为什么要进行SQL优化呢?很显然,当我们去写sql语句时:
- 1会发现性能低
- 2.执行时间太长,
- 3.或等待时间太长
- 4.sql语句欠佳,以及我们索引失效
- 5.服务器参数设置不合理
SQL语句执行过程分析
1.编写过程:
编写过程就是我们平常写sql语句的过程,也可以理解为编写顺序,以下就是我们编写顺序:
select from join on where 条件 group by 分组 having过滤组 order by排序 limit限制查询个数
我们虽然是这样去写的,但是它mysql的引擎去解析时,并不是依照我们以上编写的这样的顺序;
它并不是先解析select 而是先解析from,也就说,我们的解析过程跟编写过程是不一致的,所以我们看下发的解析顺序
2.解析过程:
from on join where group by having select order by limit
以上就是mysql的解析过程,我们发现,跟我们编写的过程完全不一致!
索引
什么是索引(index)?简单的来讲就是书的目录;
比如说我现在要通过字典来查“王”这个字,如果你在没有目录的情况下去找“王”这个字,你就需要把这个字典从头到尾的翻一遍,如果有一千页,你就必须一页一页的去翻,直到找到为止;
索引就相当于目录,查这个“王”之前先去翻看目录,发现“W”在300页,因为王首字母是“W”,我们直接去在300页中找,这样找起来就非常快;
索引在数据库中是关键字insex,用官方的定义的意思来说,索引就是帮助MySQL快速高效的获取数据的数据结构;
索引是一个数据结构,它是一个为了高效查询数据的数据结构;
那它到底是什么数据结构呢?
其实它就是一个树,我们用的比较多的就是B树、Hash树,在MySQL里面,用的就是B树索引;
B树索引
首先我画一个图,假装这个是数据表,并且给age列加一个索引:
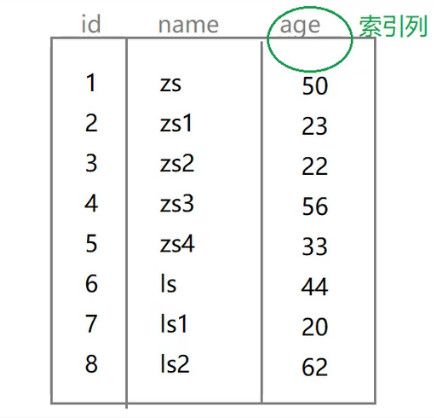
就把这个索引当成一个目录,也就是age为50的,就指向第一行,age为33的,指向第五行;
下面我会将B树索引画出来,看看到底是怎么索引了:
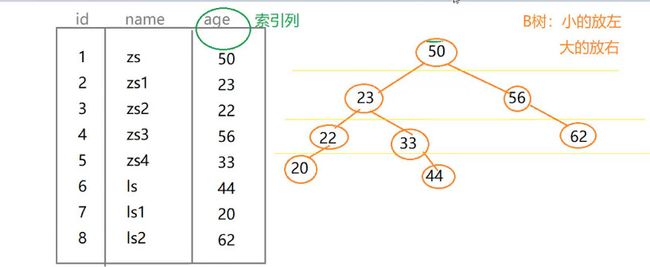
我们给age加了索引列后,它就会像树一样,把小的放到左边,把大的放到右边,第一列为50,比50小的在左边,23,比23小的继续向左排列,
33比23大,就向左排列20比22小就在22后面继续向左排列,以此类推!
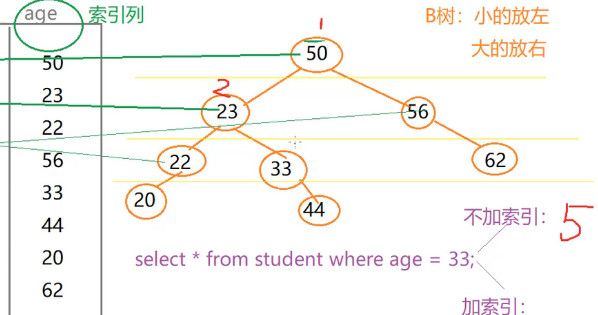
比如我们现在需要查33:
select * From 表名 where age = 33;
不加索引的话,就会从50开始查,50不是 23,不是22不是....,不加索引就一个个去找;
如果加索引的话,找33,发现33比50小,第一次,再去找23,第二次,33比23大,第三次,仅需三次就查到了:
索引的弊端
1.索引本身很占空间,可以存放在内存/硬盘(通常)
2.索引不是所有情况均可适用比如:少量数据、频繁更新的字段(如果数据表中的某一列经常会发生改变,那么这一列就不适合做索引)
3.索引确实可以提高查询效率,但是同时会降低增删改的效率,比如:
我们没有索引,你改44,改成45,很好改,直接改就行了,如果你有索引,我不光要改表里面的44,我需要把B树里面的44也要改:

有些人就觉得不划算了,提升一个降低三个,这样就很不划算了,其实很划算的!
因为我们大部分情况下都是在查询,增删改很少,因为查询影响性能很大的,所以非常有必要使用它
索引的优势
1.提高了查询效率
客户端到服务端,链接服务端是通过IO,通过输入输出流,所以说,提高查询效率就是降低了IO的使用率
2.降低CPU使用率
比如说我sql里面有一个order by desc 根据年龄降序或升序,如果没有索引,你需要把age全部拿出来全部排个序,但是如果有了索引,你就不需要排序了,B树本身就是一个排好序的结构,最左边必然是最小的,最最右边必然是最大的:
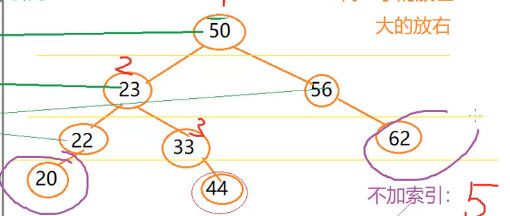
只需要根据一定的规则遍历出来就行了。
以上就是相关的B数索引的相关知识点,感谢大家的阅读和对脚本之家的支持。