基于AI、大数据的互联网应用推动了互联网数据中心产品、技术的快速升级。
首先,接入带宽从传统的10Gbps升级到25Gbps/100Gbps,需要基础网络提供高转发能力保障业务的高可用。
其次,基于RDMA(Remote Direct Memory Access,远程直接内存访问)无损以太网技术的普遍应用,实现了计算节点到存储节点的微秒级时延,大大优化端到端的业务转发性能,而这也意味着对网络运维提出了更高的挑战——如何在大规模、复杂的HPC(High Performance Computing)网络中实现更加精细的流量可视、可控?如何面向业务实现端到端的秒级故障定位,并为网络的持续优化提供精准的数据支撑?
锐捷网络认为,通过基于交换机硬件芯片的Network Telemetry技术方案(INT+gRPC),可以实现整网的流量可视化,为实现真正的可视化运维提供新的思路。查找了相关资料整了下,以下是锐捷专家的精彩解读。
网络运维新挑战
为了保证业务的高可靠,基于Scale out方式实现的分布式计算和存储应用(Hadoop/ Map reduce/HDFS)得到了大规模使用,不仅摆脱了单服务器的计算、存储性能的限制,同时可提供更灵活的扩展性,能够快速响应业务需求变化,提高系统的可靠性、可用性和存取效率。
然而业务本身在网络中分布是不可控的,因此在实际网络流量模型中不可避免会出现多对一的通信模式,即 Incast模型。下图即典型的Incast通信模型:
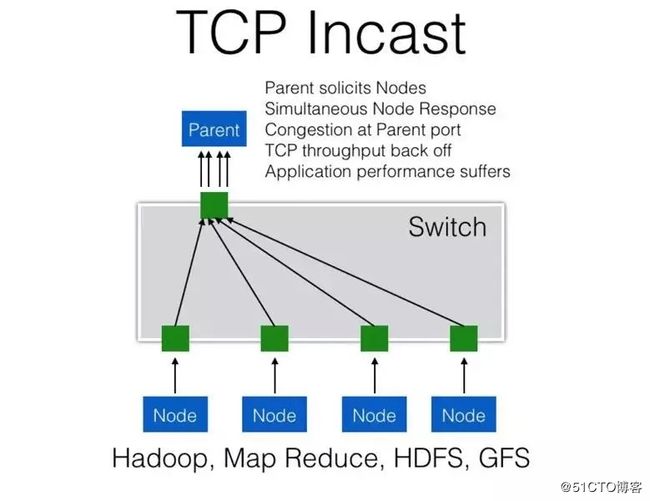
▲ TCP Incast通信模型示意图
例如,当一台Master节点向一组Slave节点发起一个计算任务请求时,所有Slave节点几乎会同时返回计算结果数据,对于Master节点来说就产生了一个“微突发流”。对于合理的“微突发流”,可以依靠接入交换机设备内部的报文缓存机制解决微突发丢包问题。
目前,主流交换机设备缓存比较小,一般以MByte为单位。下图是对应1G、10G和25G交换机的缓存容量。

▲ 带宽提升与缓存提升对比说明
从表中不难看出,网络接口速率从1Gbps发展到25Gbps,服务器的吞吐能力增加25倍,而交换机的缓存容量同比仅增加8倍,同时报文缓存时间反而下降65%(按照交换机全端口公平使用缓存为例)。
因此,25G网络架构的TCP Incast现象比10G网络更加明显,瞬时的多打一导致出接口报文拥塞,出接口缓存用完后会基于尾部丢弃机制进行丢包,应用监测到丢包后发起TCP重传,造成数据端到端时延的进一步恶化,严重影响业务体验。
针对网络丢包引起的业务故障,需要网络监控系统快速定位网络中哪台交换机的哪个端口因缓存不足导致了丢包。同时,重要业务端到端时延超出预期时,也需要定位流量转发路径上每个节点的转发时延。
总结起来,需要网络监控系统实现如下能力:
• 快速定位哪台交换机的哪个端口发生丢包;
• 实时监控每台交换机的Buffer使用情况;
• 端到端时延可以定位到具体设备和链路。
运维可视化技术实现
凭借传统的网络监控手段无法解决“看不见”的问题,如时延、转发路径、缓存和丢包。例如,由外部应用发起的请求获取网络状态信息的SNMP协议,就无法实时反映网络的状态。
为了解决此类难题,业界广泛引入Network Telemetry(网络遥测)这一理念,相比于SNMP,Telemetry实现了网络设备主动推送状态信息的能力,具有更强的时效性。
事实上,Telemetry并不是新发明,NetFlow和sFlow早已实现了网络流量的采样和推送,但NetFlow、sFlow推送的是最原始的数据采样信息,数据以IP报文格式呈现给分析工具,而非用户期望的规范化数据模型,再优异的分析工具其扩展性能也难以承担整个数据中心网络的监控分析,只能在某一分析任务中发挥作用。
另一方面,数据流量并非网络状态的全部,网络设备的 CPU、内存、网络拥塞信息、网络事件的日志信息等也无法通过NetFlow或者sFlow实时传递出来。
gRPC(Google Remote Procedure Calls ,谷歌远程过程调用)是Google公司开源的一个高性能、跨语言的RPC框架,使用HTTP/2协议并使用Proto Buffer作为序列化和反序列化的工具。通过在交换机中集成gRPC应用,定义灵活的数据格式以及数据推送的阈值来实现交换机自身状态的主动推送能力,可以实现周期性推送交换机Buffer Usage、CPU、Memory等信息给监控服务器。当发生Buffer不足导致丢包,也会实时通知给监控服务器,实现网络运行数据的可视化。

▲ gRPC交互机制
上图展示了其中一种gRPC的交互机制:
• 在交换机开启gRPC功能后充当gRPC 客户端角色,监控服务器充当gRPC服务器角色;
• 交换机主动向监控服务器发起gRPC通道建连;
• 交换机主动上报Buffer Usage、CPU、内存等信息给监控服务器,当Buffer发生丢包,交换机也会实时上报丢包事件给监控服务器。
gRPC的出现很好的解决了实时数据无法有效传给监控服务器的问题。
INT(In-band Network Telemetry)也是一种新型Telemetry协议,由Barefoot、Arista、Dell、Intel和VMware共同提出。INT的出现解决了转发路径和转发时延不可见的问题。
INT的整体处理流程如下图所示:
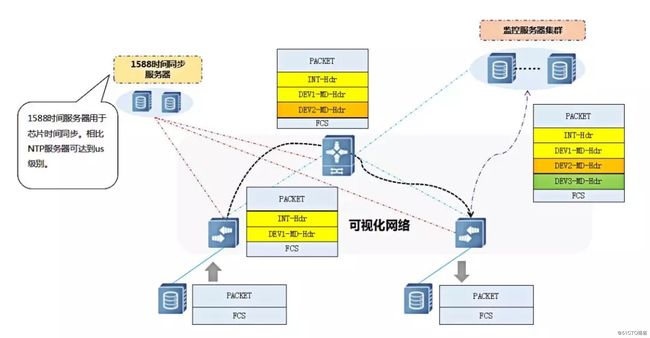
▲ 可视化网络
• 报文达到首节点,通过在交换机上设置的采样方式匹配并镜像出该报文,并在四层头部后插入INT头,将报文入端口Port ID、出端口 Port ID、入端口时间、出端口时间、以及设备的DEVICE ID封装成MetaData,将MD插入到INT头部之后;
• 报文转发到中间节点,设备匹配到INT头部后,在INT头部后再插入一层MD;
• 报文转发到最后一跳,设备匹配INT头部后,再插入一层MD,并在报文外部封装一个IP头(ERSPAN),外层IP为监控服务器地址,这样INT报文便转发到监控服务器。
总结:针对面向HPC业务的下一代数据中心网络,基于INT和gRPC的Network Telemetry技术可以实现业务端到端的网络流量可视化,打破“网络黑盒”,为精细化网络运维提供整体的解决方案和必要的技术支撑。锐捷网络新一代25G/100G网络交换机产品均已实现Network Telemetry能力(gRPC和INT)。