1、开启公众号开发者模式
公众平台的技术文档目的为了简明扼要的交代接口的使用,语句难免苦涩难懂,甚至对于不同的读者,有语义歧义。万事皆是入门难,对于刚入门的开发者讲,更是难上加难,往往看了半天wiki,就是不懂说的什么鬼。
为了降低门槛,弥补不足,特地编写了《开发者指引》,讲解了一下微信开放平台的基础常见功能,目的重在帮助大家入门微信开放平台的开发者模式。
对于已熟知或者在一定公众平台开发经验的开发小哥,请直接跳过本文。这篇文章不会给你带来厉害的编码技巧亦或接口的深层次讲解。对于现有接口存在的疑问,请直接呼叫克服或者微信投诉,不要要在本文浪费时间。
为了防止小编语意上歧义,在给大家带来困扰,直接用最暴力的方法带你入门公众号开发——附录简明代码
1.1申请服务器
以腾讯云服务器为示例:腾讯云服务器购买入口,购买指导请参考快速人们Linux云服务器。
学生党注意:腾讯公司为在读高校生提供了云+校园计划,1元/月即可使用腾讯云。
1.2搭建服务
以web.py网络框,Python,腾讯云服务器为例介绍。
1)安装/更新需要用到的软件
安装Python2.7版本以上
安装web.py
安装libxml2,libxslt,lxml python
2)编辑代码,如果不懂Python语法,青岛Python官方文档查询说明,vim main.py
# -*- coding: utf-8 -*-
# filename: main.py
import web
urls = (
'/wx', 'Handle',
)
class Handle(object):
def GET(self):
return "hello, this is a test"
if _name_=='_main_':
app = web.application(urls,globals())
3)如果出现“socket.error:No socket could be created”错误信息,可能为80端口号被占用,可能是没有权限,请自行查询解决办法。如果遇见其他错误信息,请到web.py官方文档学习webpy框架3)执行命令:sudo python main.py 80.
4)浏览器输入http://外网IP:80/wx(外网IP请到腾讯云购买成功处查询)。如下图,一个简单的web应用已搭建。
1.3 申请公众号
邮箱激活后,选择公众号类型。不同的公众号拥有不同的能力,详情请见wiki:公众号接口权限说明。当然,服务号、企业号需要一定的证件和相关资料填写,如果证件一时不能准备好,没关系,公众号其实已注册,下次可以根据此邮箱&密码登录再选中。
1.4 开发者基本配置
1)公众平台官网登录之后,找到“基本配置”菜单栏
2)填写配置
URL填写:http://外网IP:端口号/wx。外网IP请到腾讯云购买成功处查询,http的端口号固定使用80,不可填写其他。
Token:自主设置,这个token与公众平台wiki中常提的access_token不是一回事。这个token只用于验证开发者服务器。
3)现在选择提交肯定是验证token失败,因为还需要完成代码逻辑。改动原先main.py文件,新增handle.py
a)vim main.py
# -*- coding:utf-8 -*-
# filename: main.py
import web
urls = (
'/wx','Handle',
)
if _name_ == '_main_';
app = web.application(urls,globals())
app.run()
b)vim handle.py
先附加逻辑流程图
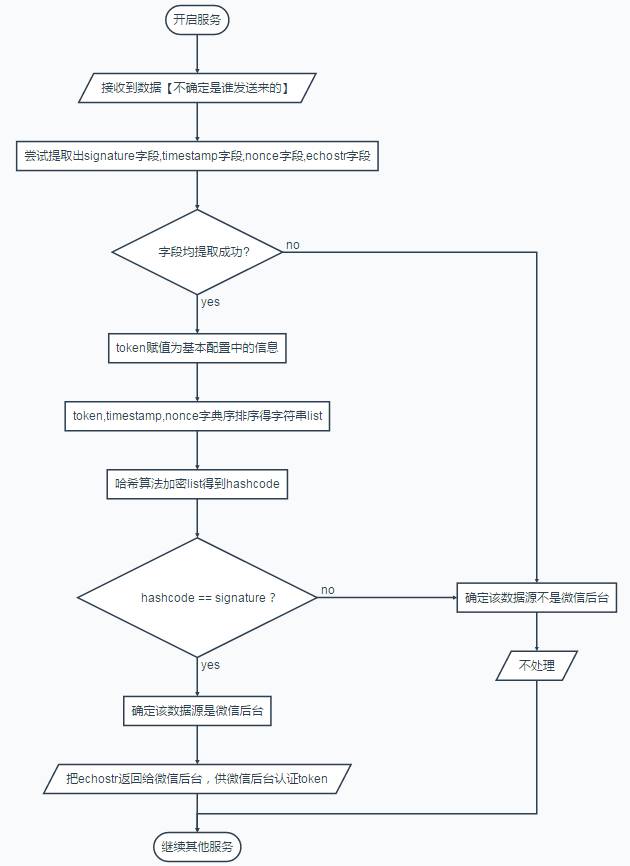
# -*- coding:utf-8 -*-
# filename:handle.py
import hashlib
improt web
class Handle(object):
def GET(self):
try:
data = web.input()
if len(data) == 0:
return "hello, this is handle view"
signature = data.signature
timestamp = data.timestamp
nonce = data.nonce
echostr = data.echostr
token = "xxxx" #请按公众平台官网\基本配置中信息填写
list = [token,timestamp, nonce]
list..sort()
shal = hashlib.shal()
map(shal.update,list)
hashcode = shal.hexdigest()
print "handle/GET func: hashcode,signature:",hashcode,signature
if hashcode == signature:
return echostr
else:
return ""
except Exception, Argument:
return Argument
4)重新启动成功后(Python main.py 80),点击提交按钮。若提示“token验证失败”,请认真检查代码或网络链接等。若token验证成功,会自动返回基本配置的主页面,点击启动按钮。
1.5 重要事情提前交代
接下来,文章准备从两个简单的示例入手。
示例一:实现“你说我学”
示例一:实现“图尚往来”
两个简单的示例后,是一些基础功能的介绍:素材管理、自定义菜单、群发。所有示例代码是为了简明的说明问题,避免代码复杂化。在实际中搭建一个安全稳定高效的公众号,建议参考框架如下图:
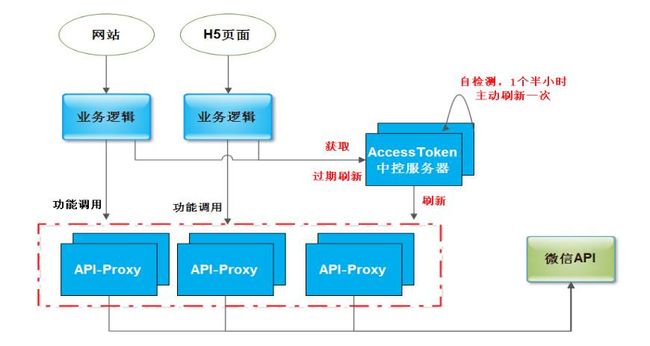
主要有三个部分:负责业务逻辑部分的服务器,负责对接微信API的API-Proxy服务器,以及唯一的Access Token中控服务器
1)AccessToken中控服务器:
负责:提供主动刷新和被动刷新机制来刷新accessToken并存储(为了防止并发刷新,注意加并发锁),提供给业务逻辑有效的accessToken。
优点:避免业务逻辑方并发获取access_token,避免AccessToken互相覆盖,提高业务功能的稳定性。
2)API-Proxy服务器:
负责:专一与微信API对接,不同的服务器可以负责对接不同的业务逻辑,更可进行调用频率、权限限制。
优点:某台API-Proxy异常,还有其余服务器支持继续提供服务,提高稳定性,避免直接暴漏内部接口,有效防止恶意攻击,提高安全性。
2 实现“你问我答”
目的:
1)理解被动消息的含义
2)理解收\发下次机制
预实现功能:粉丝给公众号一条文本消息,公众号立马回复一条文本消息给粉丝,不需要经过公众平台网页操作。
2.1接受文本消息
即粉丝给公众号发送的文本消息。官方wiki链接:消息管理/接收消息-接受普通消息
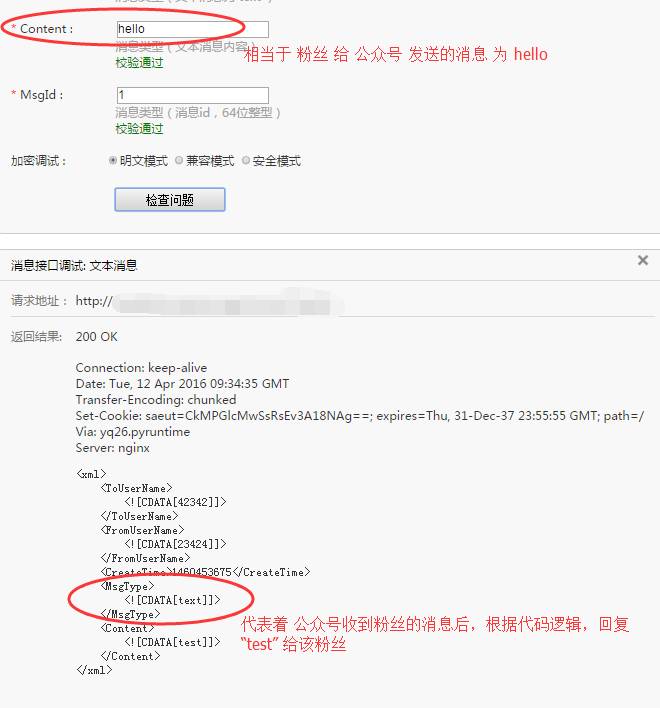
粉丝给公众号发送文本消息:“欢迎开启公众号开发者模式”,在开发者后台,收到公众平台发送的xml如下:(下文隐藏了ToUserName及FromUserName消息)
解释:
createTime 是微信公众平台记录粉丝发送该消息的具体时间
text:用于标记该xml是文本消息,一般用于去呗判断
欢迎开启公众号开发者模式:说明该粉丝发给公众号的具体内容是欢迎开启公众号开发者模式
MsgId:是公众平台为记录识别该消息的一个标记数值,微信后台系统自动产生
2.2 被动回复文本消息
即公众号给粉丝发送的文本消息,官方wiki链接:消息管理/接收消息-被动回复消息
特别强调:
1)被动回复消息,即发送被动响应消息,不同于客服消息接口
2)它其实并不是一种接口,而是对微信服务器发过来消息的一次回复
3)收到粉丝消息后不想或者不能5秒内回复时,需回复“success”字符串(下文详细介绍)
4)客服接口在满足一定条件下随时调用
公众号想回复给粉丝一条文本消息,内容为“test”,那么开发者发送给公众平台后台的xml内容如下:
特别备注:
1)ToUserName(接受者)、FromUserName(发送者)字段请实际填写。
2)createtime只用于标记开发者回复消息的时间、微信后台发送此消息都是不受这个字段约束。
3)text:用于标记此次行为是发送文本消息(当然可以是image/voice等类型)。
4)文本换行 ‘\n’。
2.3 回复success问题
查询官方wiki开头强调:加入服务器无法保证在五秒内处理回复,则必须回复“success”或者“”(空串),否则微信后台会发起三次重试。
解释一下为何有这么奇怪的规定。发起重试是微信后台为了尽可以保证粉丝发送的内容开发者可以收到。如果开发者不进行回复,微信后台没办法确认开发者已收到消息,只好重试。
真的是这样子吗?尝试一下收到消息后,不做任何回复。在日志中查看到微信后台发起了三次重试操作,日志截图如下:
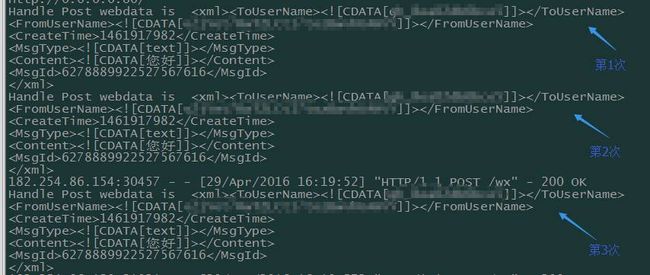
三次重试后,依旧没有及时回复任何内容,系统自动在粉丝会话界面出现错误提示“该公众号暂时无法提供服务,请稍后再试”。
如果回复success,微信后台可以确定开发者收到了粉丝消息,没有任何异常提示。因此请大家注意回复success的问题。
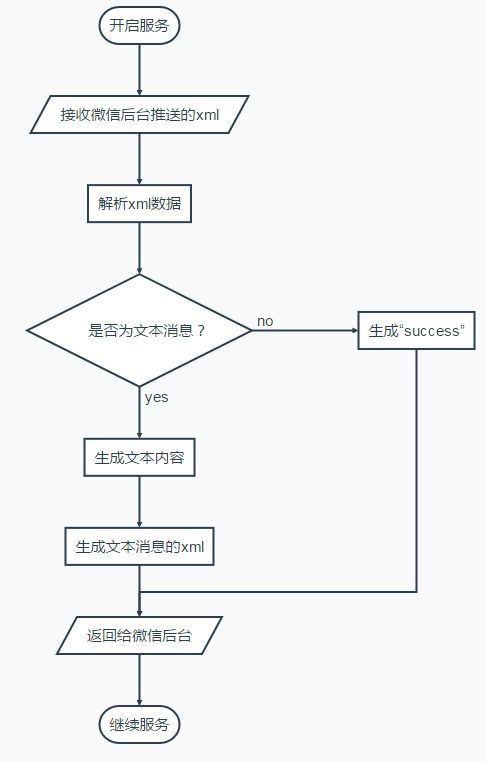
2.5 码代码
main.py文件不改变,handle.py需要增加一下代码,增加新的文件receive.py,reple.py
1)vim handle.py
# -*- coding: utf-8 -*-
# filename: handle.py
import hashlib
import reply
import receive
import web
class Handle(object):
def POST(self):
try:
webData = web.data()
print "Handle Post webdata is ",webData #后台打日志
recMsg = receive.parse_xml(webData)
if isinstance(recMsg,receive.Msg) and recMsg.MsgType == 'text':
toUser = recMsg.FromUserName
fromUser = recMsg.ToUserName
content = "test"
replyMsg = reple.TextMsg(toUser, fromUser, content)
return replyMsg.send()
else:
print "暂且不处理"
return "success"
except Exception, Argment:
return Argment
2)vim receive.py
# -*- coding: utf-8 -*-
#filename:receive.py
import xml.etree.ElementTree as ET
def parse_xml(web_data):
if len(web_data) == 0:
return None
xmlData = ET.fromstring(web_data)
mas_type = xmlData.find('MsgType').text
if mas_type == 'text':
return TextMsg(xmlData)
elif msg_type === 'image':
return ImageMsg(xmlData)
class Msg(object):
def _init_(self, xmlData):
self.ToUserName = xmlData.find('ToUserName').text
self.FromUserName = xmlData.find('FromUserName').text
self.CreateTime = xmlData.find('CreateTime').text
self.MsgType = xmlData.find('MsgType').text
self.MsgId = xmlData.find('MsgId').text
class TextMsg(Msg):
def _init_(self,xmlData):
Msg._init_(self,xmlData)
self.Content = xmlData.find('Content').text.encode("utf-8")
class ImageMsg(Msg):
def _int_(self,xmlData)
self.PicUrl = xmlData.find('PicUrl').text
self.MediaId = xmlData.find('MediaId').text
3)vim reply.py
# -*- coding:utf-8 -*-
# filename: reply.py
import time
class Msg(object):
def _init_(self):
pass
def send(self):
return "success"
class TextMsg(Msg):
def _init_(self,toUserName,fromUserName,content):
self._dict = dict()
self._dict['ToUserName'] = toUserName
self._dict[FromUserName'] = fromUserName
self._dict['CreateTime'] = int(time.time())
self._dict['Content'] = content
def send(self):
XmlForm = """
"""
return XmlForm.format(**self._dict)
class ImageMsg(Msg):
def _init_(self,toUserName,fromUserName,mediaId):
self._dict = dict()
self._dict['ToUserName'] = toUserName
self._dict['FromUserName'] = fromUserName
self._dict['CreateTime'] = int(time.time())
self._dict['MediaId'] = mediaId
def send(self):
XmlForm = """
"""
return XmlForm.format(**self._dict)
码好代码之后,重新启动程序,sudo python main.py 80。
2.6 在线测试
微信公众平台有提供一个在线测试平台,方便开发者模拟场景测试代码逻辑。正如2.2被动回复文本消息 交代此被动回复接口不同于客服接口,测试时也要注意区别。
在线测试目的在于测试开发者代码逻辑是否有误、是否符合预期。即便测试成功也不会发送内容给粉丝。所以可以随意测试。
测试结果:
1)“请求失败”,说明代码有问题,请检查代码逻辑。

2)“请求成功”,然后根据返回结果查看是否符合预期。
2.7 真实体验
拿出手机,微信扫描公众号二维码,成为自己公众号的第一个粉丝。公众号二维码位置如下图:
3 实现“图”尚往来
目的:
1)引入素材管理
2)以文本消息,图片消息为基础,可自行理解剩余的语音消息、视频消息、地理消息等
预实现功能:
接受粉丝发送的图片消息,并立马回复相同的图片给粉丝。
3.1 接收图片消息
即粉丝给公众号发送的图片消息。官方wiki链接:消息管理/接收消息-接受普通消息/图片消息http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140453&token=&lang=zh_CN。从实例讲解,粉丝给公众号发送一张图片消息,在公众号开发者后台接收到的xml如下:
特别说明:
PicUrl:这个参数是微信系统把“粉丝”发送的图片消息自动转化成url.这个url可用浏览器打开查看图片。
MediaId:是微信系统产生的id用于标记该图片,详情可参看wiki素材管理/获取临时素材。http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738727&token=&lang=zh_CN
3.2 被动回复图片消息
即公众号给粉丝发送的图片消息。官方wiki链接:消息管理/发送消息-被动回复用户消息/图片消息。http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140543&token=&lang=zh_CN
特别说明:
1)被动回复消息,即发送被动响应消息,不同于客服消息接口
2)它其实并不是一种接口,而是对微信服务器发过来消息的一次回复
3)收到粉丝消息后不想或者不能5秒内回复时,需回复“success”字符串(下文详细介绍)
4)客服接口在满足一定条件下随时调用
开发者发送给微信后台的xml如下:
这里填写的MediaId的内容,其实就是给粉丝的发送图片的原MediaId,所以粉丝收到了一张一模一样的原图。
如果想回复粉丝其他图片怎么呢?
1)新增素材,请参考新增临时素材或者新增永久素材
2)获取其MediaId,请参考获取临时素材MediaID或者获取永久素材MediaID
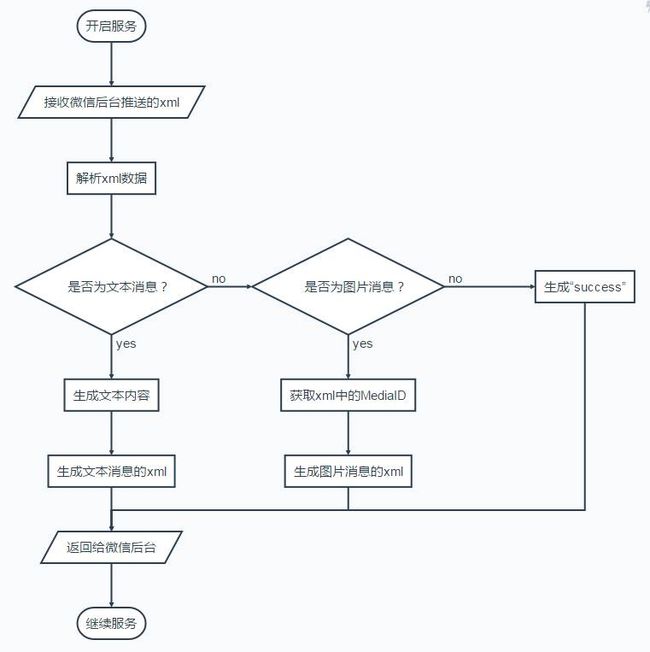
3.3 流程图
3.4 码代码
只显示更改的代码部分,其余部分参考上小节,在线测试,真实体验,回复空串,请参考实现“你问我答”。vim handle.py
# -*- coding: utf-8 -*-
# filename: handle.py
import hashlib
import reply
import receive
import web
class Handle(object):
def POST(self):
try:
webData = web.data()
print "Handle Post webdata is ", webData #后台打日志
recMsg = receive.parse_xml(webData)
if isinstance(recMsg,receive.Msg):
toUSER = recMsg.FromUserName
fromUser = recMsg.ToUserName
if recMsg.Msg.MsgType == 'text':
content = "test"
replyMsg = reply.TextMsg(toUser,fromUser,content)
return replyMsg.send()
if recMsg.MsgType == 'image':
mediaId = recMsg.MediaId
replyMsg = reple.ImageMsg(toUser,fromUser,mediaId)
return replyMsg.send()
else:
return reply.Msg().send()
else:
print "暂且不处理"
return reply.Msg().send()
except Exception,Argment:
return Argment
4 AccessToken
AccessToken的意义请参考公众平台wikihttp://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140183&token=&lang=zh_CN介绍。
4.1 查看appid及appsecret
公众平台官网查看,其中AppSecret不点击重置时候,则一直保持不变。
4.2 获取accessToken
4.2.1 临时方法获取
为了方便先体验其他接口,可以临时通过在线测试http://mp.weixin.qq.com/debug/或者浏览器获取accessToken。
4.2.2 接口获取
详情请见:公众平台wikihttp://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421140183&token=&lang=zh_CN
特别强调:
1)第三方需要一个access_token获取和刷新的中控服务器。
2)并发获取access_token会导致AccessToken互相覆盖,影响具体的业务功能
4.3 码代码
再次重复说明,下面代码只是为了简单说明接口获取方式。实际中并不推荐,尤其是业务繁重的公众号,更需要中控服务器,统一的获取accessToken。vim basic.py
# -*- coding: utf-8 -*-
# filename:basic.py
import urllib
import time
import json
class Basic:
def _init_(self):
self._accessToken = ''
self._leftTime = 0
def _real_get_access_token(self):
appId = "xxxxx"
appSecret = "xxxxx"
postUrl = ("https://api.weixin.qq.com/cgi-bin/token?grant_type="
"client_credential&appid=%s&secret=%s" % (appId,appSecret))
urlResp = urllib.urlopen(postUrl)
urlResp = json.loads(urlResp.read())
self._accessToken = urlResp['access_token']
self._leftTime = urlResp['expires_in']
def get_access_token(self):
if self._leftTime < 10:
self._real_get_access_token()
return self._accessToken
def run(self):
while(True):
if self._leftTime > 10:
time.sleep(2)
self._leftTime -= 2
else:
self._real_get_access_token()
5 临时素材
公众号经常有需要用到一些临时性的多媒体素材的场景,例如在使用接口特别是发送消息时,对多媒体文件、多媒体消息的获取和调用等操作,是通过MediaID来进行的。譬如实现“图”尚往来中,粉丝给公众号发送图片消息,便产生一临时素材。
因为永久素材有数量限制,但是公众号又需要临时性使用一些素材,因而产生了临时素材。这类素材不在微信公众平台后台长期存储,所以在公众平台官网的素材管理中查询不到,但是可以通过接口对其操作。
其他详情请以公众平台官网wiki介绍为依据。
5.1 新建临时素材
接口详情请依据wiki介绍。提供参考代码如何上传素材为临时素材,供其他接口使用。
vim media.py 编写完成之后,直接运行media.py即可上传临时素材。
# -*- coding: utf-8 -*-
#filename: media.py
from basic import Basic
import urllib2
import poster.encode
from poster.streaminghttp import register_openers
class Media(object):
def_init_(self):
register_openers()
#上传图片
def upload(self, accessToken,filePath, mediaType):
openFile = open(filePath, "rb")
param = {'media': openFile}
postData,postHeaders = poster.encode.multipart_encode(param)
postUrl = "https://api.weixin.qq.com/cgi-bin/media/upload?access_token=%s&type=%s" % (accessToken,mediaType)
request = urllib2.Request(postUrl,postData,postHeaders)
urlResp = urllib2.urlopen(request)
print urlResp.read()
if _name_ == '_main_':
myMedia = Media()
accessToken = Basic().get_access_token()
filePath = "D:/code/mpGuide/media/test.jpg" #请按实际填写
mediaType = "image"
myMedia.upload(accessToken, filePath, mediaType)
5.2 获取临时素材MdidaID
临时素材的MediaID没有提供特定的接口进行统一查询,因此有两种方式
1)通过接口上次的临时素材,在调用成功的情况下,从返回JSON数据中提取MediaID,可临时使用
2)粉丝互动中的临时素材,可从xml数据中提取MedaID,可临时使用
5.3 下载临时素材
5.3.1 手工体验
开发者如何保存粉丝发送的图片呢?接口文档:获取临时素材接口http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738727&token=&lang=zh_CN,为方便理解,从最简单浏览器获取素材的方法入手,根据实际情况,浏览器输入网址:
https://api.weixin.qq.com/cgi-bin/media/get?access_token=ACCESS_TOKEN&media_id=MEDIA_ID(自行替换数据)
ACCESS_TOKEN如“AccessToken”章节详解
MEDIA_ID如图尚往来/接受图片消息xml中的MediaId讲解
只要数据正确,则会下载图片到本地,如下图:

5.3.2 接口获取
现在已经理解这个接口的功能了,只剩码代码了。vim media.py
# -*- coding:utf-9 -*-
# filename:media.py
import urllib2
import json
from basic import Basic
class Media(object):
def get(self,accessToken,mediaId):
postUrl = "https://api.weixin.qq.com/cgi-bin/media/get?access_token=%s&media_id=%s" % (accessToken, mediaId)
rulResp = urllib2.urlopen(postUrl)
headers = urlResp.info()._dict_['headers']
if ('Content-Type:application/json\r\n' in headers) or ('Content-Type: text/plain\r\n' in headers):
jsonDict = json.loads(urlResp.read())
print jsonDict
else:
buffer = urlResp.read() #素材的二进制
mediaFile = file("test_meda.jpg", "wb")
mediaFile.write(buffer)
print "get successful"
if _name_ == '_main_':
myMedia = Media()
accessToken = Basic().get_access_token()
meidaId = "2ZsPnDj9XIQlGfws31MUfR5Iuz-rcn7F6LkX3NRCsw7nDpg2268e-dbGB67WWM-N"
myMedia.get(accessToken,mediaId)
直接运行media.py即可把想要的素材下载下来,其中图文消息类型的,会直接在屏幕输出json数据段。
6 永久素材
6.1 新建永久素材的方式
6.1.1 手工体验
公众号官网的素材管理新增素材。补充一点,公众平台只以MediaID区分素材,MediaID不等于素材的文件名。MediaID只能通过接口查询,公众平台官网看到的是素材的文件名,如下图:
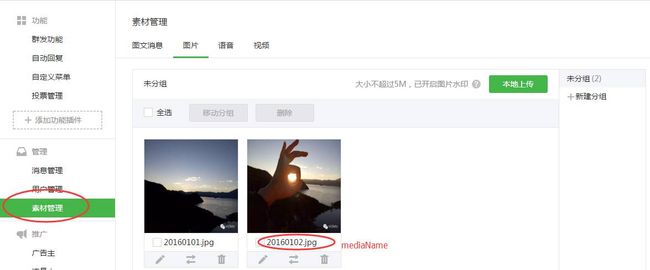
6.1.2 接口删除
新增永久素材接口(详情见wiki)http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738729&token=&lang=zh_CN跟新增临时素材的操作差不多,使用URL不一样而已,这里避免重复,以新增永久图文素材接口为例,新增其他类型的素材请参考新增临时素材代码。vim material.py
# -*- coding: urt-8 -*-
# filename: material.py
import urllib2
import json
from basic import Basic
class Material(object):
#上传图文
def add_news(self,accessToken,news):
postUrl = "https://api.weixin.qq.com/cgi-bin/material/add_news?access_token=%s" % accessToken
urlResp = urllib2.urlopen(postUrl,news)
print urlResp.read()
if _name_ == '_main_':
myMaterial = Material()
accessToken = Basic().get_access_token()
news =(
{
"articles";
[
{
"title"; "test",
"thumb_media_id":"X2UMe5WdDJSS2AS6BQkhTw9raS0pBdpv8wMZ9NnEzns",
"author":"vickey",
"digest":"",
"show_cover_pic":1,
"content": "
",
"content_source_url":"",
}
]
})
#news 是个dict类型,可通过下面方式修改内容
#news['articles'][0]['title'] = u"测试".encode(utf-8')
#print news['articles'][0]['title']
news = json.dumps(news,ensure_ascii=False)
myMaterial.add_news(accessToken,news)
6.2 获取永久素材MediaID
1)通过新增永久素材接口(详见wiki)http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738729&token=&lang=zh_CN新增素材时,保存MediaID
2)通过获取永久素材列表(下文介绍)的方式获取素材信息,从而得到MediaID
6.3 获取素材列表
官方wiki链接:获取素材列表http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738734&token=&lang=zh_CN。特别说明:此接口只是批量拉取素材信息,不是一次性拉去所有素材的信息,所以可以理解offset字段的含义了吧。vim material.py
# -*- coding: utf-8 -*-
# filename:material.py
import urllib2
import json
import poster.encode
from poster.streaminghttp import register_openers
from basic import Basic
class Material(object):
def _init_(self):
register_openers()
#上传
def upload(self, accessToken, filePath, mediaType):
openFile = open(filePath,"rb")
fileName = "hello"
param = { 'media':openFile,'filename':fileName}
#param = {'media' : openFile}
postData,postHeaders = poster.encode.multipart_encode(param)
postUrl = "https://api.weixin.qq.com/cgi-bin/material/add_material?access_token=%s&type=%s" % (accessToken, mediaType)
request = urllib2.Request(postUrl,postData,postHeaders)
urlResp = urllib2.urlopen(request)
print urlResp.read()
#下载
def get(self, accessToken,mediaId):
postUrl = "https://api.weixin.qq.com/cgi-bin/material/get_material?access_token=%s" % accessToken
postData = "{ \"media_id\": \"%s\" }" % mediaId
urlResp = urlResp.info()._dict_['headers']
if ('Content-Type:application/json\r\n' in headers) or ('Content-Type: text/plain\r\n' in headers):
jsonDict = json.loads(urlResp.read())
print jsonDict
else:
buffer = urlResp.read() #素材的二进制
mediaFile = file("test_media.jpg","wb")
mediaFile.write(buffer)
print "get successful"
#删除
def delete(self,accessToken,mediaId):
postUrl = "https://api.weixin.qq.com/cgi-bin/material/del_material?access_token=%s" % accessToken
postData = "{ \"media_id\": \"%s\"}" % mediaId
urlResp = urllib2.urlopen(postUrl,postData)
print urlResp.read()
#获取素材列表
def batch_get(self, accessToken,mediaType, offset=0, count=20:
postUrl = ("https://api.weixin.qq.com/cgi-bin/material"
"/batchget_material?access_token=%s" % accessToken)
postData = ("{ \"type\": \"%s\", \"offset\": %d,\"count\": %d}"
% (mediaType,offset,count))
urlResp = urllib.urlopen(postUrl,postData)
print urlResp.read()
if _name_== '_main_':
myMaterial = Material()
accessToken = Basic().get_access_token()
mediaType = "news"
myMaterial.batch_get(accessToken,mediaType)
6.4 删除永久素材
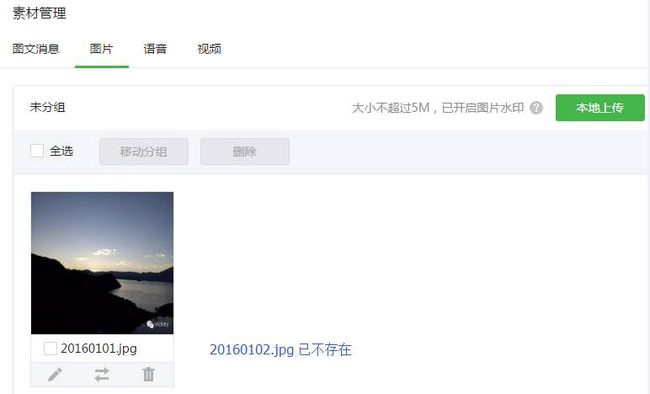
如果我想删除掉20160102.jpg这张图片,除了官网直接操作,也可以使用接口:删除永久素材http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1444738731&token=&lang=zh_CN接口文档。
首先需要知道该图片的mediaID,方法上小节已讲述。代码可参考上小节:Material().delete()接口
调用接口成功后,在公众平台官网素材管理的图片中,查询不到已删除的图片。
7 自定义菜单
自定义菜单意义作用请参考官方wikihttp://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1421141013&token=&lang=zh_CN介绍。
目标:三个菜单栏,体验click、view、media_id三种类型的菜单按钮,其他类型在本小节学习之后,请自行查询公众平台wiki说明领悟。
7.1 创建菜单界面
1)根据公众平台wiki给的json数据编写代码,其中涉及media_id部分请阅读“永久素材”章节。vim menu.py
# -*- coding: utf-8 -*-
#filename: menu.py
import urllib
from basic import Basic
class Menu(object):
def _init_(self_):
pass
def create(self,postData,accessToken):
postURL = "https://api.weixin.qq.com/cgi-bin/menu/create?access_token=%s" % accessToken
if isinstance(postData,unicode):
postData = postData.encode('utf-8')
urlResp = urllib.urlopen(url=postUrl,data=postData)
print urlResp.read()
def query(self,accessToken):
postUrl = "https://api.weixin.qq.com/cgi-bin/menu/get?access_token=%s" % accessToken
urlResp = urllib.urlopen(url=postUrl_
print urlResp.read()
def delete(self,accessToken):
postUrl = "https://api.weixin.qq.com/cgi-bin/menu/delete?access_token=%s" % accessToken
urlResp = urllib.urlopen(url=postUrl)
print urlResp.read()
#获取自定义菜单配置接口
def get_current_selfmenu_info(self,accessToken):
postUrl = "https://api.weixin.qq.com/cgi-bin/get_current_selfmenu_info?access_token=%s" % accessToken
urlResp = urllib.urlopen(url=postUrl)
print urlResp.read()
if _name_ == '_main_':
myMenu = Menu()
postJson = """
{
"button":
[
{
"type":"click",
"name": "开发指引",
"key":"mpGuide"
},
{
"name":"公众平台",
"sub_button":
[
{
"type":"vies",
"name":"更新公告",
"url":"http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1418702138&token=&lang=zh_CN"
},
{
"type":"view",
"name": "接口权限说明",
"url":"http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1418702138&token=&lang=zh_CN"
},
{
type":"view",
"name":"返回码说明",
"url":"http://mp.weixin.qq.com/wiki?t=resource/res_main&id=mp1433747234&token=&lang=zh_CN"
}
]
},
{
"type": "media_id",
"name": "旅行",
"media_id":"z2zOokJvlzCXXNhSjF46gdx6rSghwX2xOD5GUV9nbX4"
}
]
}
"""
accessToken = Basic().get_access_token()
#myMenu.delete(accessToken)
myMenu.create(postJson,accessToken)
2)在腾讯云服务器上执行命令:python menu.py。
3)查看:
重新关注公众号后可查看新创建菜单界面,题外话,如果不重新关注,公众号界面也会自动更改,但有时间延迟。
如下图所示,点击子菜单“更新公告“(view类型),弹出网页(PC版本)
点击旅行(media_id类型),公众号显示了一篇图文消息,如下图所示:
7.2 完善菜单功能
查看公众平台自定义菜单wiki与公众平台wiki/自定义菜单事件推送后,可知:点击click类型button,微信后台会推送一个event类型的xml给开发者。
显然,click类型的还需要开发者进一步完善后台代码逻辑,增加对自定义菜单事件推送的响应。
7.2.1 流程图
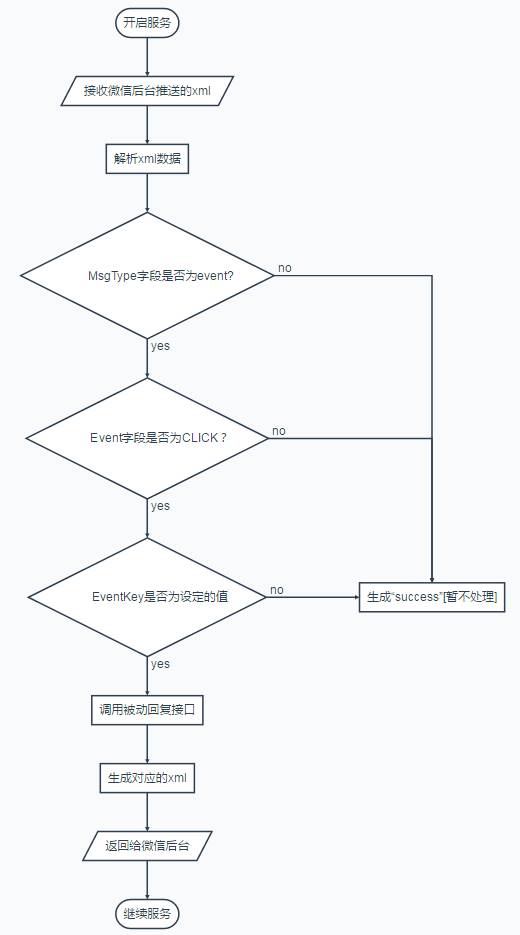
7.2.2 码代码
1)vim handle.py(修改)
# -*- coding: utf-8 -*-
# filename:handle.py
import reply
import receive
import web
class Handle(object):
def POST(self):
try:
webData = web.data()
print "Handle Post webdata is ", webData #后台打日志
recMsg = receive.parse)xml(webData)
if isinstance(recMsg, receive.Msg):
toUser = recMsg.FromUserName
fromUser = recMsg.ToUserName
if recMsg.MsgType == 'text':
content = "test"
replyMsg = reply.TextMsg(toUser,fromUser,content)
return replyMsg.send()
if recMsg.MsgType == 'image':
mediaId = recMsg.MediaId
replyMsg = reply.ImageMsg(toUser,fromUser,mediaId)
return replyMsg.send()
if isinstance(recMsg,receive.EventMsg):
if recMsg.Event == 'CLICK':
if recMsg.Eventkey == 'mpGuide':
content = u"编写中,尚未完成".encode('utf-8')
replyMsg = reply.TextMsg(toUser,fromUser,content)
return replyMsg.send()
print "暂且不处理“
return reply.Msg.send()
except Exception, Argment:
return Argment
2)vim receive.py(修改)
# -*- coding: utf-8 -*-
# filename:receive.py
import xml.etree.ElementTree as ET
def parse_xml(web_data):
if len(web_data) == 0:
return None
xmlData = ET.fromstring(web_data)
msg_type = xmlData.find('MsgType').text
if msg_type == 'event':
event_type == 'CLICK':
return Click(xmlData)
#elif event_type in ('subscribe', 'unsubscribe'):
#return Subscribe(xmlData)
#elif event_type == 'VIEW':
#return View(xmlData)
#elif event_type == 'LOCATION':
#return LocationEvent(xmlData)
#elif event_type == 'SCAN':
#return Scan(xmlData)
elif msg_type == 'image':
return ImageMsg(xmlData)
class EventMsg(object):
def _init_(self,xmlData):
self.ToUserName = xmlData.find('ToUserName').text
self.FromUserName = xmlData.find('FromUserName').text
self.CreateTime = xmlData.find('CreateTime').text
self.MsgType = xmlData.find('MsgType').text
self.Event = xmlData.find('Event').text
class Click(EventMsg):
def _init_(self, xmlData):
EventMsg._init_(self,xmlData)
self.Eventkey = xmlData.find('EventKey').text
7.3体验
编译好代码后,重新启动服务,(sudo python main.py 80),view类型、meidia_id类型的本身就很容易实现,现在重点看一下click类型的菜单按钮。
微信扫码成为公众号的粉丝,点击菜单按钮“开发指引”。
查看后台日志,发现接收到一条xml,如截图:
公众号的后台代码设置对该事件的处理是回复一条内容为“编写之中”的文本消息,因此公众号发送了一条文本消息给我,如图:

好啦,到此,目标已实现。对于自定义菜单其他类型,均同理可操作。
8 关于反馈问题
是程序肯定有bug,所以在使用开放平台过程中,肯定会遇见各种各样的问题,可能是自己的坑,也可能是微信团队的锅。当自己查自己代码千千遍,依旧没有发现问题时候,可以通过腾讯客服等等渠道,请求微信团队的帮助。如何高效快速的得到帮助呢?下面强调三个要点:
1)精明扼要的描述清楚场景以及遇见问题,描述过程中尽可能使用wiki上的名称,譬如自定义菜单,素材管理等专有名词,不然开发根本不知道你在说什么。
2)提供账号信息:AppID(登录公众平台官网->基本配置),若牵扯粉丝提供粉丝的OpenID。
3)提供bug的发生时间,至少要以小时为单位(年-月-日-小时),当然越具体越容易查明问题。