ZooKeeper 分布式过程协同技术详解



简介
分布式系统
分布式系统是同时跨越多个物理主机, 独立运行的多个软件所组成的系统。
-
分布式系统中的两种进程通信方式
- 方式一: 直接通过网络进行信息交换
- 方式二: 读写某些共享存储
 分布式系统中的两种进程通信方式
分布式系统中的两种进程通信方式 -
分布式系统需注意以下几点
- 消息延迟: (如网络拥堵),导致消息不是按顺序到达
- 处理器性能: 导致消息延迟处理
- 时钟偏移: 导致系统作出错误决策
Zookeeper使用场景
- 适用场景
- 选举集群主节点
- 检测崩溃
- 存储集群元数据
- 服务发现
- 数据分片
- 不适用场景
- 海量数据存储
主-从应用

主节点失效
- 备份主节点: 在主节点崩溃时接管主节点的角色, 进行故障转移,并恢复到旧主节点崩溃时的状态
- 脑裂: 误判主节点崩溃(如消息延迟), 而导致集群中出现两个主节点
从节点失效
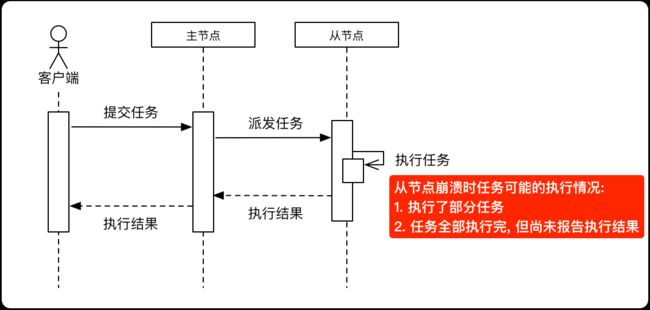
通信故障
- 某台机器网络连接断开, 导致断开的机器和网络中的某一从节点执行同一任务
主-从应用的需求
综上所述, 我们对主-从应用的需求如下:
- 主节点选举
- 崩溃检测
- 组成员关系管理
- 元数据管理
了解Zookeeper
Zookeeper基础
Zookeeper数据树结构示例
节点称为znode节点

API
znode节点是数据操作的最小单元, Zookeeper不允许局部写入或读取zonde节点的数据
| API | 说明 |
|---|---|
create /path data |
创建一个名为/path的znode节点,并包含数据data create -e /master "master1.example.com:2223"(-e表示临时节点)create -s /tasks/task- "cmd"(-s创建有序节点) |
delete /path |
删除名为/path的zonde |
exists /path |
检查是否存在名为/path的节点 |
set /path data |
设置名为/path的zonde的数据为data |
get /path |
返回名为/path节点的数据信息 |
getChildren /path |
返回/path节点的所有子节点列表 |
ls /path |
查看/path下的节点, 例如ls /查看根节点下有哪些节点 |
znode的不同类型
新建znode时, 还需要指定该节点的类型(mode),不同的类型决定了znode节点的行为方式
| 节点类型 | 重点说明 | 删除时机 | 案例 |
|---|---|---|---|
| 持久节点(persistent) | 只能通过调用delete删除 | 保存从节点的任务分配情况,即使分配任务的主节点节点崩溃了 | |
| 临时节点(ephemeral) | Zookeeper不允许临时节点有子节点(因为临时节点会自动删除) | 1.创建该节点的客户端崩溃或断开连接 2.主动调用delete删除 |
检测主/从节点崩溃时,需要每个节点建立临时节点 |
| 有序节点(sequential) | 创建时,一个序号会被追加到路径后,例如创建路径为task/task-,则最终路径为task/task-1 |
名称唯一,可直观查看znode的创建顺序 |
上面3中类型排列组合可知, znode节点有4种类型:
- 持久节点
- 临时节点
- 持久有序节点
- 临时有序节点
监视与通知
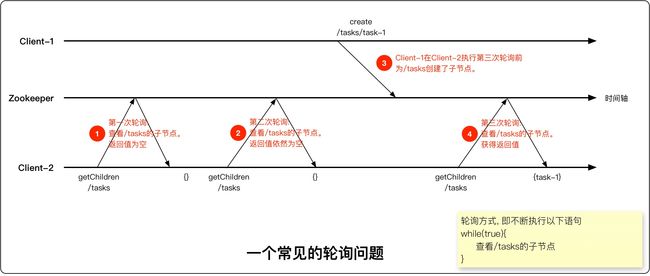
一种常见的轮询问题
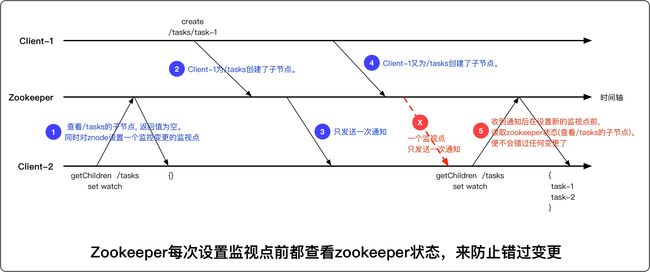
基于通知机制

监视点
通知机制是单次出发的操作, 即设置一次监视点, 只会发出一次变动通知。通过每次设置监视点前读取Zookeeper的状态来防止错过任何变更。
使用版本控制

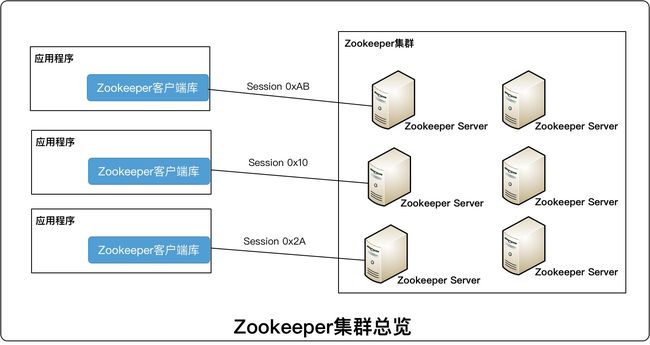
Zookeeper架构
架构总览
Zookeeper服务器运行在两种模式下:
| 模式 | 说明 |
|---|---|
| 独立模式(standalone) | 即单机模式 |
| 仲裁模式(quorum) | 即一组集群 |
仲裁
仲裁模式下,Zookeeper复制集群种所有服务器的数据树。但如果让一个客户端等所有服务器完成数据保存后再继续,便会导致无法接受的延迟问题。Zookeeper的解决方案是使用法定人数,即只要法定个数的服务器完成数据保存后,客户端即可继续。
会话(Session)
- 当客户端通过某一个特定语言套件来创建一个Zookeeper句柄时,它就会通过服务建立一个会话(Session)。然后通过TCP协议与服务器通信
- 当会话无法与当前连接的服务器继续通信时,Zookeeper客户端就可能透明地将会话转移到另一个服务器上
- 同一个会话提供了顺序保障,即请求会先进先出
开始使用Zookeeper
安装
- 下载Zookeeper安装包并解压.
tar -xvzf zookeeper-3.4.8.tar.gz - 创建配置文件(conf目录下有样例配置)。
mv conf/zoo_sample.cfg conf/zoo.cfg. - 最好将data移除
/tmp目录, 防止Zookeeper填满根分区, 修改zoo.cfg中的配置dataDir=/tmp/zookeeper - 启动Zookeeper服务器.
bin/zkServer.sh start(bin/zkServer.sh start-foreground可在屏幕上看到服务器日志输出) - 启动Zookeeper客户端.
bin/zkCli.sh
 日志
日志 -
命令使用方式

生命周期和会话

- 客户端与服务器因网络超时断开连接后, 客户端仍然保持connecting状态。因为对声明会话超时负责的是服务端,而不是客户端。
- 会话超时设置为时间t
| 端 | 时间 | 行为 |
|---|---|---|
| 服务端 | t | 经过时间t后,服务端接收不到这个会话的任何消息,服务端会声明会话过期 |
| 客户端 | t/3 | 经过t/3时间未收到服务端消息,则主动向服务器发送心跳消息 |
| 客户端 | 2t/3 | 仍未收到服务端消息,则开始寻找其它的服务器,此时它还有t/3的时间去寻找 |
- 仲裁模式(集群模式)下,Zookeeper需要传递可用的服务器列表给客户端,告知客户端可以连接的服务器信息并选择一个进行连接
- 断开连接后,客户端不能连接到一个比自己状态旧的服务器,Zookeeper处理方式见下图

仲裁模式
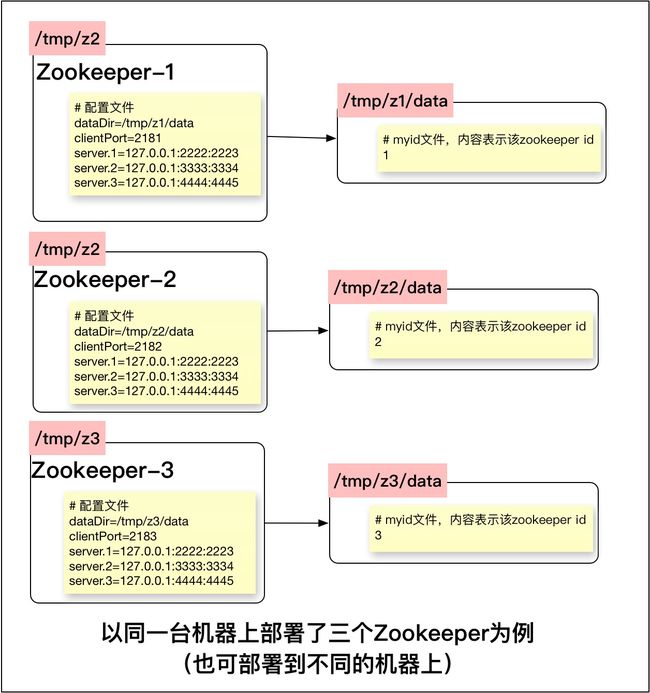
我们可以在一台机器上运行多个Zookeeper,来构建仲裁模式(集群模式)
- 配置如下
# 在数据文件存储目录下建立文件myid,并写入内容1(zookeeper id),便可定义该zookeeper服务器ID。 命令: echo 1>/tmp/z1/data/myid
# 这样做的好处是, 部署到不同机器的zookeeper不需要改配置文件
dataDir=/tmp/z1/data
# 客户端连接的端口号
clientPort=2182
# /root/dev/research/zookeeper-3.4.8/conf/zoo.cfg
# server.{n即zookeeper服务器id}=[ip地址或hostname]:[集群通信端口号]:[群首选举端口号]
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
-
实践(Zookeeper部署示意图)
 Zookeeper部署示意图
Zookeeper部署示意图- 最初只启动z3,从日志可以看出z3会疯狂尝试连接到其它服务器,然后失败。
 Zookeeper部署示意图
Zookeeper部署示意图-
然后再启动z2,此时达到了法定人数。从日志可以看出,z3被选为了leader,z2作为follower被激活
 Zookeeper-3日志
Zookeeper-3日志 Zookeeper-2日志
Zookeeper-2日志
-
使用zkCli.sh访问集群
./zkCli.sh -server 127.0.0.1:2182,127.0.0.1:2181(如果希望客户端只连接上海机房集群,可以只输入上海zookeeper服务器ip) 随机连接集群中一台机器
随机连接集群中一台机器zookeeper可以实现简单的负载均衡,但是无法按权重来进行负载。
-
现在我们来实现一个原语:通过zookeeper实现锁
 通过zookeeper实现锁
通过zookeeper实现锁
一个主-从模式例子的实现
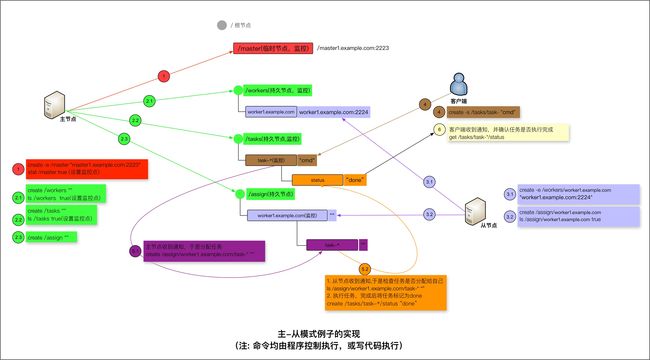
主节点角色
从节点,客户端(略),见上面分析图
# 连接Zookeeper
[root@iZ11bh64aveZ bin]# ./zkCli.sh -server 127.0.0.1:2182,127.0.0.1:2181
# -e表示临时节点
[zk: 127.0.0.1:2182,127.0.0.1:2181(CONNECTED) 0] create -e /master "master1.example.com:2223"
Created /master
[zk: 127.0.0.1:2182,127.0.0.1:2181(CONNECTED) 1] ls /
[zookeeper, master]
[zk: 127.0.0.1:2182,127.0.0.1:2181(CONNECTED) 2] get /master
master1.example.com:2223
cZxid = 0x10000000c
ctime = Wed Feb 22 23:05:34 CST 2017
mZxid = 0x10000000c
mtime = Wed Feb 22 23:05:34 CST 2017
pZxid = 0x10000000c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x25a6118b1220004
dataLength = 24
numChildren = 0
# /master已经存在,无法重复创建
[zk: 127.0.0.1:2182,127.0.0.1:2181(CONNECTED) 4] create -e /master "master1.example.com:2223"
Node already exists: /master
# 对/master节点设置监视点
[zk: 127.0.0.1:2182,127.0.0.1:2181(CONNECTED) 5] stat /master true
cZxid = 0x10000000c
ctime = Wed Feb 22 23:05:34 CST 2017
mZxid = 0x10000000c
mtime = Wed Feb 22 23:05:34 CST 2017
pZxid = 0x10000000c
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x25a6118b1220004
dataLength = 24
numChildren = 0
任务队列化(有序节点的应用)
可以使用有序节点来达到任务队列化的目的。这样做有两个好处:
- 序列号指定了任务被队列化的顺序;
- 可以通过很少的工作为任务创建基于序列号的唯一路径。
使用Zookeeper的API
建立Zookeeper会话
句柄
- Zookeeper的API围绕句柄(handle)而构建,每个API调用都需要传递handle。它代表与Zookeeper之间的一个会话
| 句柄 | 说明 |
|---|---|
| 只要会话活着,句柄就仍然有效 | 例如会话在断开后被迁移到另一台服务器,由于此时会话还有效,因此句柄仍然有效 |
| 如果句柄关闭,则终止会话 | 如果句柄关闭,Zookeeper客户端会告知服务器终止这个会话 |
| - | 如果Zookeeper发现客户端死掉,就会使该会话无效。如果客户端尝试使用该会话的那个句柄连接,那么服务器会通知客户端该会话已失效,这个句柄进行的任何操作都会返回错误 |
创建Zookeeper句柄API
- API
/**
connectString: 连接zookeeper的主机和端口信息,如:127.0.0.1:2182,127.0.0.1:2181
sessionTimeout: 超时时间,单位ms。一般设置为5-10秒。sessionTimeout=15s表示Zookeeper如果有15s无法和客户端通信,则会终止该会话。
watcher:Watcher对象(需自己实现Watcher接口),用于监控会话(如建立/失去连接,Zookeeper数据变化,会话过期等事件)
*/
Zookeeper(String connectString,int sessionTimeout, Watcher watcher)
- 实现一个Watcher
package org.apache.zookeeper.book.luyunfei;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
/**
* Created by luyunfei on 24/02/2017.
*/
public class Master implements Watcher {
@Override
public void process(WatchedEvent watchedEvent) {
// 监控到连接断开时,自己不要关闭会话后再启动一个新的会话,这样会增加系统负载,并导致更长时间的中断, Zookeeper客户端库会处理
System.out.println("监控: "+watchedEvent);
}
public static void main(String[] args) throws InterruptedException, IOException {
String connectString = "139.196.53.21:2182,139.196.53.21:2181";
// 注意:如果服务器发现请求的会话超时时间太长或太短,服务器会调整会话超时时间
int sessionTimeout = 10 * 1000;
Master obj = new Master();
ZooKeeper zooKeeper = new ZooKeeper(connectString, sessionTimeout, obj);
Thread.sleep(600000);
//客户端可以调用Zookeeper.close()方法主动结束会话. 否则即便客户端断开连接,会话也不会立即消失,服务端要等会话超时以后才结束会话
zooKeeper.close();
}
}
## 执行上述代码,启动客户端
2017-02-24 22:49:29,359 - INFO - [main:ZooKeeper@438] - Initiating client connection, connectString=139.196.53.21:2182,139.196.53.21:2181 sessionTimeout=10000 watcher=org.apache.zookeeper.book.luyunfei.Master@3e6fa38a
2017-02-24 22:49:29,399 - INFO - [main-SendThread(139.196.53.21:2182):ClientCnxn$SendThread@1032] - Opening socket connection to server 139.196.53.21/139.196.53.21:2182. Will not attempt to authenticate using SASL (unknown error)
2017-02-24 22:49:29,488 - INFO - [main-SendThread(139.196.53.21:2182):ClientCnxn$SendThread@876] - Socket connection established to 139.196.53.21/139.196.53.21:2182, initiating session
2017-02-24 22:49:29,649 - INFO - [main-SendThread(139.196.53.21:2182):ClientCnxn$SendThread@1299] - Session establishment complete on server 139.196.53.21/139.196.53.21:2182, sessionid = 0x25a7098967b0000, negotiated timeout = 10000
监控: WatchedEvent state:SyncConnected type:None path:null
## 此时关闭Zookeeper服务器(/tmp/z3/zookeeper-3.4.8/bin/zkServer.sh stop), 程序监控到Disconnected事件
2017-02-24 22:57:31,009 - INFO - [main-SendThread(139.196.53.21:2182):ClientCnxn$SendThread@1158] - Unable to read additional data from server sessionid 0x25a7098967b0000, likely server has closed socket, closing socket connection and attempting reconnect
监控: WatchedEvent state:Disconnected type:None path:null
....
....
## 此时又开启Zookeeper服务器(/tmp/z3/zookeeper-3.4.8/bin/zkServer.sh start), 客户端自动重新连接服务
2017-02-24 22:59:02,559 - INFO - [main-SendThread(139.196.53.21:2182):ClientCnxn$SendThread@1299] - Session establishment complete on server 139.196.53.21/139.196.53.21:2182, sessionid = 0x25a7098967b0000, negotiated timeout = 10000
监控: WatchedEvent state:SyncConnected type:None path:null
- 当看到Disconnected事件时,千万不要自己创建一个新的Zookeeper句柄来重新连接服务,Zookeeper客户端库会负责在通信恢复时为你重新连接服务。
- 假设有3台Zookeeper服务(法定人数为2),一个服务器故障不会导致服务终端。客户端会很快收到Disconnected事件,之后便为SyncConnected事件
- 再说一遍: 不要自己试着管理Zookeeper客户端连接(如监控到连接断开时,自己不要关闭会话后再启动一个新的会话,这样会增加系统负载,并导致更长时间的中断)。Zookeeper客户端库会处理,它会很快重建会话,以便将影响最小化。
Zookeeper管理接口
Zookeeper有两种管理接口: JMX和命令,先介绍命令管理接口(stat,dump命令)
# stat命令
[root@iZ11bh64aveZ bin]# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
#(手动敲入stat)
stat
Zookeeper version: 3.4.8--1, built on 02/06/2016 03:18 GMT
Clients:
/127.0.0.1:60538[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x300000002
Mode: leader
Node count: 4
Connection closed by foreign host.
[root@iZ11bh64aveZ bin]#
- dump命令
# dump命令
[root@iZ11bh64aveZ bin]# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
# (手动敲入dump)
dump
SessionTracker dump:
Session Sets (4):
0 expire at Fri Feb 24 23:27:28 CST 2017:
0 expire at Fri Feb 24 23:27:32 CST 2017:
0 expire at Fri Feb 24 23:27:34 CST 2017:
1 expire at Fri Feb 24 23:27:38 CST 2017:
0x25a70a1e2b80000
ephemeral nodes dump:
Sessions with Ephemerals (0):
Connection closed by foreign host.
[root@iZ11bh64aveZ bin]#
# 此时停止客户端,过了一段时间才会出现如下信息(即会话过一段时间后才消失。这是因为直到会话超时时间过了以后,服务端才会结束这个会话)
# 最好在客户端停止时,会话立即消失。客户端可以调用Zookeeper.close()方法主动结束会话
[root@iZ11bh64aveZ bin]# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
dump
SessionTracker dump:
Session Sets (0):
ephemeral nodes dump:
Sessions with Ephemerals (0):
Connection closed by foreign host.
[root@iZ11bh64aveZ bin]#
给上面的Master程序增加管理权(创建主节点)
创建znode节点
创建Zookeeper节点API create()----同步调用版本
要重视对异常的处理, 例如: 如果create执行创建主节点成功了,此时,客户端还不知道自己成功创建了主节点,然后客户端死掉了。这个时候就不会再有其它任何进程称为主节点进程了。
/**
String path: 节点path
byte[] data: 节点数据, 只能传入字节数组类型的数据. 如果没有数据,则可传new byte[0]
List acl: ACL策略。例如
1. ZooDefs.Ids.OPEN_ACL_UNSAFE为所有人提供了所有权限(该策略在不可信环境下非常不安全)
2. 其它策略
CreateMode: 节点类型(枚举,如:临时节点,临时有序节点,持久节点,持久有序节点)
抛出两类异常:
1. KeeperException
1.1 ConnectionLossException: KeeperException异常的子类,发生于客户度与Zookeeper服务端失去连接时,通常由网络原因导致
注意:虽然Zookeeper会自己处理重建连接,但是我们必须知道未决请求的状态(是否已经处理/需重新请求)
2. InterruptedException:发生于客户端线程调用了Thread.interrupt, 通常是因为应用程序部分关闭,但还在其他相关应用的方法中使用
处理方式:1. 向上直接抛出异常,让程序最外层捕获,然后主动关闭zk句柄(zookeeper.stop()),然后做清理善后
2. 如果句柄没有关闭,则可能会有其它异步执行的后续操作,这种情况做清理善后会比较棘手
*/
create(String path, byte[] data, List acl, CreateMode createMode) throws KeeperException, InterruptedException
创建Zookeeper节点举例(创建节点)
// 创建zonde节点代码
public void runForMaster(ZooKeeper zooKeeper) throws KeeperException, InterruptedException {
Random random = new Random(this.hashCode());
String serverId = Integer.toHexString(random.nextInt());
// 创建节点
zooKeeper.create(
"/master", // 节点path
serverId.getBytes(), // 节点数据, 这里定义节点数据为代表该客户端的随机ID
ZooDefs.Ids.OPEN_ACL_UNSAFE,// 该节点的安全策略
CreateMode.EPHEMERAL// 节点类型(枚举,如:临时节点,临时有序节点,持久节点,持久有序节点)
);
}
getData API----同步调用版本
/**
path: znode节点路径
watch:
boolean类型版本api: 表示是否想要监听后续的数据变更,true则使用创建句柄时所设置的Watcher对象监控事件
Watcher类型版本api: 表示使用新Watcher对象监视变更
Stat: getData方法可填充节点的元数据信息,stat表示新填充的元数据信息,对象定义如下
public class Stat implements Record {
private long czxid;
private long mzxid;
private long ctime;
private long mtime;
private int version;
private int cversion;
private int aversion;
private long ephemeralOwner;
private int dataLength;
private int numChildren;
private long pzxid;
}
返回值: znode节点数据的字节数组
*/
byte[] getData(String path, boolean watch, Stat stat)
byte[] getData(String path, Watcher watcher, Stat stat)
// 我们通过Stat结构,可以获得当前主节点创建的时间
Stat stat = new Stat();
byte[] data = zooKeeper.getData("/master", false, stat);
Date startDate = new Date(stat.getCtime());//ctime单位为秒
getData 举例(申请成为主节点)
String serverId = Integer.toHexString(new Random(this.hashCode()).nextInt());
boolean isLeader = false;
ZooKeeper zooKeeper;
// 创建zonde节点(申请成为主节点)
public void runForMaster() throws KeeperException, InterruptedException {
while (true) {
try {
// 创建/master节点,如果执行成功,本客户端将会成为主节点
zooKeeper.create(
"/master",
serverId.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL
);
} catch (KeeperException.NodeExistsException e) {
// 主节点已经存在了,不再申请成为主节点
isLeader = false;
break;
} catch (KeeperException.ConnectionLossException e) {
// 这里留空,以便在网络异常情况下,继续while循环来申请成为主节点
}
// 如果已经存在主节点,则跳出while循环,不再申请成为主节点
if (checkMaster()) break;
}
}
// 检查是否存在主节点
public boolean checkMaster() throws KeeperException, InterruptedException {
while (true) {
try {
Stat stat = new Stat();
// 通过获取/master节点数据,并和自身的serverId比较,来检查活动主节点
byte[] data = zooKeeper.getData("/master", false, stat);
isLeader = new String(data).equals(serverId);
// 已经存在主节点了,返回true,告知runForMaster()不要再进行while循环了
return true;
} catch (KeeperException.NoNodeException e) {
return false;
} catch (KeeperException.ConnectionLossException e) {
}
}
}
getData API----异步调用版本
虽然是异步的, 但是顺序能够得到保证。因为为了保持顺序,只会有一个单独的线程按照接收顺序处理响应包
/**
StringCallback: 提供回调方法的对象,它通过传入的上下文参数(Object ctx)来获取数据。它实现StringCallback接口
Object ctx: 用户指定上下文信息,最终会传入回调函数中
*/
void create(String path, byte[] data, List acl, CreateMode createMode, StringCallback cb, Object ctx)
/**
以下演示了如何创建一个StringCallback回调方法的对象。
注意: 因为只有一个单独的线程处理所有回调调用,因此一个回调函数阻塞,会导致后续所有回调函数都阻塞。
所以要避免在回调函数里做集中操作(即while(true){...})或阻塞操作(如调用synchronized方法).以便其被快速处理
*/
AsyncCallback.StringCallback cb = new AsyncCallback.StringCallback() {
/**
rc : 返回码,0: 正常返回;其它表示对应的KeeperException异常
path: create()传入的参数,即znode路径
ctx: create()传入的参数,即上下文
name: znode节点最终的名称(一般path和那么值一样。单如果采用CreateMode.SEQUENTIAL有序模式,则name为最终名称)
*/
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
checkMaster();
break;
case OK:
state = MasterStates.ELECTED;
takeLeadership();
break;
case NODEEXISTS:
state = MasterStates.NOTELECTED;
masterExists();
break;
default:
state = MasterStates.NOTELECTED;
LOG.error("Something went wrong when running for master.",
KeeperException.create(Code.get(rc), path));
}
LOG.info("I'm " + (state == MasterStates.ELECTED ? "" : "not ") + "the leader " + serverId);
}
};
AsyncCallback.StringCallback cb = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
}
};
getData API----异步调用版本
异步版本比同步版本简单, 没有while(true){...},防止一直卡在本线程导致其它线程无法执行
void checkMaster() {
zk.getData("/master", false, masterCheckCallback, null);
}
设置元数据
这里和create API没啥不同,有个技巧见代码注释
public void bootstrap(){
createParent("/workers", new byte[0]);
createParent("/assign", new byte[0]);
createParent("/tasks", new byte[0]);
createParent("/status", new byte[0]);//new byte[0] 表示传入空数据
}
void createParent(String path, byte[] data){
zk.create(path,
data,
Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
createParentCallback,
data);// A----这里将data作为上下文传入到回调函数中,以便在下面CONNECTIONLOSS时再递归调用createParent函数。
}
StringCallback createParentCallback = new StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
case CONNECTIONLOSS:
/*
* Try again. Note that registering again is not a problem.
* If the znode has already been created, then we get a
* NODEEXISTS event back.
*/
createParent(path, (byte[]) ctx);//呼应A
break;
case OK:
LOG.info("Parent created");
break;
case NODEEXISTS:
LOG.warn("Parent already registered: " + path);
break;
default:
LOG.error("Something went wrong: ",
KeeperException.create(Code.get(rc), path));
}
}
};
注册从节点
略
Zookeeper会严格维护执行顺序,并提供强有力的有序保障。然而在多线程下还需要小心面对顺序问题:比方说遇到异常重发请求时,重发请求可能排在其他线程请求后面了。
处理状态变化(监视点+通知)
引言
轮询(不好的方式)
例如监视主节点崩溃, 假设备份节点以50ms/次的频率积极轮询, 那么轮询的请求量= (50ms*备份节点个数n)/次。虽然Zookeeper可以很轻松处理这些请求,但主节点崩溃的情况很少发生,这些请求其实是多余的。
监视点(改进方式)
通过监视点(watch),客户端可以对指定的znode节点注册一个通知请求,在发生变化时就会收到一个单次的通知。
如何检测主节点崩溃
- 主节点在zookeeper树上创建一个临时节点,来标示主节点锁。
- 备份节点注册一个监视器来监视这个锁是否存在
- 如果主节点崩溃,这个临时节点就会自动删除;同时备份节点会受到通知,它们就可以开始进行主节点选举。

案例:单次触发器
| 术语 | 说明 |
|---|---|
| 事件(event) | 一个znode节点执行了更新操作 |
| 监视点(watch) | 如:znode节点被赋值,或被删除 |
| 通知(notification) | 注册了监视点的应用客户端收到的事件报告消息 |
- 监视点是一次性的触发器: 例如,对/master设置监视点后,/master节点数据被修改了了,客户端会收到一次通知, 但下次数据再变化,客户端就不会再收到通知了。除非再次设置监视点。
- 当一个zookeeper客户端与服务端A断开连接后(注意,并非会话过期,会话过期会删除监视点),连接到服务端B。客户端会给B发送未触发的监视点列表。B会检查列表中注册监视点后是否有变化,如有,通知客户端。没有,注册监视点
事件丢失
- 事件是可能丢失的,但并不是问题。
- 事件丢失: 一个事件A发生,通知客户端。在客户端继续添加监视点之前,又发生了事件B,此时没有监视点,事件B不会发送通知,于是丢失
- 为什么不是问题: 下一个监视点设置的时候,可以查看最新的状态(终态)。中间的变化不用关心
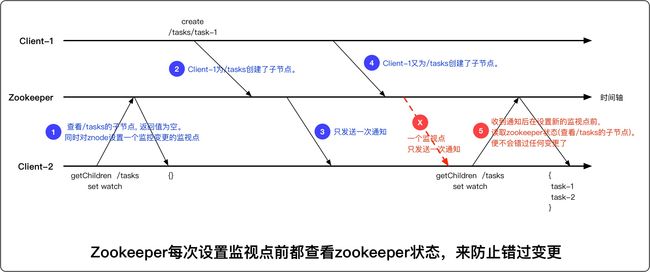
批量通知
多个事件分摊到一个通知上具有积极作用,比如进行高频率的更新操作时,就比较轻量了。
如何设置监视点
Zookeeper的API中所有读操作: getData,getChildren,exists均可以设置监视点
// API
public byte[] getData(final String path,Watcher watcher(自定义监视点),Stat stat)
public byte[] getData(String path,boolean watch(true=使用默认监视点),Stat stat)
// API中watcher的实现类
public class Master implements Watcher {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("监控: "+watchedEvent);
}
}
WatchedEvent的数据结构
public class WatchedEvent {
private final KeeperState keeperState;// 会话状态,枚举类型: Disconnected,SyncConnected,AuthFailed,ConnectedReadOnly,SaslAuthenticated,Expired
private final EventType eventType;// 事件类型, 枚举: NodeCreated,NodeDeleted,NodeDataChanged,NodeChildrenChanged,None(无事件发生,而是Zookeeper的会话状态发生了变化)
private String path;//事件类型不是None时,返回一个znode路径
}
- 监视点有两种类型
- 数据监视点: exists,getData可以设置数据监视点
- 子节点监视点: getChildren可以设置子节点监视点,这种监视点只在znode子节点创建或删除时才被触发
| 事件类型 | 可设置该事件监视点的API |
|---|---|
| NodeCreated | exists |
| NodeDeleted | exists,getData |
| NodeDataChanged | exists,getData |
| NodeChildrenChanged | getChildren |
- 监视点一旦设置就无法移除,如果要移除,只有两个方法
- 触发这个监视点
- 使其会话被关闭或过期
API的普遍模型
以下以exists为例,介绍API的普遍模型,该框架使用非常广泛
// 异步调用方式
zk.exists("/myZnode",myWatcher,existsCallback,null应用上下文,会作为callback参数);
Watcher myWatcher = new Watcher(){
public void process(WatchedEvent e){
// Watcher的实现
}
}
StatCallback existsCallback = new StatCallback(){
public void processResult(int rc, String path, Object ctx, Stat stat){
//exists的回调对象
}
}
故障处理
故障发生点
- Zookeeper服务
- 网络
- 应用
可恢复的故障场景
| 场景 | 说明 |
|---|---|
| 正常情况 | 客户端在从Zookeeper获得响应时,可以非常肯定它与其它客户端获得的响应均保持一致 |
| 客户端与Zookeeper服务连接丢失时 | 客户端会使用Disconnected事件和ConnectionLossException异常来表示自己无法了解当前的系统状态 |
Disconnected事件和ConnectionLossException异常
处理
- 客户端会不断尝试重新连接另一个Zookeeper服务器,直到重新建立了会话
- 一旦会话重新建立,Zookeeper会做如下事情:
- 产生一个SyncConnected事件,并开始处理请求
- 注册之前已经注册过的监视点,对期间发生的变更产生监视点事件
典型原因
一个典型原因是因为Zookeeper服务器故障
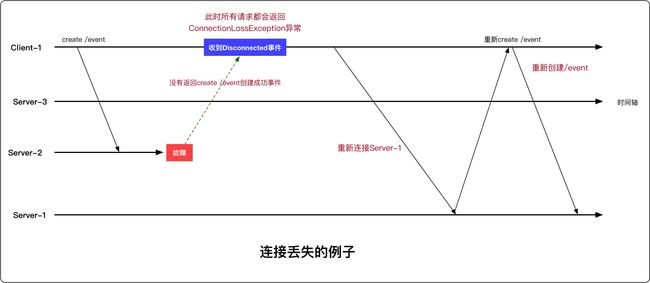
影响和处理
连接丢失时,如果客户端还存在进行中的请求要处理,就会产生很大的影响,开发中要谨慎处理
- 连接丢失时,虽然会返回ConnectionLossException和CONNECTIONLOSS返回码,但客户端无法通过这些异常和返回码来判断请求是否已经被处理
- 客户端开发时,需要正确处理连接丢失的情况,以保证最小的系统开销和损坏。而不是简单处理(如重启客户端)
举例
- 以下是出现两个群首的例子,如果开发不仔细,系统中会出现两个群首。
- 因此,当一个进程收到Disconnected事件时,在重新连接之前,进程需要挂起群首的操作。
- 客户端失去连接一段时间,客户端开发者通常会选择关闭会话。有一点需要注意,由于此时已失去连接了,Zookeeper服务端并不会感知客户端关闭了会话,服务端依然会等待会话过期时间过去后才声明会话已过期

FAQ
当网络中断持续一段时间,客户端连接另一个服务器可能会发生一个长延时。为什么客户端没有网络中断的某一个时刻(如2倍会话超时时间)作出判断,而一直连接那个超时的服务器呢?
- Zookeeper将这种策略问题的决定权交给开发者处理(即程序员自己写代码处理),而不是客户端API。因为开发者可以很容易实现关闭句柄这种策略
- Zookeeper集群集体停机导致的网络中断,时间冻结,然而恢复后,会话超时时间被重置,因此会出现较长的延迟。对于Zookeeper集群故障,客户端是不需要做额外处理的。
- 总之,对于网络中断的情况,开发者应该根据自己的实际情况选择自己关闭会话,而不是依赖客户端API(它才不管你)
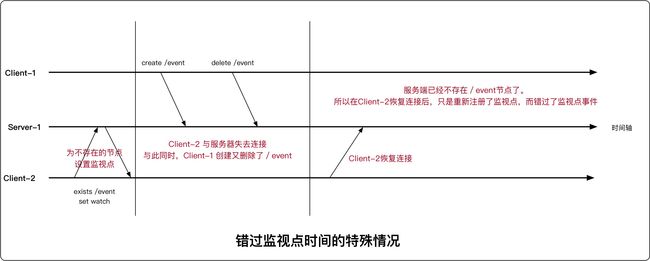
Disconnected导致的错过监视点事件的特殊情况
- Disconnected恢复后,Zookeeper客户端库会在会话重新建立时,建立所有已经存在的监视点
- 然后客户端会发送监视点列表和最后已知的zxid(最终状态的时间戳),服务器会接受并检查监视点列表中各znode节点的修改时间戳,如果晚于zxid,服务器就会触发这个监视点
- 每个Zookeeper操作都完全符合以上逻辑。除了exists,因为exists可以在一个不存在的节点上设置监视点
- 因此exists会导致如下一种错过监视点事件的特殊情况,解决方案是:尽量避免监视一个znode节点的创建事件。如果一定要监视创建事件,也要选择监视存活时期更长的znode节点
Disconnected恢复后,自动重连处理的危害
- 通常,Disconnected恢复后,有些Zookeeper封装库通过简单的补发命令自动处理连接丢失的故障
- 有时候会导致错误的结果,比如:在建立/leader节点时,出现Disconnected。重连后,再执行建立/leader节点就可能出错,因为其它节点可能已经建立了/leader
不可恢复的故障
Zookeeper丢弃会话的情况
- 会话过期
- 已认证的会话无法再次与Zookeeper完成认证
丢弃会话的影响
- 会话被意外丢弃,会导致临时性节点丢失
处理方式
- 最简单的方法就是终止进程并重启。这样可以通过一个新的会话重新初始化自己的状态
- 如果不重启,首先必须要清楚与旧会话关联的应用内部的状态信息,然后重新初始化新的状态
从不可恢复故障自动恢复的危害
现在Zookeeper句柄与会话之间是一对一的关系,早先的Zookeeper不是,所以会出现这种情况: 旧句柄会话是群首,新句柄使用同一个会话操作只有群首有权操作的数据。
群首选举和外部资源
- 只要客户端与Zookeeper进行任何交互操作,Zookeeper都会保持同步。注意前提是: 客户端与Zookeeper进行了交互
- 如果客户端与Zookeeper没有交互,则Zookeeper无法保证上述视图的一致性
- 没有交互的情况举例:
- 客户端服务器过载,导致无法及时发送心跳,进而导致会话超时,客户端却仍然以为自己仍然是主节点
- 一个很普遍的资源中心化管理方法(用来确保一致性): Zookeeper确保每次只有一个主节点可以独占访问一个外部资源
协调外部资源的一个棘手问题
下图展示了在协调外部资源(如DB)时出现的一个很棘手的问题。(超载,时钟偏移都可能导致该问题)
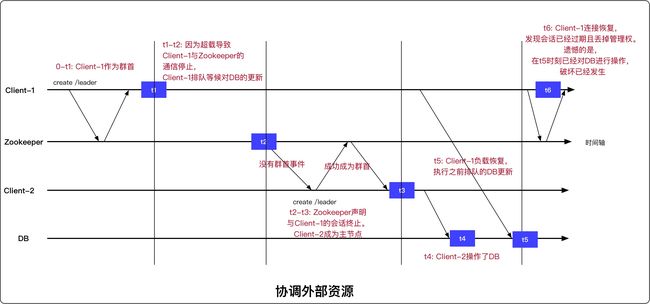
解决方案:
确保应用不会在超载或时钟偏移的环境中运行: 小心监控系统负载;良好设计的多线程应用;时钟同步程序保证时钟同步
-
使用一种名为隔离的技巧,分布式系统常常使用这种方法用于确保资源的独占访问(即连接外部资源时使用一个版本号,如果外部资源已经接收到更高版本的隔离符号,则请求或连接就会被拒绝)。具体做法是:使用Stat结构成员变量czixd,它表示创建该节点时的zxid,zxid为唯一的单调递增序列号,所以可以使用czxid作为一个隔离符号
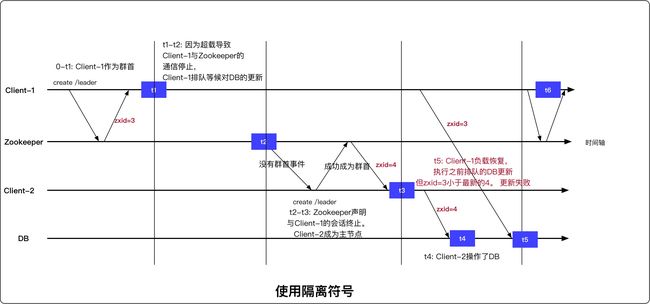
Zookeeper内部原理
请求,事物,标识符
请求类型
| 请求类型 | 举例 | 处理方式 | 说明 |
|---|---|---|---|
| 只读请求 | exists,getData,getChildren | Zookeeper服务器会在本地(群首或从节点)处理 | 因为在本地处理,所以Zookeeper在处理以只读请求为主要负载时,性能会很高。增加更多服务器到集群,可大幅提高整体处理能力,处理更多读请求 |
| 写请求 | create,delete,setData | 将会被转发给群首处理 | - |
事务
以对/z节点setData为例, 事务= 新的数据字段+ 新的版本号。处理该事务时,服务端会用事务中的数据信息替换/z节点中原有的数据信息,并会用事务中的版本号更新该节点版本号(而不是简单对节点版本号+1)
- 一个事务就是一个单位,不会被其它事务干扰。(早期,Zookeeper通过服务器单线程来保证事务顺序执行,后来增加了多线程支持)
- 事务还具有幂等性。即可以对同一个事务执行多次
标识符
群首产生了一个事务,就会为该事务分配一个标识符,称之为Zookeeper会话ID(zxid), 通过zxid可以判断执行顺序
- zxid = 时间戳+计数器
群首选举
群首为集群中的服务器选择出来的一个服务器,并会一直被集群认可。群首的作用: 对客户端写请求进行排序, 并转换为事务
单个服务器启动过程

选主投票
-
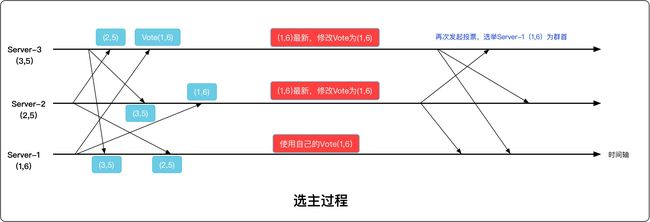
群首选举通知消息(leader election notifications)
- 当一个服务器进入LOOKING状态,就会向集群中每个服务器发送一个通知
- 一个服务器发送的投票信息为: (1,5), 表示该服务器sid为1,最近执行的事务zxid为5
- 出于群首选举的目的,zxid只有一个数组,而其他协议中,zxid则还有时间戳epoch和计数器
 投票
投票- 当一个服务器接收到仲裁数量的服务器发来的投票都一样时,就表示群首选举成功;如果被选举的群首为自己,则该服务器行使群首角色,否则就成为追随者并尝试连接群首(不一定连接成功,一旦连接成功,则会进行状态同步,在同步完成后,追随者才可以处理新的请求)
选主过程
- Zookeeper实现选主的Java类为QuorumPeer,超时时间定义在FastLeaderElection中(200ms), 如果要自定义选主实现算法,可实现quorum包中的Election接口

Zab协议
- Zab: Zookeeper原子广播协议(Zookeeper Atomic Broadcast protocol)
- 在接收到一个写请求后,追随者会将请求转发给群首,群首将探索性地执行该请求,并将执行结果以事务的方式对状态进行广播
- 引入Zab协议,以帮助服务器确认一个事务是否已经提交
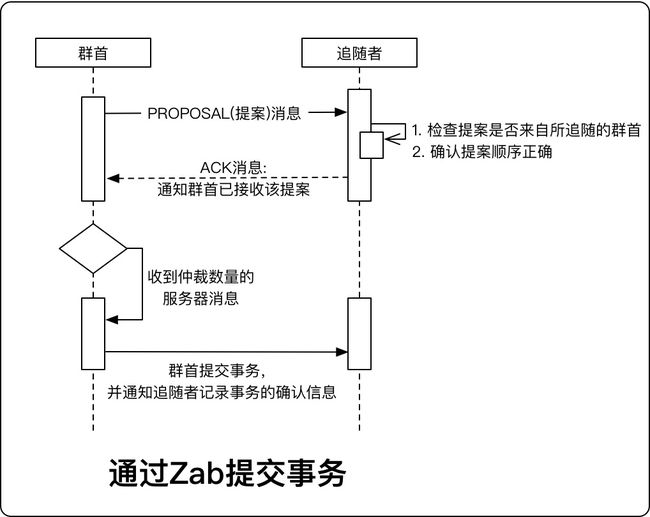
| Zab对下列事项提供保障 | 说明 |
|---|---|
| 如果群首按顺序广播事务T1,T2。那么每个服务器在提交T2前保证T1已经提交完成 | 保证事务在服务器之间传送顺序一致 |
| 如果某个服务器按照T1,T2的顺序提交事务,所有其他服务器也必然会在T2前提交T1 | 保证服务器不会跳过任何事务 |
多群首问题
- Zookeeper使用时间戳来解决多群首问题(集群中出现多个群首),zxid第一个元素为时间戳信息。
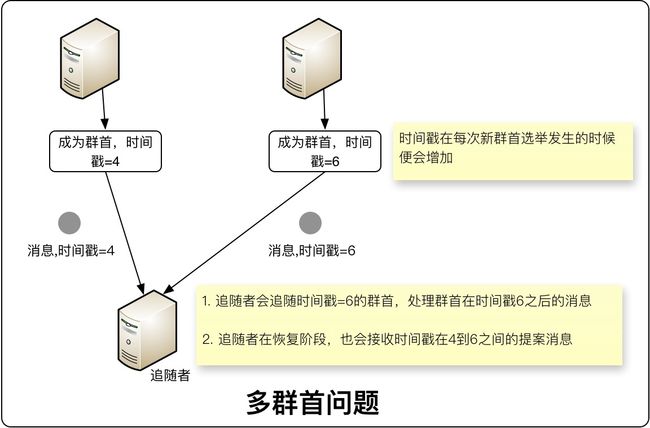
- 阻止系统中同时出现多个群首是非常困难的,因此广播协议不能基于以上假设。为了解决这个问题,Zab协议提供了以下保障
| Zab对下列事项提供保障 | 说明 |
|---|---|
| 群首确保提交完所有之前的时间戳内需要提交的事务,才开始广播新事务 | 1.群首不会马上处于活动状态,直到确保仲裁数量的服务器认可这个群首新的时间戳 2.一个时间戳的最初状态,必须包含之前已经提交的事务,或已经被其他服务器接受,但尚未提交完成的事务 3.如果一个提案消息时间戳为4,但它在新群首处理第一个提案消息(时间戳6)之前没有提交,那么旧提案将永远不会被提交 |
| 任何时间点,都不会出现两个被仲裁支持的群首 | 保证服务器不会跳过任何事务 |
- 群首发生重叠的情况: [旧群首失效----新群首生效]期间,仲裁服务器中有一个服务器还未追随新群首,因此它接收旧群首的提案A,其它的服务器追随新群首,而未接收提案A。此时事务A依然会提交。因为新群首在生效前会学习旧仲裁服务器之前接受的所有提议,并保证他们不会再接收来自旧群首的提议
- 时间戳发生转换时,Zookeeper使用两种不同的方式来更新追随者优化这个过程
- 追随者之后群首不多:群首只需发送缺失的事务点
- 滞后太多:发送群首拥有的最新完整快照
观察者
- 服务器类型:群首,追随者,观察者
- 观察者,追随者共同点是:提交来自群首的提议;不同点是:观察者不参与选举
- 引入观察者的目的:
- 提高读请求的可扩展性。写操作吞吐率与仲裁者数量成反比,引入追随者能提高读服务器数量,而不改变仲裁者数量,从而不降低写操作吞吐率,提高读操作效率
- 进行跨多个数据中心部署。引入观察者后,更新请求能够以高吞吐率和低延迟的方式在一个数据中心进行,接下来再传播到异地的其他数据中心得到执行
服务器的构成
- 服务器:群首,追随者,观察者根本上都是服务器。
- 处理流水线: 处理一个请求的一系列过程
- 请求处理器:处理流水线上的每一个过程就是请求处理器
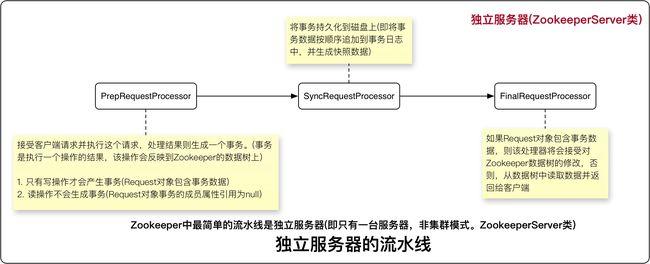
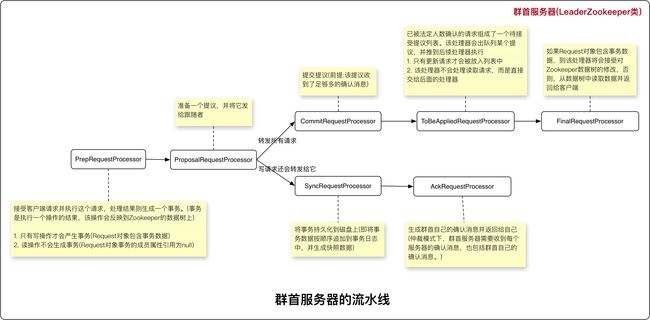
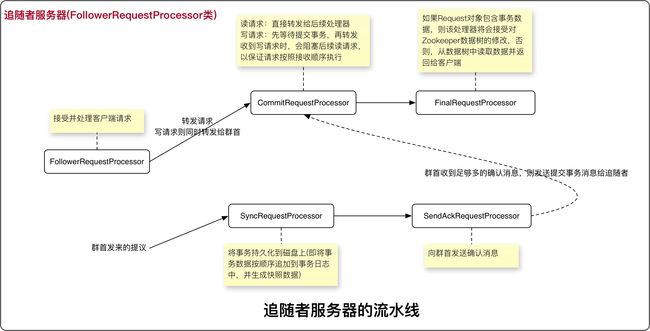
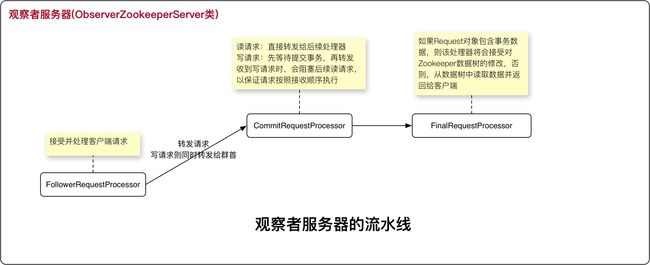
本地存储
SyncRequestProcessor处理器用于在处理提议时写入日志和快照。在接受一个提议时,一个服务器(追随者或群首服务器)就会将提议的事务持久化到日志中,该事务日志保存在服务器的本地磁盘中
日志和磁盘的使用
为了写日志更快,使用一下两种手段
- 组提交: 即事务先放在内存队列中,定期flush到磁盘。
SyncRequestProcessor.run() - 补白: 在文件中预分配磁盘存储块,而不是每次写到文件结尾时,文件系统都需要分配一个新的存储块
- 为避免受到系统中其他写操作干扰,强烈推荐将事务日志写入到一个独立的磁盘,与 操作系统文件,快照文件分开
快照
- 快照是Zookeeper数据树的拷贝副本,每个服务器会经常以序列化整个树的方式来提取快照,并保存到文件中
- 服务器进行快照时不需要进行协作,也不需要暂停处理请求。
- 如果快照过程中,数据树由于处理请求而发生变化,那么称这样的快照是模糊的,它不能反映出任意给定的时间点数据树的准确状态
服务器与会话
- 独立模式下
- 单个服务器跟踪和维护所有会话(SessionTracker类 和 SessionTrackerImpl类)
- 仲裁模式下
- 群首服务器跟踪和维护会话(和独立模式的服务器一样,都是SessionTracker类 和 SessionTrackerImpl类)
- 追随者服务器仅仅是简单地把客户端连接的会话信息转发给群首(LearnerSessionTracker类)
-
为保证会话存活,服务器需要接收会话的心跳信息,心跳的形式有:
- 新的请求
- 显示的ping消息(LearnerHandler.run())
- 以上两种情况,服务器通过更新会话的过期时间来出发会话活跃(SessionTrackerImpl.touchSession())
- 仲裁模式下,群首服务器发送一个ping给追随者们,追随者返回上次ping之后的一个session列表
-
管理会话过期
-
Zookeeper将"会话过期(名词)"维护在过期队列(expiry queue)中,它分为多个bucket

- 使用bucket模式来管理的主要原因是减少让会话过期这项工作的系统开销。以适当的细粒度来检查会话过期
-
服务器与监视点
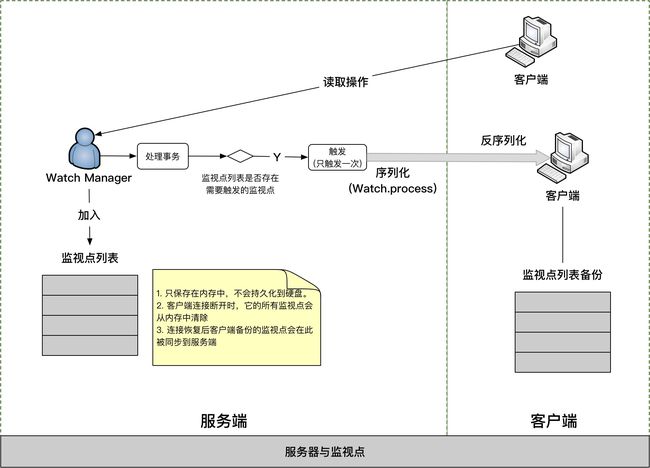
客户端
客户端库主要有两个类
- Zookeeper类
- 写客户端代码时,需要实例化该类来建立一个会话。
- 一旦建立了一个会话,Zookeeper会使用服务端生成的会话标识符(SessionTrackerImpl类)来关联该会话
- ClientCnxn类
- 管理连接到server的Socket连接
- 该类维护一个可连接的Zookeeper服务器列表,在连接断掉时无缝切换到其他服务器(使用同一个会话)
- 重连会重置所有监视点到新服务器(ClientCnxn.SendThread.primeConnection()), 可使用disableAutoWatchReset禁用(默认开启)
序列化
- 使用场合
- 网络传输
- 磁盘保存
- Zookeeper使用了Hadoop中的Jute来做序列化(org.apache.jute)
- Jute定义文件为zookeeper.jute,它包含所有的消息定义和文件记录
运行Zookeeper
配置Zookeeper服务器
- Zookeeper配置文件为: zoo.cfg, 很多参数也可以通过java的系统属性传递, 如
-Dzookeeper.propertyName - data目录: 它可以保存一些差异化文件,其中myid文件用于区分各个服务器
| key | 说明 |
|---|---|
| 基本配置 | - |
| clientPort | 给客户端连接的端口号,默认2181 |
| dataDir | 配置内存数据库保存的模糊快照目录,id文件也保存在该目录下. 并不需要配置到一个专用存储设备上,快照后台异步写入,且不会锁数据库 |
| dataLogDir | 事务日志存储目录,事务日志顺序同步写入,推荐使用专用的日志存储设备 |
| tickTime | 定义Zookeeper使用的基本时间度量单位(毫秒). 默认3000毫秒。最小超时时间=1 tick,客户端最小会话超时时间= 2 tick,更低的tickTime可以更快发现超时,但会导致更高的网络流量(心跳消息)和cpu(会话存储器处理) |
| 存储配置 | - |
| preAllocSize | 预分配的事务日志文件大小(KB),默认64MB。预分配的目的是减少文件寻址操作的次数和其它开销。每次快照后会重启一个新的事务日志,因此100次快照会有100*64KB磁盘开销,如果事务文件平均100B,那么设置100KB比较合适 |
| snapCount | 1.每次快照之间的事务数,默认100000(10w). 2.服务器重启恢复状态耗时(A)=读取快照耗时(B)+快照后所发生事务的执行时间(C),使用快照可以减少C,但会影响服务器性能。 3.集群中仲裁服务器最好不要同时进行快照(将snapCount设置为随机数); 4.如果前一个快照任务正在进行,后一个快照任务就会等待 |