windows环境下,python+impyla+hive2
写在前面:我的需求是使用python连接hive数据库,读取数据库中的数据。首先,我自己搭建了hadoop集群,包含三个节点,安装了hive数据库,导入了一些数据。在这过程中,遇到了很多错误,查找了很多文档,现在简单整理一下思路方便以后查找。
1.环境说明:
win10
python编译器:PyCharm
集群环境:
CentOS 6.7
hadoop 2.7.3
hive 2.3.2
2.大致步骤
总体来说分为两个步骤。(1)配置hiveserver2(2)基于implay连接hive数据库,读取数据
2.1配置hiveserver2
(1)修改hdfs-site.xml、core-site.xml、hive-site.xml。分别在这三个配置文件中添加如下内容:
hdfs-site.xml:表示启用 webhdfs
dfs.webhdfs.enabled
true
core-site.xml:
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hadoop.proxyuser.hadoop.hosts
*
hadoop.proxyuser.hadoop.groups
*
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
( 如果代理用户的组所属root 则修改为:hadoop.proxyuser.root.hosts
hadoop.proxyuser.root.groups )
注意:在一个节点上修改好以后,要发送给集群中的其他所有节点。
hive-site.xml
hive.server2.authentication
NONE
**
hive.server2.thrift.port
10000
hive.server2.thrift.bind.host
192.168.27.101 --自己的IP地址
(2)在安装hive的节点上启动hiverserver2(hive版本不同,启动命令不一样。)

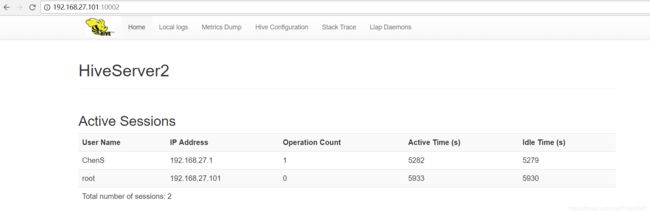
(3)复制一个窗口,打开beeline,连接hive2。出现红线所示即为连接成功。

访问web页面如图所示:
beeline连接hiveservre2时遇到了如下错误:
 解决办法:文件权限问题。原文链接https://www.cnblogs.com/zhangeamon/p/5787365.html
解决办法:文件权限问题。原文链接https://www.cnblogs.com/zhangeamon/p/5787365.html
2.2 基于implay连接hive数据库
python连接数据库有两种方式:(1)基于pyhive(2)基于implay
一开始使用的是基于pyhive,由于种种原因没有成功。所以使用了基于implay
(1)导包:
1、pip install six 2、pip install bit_array 3、pip install thriftpy thrift (on Python 2.x) or thriftpy (on Python 3.x) 4、pip install thrift_sasl==0.2.1 5、pip install pure-sasl 7、pip install impyla 8、pip install pandas(2)代码如下:
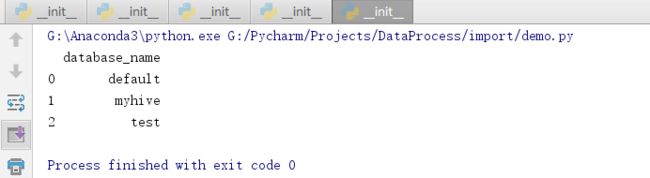
from impala.dbapi import connect from impala.util import as_pandas conn = connect(host='192.168.27.101', port=10000, auth_mechanism='PLAIN', user='root', password='123456') cursor = conn.cursor() cursor.execute('show databases') print(as_pandas(cursor)) cursor.close() conn.close()(3)运行结果:
参考文档:
https://blog.csdn.net/qq_24908345/article/details/80595948
https://blog.csdn.net/xuyanhuiwelcome/article/details/69946205
https://blog.csdn.net/Xiblade/article/details/82318294