基本介绍

首先从一个重要的概念“模板”说起。 广义上来说,web中的模板就是填充数据后可以生成文件的页面。 严格意义上来说,应该是模板引擎利用特定格式的文件和所提供的数据编译生成页面。模板大致分为前端模板(如ejs)和后端模板(如freemarker)分别在浏览器端和服务器端编译。
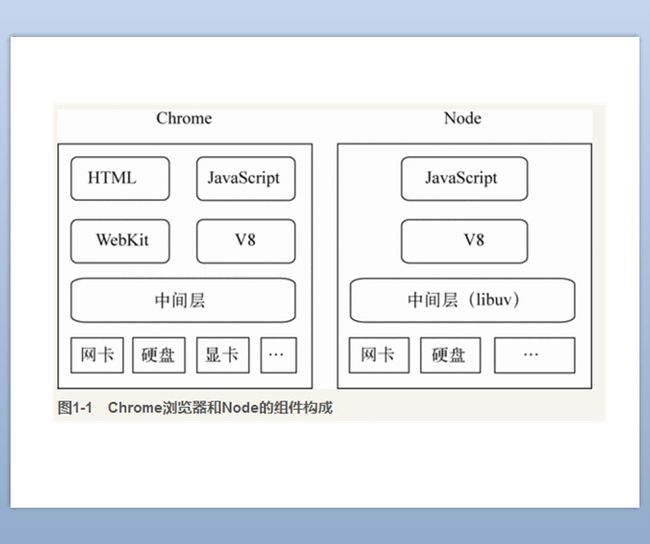
由于当场有一部分同学对node.js并不是很了解,这里补充一下node.js的相关知识。官网上的给他的定义事件驱动、异步什么的就不说了。这里借用朴灵书上的一张图来解释一下node.js这个玩意的结构。如果懂java的同学可以将其理解为js版本的jvm。 浏览器一般包括渲染器和js脚本引擎,以chrome浏览器为例,用的webkit内核的渲染器,V8的脚本引擎,而node.js用到了v8引擎。总而言之它就是一个js的运行环境,就好比浏览器的F12调试工具,只不过node.js没有DOM和BOM。
这张图描述的是node.js周边的一些信息,比如npm这个出色的包管理器和cnode社区以及github,都在一定程度上促进了node.js的繁荣,提供了技术保障。

大公司通常都是技术的风向标,例如google的angular、facebook的react现在都很火。这里只列了3个大公司当作例子。淘宝的中途岛架构就不用说了,国内node.js的先行者朴灵就来自淘宝。去哪儿也出了个应该叫做“QTX”的技术框架。360月影带领的75团队出了个基于ES6/ES7的web服务器框架――thinkjs,当时我们技术总监很看好,但是由于鄙人没有时间学习ES6再加上插件不够丰富,所以还是选用了较为成熟的Express。

言归正传,这个表格列出了我所接触过的3种前后端分离的开发方式。 第一种是最常见的使用java之类的后端语言模板,SEO友好,缓存利用率和减轻浏览器渲染负担方面都比较好,最大的问题就是模板文件的耦合度太高,出了问题谁都不想来解决,前端人员看不到数据,后端人员不懂页面,模板文件就像是一个烫手的山芋。 第二种是目前我们项目移动端的实现方案,利用angular这种框架(angular的指令可以看成是前端模板)和nginx这种反向代理服务器,让前后端彻底解耦,只通过ajax交互数据。这种方案和前一种的优缺点刚好相反。前端模板的性能始终是个问题,尤其是在移动端,更尤其是在低端的移动设备上。 最后一种是新项目使用的用node.js做前端服务器,将前端的职责从浏览器划分到了模板这一层,解决了以上所有的问题,不过确实也有新的问题,这种问题稍后再分析。

当然全栈开发在小型项目中也是非常适合的。对于传统的jsp/php开发来说,全栈开发的沟通成本更低,开发人员能更容易理解整个功能模块,从而更好的还原产品的设计。尤其现在出现的以js语言为基础的全栈开发:meteor和MEAN技术,更是使得前后端开发用一种语言直接搞定,再配上Mongodb,数据从浏览器到数据库都无需转义直接使用,还不用写sql,开发成本又大大降低。

这次搭建node.js服务器用到的一些插件。 鼎鼎大名的express不用多介绍了,轻量级web服务器框架。 用handlebars模板引擎也属巧合,因为express4默认就是它,handlebars不愧为“弱逻辑”的模板引擎,主张的是减少模板逻辑,尽量只用变量和分页,基于它的设计理念,我只扩充了两个helper。具体文章:https://yalishizhude.github.io/2016/01/22/handlebars/superagent的使用还是因为express4,因为它的测试代码用的是supertest,supertest是基于superagent,所以用了superagent来转发和发起请求。superagent还是太弱了,长连接都无法建立,还是推荐request插件。 restfuleAPI就没什么好介绍了,前端服务器与浏览器,前端服务器与后端服务器都是用的这一套规范,基本上就是url指向资源,增删改查又具体的请求方法表示,状态码表示结果等~ gulp打包工具,webpack研究了很久,发现每增加一个页面都要修改配置文件,这个太蛋疼,遂放弃。
开发流程
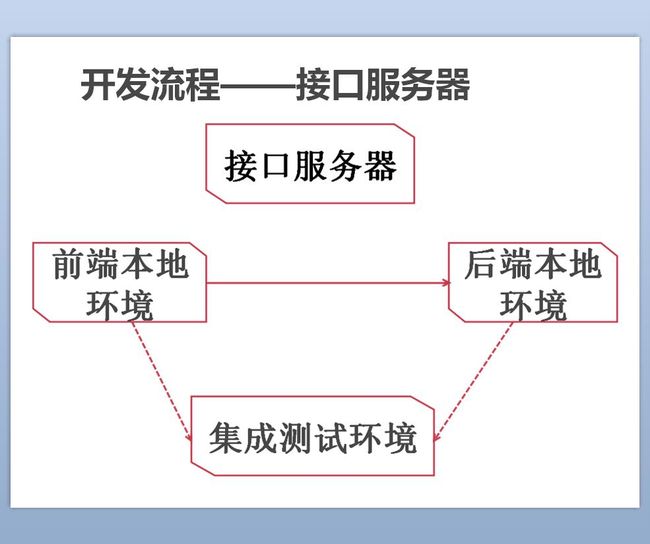
如果这次分享主要是讲怎样将node.js做为前端服务器来实现前后端分离的话那也没什么好讲的,看看淘宝UED的文章就好了。前后端分离其实最大的问题是带来沟通成本的上升,具体来说就是接口的定义和调试。在上图的传统开发流程中,接口的定义会放在接口服务器中,然后前后端各自根据接口文档造假数据进行本地调试,之后进行联调。这个环节就是前后端开始撕逼的时候了,这个参数不对,那个返回值不对,总之很浪费时间。接下来看这个问题在我们项目中是怎么解决的~
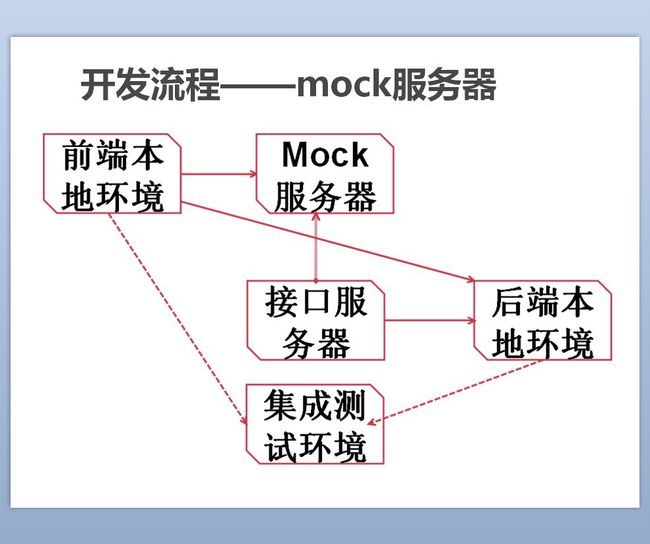
前后端因为接口撕逼的问题一直存在,作为保守主义的我相信迭代开发,所以第一步做的只是增加了一个mock服务器。这个服务器的神奇之处就是根据接口文档自动生成假数据,实现了接口即API,前端同学再也不用把数据写死进行测试了。没办法,谁叫我是前端开发,首先想到自己人,嘿嘿~当然这个只在一定程度上有利于前端开发,后端的接口和文档不一致联调时也会出现问题。怎么办?
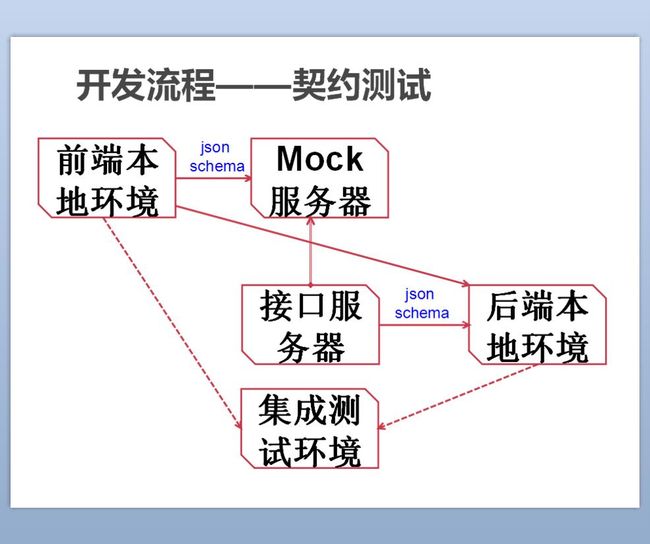
偶然在破浪大神的博客上看到老马的一篇专门讲前后端分离的文章,其中一个重要的概念就是契约测试也叫双边测试吧。核心概念就是为了解决远程联调的问题。对前后端的参数都进行校验,要求大家按照接口文档进行开发。受其启发,加入json-schema规则,实现了对http请求的参数校验,谁不按规矩来谁改。
这个redmine是我们最早的接口文档管理器,除了记录和查看功能再无其他作用。
swagger号称世界最流行的接口文档服务器,界面美观,插件也还比较多,可以针对后端语言直接生成测试代码。不过部署的时候始终没玩懂,而且yaml格式不如json习惯,放弃了它。
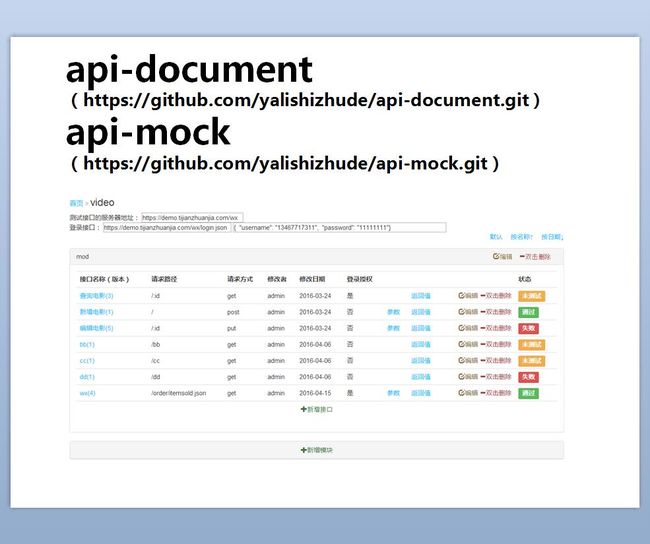
这就是现在我们项目上用的文档服务器和mock服务器,基于MEAN技术实现的服务器,基本功能:
利用mockjs插件,可以动态生成随机数据基于json-schema对接口参数实行校验和接口测试,并保存测试状态和接口响应时间。简单的json编辑器带有登陆校验功能,可登陆后进行接口调试mock服务器按照api服务器来响应请求,接口更新时自动更新
一些问题

node.js是前端工程师的翅膀,而插上翅膀是变成天使还是变成恶魔?这个要看能不能解决的使用它时带来的问题了。
首先前端的工作量毫无疑问地会增加,但沟通成本会降低。node.js单线程的服务器稳定性确实不够好,不过代码的健壮性和完善的日志可以有效的规避。回调。这个问题解决方法就太多了,node.js的q/async模块以及ES6/ES7。node.js调试。虽然我一直排斥IDE,但不得不承认webstorm在调试上确实很方便。我用的node-inspector也还凑合,界面类似chrome开发者工具,看上去挺熟悉的。

如果对于后端程序员,更加应该拥簇node.js了。接口整合的工作交给了前端服务器进行处理,同时和前端耦合度大大降低,工作量和工作效率都减少了。

心得体会有两点
node.js的使用虽然有一定的学习成本,但对于前端开发人员还是很友好的。而且前端使用node.js的话,无论是技术含量还是工作量都会有所提升,从而提升了岗位的重要性。当前端开发人员能创造更多价值的时候才有资格要求更高的薪水~工作中建议少提建议多给可行性方案,同时进行技术预研而不是写个简单的helloworld。
总结
可能有人说你介绍的这一套东西这么复杂,用起来太麻烦了,还不如面对面沟通。 对于这样的质疑我只能用腾讯高级UI工程师余果在《web全栈工程师的自我修养》中讲到的一个例子。有一次他电面一家小公司的前端负责人问他怎么管理代码时,对方说直接用ftp上传,同时抱怨手下人老是更新错代码,又问他为什么不用svn或git,他说还不如手动更新方便。 这个故事的道理就是我面对质疑的回答~
ppt下载地址