智能决策上手系列教程索引
我们继续上一篇抓取Boss直聘网站招聘列表的练习,进一步抓取每个招聘的详细信息。
网络数据抓取-Python-爬虫-Header-Boss直聘
代码回顾(中间啰嗦部分被省略):
url='https://www.zhipin.com/c101020100/h_101020100/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page='
headers={
'user-agent':'Mozilla/5.0'
}
page=1
hud=['职位名','薪资1','薪资2','地点','经验','学历','公司行业','融资阶段','公司人数','发布日期','发布人']
print('\t'.join(hud))
import requests
from bs4 import BeautifulSoup
for n in range(1,21):
html=requests.get(url+str(page),headers=headers)
page+=1
soup = BeautifulSoup(html.text, 'html.parser')
for item in soup.find_all('div','job-primary'):
shuchu=[]
shuchu.append(item.find('div','job-title').string) #职位名
...
print('\t'.join(shuchu))
1. 分析页面
对于https://www.zhipin.com/c101020100/h_101020100/?query=人工智能&page=1这个页面,我们再次右击某个招聘的标题文字,检查Elements元素面板:
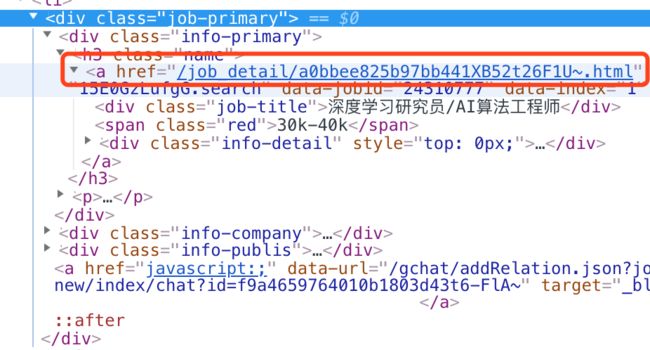
这里的
a标记元素是一个可以点击的链接元素,它的
href属性就是点击后将要打开的新页面地址,点击它就会打开这个招聘职位对应的详情页面,对比发现真正打开的页面只是比这个
href地址前面多了
https://www.zhipin.com,就变成了类似
https://www.zhipin.com/job_detail/7231c7f3bb87e0f51XZ43tm8F1A~.html的页面。
我们需要让爬虫自动的打开每个详细页面,并提取里面的有用信息,以便于我们存储到Excel表格里面进行分析。
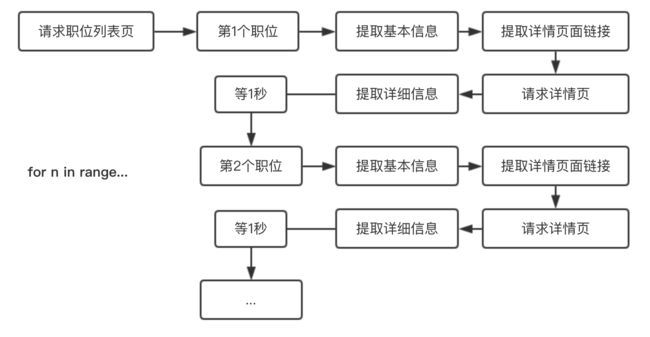
下图是我们期望的顺序:
2. 获取链接
BeautifulSoup获取元素属性的方法是直接使用['属性名'],比如这里我们需要获取href属性,那么就只要找到这个a标记,然后.['href']就可以得到链接地址了。
建议你新建一个文件,然后使用下面精简过的代码进行测试(这里改为range(1,2)只读取第1页):
url='https://www.zhipin.com/c101020100/h_101020100/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page='
headers={
'user-agent':'Mozilla/5.0'
}
page=1
hud=['职位名','薪资1','薪资2','地点','经验','学历','公司行业','融资阶段','公司人数','发布日期','发布人']
print('\t'.join(hud))
import requests
from bs4 import BeautifulSoup
for n in range(1,2):
html=requests.get(url+str(page),headers=headers)
page+=1
soup = BeautifulSoup(html.text, 'html.parser')
for item in soup.find_all('div','job-primary'):
shuchu=[]
shuchu.append(item.find('div','job-title').string) #职位名
#读取每个职位的详细信息页面
link=item.find('div','info-primary').find('h3').find('a')['href']
print(link)
#print('\t'.join(shuchu))
Python里面,如果你需要临时禁用一行代码,可以在它开头添加井号
#;如果你需要临时禁用多行代码,那么需要在开始和结尾添加三个单引号'''
3. 请求详情页面并提取数据
打开任意一个详情页面比如这个页面,可以看到我们需要的职位详情内容包含在一个 这里有个难题,这个 在Notebook里再新建一个代码文件,测试下面的代码: 这里我们使用了几个新的知识: 我们测试好了之后,把它们合并到一起(仍然是只拉取第一页职位列表): 强烈推荐安装Anaconda,使用它自带的Jupyter Notebook来运行下面这个代码。使用天池Notebook可能导致被Boss直聘网站禁用后无法修复的问题。 如果你的代码本来好好地,然后就不能正常运行,或者能运行但是详情字段都输出None,那么请做以下尝试: 目前还不确定Boss直聘的反爬虫机制,不过下一篇我们一定会深入讨论更多内容,届时也许会有更好办法。 这里在 Boss直聘的页面相对还是比较容易抓取的,但是如果你频繁发送页面请求,他们的服务器会把你的网络IP地址给封禁,让你再也请求不到他们服务器的任何数据。 如果你不确定当前电脑的IP是否被他们服务器封禁,可以在浏览器里面查看打开你代码中的任意链接,看是否能正常访问,如果可以那就没事。Boss直聘有时候封禁你只是临时的,你只要在浏览器内正常验证一下表示当前你是真人不是爬虫,那么就能解除封禁。 这种封禁一般是几分钟到1小时,罕见彻底封禁不自动解禁的。 如果你被封禁了又急需解锁,那么恐怕最快的办法就是换个IP了,可以试试看换台电脑或者换到别的网线接口上,如果是家庭宽带,也可以试试看拔掉网线过几分钟再插上。 原则上讲,网站服务器一般不会采用封IP的办法的,因为如果是一个公司共用这个宽带,那么一旦封禁IP,全公司都不能访问他们的网站了,其他人会觉得这个网站很糟而弃用。 我并不确定Boss直聘网站是否真的采用了封IP的方法,无论如何,下一篇我们将讨论如何破解另外一种反爬虫的机制。——对于封禁IP的方法来反爬虫,代码上几乎是误解的,你必须有很多个IP来运行你的爬虫,很多个IP可以是很多台电脑,也可以是代理服务器,暂时我们不讨论这个。 如果你希望成为一个真正的爬虫专家,那么你需要认真的学习一些计算机网络通信的基础知识,可以在网上购买一些大学计算机通信专业的课本来看。——当然这不是我推荐每个人去做的。 经过这三篇文章的学习,你应该已经准备好迈入编程的门槛了,接下来的情况天池Notebook可能就不够用了,建议你正式下载和安装Anaconda。 Anaconda安装和Jupyter Notebook上手教程 如果您发现文章错误,请不吝留言指正; END
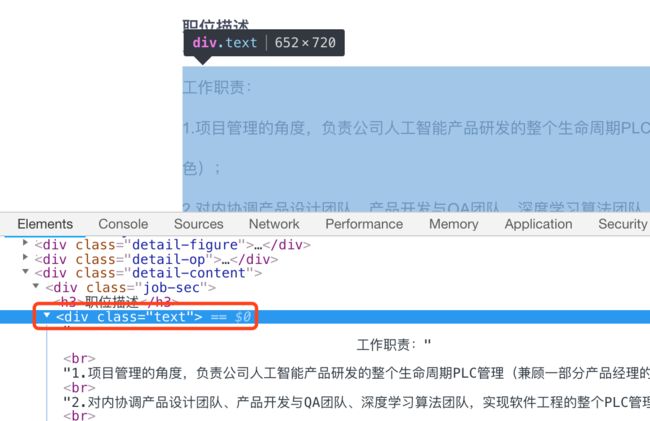
text div里面的内容很乱,包含了很多空格回车还有.string是不行的,但用.text就能很好的解决这些问题import requests
from bs4 import BeautifulSoup
headers={
'user-agent':'Mozilla/5.0'
}
def getDetails(link):
xq_html=requests.get('https://www.zhipin.com'+link,headers=headers)
xq_soup= BeautifulSoup(xq_html.text, 'html.parser')
miaoshu=xq_soup.find('div','job-sec').find('div','text').text #获得标记的内部文字
miaoshu=miaoshu.lstrip().rstrip() #去除开头和结尾的空格
return miaoshu
xq=getDetails('/job_detail/7231c7f3bb87e0f51XZ43tm8F1A~.html')
print(xq)
def getDetails(link), def xxx(a):这是创建了一个函数。def是define(定义)的意思。
def run():也可以创建def hit(someone):这样的函数。print('hello!')就是在使用print函数,执行输出hello这个单词的动作;同样,requests.get(...)也是在执行requests自身带有的get动作函数,上面的xq=getDetails(...)就是使用了我们自己创建的getDetails函数。return miaoshu,这里是指函数最后输出的结果,类似html=requests.get(...)这样把获取到的页面数据输出给html这个对象。我们的getDetails函数也会把整理后的miaoshu文字输出给下面的xq。元素.text和元素.string差不多效果,都是得到元素里面的文字,但.text可以去掉掺杂在里面的尖括号。lstrip().rstrip(),左右去掉多余的空格,left-strip,right-strip的意思。4. 合并代码
url='https://www.zhipin.com/c101020100/h_101020100/?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page='
headers={
'user-agent':'Mozilla/5.0'
}
hud=['页数','职位名','薪资1','薪资2','地点','经验','学历','公司行业','融资阶段','公司人数','发布日期','发布人','详情']
print('\t'.join(hud))
import requests
from bs4 import BeautifulSoup
import time
def getDetails(link):
xq_html=requests.get('https://www.zhipin.com'+link,headers=headers)
xq_soup= BeautifulSoup(xq_html.text, 'html.parser')
miaoshu=''
try:
miaoshu=xq_soup.find('div','job-sec').find('div','text').text #获得标记的内部文字
miaoshu=miaoshu.lstrip().rstrip() #去除开头和结尾的空格
except:
miaoshu='None'
return miaoshu
for n in range(1,2):
html=requests.get(url+str(n),headers=headers)
soup = BeautifulSoup(html.text, 'html.parser')
liebiao=soup.find_all('div','job-primary')
for item in liebiao:
shuchu=[]
shuchu.append(str(n))
shuchu.append(item.find('div','job-title').string) #职位名
xinzi=item.find('span','red').string
xinzi=xinzi.replace('k','')
xinzi=xinzi.split('-')
shuchu.append(xinzi[0]) #薪资起始数
shuchu.append(xinzi[1]) #薪资起始数
yaoqiu=item.find('p').contents
shuchu.append(yaoqiu[0].string if len(yaoqiu)>0 else 'None') #地点
shuchu.append(yaoqiu[2].string if len(yaoqiu)>2 else 'None') #经验
shuchu.append(yaoqiu[4].string if len(yaoqiu)>4 else 'None') #学历
gongsi=item.find('div','info-company').find('p').contents
shuchu.append(gongsi[0].string if len(gongsi)>0 else 'None') #公司行业
shuchu.append(gongsi[2].string if len(gongsi)>2 else 'None') #融资阶段
shuchu.append(gongsi[4].string if len(gongsi)>4 else 'None') #公司人数
shuchu.append(item.find('div','info-publis').find('p').string.replace('发布于','')) #发布日期
shuchu.append(item.find('div','info-publis').find('h3').contents[3].string) #发布人
#读取每个职位的详细信息页面
link=item.find('div','info-primary').find('h3').find('a')['href']
xq=getDetails(link)
shuchu.append(xq)
print('\t'.join(shuchu))
time.sleep(1)
print(html.text),输出最初得到的页面内容,查看是否正常,有没有被服务器拒绝的字样。for n in range(1,21)中的1,这个1代表从第几页列表开始爬取,Boss直聘似乎是每次爬取100个详情页面(3个列表页)左右就要验证一下,所以你需要3页3页的爬取,然后粘贴到excel中放到一起。
getDetails函数里面增加了try:...except:...这个用法,它表示尝试着执行try后面的代码,如果运行出错(比如找不到对应的标记元素导致find函数失败),那么就执行except:后面的代码。5. 关于请求失败
6. 后续学习
请认真参照我的这个教程进行。
智能决策上手系列教程索引
每个人的智能决策新时代
如果您觉得有用,请点喜欢;
如果您觉得很有用,欢迎转载~