网络爬虫基础(嵩天老师爬虫教学)
本博客的主要内容:介绍如何使用基本的库完成对html页面内容的爬取和分析,分以下几方面介绍
介绍网络爬虫的基本工作过程
requests库的基本用法
使用BeautifulSoup对页面进行解析
1.介绍网络爬虫的基本工作过程
The Website is the API 我们应该将网页看成是一个我们获取信息的接口,我们可以通过python爬虫从中获取我们所需要的信息。
2.requests库的基本使用
requests库有好几种方法,这里我们介绍最主要的get和post方法
import requests
r = requests.get("http://python123.io/ws/demo.html")
print(r)
#返回码200表示访问正常
r.encoding = r.apparent_encoding #使用该语句将正确的编码给到 r
r.text #打印出html页面的内容
'This is a python demo page \r\n\r\nThe demo python introduces several python courses.
\r\nPython is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\nBasic Python and Advanced Python .
\r\n'
以上说明成功访问了,但是存在一些网站我们通过以上的操作访问不成功,且手动点击却可以访问成功。大概率是因为我们的请求头的原因,看一下我们的请求头
r.request.headers
{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
可以看到我们的User-Agent非常诚实地告诉服务器,这个请求来自python,有一些服务器过滤了python的请求,自然就访问不到了。
import requests
url = "http://python123.io/ws/demo.html"
head = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
r = requests.get(url,headers=head)
r.request.headers
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
这时可以看到我们的User-Agent变了。同理,其他参数也可以在字典中构建
如何向get中传递参数呢?这里我们使用百度搜索来介绍:我们打开百度的网址,进行一个简单的搜索,可以发现百度搜索是使用get传参的:www.baidu.com/s?wd=keyword 我们来尝试使用python搜索
import requests
kv = {'wd':'python'}
url = "http://www.baidu.com/s"
r = requests.get(url,params=kv)
print(r.request.url)
https://www.baidu.com/s?wd=python
成功进行访问。
这就是简单的get方式请求方法,对于POST方法,其实就是多了一个data参数
kv = {'key','value1','key2':'value2'}
r = requests.request('POST','http://python123.io.ws',data=kv)
body = '主体内容'
r = requests.request('POST', 'http://python123.io/ws', data=body)
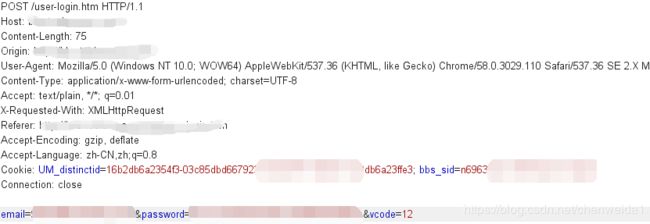
举一个常见的例子,很多账号登陆的过程都是使用POST提交账号密码以及验证码
kv = {'email':'[email protected] ', 'password': '123', 'vcode':12}
r = requests.post(url,data=kv)
r.request.body #查看到自己所提交的内容
一样也是很简单。
最后我们写一个简单的爬取网络图片的代码框架
import requests
import os
url = "http://pic16.nipic.com/20110819/1058141_160828281110_2.jpg" #这是我在网上随便找的一张图
root = "D://pics//" #
path = root + url.split('/')[-1] #使用图片原来的名称
try:
if not os.path exists(root): #判断我们电脑上是否存在该路径,没有的话创建该路径
os.mkdir(root)
if not os.path.exists(path): #判断该图片是否存在电脑,不存在就爬取
r = requests.get(path)
with open(path, 'wb') as f:
f.write(r.content) #r.content保存图片的二进制格式
f.close()
print(“文件保存成功”)
else:
print(“文件已存在”)
except:
print("爬取失败")
建议同学们使用try except来规范自己的代码。
使用BeautifulSoup对页面进行解析
主要功能:对html页面进行解析,通过各种方法以及属性提取关键信息
import requests
from bs4 import BeautifulSoup
r = requests.get("http://python123.io/ws/demo.html")
r.encoding = r.apparent.encoding
demo = r.text
soup = BeautifulSoup(demo,'html.parser') # BeautifulSoup有好几种解析器,我们使用html.parser解析html页面
soup.find('a') #以标签的格式返回第一个标签,为什么强调标签格式,因为后面使用的find_all()返回的是一个列表形式
* Basic Python *
soup.find_all('a') #返回的是所有标签,并且是以列表形式返回的
*[ Basic Python ,
Advanced Python ]*
上面是使用标签来定位查找,我们也可以用标签内关键字来查找,比如使用id来查找
import re
soup.find_all(id=re.compile('link'))
*[Basic Python ,
Advanced Python ]*
还可以使用字符串来查找,也就是我们html页面看到的内容
soup.find_all(string=re.compile('python'))
*['This is a python demo page',
'The demo python introduces several python courses.']*
通过以上方法我们可以得到指定标签指定属性的值,或者是字符串的内容。
打印所有标签:
for tag in soup.find_all(True):
print(tag.name)
html
head
title
body
p
....
中国大学排名 http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html 网站获取中国2016大学排名并输出
import requests
import bs4
from bs4 import BeautifulSoup
#第一步,实现页面内容的读取
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return " "
#第二步,提取html中关键的数据,这里我们使用二维的数据列表即可。
def fillUnivList(ulist,html):
soup = BeautifulSoup(html, 'html.parser') #html = getHTMLText(url)
for tr in soup.find('tbody').children: #从页面源码分析我们得到大学排名的标签是tbody的子标签
if isinstance(tr, bs4.element.Tag) # 这里因为开始和最后有两个非element.Tag属性的标签,需要去除掉
tds = tr.find_all('td') #将下的标签传给tds,这样tds就是一个 标签的列表
ulist.append([tds[0].string, tds[1].string, tds[3].string]) #将排名,学校名称,分数以列表形式传递给ulist
#第三步:指定打印出多少个学校
def printUnivList(ulist, num): #num指多少个学校
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}" #{3}表示以format中第三个变量来填充,chr(12288)是中文字符的空格,所以能够很好地显示
print(tplt.format("排名","学校名称","总分",chr(12288))) # ^代表居中对齐
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
#第四步:主函数
def main():
uinfo = []
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()
效果图:
你可能感兴趣的:(python)
使用Python将PDF文件转换为MOBI格式
choiiie
菜狗的怪问题合集 pdf python 经验分享
使用Python将PDF文件转换为MOBI格式引言在这篇文章中,我们将学习如何使用Python创建一个图形用户界面(GUI)应用程序,将PDF文件转换为MOBI格式。我们将使用tkinter作为GUI库,PyMuPDF或PyPDF2来处理PDF文件,以及Calibre的ebook-convert命令行工具来完成文件格式的转换。GitHub项目地址这个项目已经托管在GitHub上准备工作在开始之前,
JsonPath用法详解
吴少凡
python 开发语言 自动化 pycharm
JSONPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括Javascript、Python、PHP和Java。1、JSONPath安装:pipinstalljsonpath#如果安装太慢可以使用清华源来加速安装pipinstalljsonpath-ihttps://pypi.tuna.tsinghua.edu.cn/simple2、JSONPath语法J
python批量转化pdf图片为jpg图片
不懂python不懂R
python python pdf
1.把pdf图片批量转为jpg;需要注意的是,需要先安装poppler这个软件,具体安装教程放在下面代码中了2.代码#poppler安装教程参考:https://blog.csdn.net/wy01415/article/details/110257130#windows上poppler下载链接:https://github.com/oschwartz10612/poppler-windowsfr
python程序中调用openai接口
MEMORYLORRY
gpt openai gpt 人工智能 机器学习 python transformer
调用openai接口1.openai例子(国内访问)2.解决思路3.搭建nginx3.1创建OpenSSL创建证书3.2nginx配置3.3验证效果4.python调用5.SSL:certificate_verify_failed错误1.openai例子(国内访问)fromopenaiimportOpenAIAPI_KEY='sk-api-key'client=OpenAI(api_key=API
python config使用
Soochow_NJU_Smile
python config
config.cfg[test]filename=C:\\Users\\86188\\Desktop\\study\\configstudy\\fire.png[detect]number=1main.pyimportcv2importconfigparsercfg=configparser.ConfigParser()cfg.read('config.cfg')source=cfg.get('t
2024年最全办公室文员必备python神器,将PDF文件表格转换成excel表格!(1),把面试官逗笑了
TOP级别安卓开发
程序员 python pdf excel
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。一、Python所有方向的学习路线Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。二、学习软件工欲善其必先利其器。学习Py
第 9 课 Python 异常处理
嵌入式老牛
Python入门 python 开发语言
1.异常与错误程序错误是指语法错误(指令输入不正确)和逻辑错误(程序执行结果不正确),而程序异常是一个意外事件,该事件会在程序执行过程中发生,影响了程序的正常执行,比如:打开的文件不存在、被除数为0、操作的数据类型不对、存储错误,互联网请求错误等等。一般情况下,在Python无法正常处理程序时就会发生一个异常。异常是Python对象,表示一个错误。当Python脚本发生异常时我们需要捕获处理它,否
华为OD机试E卷 -boss的收入(Java & Python& JS & C++ & C )
算法大师
最新华为OD机试 华为od java python javascript c++ c语言 华为od机考e卷
最新华为OD机试真题目录:点击查看目录华为OD面试真题精选:点击立即查看题目描述一个XX产品行销总公司,只有一个boss,其有若干一级分销,一级分销又有若干二级分销,每个分销只有唯一的上级分销。规定,每个月,下级分销需要将自己的总收入(自己的+下级上交的)每满100元上交15元给自己的上级。现给出一组分销的关系,和每个分销的收入,请找出boss并计算出这个boss的收入。比如:收入100元,上交1
如何用Python将pdf文件转化为高清图片
张登杰踩
pdf
最近在整理文档,需要将文档进行OCR识别,然后结构化。直接解析pdf文档,行不通,因为文档里面是图片。于是采取先转图片,然后OCR,然后结构化。下面是pdf文档转图片的方法。importfitz#PyMuPDFdefpdf_to_images(pdf_path,images_folder):#打开PDF文件document=fitz.open(pdf_path)forpage_numinrange
华为OD机试E卷 --选修课--24年OD统一考试(Java & JS & Python & C & C++)
飞码创造者
最新华为OD机试题库2024 华为od java javascript python js c语言
文章目录题目描述输入描述输出描述用例题目解析JS算法源码Java算法源码python算法源码c算法源码题目描述现有两门选修课,每门选修课都有一部分学生选修,每个学生都有选修课的成绩,需要你找出同时选修了两门选修课的学生,先按照班级进行划分,班级编号小的先输出,每个班级按照两门选修课成绩和的降序排序,成绩相同时按照学生的学号升序排序。输入描述第一行为第一门选修课学生的成绩,第二行为第二门选修课学生的
Python调用open ai接口
蓝天星空
编程 人工智能 python
要使用Python调用OpenAI的接口,您需要完成以下几个步骤:1.**注册并获取API密钥**2.**安装OpenAI的Python库**3.**编写Python代码以调用API**以下是详细的步骤说明:---###1.注册并获取API密钥首先,您需要在[OpenAI官方网站](https://beta.openai.com/signup/)注册一个账户。注册完成后,您需要创建一个API密钥:
Linux搭建wordpress
长江空自流
vps linux wordpress 安装
Linux搭建wordpress一、环境vps:Centos6x86minimal512ram小内存xshell5:ssh远程连接主机首先搭建lamp环境(linuxapachemysqlphp或python等)二、apache1安装yuminstallhttpd2启动apacheservicehttpdstart直接在浏览器中输入IP地址,应该就可以访问到Apache的欢迎页面了三、mysql1
python中strip()和split()的使用方法(学习笔记)
木子_李轩
笔记
1.strip():用于移除字符串头、尾指定的字符(默认空格),不能删除中间部分的字符。#未使用strip()path=r"C:\Users\67539\Desktop\22\11.txt"f=open(path,"r")forlineinf:#按行读取print(line)f.close()#结果cat22airplane23dog58mug86#########################
Flask基础和URL映射
終不似少年遊*
python进阶学习 flask python 后端 开发框架
目录1.Flask介绍2.Flask第一个应用程序3.Flask运行方式4.Flask中DEBUG模式5.Flask环境参数的加载6.Flask路径参数的使用7.Flask路径参数类型8.Flask路径参数类型转换底层9.Flask自定义路由转换器自定义步骤:10.自定义转换to_python函数11.Postman的使用功能:使用示例:12.查询参数的使用13.请求体参数的使用14.上传文件的使
python strip() 函数和 split() 函数的详解
xinyuerr
java python python java 数据库
本文主要介绍了pythonstrip()函数和split()函数的详解及实例的相关资料,需要的朋友可以参考下pythonstrip()函数和split()函数的详解及实例一直以来都分不清楚strip和split的功能,实际上strip是删除的意思;而split则是分割的意思。因此也表示了这两个功能是完全不一样的,strip可以删除字符串的某些字符,而split则是根据规定的字符将字符串进行分割。下
CH4 - Python开发技术—流程控制之分支结构 (头歌)
MSY~学习日记分享
python python 开发语言
目录第1关:英制单位英寸与公制单位厘米互换第2关:百分制成绩转换为等级制成绩第3关:约瑟夫环问题第1关:英制单位英寸与公制单位厘米互换"""英制单位英寸和公制单位厘米互换"""defcmin(value,unit):''':paramvalue:长度,:paramunit:单位'''#请在此处添加代码##*************begin************#ifunit=='cm'orun
Python中strip()函数和split()函数用法:
半吊子烟酒僧
函数
pythonstrip()函数和split()函数:strip是删除的意思;split则是分割的意思。strip可以删除字符串的某些字符,而split则是根据规定的字符将字符串进行分割。1Pythonstrip()函数介绍:声明:s为字符串,x为要删除的字符序列s.strip(x)删除s字符串中开头、结尾处为x的序列字符s.lstrip(x)删除s字符串中开头处为x的序列字符s.rstrip(x)
python面试情景题_50道python笔试面试真题大集合
我是史迪仔
python面试情景题
Python爬虫人工智能100GBweb爬虫数据分析人工智能视频免费领题目后面有50道题答案领取方式哦1、一行代码实现1--100之和利用sum()函数求和2、如何在一个函数内部修改全局变量利用global修改全局变量3、列出5个python标准库os:提供了不少与操作系统相关联的函数sys:通常用于命令行参数re:正则匹配math:数学运算datetime:处理日期时间4、字典如何删除键和合并两
Error in py_run_file_impl(file, local, convert) : ModuleNotFoundError: No module named ‘igraph‘
hyena_7
Python R 服务器配置 python r语言 开发语言
在HPC平台上跑我的R语言代码,结果一直报错说:Errorinpy_run_file_impl(file,local,convert):ModuleNotFoundError:Nomodulenamed'igraph'我就知道是我R语言里面导入python包那里出现了问题,对应的python环境没有这个包,我进入了R环境,使用命令如下:library(reticulate)py_module_av
python strip() 详解
薇远镖局
Python python 开发语言
strip()是Python字符串方法之一,用于移除字符串开头和结尾的空白字符(包括空格、制表符、换行符等)或指定字符。它不会影响字符串中间的空白字符。语法str.strip([chars])参数chars(可选):一个字符串,表示要移除的字符集合。如果未指定,默认移除空白字符。返回值返回一个新的字符串,表示移除了开头和结尾指定字符后的结果。示例1、移除空白字符:s="Hello,World!"p
Python--字符串
小丁丁_ddxdd
技术层-python
描述Pythonstrip()方法用于移除字符串头尾指定的字符(默认为空格)。语法strip()方法语法:str.strip([chars]);参数chars--移除字符串头尾指定的字符。返回值返回移除字符串头尾指定的字符生成的新字符串。实例以下实例展示了strip()函数的使用方法:#!/usr/bin/pythonstr="0000000thisisstringexample....wow!!
使用uWSGI将Flask应用部署到生产环境
liuhongyue
flask python 后端
使用uWSGI将Flask应用部署到生产环境:1、安装uWSGIcondainstall-cconda-forgeuwsgi(pipinstalluwsgi会报错)2、配置uWSGI在python程序的同一文件夹下创建uwsgi.ini文件,文件内容如下表。需要按照实际情况修改文件名称地址,log文件保存路径,启动的进程数和线程数等3、启动服务,执行命令:uwsgi--iniuwsgi.ini4、
centos7中报错ModuleNotFoundError: No module named ‘_ctypes‘解决方法
丢失想象
centos python
分析:python3中有个内置模块叫ctypes,它是python3的外部函数库模块,提供了兼容C语言的数据类型,并通过它调用Linux系统下的共享库(Sharedlibrary),此模块需要使用centos7系统中外部函数库(Foreignfunctionlibrary)的开发链接库(头文件和链接库)。由于在centos7系统中没有安装外部函数库(libffi)的开发链接库软件包,所以在安装pi
Python酷库之旅-第三方库Pandas(008)
神奇夜光杯
python pandas 人工智能 开发语言 excel 标准库及第三方库 学习和成长
目录一、用法精讲16、pandas.DataFrame.to_json函数16-1、语法16-2、参数16-3、功能16-4、返回值16-5、说明16-6、用法16-6-1、数据准备16-6-2、代码示例16-6-3、结果输出17、pandas.read_html函数17-1、语法17-2、参数17-3、功能17-4、返回值17-5、说明17-6、用法17-6-1、数据准备17-6-2、代码示例1
Python 中的 strip() 和 split() 方法详解
Ryann6
python 开发语言
目录一、strip()方法1.什么是strip()?2.基本语法3.基本用法示例1)去除空白字符2)移除指定字符4.lstrip()和rstrip()5.注意事项二、split()方法1.什么是split()?2.基本语法3.基本用法示例1)按空格分割字符串2)指定分隔符3)限制分割次数4.rsplit()方法5.splitlines()方法三、strip()与split()的结合使用1)移除空格
安装auto_gptq解决办法
Ven%
简单说深度学习 Ubuntu 深度学习基础动手 人工智能 深度学习 机器学习 python
这个错误表明在安装auto_gptq包时,生成QiGen内核时失败了。具体来说,setup.py脚本尝试运行一个Python脚本来生成内核,但该脚本不存在或无法访问。以下是一些可能的解决方案:1.确保依赖项已安装首先,确保你已经安装了所有必要的依赖项。你可以尝试以下命令来安装auto_gptq的依赖项:pipinstalltorchtransformers2.使用预编译的二进制文件如果你不需要从源
6. 马科维茨资产组合模型+政策意图AI金融智能体(DeepSeek-V3)增强方案(理论+Python实战)
AI量金术师
金融资产组合模型进化论 人工智能 金融 python 机器学习 算法 大数据 数学建模
目录0.承前1.幻方量化&DeepSeek1.1Whatis幻方量化1.2WhatisDeepSeek2.重写AI金融智能体函数3.汇总代码4.反思4.1不足之处4.2提升思路5.启后0.承前本篇博文是对上一篇文章,链接:5.马科维茨资产组合模型+政策意图AI金融智能体(Qwen-Max)增强方案(理论+Python实战)的AI金融智能体更改为幻方量化DeepSeek-V3的尝试。唯一区别之处在于
python使用matplotlib可视化多个分组并排的柱状图(bar plot side by side)
Data+Science+Insight
数据科学从0到1 python 机器学习 数据挖掘 人工智能 深度学习
python使用matplotlib可视化多个分组并排的柱状图(barplotsidebyside)目录python使用matplotlib可视化多个分组并排的柱状图(barplotsidebyside)#导入包和库#python使用matplotlib可视化多个分组并排的柱状图(barplotsidebyside)#导入包和库importpandasaspdimportnumpyasnp#不显示
python使用TestLink-API-Python-client库对testLink操作——excel导入
fairytaildhk
python python testLink excel
依赖库:TestLink-API-Python-client,xlrd通过pip安装:python3-mpipinstallTestLink-API-Python-client(笔者本地有多个版本python,只有一个版本直接python就可以)url:替换自己的testLink地址http://xx.xx.xx.xx:xxxx/testlink/lib/api/xmlrpc/v1/xmlrpc.
python方差分析误差棒_一文讲透,带你学会用Python绘制带误差棒的柱状图和条形图...
加勒比考斯
python方差分析误差棒
Python数据可视化,作为数据常用的必备技能,是目前大数据和数据分析的一个热门,而matplotlib库作为Python中最为常用和经典的二维绘图库,受到了很多人的青睐,最近已经和大家共同探讨了多种类型的图表的绘制,其中关于误差棒图,咱们已经在上次一起讨论过了,今天咱们继续深入研究误差棒图相关的知识。那今天咱们聊点什么呢?咱们一起探讨一下如何在Python中绘制带误差棒的柱状图和条形图吧!首先,
对于规范和实现,你会混淆吗?
yangshangchuan
HotSpot
昨晚和朋友聊天,喝了点咖啡,由于我经常喝茶,很长时间没喝咖啡了,所以失眠了,于是起床读JVM规范,读完后在朋友圈发了一条信息:
JVM Run-Time Data Areas:The Java Virtual Machine defines various run-time data areas that are used during execution of a program. So
android 网络
百合不是茶
网络
android的网络编程和java的一样没什么好分析的都是一些死的照着写就可以了,所以记录下来 方便查找 , 服务器使用的是TomCat
服务器代码; servlet的使用需要在xml中注册
package servlet;
import java.io.IOException;
import java.util.Arr
[读书笔记]读法拉第传
comsci
读书笔记
1831年的时候,一年可以赚到1000英镑的人..应该很少的...
要成为一个科学家,没有足够的资金支持,很多实验都无法完成
但是当钱赚够了以后....就不能够一直在商业和市场中徘徊......
随机数的产生
沐刃青蛟
随机数
c++中阐述随机数的方法有两种:
一是产生假随机数(不管操作多少次,所产生的数都不会改变)
这类随机数是使用了默认的种子值产生的,所以每次都是一样的。
//默认种子
for (int i = 0; i < 5; i++)
{
cout<<
PHP检测函数所在的文件名
IT独行者
PHP 函数
很简单的功能,用到PHP中的反射机制,具体使用的是ReflectionFunction类,可以获取指定函数所在PHP脚本中的具体位置。 创建引用脚本。
代码:
[php]
view plain
copy
// Filename: functions.php
<?php&nbs
银行各系统功能简介
文强chu
金融
银行各系统功能简介 业务系统 核心业务系统 业务功能包括:总账管理、卡系统管理、客户信息管理、额度控管、存款、贷款、资金业务、国际结算、支付结算、对外接口等 清分清算系统 以清算日期为准,将账务类交易、非账务类交易的手续费、代理费、网络服务费等相关费用,按费用类型计算应收、应付金额,经过清算人员确认后上送核心系统完成结算的过程 国际结算系
Python学习1(pip django 安装以及第一个project)
小桔子
python django pip
最近开始学习python,要安装个pip的工具。听说这个工具很强大,安装了它,在安装第三方工具的话so easy!然后也下载了,按照别人给的教程开始安装,奶奶的怎么也安装不上!
第一步:官方下载pip-1.5.6.tar.gz, https://pypi.python.org/pypi/pip easy!
第二部:解压这个压缩文件,会看到一个setup.p
php 数组
aichenglong
PHP 排序 数组 循环 多维数组
1 php中的创建数组
$product = array('tires','oil','spark');//array()实际上是语言结构而不 是函数
2 如果需要创建一个升序的排列的数字保存在一个数组中,可以使用range()函数来自动创建数组
$numbers=range(1,10)//1 2 3 4 5 6 7 8 9 10
$numbers=range(1,10,
安装python2.7
AILIKES
python
安装python2.7
1、下载可从 http://www.python.org/进行下载#wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
2、复制解压
#mkdir -p /opt/usr/python
#cp /opt/soft/Python-2
java异常的处理探讨
百合不是茶
JAVA异常
//java异常
/*
1,了解java 中的异常处理机制,有三种操作
a,声明异常
b,抛出异常
c,捕获异常
2,学会使用try-catch-finally来处理异常
3,学会如何声明异常和抛出异常
4,学会创建自己的异常
*/
//2,学会使用try-catch-finally来处理异常
getElementsByName实例
bijian1013
element
实例1:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/x
探索JUnit4扩展:Runner
bijian1013
java 单元测试 JUnit
参加敏捷培训时,教练提到Junit4的Runner和Rule,于是特上网查一下,发现很多都讲的太理论,或者是举的例子实在是太牵强。多搜索了几下,搜索到两篇我觉得写的非常好的文章。
文章地址:http://www.blogjava.net/jiangshachina/archive/20
[MongoDB学习笔记二]MongoDB副本集
bit1129
mongodb
1. 副本集的特性
1)一台主服务器(Primary),多台从服务器(Secondary)
2)Primary挂了之后,从服务器自动完成从它们之中选举一台服务器作为主服务器,继续工作,这就解决了单点故障,因此,在这种情况下,MongoDB集群能够继续工作
3)挂了的主服务器恢复到集群中只能以Secondary服务器的角色加入进来
2
【Spark八十一】Hive in the spark assembly
bit1129
assembly
Spark SQL supports most commonly used features of HiveQL. However, different HiveQL statements are executed in different manners:
1. DDL statements (e.g. CREATE TABLE, DROP TABLE, etc.)
Nginx问题定位之监控进程异常退出
ronin47
nginx在运行过程中是否稳定,是否有异常退出过?这里总结几项平时会用到的小技巧。
1. 在error.log中查看是否有signal项,如果有,看看signal是多少。
比如,这是一个异常退出的情况:
$grep signal error.log
2012/12/24 16:39:56 [alert] 13661#0: worker process 13666 exited on s
No grammar constraints (DTD or XML schema).....两种解决方法
byalias
xml
方法一:常用方法 关闭XML验证
工具栏:windows => preferences => xml => xml files => validation => Indicate when no grammar is specified:选择Ignore即可。
方法二:(个人推荐)
添加 内容如下
<?xml version=
Netty源码学习-DefaultChannelPipeline
bylijinnan
netty
package com.ljn.channel;
/**
* ChannelPipeline采用的是Intercepting Filter 模式
* 但由于用到两个双向链表和内部类,这个模式看起来不是那么明显,需要仔细查看调用过程才发现
*
* 下面对ChannelPipeline作一个模拟,只模拟关键代码:
*/
public class Pipeline {
MYSQL数据库常用备份及恢复语句
chicony
mysql
备份MySQL数据库的命令,可以加选不同的参数选项来实现不同格式的要求。
mysqldump -h主机 -u用户名 -p密码 数据库名 > 文件
备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > ba
小白谈谈云计算--基于Google三大论文
CrazyMizzz
Google 云计算 GFS
之前在没有接触到云计算之前,只是对云计算有一点点模糊的概念,觉得这是一个很高大上的东西,似乎离我们大一的还很远。后来有机会上了一节云计算的普及课程吧,并且在之前的一周里拜读了谷歌三大论文。不敢说理解,至少囫囵吞枣啃下了一大堆看不明白的理论。现在就简单聊聊我对于云计算的了解。
我先说说GFS
&n
hadoop 平衡空间设置方法
daizj
hadoop balancer
在hdfs-site.xml中增加设置balance的带宽,默认只有1M:
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description&g
Eclipse程序员要掌握的常用快捷键
dcj3sjt126com
编程
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可以那么勤奋,每天都孜孜不倦得
Android学习之路
dcj3sjt126com
Android学习
转自:http://blog.csdn.net/ryantang03/article/details/6901459
以前有J2EE基础,接触JAVA也有两三年的时间了,上手Android并不困难,思维上稍微转变一下就可以很快适应。以前做的都是WEB项目,现今体验移动终端项目,让我越来越觉得移动互联网应用是未来的主宰。
下面说说我学习Android的感受,我学Android首先是看MARS的视
java 遍历Map的四种方法
eksliang
java HashMap java 遍历Map的四种方法
转载请出自出处:
http://eksliang.iteye.com/blog/2059996
package com.ickes;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* 遍历Map的四种方式
【精典】数据库相关相关
gengzg
数据库
package C3P0;
import java.sql.Connection;
import java.sql.SQLException;
import java.beans.PropertyVetoException;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class DBPool{
自动补全
huyana_town
自动补全
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml&quo
jquery在线预览PDF文件,打开PDF文件
天梯梦
jquery
最主要的是使用到了一个jquery的插件jquery.media.js,使用这个插件就很容易实现了。
核心代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.
ViewPager刷新单个页面的方法
lovelease
android viewpager tag 刷新
使用ViewPager做滑动切换图片的效果时,如果图片是从网络下载的,那么再子线程中下载完图片时我们会使用handler通知UI线程,然后UI线程就可以调用mViewPager.getAdapter().notifyDataSetChanged()进行页面的刷新,但是viewpager不同于listview,你会发现单纯的调用notifyDataSetChanged()并不能刷新页面
利用按位取反(~)从复合枚举值里清除枚举值
草料场
enum
以 C# 中的 System.Drawing.FontStyle 为例。
如果需要同时有多种效果,
如:“粗体”和“下划线”的效果,可以用按位或(|)
FontStyle style = FontStyle.Bold | FontStyle.Underline;
如果需要去除 style 里的某一种效果,
Linux系统新手学习的11点建议
刘星宇
编程 工作 linux 脚本
随着Linux应用的扩展许多朋友开始接触Linux,根据学习Windwos的经验往往有一些茫然的感觉:不知从何处开始学起。这里介绍学习Linux的一些建议。
一、从基础开始:常常有些朋友在Linux论坛问一些问题,不过,其中大多数的问题都是很基础的。例如:为什么我使用一个命令的时候,系统告诉我找不到该目录,我要如何限制使用者的权限等问题,这些问题其实都不是很难的,只要了解了 Linu
hibernate dao层应用之HibernateDaoSupport二次封装
wangzhezichuan
DAO Hibernate
/**
* <p>方法描述:sql语句查询 返回List<Class> </p>
* <p>方法备注: Class 只能是自定义类 </p>
* @param calzz
* @param sql
* @return
* <p>创建人:王川</p>
* <p>创建时间:Jul