1. 什么是greenDao
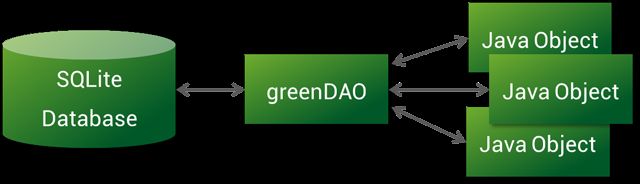
弄明白greenDao之前我们应该先了解什么是ORM(Object Relation Mapping 即 对象关系映射),说白了就是将面向对象编程语言里的对象与数据库关联起来的一种技术,而greenDao就是实现这种技术之一,所以说greenDao其实就是一种将java object 与SQLite Database关联起来的桥梁,它们之间的关系 如下图所示;
2. 为什么要使用greenDao
greenDao可以说是当今最流行,最高效而且还在迭代的关系型数据库。而且greenDao3.0还支持RxJava操作,greenDao如此受欢迎离不开以下几点:
- 存取速度快
每秒中可以操作数千个实体 下图是几种常见关系型数据库性能比较;
 几种常用数据库比较
几种常用数据库比较 - 支持数据库加密
支持android原生的数据库SQLite,也支持SQLCipher(在SQLite基础上加密型数据库)。 - 轻量级
greenDao的代码库仅仅100k大小 - 激活实体
处于激活状态下的实体可以有更多操作方法 - 支持缓存
能够将使用的过的实体存在缓存中,下次使用时可以直接从缓存中取,这样可以使性能提高N个数量级 - 代码自动生成
greenDao 会根据modle类自动生成实体类(entities)和Dao对象,并且Dao对象是根据entities类量身定做的并且一 一对应。
3. 怎样使用greenDao
3.1 入门
3.1.1 配置GreenDao
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.greenrobot:greendao-gradle-plugin:3.2.0'//greenDao生产代码插件
}
apply plugin: 'org.greenrobot.greendao'//greendao插件
dependencies {
compile 'org.greenrobot:greendao:3.2.0'
配置数据库信息
greendao {
//数据库schema版本,也可以理解为数据库版本号
schemaVersion 2
//设置DaoMaster 、DaoSession、Dao包名
daoPackage 'com.qhn.bhne.footprinting.db'
//设置DaoMaster 、DaoSession、Dao目录
targetGenDir 'src/main/java'
//设置生成单元测试目录
// targetGenDirTest
//设置自动生成单元测试用例
// generateTests
}
到这里数据库基本配置已经完成,接下来让我们一起来了解下greenDao的核心类该怎样使用吧。
3.1.2 核心类介绍
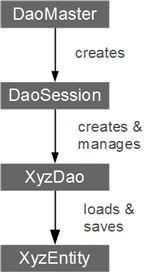
**DaoMaster: **
是GreenDao的入口也是greenDao顶级对象,对于一个指定的表单持有数据库对象(SQLite数据库)并且能够管理DAO类
能够创建表和删除表
其内部类OpenHelper 与DevOpenHelper是创建SQlite数据库的SQLiteOpenHelper的具体实现
DaoSession:
对于一个指定的表单可以管理所有的Dao 对象。
也能够对实体类执行 insert ,load,update,refresh.delete操作。
DaoSession也能跟踪 identity scope:即session查询后的实体会存在缓存中,并给该实体生成一个flag来追踪该实体,下次再次查询时会直接从缓存中取出来而不是从数据库中取出来
DAOS
能够持久访问和查询实体类
比起DaoSession有更多的持久化方法 count, loadAll,insertInt等等;
Entities - 自动生成的代码,一般情况下与javaBean对象的属性一一对应。
3.1.3 构建Model类
Molde类需要用java类来定义并且可以通过GreenDao中的注释来表明Model中的每个属性在数据库的中该如何定义;定义model类后点击Make project选项GreenDao就会自动生成DaoMaster,DaoSession,和DAOS类,生成的代码将会保存在预先在budle gradle中设置的位置
- 实体和注释
GreenDao 通过注释来定义表单与实体
@Entity
public class User {
@Id
private Long id; private String name;
@Transient
private int tempUsageCount; // 没有存入数据库中
}
@Entity
- 告诉GreenDao 该Bean类需要持久化。只有使用@Entity注释的Bean类才能被dao类操作;
- @Entity可以在不使用参数下使用,但是也可以给Entity配置参数,其参数如下
//如果该实体属于多个表单,可以使用该参数;
schema = "myschema",
// 该实体属于激活状态,激活状态的实体有更新,删除,刷新方法;
active = true,
// 给这个表指定一个名字,默认情况下是名字是类名
nameInDb = "AWESOME_USERS",
// 可以给多个属性定义索引和其他属性.
indexes = { @Index(value = "name DESC", unique = true) },
//是否使用GreenDao创建该表.
createInDb = false,
// 是否所有的属性构造器都应该被生成,无参构造器总是被要求
generateConstructors = true,
// 如果该类中没有set get方法是否自动生成
generateGettersSetters = true
基本注释属性
@ID 一般会选择long/Long属性作为Entity ID(即数据库中的主键)autoincrement=true表示主键会自增如果false就会使用旧值
@Property 可以自定义一个该属性在数据库中的名称,默认情况下数据库中该属性名称是Bean对象中的 属性名但是不是以驼峰式而是以大写与下划线组合形式来命名的比如:customName将命名为 CUSTOM_NAME;注意:外键不能使用该属性;
@NotNull 确保属性值不会为null值;
@Transient 使用该注释的属性不会被存入数据库中;
@Unique 将属性变成唯一约束属性;也就是说在数据库中该值必须唯一
@Generated 提示开发者该属性不能被修改;并且实体类的方法,属性,构造器一旦被@Generated注释就不能被再次修改,否则或报错
Error:Execution failed for task ':app:greendao'.> Constructor (see
ExampleEntity:21) has been changed after generation.Please either mark
it with @Keep annotation instead of @Generated to keep it untouched,or
use @Generated (without hash) to allow to replace it.
这是因为在通过javabean对象自动生成entities类时,greenDao会增加实体类代码,@Generated注释部分与GreenDao增加的代码相关,胡乱修改@Generated代码,就会导致entities部分属性与javabean不匹配导致报错;有俩种方法可以避免这种错误
还原@Generated 改动的部分,当然你也可以完全删除@Generated 注释的部分下一次 app build时将会自动生成;
使用@Keep 代替@Generated 这将告诉greenDao 不会使用该属性注释的代码,但是这种改变可能会破坏entities类和greenDAO的其他部分的连接;注意:默认情况下 greenDao会使用合理的默认值去设置实体类,因此开发者不需要为每个属性都添加注释
@Entity
public class User {
@Id(autoincrement = true)
private Long id;
@Property(nameInDb = "USERNAME")
private String name;
@NotNull
private int repos;
@Transient
private int tempUsageCount;
...}
- 主键限制
每个实体类都应该有一个long或者LONG型属性作为主键;如果你不想用long或者LONG型作为主键,你可以使用一个唯一索引(使用@Index(unique = true)注释使普通属性改变成唯一索引属性)属性作为关键属性。
@Id
private Long id;
@Index(unique = true)
private String key;
- 索引属性
使用@Index 可以将一个属性变为数据库索引;其有俩个参数 - name :不使用默认名称,自定义索引名称
- unique : 给索引增加一个唯一约束,迫使该值唯一
@Entity
public class User {
@Id
private Long id;
@Index(unique = true)
private String name;
}
- 核心代码初始化
创建数据库过程
// 下面代码仅仅需要执行一次,一般会放在application
helper = new DaoMaster.DevOpenHelper(this, "notes-db", null);
db = helper.getWritableDatabase();
daoMaster = new DaoMaster(db);
daoSession = daoMaster.newSession();
// 在activity或者fragment中获取Dao对象
noteDao = daoSession.getNoteDao()
完成以上所有工作以后,我们的数据库就已经自动生成了,接下来就可以对数据库进行操作了;
增删改查
greenDao的增,删 ,改操作比较简单分别调用insert(),delete(),update()方法即可,save()方法比较特殊既能执行插入操作也能执行修改操作这个具体的可以查看greenDaoAPI-
Query
与原生SQLitedatabases的查询操作相比,greenDao Query简直不能再简单;greenDao 使用QueryBuilder构建查询语句也支持原生的SQL查询语句- 简单的查询语句 在用户表中查询叫姓“Joe”的所有的用户:
List joes = userDao.queryBuilder()
.where(Properties.FirstName.eq("Joe"))
.orderAsc(Properties.LastName) .list();
- 嵌套挑去查询语句:查询一个出生在1970年10月或者以后的"joe"用户
QueryBuilder qb = userDao.queryBuilder();
qb.where(Properties.FirstName.eq("Joe"),//第一个约束条件姓乔
qb.or(Properties.YearOfBirth.gt(1970),//或者出生日期大于1970年
qb.and(Properties.YearOfBirth.eq(1970),
Properties.MonthOfBirth.ge(10))//并且在1970年出生 但是月份大于
10月的));
List youngJoes = qb.list();
greenDao除了eq()操作之外还有很多其他方法大大方便了我们日常查询操作比如:
- eq():==
- noteq():!=
- gt(): >
- lt():<
- ge:>=
- le:<=
- like():包含
- between:俩者之间
- in:在某个值内
- notIn:不在某个值内
- 分页查询
- limit(int): 限制查询的数量;
- offset(int): 每次返回的数量; offset不能单独使用;
- 查询与LazyList类
Query : Query类表示一个查询能够执行很多次;而当通过QueryBuilder的任何查询方法(eg:list())来获取查询结果时,querybuilder都会 在其内部创建Query来执行查询语句的;如果执行多次查询应该使用Query对象; 如果只想获取一个结果时可以使用Query(or QueryBuilder)中的unique()方法;
LazyList : 可以通过以下方法获取查询结果集合;
list() 缓存查询结果;list()类型一般为ArrayList
listLazy() 懒查询,只有当调用list()中的实体对象时才会执行查询操作并且只缓存第一次被查询的结果,需要关闭
listlazyUncached() 懒查询,只有当调用list()中的实体对象时才会执行查询操作并且不缓存;
listIterator() 对查询结果进行遍历,不缓存,需要关闭;
后面三个方法是LazyList类中的方法,LazyList为了执行不同的缓存策略其内部持有数据库的cursor对象;一般情况下这三个方法执行完毕后会自动关闭cursor;但是防止在还没有执行完查询结果时,对象被终结cursor还是无法被关闭的情况发生,需要手动关闭close();
- 多次执行查询语句
Query对象一旦生成就能多次被使用,你也可以为下一次查询增加查询条件
// fetch users with Joe as a first name born in 1970Query
query = userDao.queryBuilder().where(
Properties.FirstName.eq("Joe"),
Properties.YearOfBirth.eq(1970)).build();List joesOf1970 =
query.list(); // using the same Query object, we can change the
parameters// to search for Marias born in 1977
later:query.setParameter(0, "Maria");query.setParameter(1,
1977);List mariasOf1977 = query.list();
在多线程执行查询
如果有多条线程执行查询语句时需要调用forCurrentThread()方法将query对象与当前线程进行绑定,如果其他线程修改该Query对象,greenDao将会抛出一个异常;forCurrentThread()方法通过将Query创建时的时间作为 query标识;使用SQL查询
如果QueryBuilder不能满足需求可以使用以下俩种方法来实现你的需求;首选方法用SQL语句:
Query query = userDao.queryBuilder().where( new
StringCondition("_ID IN " + "(SELECT USER_ID FROM
USER_MESSAGE WHERE READ_FLAG = 0)")).build();
- 备选方法 :
使用queryRaw 或者queryRawCreate:
Query query = userDao.queryRawCreate( ", GROUP G WHERE
G.NAME=? AND T.GROUP_ID=G._ID", "admin");
好了这一期的GreenDao的介绍到这里就结束了,本期主要讲解了greenDao的基本概念与基本操作,下一期(史上最高效的ORM方案——GreenDao3.0高级用法)我会介绍GreenDao的高级操作:session缓存,多表查询,多表关联,自定义参数类型。如果你觉得本篇本章有什么不足的地方欢迎在评论区留言;
最后原创不易,喜欢的点个喜欢或者关注一下吧!!