[TOC]
ElasticSearch基础和实践
1. ES是什么
ES是一个开源的高扩展的分布式全文搜索引擎,它可以准实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
为何elasticsearch是准实时的
1. 1 全文检索(Full-text Search)
全文检索原理及实现方式
我们生活中的数据总体分为两种:结构化数据和非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等,又叫全文数据
半结构化数据,如XML,HTML等,根据需要可按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理
按照数据的分类,搜索也分为两种:
- 结构化数据的搜索:如对数据库的搜索,用SQL语句。再如对元数据的搜索,如利用windows搜索对文件名,类型,修改时间进行搜索等。
- 非结构化数据的搜索:如利用windows的搜索也可以搜索文件内容,Linux下的grep命令,再如用Google和百度可以搜索大量内容数据。
全文数据的搜索主要有两种方法:
顺序扫描法(Serial Scanning):所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。
-
全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
从非结构化数据中提取出的然后重新组织的信息,我们称之索引- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
1. 2 ES基本概念
1.2.1 MySQL与ES概念对比
| ElasticSearch | MySQL |
|---|---|
| index(索引,名词) | database(数据库) |
| type(类型) | table(表) |
| document(文档) | row(行) |
| field(字段) | column(列) |
| mapping(映射) | schema(模式) |
| query DSL(查询语言) | SQL |
1.2.2 其他
1)Cluster:集群
ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
2)Node:节点
形成集群的每个服务器称为节点。
3)Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
4)Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。
当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。

2. ES干什么
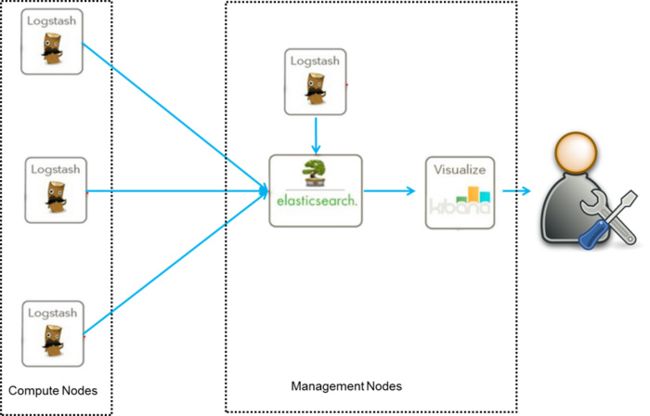
2.1 ELK日志分析系统(ElasticSearch,Logstash,Kibana)
2.2 基于现有应用系统提升搜索能力
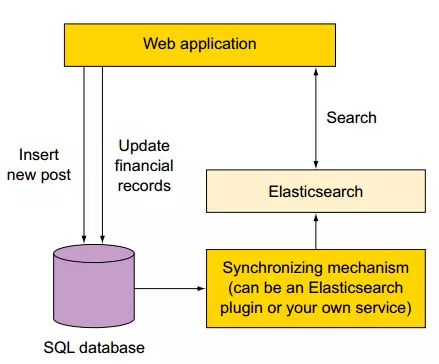
2.3 使用ES作为存储和检索服务器

3. ES怎么用
Mac下ElasticSearch安装
启动 Elasticsearch:
cd elasticsearch-
./bin/elasticsearch
3.1 Elasticsearch数据类型
映射中主要就是针对字段设置类型以及类型相关参数。
JSON基础类型如下:
- 字符串:string
- 数字:byte、short、integer、long、float、double、
- 时间:date
- 布尔值: true、false
- 数组: array
- 对象: object
Elasticsearch独有的类型:
- 多重: multi
- 经纬度: geo_point
- 网络地址: ip
- 堆叠对象: nested object
- 二进制: binary
- 附件: attachment
注意点:
Elasticsearch映射虽然有index和type两层关系,但是实际索引时是以index为基础的。建议一个index下面只有一个type。
3.2 mapping
mapping是类似于数据库中的表结构定义,主要作用如下:
定义index下的字段名
定义字段类型,比如数值型、浮点型、布尔型等
定义倒排索引相关的设置,比如是否索引、记录position等
PUT 127.0.0.1:3901/course_audit_aliased
{
"mappings":{
"course_audit_aliased":{
"properties":{
"id":{
"type":"keyword",
"ignore_above":256 //忽略所有长度超过256的字符串
},
"gmtCreate":{
"type":"long"
},
"gmtModified":{
"type":"long"
},
"courseId":{
"type":"long"
},
"courseName":{
"type":"text",
"analyzer":"ngram_analyzer"//NGram分词器
},
"ownerId":{
"type":"long"
},
"ownerName":{
"type":"text",
"analyzer":"ngram_analyzer"
},
"status":{
"type":"integer"
},
"liveFlag":{
"type":"integer"
},
"hasRecord":{
"type":"boolean"
},
"lastSubmitReviewTime":{
"type":"long"
}
}
}
},
"settings":{
"index":{
"refresh_interval":"1m",//每1min刷新索引
"number_of_shards":"2",
"translog":{
"durability":"async"
},
"merge":{
"scheduler":{
"max_thread_count":"1"
}
},
"analysis":{
"analyzer":{
"ngram_analyzer":{
"filter":[
"lowercase"
],
"type":"custom",
"tokenizer":"common_ngram_tokenizer"
}
},
"tokenizer":{
"common_ngram_tokenizer":{
"type":"nGram",
"min_gram":"1",
"max_gram":"256"
}
}
},
"number_of_replicas":"1"
}
}
}
3.2.1 Text vs Keyword
数据类型被用来索引长文本,比如说电子邮件的主体部分或者一款产品的介绍。这些文本会被分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。允许 ES来检索这些词语。text 数据类型不能用来排序和聚合。
Keyword 数据类型用来建立电子邮箱地址、姓名、邮政编码和标签等数据,不需要进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
3.3 Apache Lucene评分机制
默认评分机制
TF/IDF(词频/逆文档频率)算法
基本原则
- 匹配到的关键词越稀有,文档的得分就越高。
- 文档的域越小(包含比较少的Term),文档的得分就越高。
- 设置的权重(索引和搜索时设置的都可以)越大,文档得分越高。
3.4 基本查询
分页和结果集大小
from:该属性指定我们希望在结果中返回的起始文档。它的默认值是0,表示想要得到从第一个文档开始的结果。
size:该属性指定了一次查询中返回的最大文档数,默认值为10。如果只对切面结果感兴趣,并不关心文档本身,可以把这个参数设置成0。
过滤 is not null
"exists": {
"field": "gmtCreate"
}
返回版本值
"version": true
query_string和排序
GET /course_audit_aliased/course_audit_aliased/_search
{
"query": {
"query_string": {
"default_field": "courseName",
"query": "1"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
},
{
"lastSubmitReviewTime": {
"order": "asc"
}
}
]
}
3.5 结构化查询 Query DSL (Domain Specific Language)
term vs match
- term是精确查询,搜索前不会再对搜索词进行分词
- match是模糊查询
terms类似mysql的in
"terms" : {
"price" : [20, 30]
}
multi-match
{
"dis_max": {
"queries": [
{
"match": {
"title": {
"query": "Quick brown fox",
"minimum_should_match": "30%"
}
}
},
{
"match": {
"body": {
"query": "Quick brown fox",
"minimum_should_match": "30%"
}
}
},
],
"tie_breaker": 0.3
}
}
{
"multi_match": {
"query": "Quick brown fox",
"type": "best_fields",
"fields": [ "title", "body" ],
"tie_breaker": 0.3,
"minimum_should_match": "30%"
}
}
bool
Bool查询包括四种子句:must,filter,should, must_not。
filter快在两个方面:
- 对结果进行缓存
- 避免计算分值
{
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "from" : 10, "to" : 20 }
}
},
"should" : [
{
"term" : { "tag" : "wow" }
},
{
"term" : { "tag" : "elasticsearch" }
}
]
}
}
range
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
"query": {
"range": {
"status": {
"gte": 3,
"lte": 20
}
}
}
"query": {
"bool": {
"must": [
{
"term": {
"courseName": {
"value": "1"
}
}
},
{
"range": {
"status": {
"lte": 1
}
}
}
]
}
}
高亮
{
"query": {
"match": {
"courseName": "1"
}
},
"highlight": {
"pre_tags": [
""
],
"post_tags": [
""
],
"fields": {
"courseName": {}
}
}
}
3.6 分词
分词器比较
- 系统默认分词器
- 中文分词器:ik分词器
- 其他分词器
3.7 准实时
要把数据写到磁盘,需要调用 fsync,但是fsync十分耗资源,无法频繁的调用,在这种情况下,Elasticsearch 利用了filesystem cache,新文档先写到in-memory buffer,然后写入到 filesystem cache,过一段时间后,再将segment写到磁盘。在这个过程中,只要文档写到filesystem cache,就可以被搜索到了。
4. ES为什么可以这样子
4.1 倒排索引
倒排索引建立索引中词和文档之间的映射,数据是面向词而不是面向文档。

4.2 写入/读取数据的原理
4.2.1 写入
- 客户端选择一个node发送请求过去,这个node就是coordinating node(协调节点)
- coordinating node对document进行路由,将请求转发给对应的node(有primary shard)
- 实际的node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
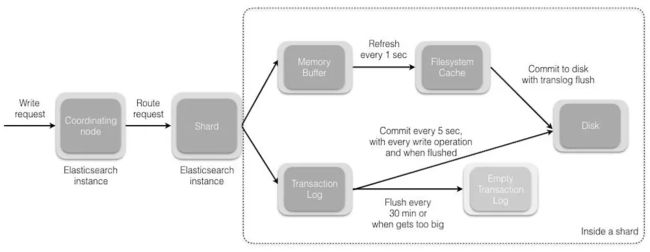
4.2.2 读取
你可以通过doc id来查询,会根据doc id进行hash,判断出来当时把doc id分配到了哪个shard上面去,从那个shard去查询
- 客户端发送请求到任意一个node,成为coordinate node
- coordinate node对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮询算法,在primary shard以及其所有replica中随机选择一个,让读请求负载均衡
- 接收请求的node返回document给coordinate node
- coordinate node返回document给客户端
4.2.3 搜索数据过程
客户端发送请求到一个coordinate node
协调节点将搜索请求转发到所有的shard对应的primary shard或replica shard也可以
query phase:每个shard将自己的搜索结果(其实就是一些doc id),返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果
-
fetch phase:接着由协调节点,根据doc id去各个节点上拉取实际的document数据,最终返回给客户端
 image.png
image.png
5. 分享几个面试问题
- ES如何更新文档
例如:“我是有赞人”更改为“我是流弊的有赞人”
- ES索引重建时,如何保持继续服务