best-selling pair of dress shoes
- Tennis Shoes
正如你看到的搜索,并不是实际值-预测值,而是尽可能接近每个用户查询的最佳排序。NDCG是一种衡量搜索结果和理想排序差距的指标。其他一些指标衡量搜索结果的好坏各有利弊,这些指标几乎总是取值介于0(最差搜索结果)至1(最好搜索结果)。
此外,这些指标不能仅是纯粹的差异或编辑距离类型的计算。由于用户更关注顶部的搜索结果,因此要获取这些位置需具备优先权。因此,搜索指标通常包括位置偏差,这意味着前几个结果偏离理想时,比底部结果偏离更糟糕,NDCG内置了位置偏差。
虽然有一些可用的指标 ( 例如 ERR,MAP等 ),在本文中我只把 “NDCG”作为真正相关性指标的缩写。
二、用机器学习生成ranking函数
经典的回归问题构建了一个用一组特征直接预测的函数 f。我们尽量减少实际股价- f(公司特征)。机器学习排序的目标是构建不直接预测的ranking函数。相反,它用于排序-我们提供一组理想的顺序作为训练数据,ranking函数需要两个输入,即query查询和document文档,并为每一个查询正确排序的文档分配一个分数。
重述以上一点更多内容:
股市:对于公司x,生成函数f(x),使y - f(x)最小化
搜索:对于文件d,查询q,生成函数f(d,q),当f(d,q)降序排序时,使所有文档的NDCG最大化
我们来看一个粗略的例子,看看我们的意思。作为数据科学家/搜索工程师,我们认为以下查询/文档的特征对我们的电子商务搜索有帮助:
-
商品标题中关键字的TF * IDF分数:titleScore(d,q)
-
商品描述中关键字的TF * IDF分数:descScore(d,q)
- 商品的销量:numSold(d)
机器学习过程可能会得到一个文档评分公式,如:
f(d,q)= 10 titleScore(d,q)+ 2 descScore(d,q)+ 5 * numSold(d)
通过一组测试查询(通过这样的模型,我们可以得到尽可能接近用户理想的排序)可以最大限度地提高NDCG。
大多数机器学习排序的复杂度通常来自于调整的问题,以便可以应用其他机器学习方法。这些往往分为三种:单文档方法(point-wise),文档对方法( pair-wise)和文档列表方法(list-wise),我们将在下面介绍。我们将简要介绍几种方法,并思考每种方法的利弊。
三、单文档 机器学习排序(point-wise learning to rank)
搜索的“训练集”看起来有点像一般的机器学习训练集。单文档学习排名基于这种情况,所以让我们简要回顾一下搜索训练集的样子。搜索训练集的形式为在某个查询下带得分的文档,并称为判断列表,以下是一个判断列表的例子:
得分,查询,文档
4,dress shoes,best_selling_dress_shoes
3,dress shoes,meh_dress_shoes
...
0,dress shoes,ladies_dress
0,dress shoes,toga_item
正如你所看到的,非常相关的文档比如best_selling_dress_shoes的得分为4,而完全不相关的文档(toga_item)得分为0。
单文档学习排名不关注直接优化每个查询的排名。相反,我们只是尝试预测相关性得分。我们使用某种回归来创建包含文档d,查询q的排序函数f(d,q)。就像股价的例子一样,我们试图尽量减少残差。我们希望f(toga_item,“dress shoes”)得分为0,和f(best_selling_dress_shoes,“dress shoes”)得分为4。
在训练和评估期间,我们单纯将残差 y - f(d,q)最小化(这里的y是d,q的得分)。在这种情况下,假设我们的排序函数f给出了上述0分的文档为0.12分,4分的文档为3.65分。只看残差的话这似乎做的很好。如果所有文档得分平均不偏离0.5分以上,那么我们认为每个查询的NDCG也被最大化,也就是说,我们认为如果我们能够创建一个只返回得分的排序函数,我们应该可以得到接近用户期望的理想排序。
但表象可能是骗人的,单文档学习排名的一个问题是获得正确排序的头部项通常比判断列表尾部的模糊项更加重要。基本上所有认知和位置偏差在最大化度量(如NDCG)下都会被忽略。
实际上,一个经常交换精准相关项和不太相关项,但可以准确地预测第50页较低的相关性等级的模型并不是很好。买家在前几个结果中看了些勉强相关的项目且没有被其打动时,所以他们离开了。
更为灾难性的是,当你考虑仅发生在具体查询中的关系时会出现另一个问题,单文档方法会清除查询分组,忽略这些查询内的细微差别。例如,一个查询与标题字段上的相关性得分有很强的相关,而另一个查询与描述字段得分相关。或许某个查询的“good”标题匹配得分是5,而另一个查询的“good”标题匹配得分是15,这些情况是真实存在的:不同匹配中文档频率不一致可能导致这些场景。
因此,一般来说,单文档方法的执行效果不佳,我们将继续研究那些不清除查询分组,而是尝试使用排序函数直接优化每个查询的排序的方法。
四、文档列表方法(LIST-WISE),文档对方法(PAIR-WISE)
单文档学习排名以尽量减少理想与实际相关程度之间的差异。其他方法定义了不同的误差理解,更接近直接优化每个查询的理想顺序。我们来看一下文档列表(LIST-WISE)和文档对方法(PAIR-WISE)机器学习排序解决方案的两个例子,以便更接近于结合位置偏差和容纳每个查询细微差别的能力。
五、直接用w/ListNet优化列表
文档列表学习感觉像最纯粹的机器学习排序方式。它非常直接地定义错误:当前ranking函数的列表距离理想值的差距有多大?例如,这样的一种方法是通过查看给定顺序的排列概率。 基本思想是定义一个函数,该函数计算按给定的相关性得分的排列是用户真实寻找的概率。如果我们从判断列表中将“得分”作为排序,第1个结果的得分高于第2个,这样将获得最高概率。然而,从判断列表中获取的相关性等级对于当前用户当前的地点、时间、上下文有可能是不正确的。因此,单个较低分项在高分项上不可能成为完美的相关性排序,也许这才是用户此时此刻实际想要的,最低相关性得分排第一个的重排列表是极不可能的,排列概率接近零。
相对于计算每个列表排序可能的错误,仅查看排列中的第一个项对于搜索是“最佳”的概率来近似排列优先级在计算上是更加可行的。这被称为“第一”概率,它查找单个相关性分数以及查询的每个其他相关性分数,以计算该项将是第一的概率。正如你所预料的那样,较高的得分的相关性项将获得更高的概率排在前面,较低的得分项在该用户相同上下文时间地点下不太可能排在前面。
文档列表方法ListNet提出最小化训练集相关得分与神经网络中权重之间的交叉熵。听起来像胡言乱语,但真正重要的是通过最小化的error函数,开发一个直观的例子来看看它如何工作,如下面的伪python所示:
def error():
error = 0
For each query
For each doc:
error -= TopOneP(doc.grade) * log( TopOneP(f(doc, query)))
这里f是我们正在优化的ranking函数。 TopOneP是给定得分或分数排第一的概率。
首先,我们来看第一项TopOneP(doc.grade)。你想想这里发生了什么,假如第一名基于判断列表得分的概率高,那么第二项log(P ...)将增加更多权重,换句话说,第一项可以被认为是基于判断列表中的得分该项的优先级。更高得分项有更多第一的概率:正是我们寻找的位置偏差!
现在看第二个,log(TopOneP ...)。回想一下, log**(TopOneP = 1)为0,当TopOneP接近0时log(TopOneP <1)越来越负。因此,如果TopOneP接近于0,并且因此log越来越负,则整个项越来越负。负越多越不好,因为error-=(big negative number**)使错误变成更大的正数。
综上所述,当(1)该项在判断列表很重要时(TopOneP(doc.grade)很高),并且当我们的rangking函数f的TopOneP很低时,会产生更多的误差。显然这是不好的:在判断的基础上,真正需要靠前的,应该用f把它排到前面。
ListNet中的目标是通过迭代更新f函数中的权重来最小化误差。这里我不想深入讲解,因为上面的点更为重要。参阅这篇文章❶ 获得更多信息以及如何使用误差的定义来计算梯度(如何更改特征的权重)以尽量减少误差。
六、使用RankSVM优化文档对方法
文档对机器学习排序(pair wise learning to rank)通过最小化在搜索结果中乱序结果数, 一个具体指标:Kendall's Tau衡量了搜索解决方案中有序对的比例。文档对学习排序的一种形式是对查询进行分类,使得项目“有序”或者“乱序”。例如,你可能会发现,当对特定的查询集进行排序时,标题得分更高的其销售事项总数反而比较低。
Thorsten Joachims在这篇文章❷ 中介绍了一种流行的文档对机器学习排序方法RankSVM,还在Fabian Pedregrosa的博客文章中以Python方式实现,且乐意我在这篇文章借用他的图。
想象一下我们有两个查询,或许以我们的“dress shoes”查询,另一个是“t-shirt”。下面的图表y轴为标题得分特征,而x轴可能是销量。我们将“dress shoes”的每个判断绘制为三角形,并将“t-shirt”的每个判断绘制成圆形。颜色越深的形状越相关。
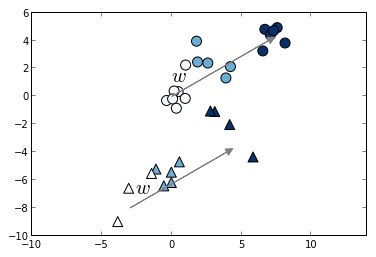
我们的目标是发现一个类似于上面图像中的w向量的函数,将最接近于正确的搜索结果排序。
事实证明,这个任务与使一个项好于另一个项的分类问题是一样的,适用于支持向量机(Support Vector Machine SVM)的二元分类任务。如果dress_shoes比meh_dress_shoes更好,我们可以将该排序标记为“更好”或者“1”。类似地,meh_dress_shoes在dress_shoes之前标记为“更差”或“-1”。然后,我们可以构建一个分类器来预测一个项可能比另一个更好。
这个分类任务需要更多底层特征值,想想“更好“的含义是什么,这意味着dress_shoes和meh_dress_shoes之间存在某些差异而将它归类为更好。所以RankSVM在此增量:itemA的特征值减去itemB的特征值上进行分类。
作为一个例子,只关注单一特征“销量”,我们可能会看到dress_shoes销售为5000,而meh_dress_shoes的销售量只有1000。所以产生的4000“差异”在训练过程中将会是一个特征。我们将这个差异作为一个SVM训练样本:(1,4000)。这里1是我们预测的“更好”的标签,而4000是我们在SVM中用作特征的“销量”增量。
在特征空间中绘制每个成对的差异来创建两个分类,如下所示,可以使用SVM来找到两个分类之间的适当判定边界:
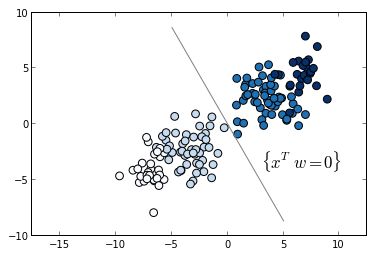
当然,我们不需要一个判定边界。 我们需要一个方向向量表示这个方向“更相关”。 最终,与该判定边界垂直的向量提供了ranking函数的线性权重比例:
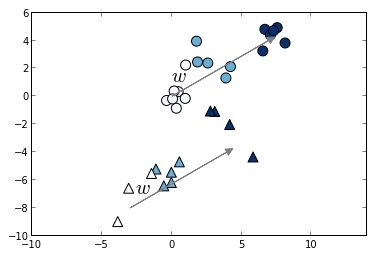
这听起来就像变成简单的线性回归,毕竟我们只获得特征权重和线性ranking函数。 但是如果你还记得单文档方法的讨论,在单个查询中你有时会具有查询内依赖性/细微差别。 特征中的一个好的标题在“dress shoes”得分为“5”,相比在“t-shirts”的得分为“15”,“RankSVM” 所做的是通过关注单个查询中指出“标题得分越高,对应查询中相关性越高”的粗略的感官中的分类增量。
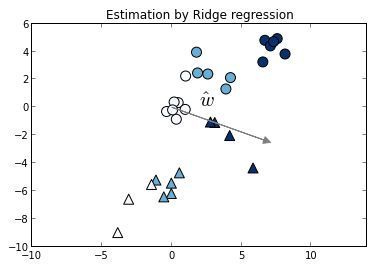
在图形中,你可以看到,使用线性回归运行上述相同的数据:
七、RankSVM与List-Wise方法
你可以看到, RankSVM似乎仍然创建一个直接的、线性的相关性。我们知道现实往往是非线性的。使用SVM,可以使用非线性内核,尽管线性内核往往是最受欢迎的。 RankSVM的另一个缺点是它只考虑到文档对的差异,而不考虑位置偏差。当RankSVM中的项无序时,无法优先保证头部项正确的同时忽略底部项的不准确。
虽然文档列表方法往往更准确,并且包含位置偏差,但训练和评估的成本很高。虽然RankSVM往往不那么准确,但该模型很容易训练和使用。
由于其简单性,RankSVM可以轻松地为特定用户或部分查询/用户构建模型。可以想象将查询分类到不同的用例中。也许对于电子商务,有些查询我们可以肯定地说是错别字。而其他的是我们知道的广泛的类目搜索查询(如“shoes”)。
如果我们相应地对查询进行分类,我们可以为每种类型的用例分别构建模型。我们甚至可以组合不同的SVM模型。例如,由于模型是一组线性权重集合,我们可以将模型绑定到特定的用户Tom,并将其与Tom正在执行的查询绑定的模型相加,搜“dress shoes”返回dress shoes,我们觉得Tom会很喜欢。
八、结论
主要的结论是无论选择什么样的模型,明白该模型需要优化什么,需要尽量减少什么样的误差?
你了解了单文档方法如何优化判断的残差,以及如何为不理想。 RankSVM执行一个更简单的优化来消除无序对,但这也有问题,因为没有考虑到位置偏差。有趣的是,ListNet的排列概率和第一概率给同样有效的好答案留有余地。我个人认为,如果这种方法用于多样化搜索结果,可以为当前用户展示许多有效的假设。
当然,结束之刻,假如我们不选取正确的特征来训练我们的模型,模型的类型可能不是很重要!特征选取,创作,生成和设计,往往才是最难的一部分,而非模型的选择。