python自学笔记
https://www.cnblogs.com/secondtonone1/p/6796323.html
恋恋风辰
python自学笔记(一)
我没学过python,通过网上和一些图书资料,自学并且记下笔记。
很多细节留作以后自己做项目时再研究,这样能更高效一些。
python基础自学笔记
一、基本输入和输出
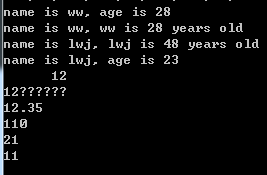
pthon3.0用input提示用户输入,用print提示用户输出,格式为print("...")
如果格式化输出,那么格式为print("%d" %(变量名)), %d可以替换为%s等其他格式符,
以后用到什么格式自己查,这样学起来高效。
简单的例子:
#-*-coding:utf-8-*-
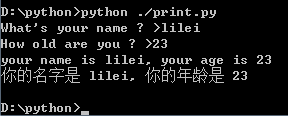
name = input("What's your name ? >")
age = input("How old are you ? >")
print ("your name is %s, your age is %d" %(name, int(age)))
print ("你的名字是 %s, 你的年龄是 %d" %(name,int(age)))
运行结果:
二、基本数据结构
1 列表
列表和C++里边的list差不多
插入方式为: list.insert(1,‘小草’);
1为要插入元素放在下标为1的位置,‘小草’为要插入的元素
移除元素的方式为:list.pop(3);
指定取出下标为3的元素
list中元素是按照从下标为0开始计算的。
如果要计算列表中元素个数可以通过len(list)计算。
下面是个小例子:
![]()
animals = ["大象","猴子","蚂蚁","豪猪"]
print ("动物园有这些动物:", animals)
lion = "狮子"
print ("新来了", lion)
animals.insert(1,lion)
print ("动物园有这些动物:", animals)
animals.pop(3)
print ("蚂蚁灭绝了")
print ("动物园有这些动物:", animals)
print ("老虎和狮子交配生了两个小宝宝")
babies = ["小宝宝1号", "小宝宝2号"]
animals.insert(2,babies);
print ("动物园有这些动物:", animals)
print("饲养员给两个小宝宝取了名字")
animals[2][0]="小毛"
animals[2][1]="大毛"
print ("动物园有这些动物:",animals)
print("列表中有%d个元素" %len(animals))
print("第三个元素包含%d个元素" %len(animals[2]))
![]()
试着用python 运行上面这个程序
2 tuple(元组)
tuple定义之后不可修改,理解为不可修改的列表就行了
试着运行下面这个程序,看看结果:
![]()
#-*-coding:utf-8-*-
nums = (0,1)
print("nums are", nums)
another = (0,1,[3,4])
print("nums are", another)
another[2][0] = 5
print("nums are", another);
![]()
为什么another能被修改?因为another[2]指向的是list,接着将list的第一个元素,
下表为0的元素赋值为5,这是允许的。
3 dict(字典)
字典和C++map很相似,但是不完全相同,字典dict可以包含不同类型的key和value
字典的插入方式很简单d['韩梅梅']=23
d为字典定义的变量名,key为‘韩梅梅’, value为23
当字典d中没有‘韩梅梅’这个key,那么就会将key和value插入d
如果调用d[‘韩梅梅’]=22,那么‘韩梅梅’对应的value就为22了
如果字典d中没有‘李磊’这个key,那么调用print(d['李磊'])就会提示出错。
所以取元素的时候要记得判断字典中是否有该key对应的value
可以通过get和in判断,下边代码有使用方法。
字典同样调用pop移除元素
d.pop('韩梅梅')
下面这段代码综合了dict使用方式
![]()
infos = {"李明":23, "豆豆":22,"老李":55}
print("李明的年龄为%d" %(infos["李明"]))
infos["王立冬"]=32
print (infos)
#print (infos["梁田"])
if not ("梁田" in infos):
print("梁田不在记录")
print(infos.get("梁田"))
print(infos.get("梁田","梁田不在记录"))
infos.pop("王立冬")
print (infos)
![]()
用python调用上边代码,看看效果。
4 set(集合)
集合中允许存在多个重复的值
集合添加元素用add,删除用remove操作
下边的代码为集合操作
![]()
numset = set([1,3,5,7,9]) print(numset) numset.add(4) print(numset) numset.add(4) print(numset) numset.remove(3) print(numset) numset2 = set([2,4,6,8,10]) print(numset&numset2) print(numset|numset2)
![]()
三、循环和控制
这部分和C++差不多,就是基本写法不一样
![]()
nums = (0,100,34,50,179,130,27,22)
print("nums are:", nums)
bigernums =[]
smallnums = []
for num in nums:
if num > 50:
bigernums.append(num)
print("大于50的数字有:", bigernums)
for num in nums:
if num < 50:
smallnums.append(num)
print("小于50的数字有:", smallnums)
print(range(5))
print(list(range(5)))
#1~10数字求和
sum = 0
for num in list(range(11)):
sum += num
print("1到10数字求和结果为:%d" %sum)
#错误输出
#print("1到10数字求和结果为:%d", sum)
#换一种方式求和,while循环注意别写成死循环
i = 0
sum = 0
while i < 11:
sum += i
i=i+1#i++不行,习惯了C++
print("1到10数字求和结果为:%d" %sum)
![]()
python通过缩进和:控制模块。
四、函数
1 定义函数
#函数的定义
def judgeint(x):
if not isinstance(x,(int)):
raise TypeError('类型不匹配')
else:
return x
是通过def 函数名(参数):方式来定义函数。上面这个函数定义在func.py文件中,
我再写一个文件使用这个函数
![]()
from func import judgeint
numlist = [1,3,5]
strlist =['1','2','3']
for i in numlist:
print(judgeint(i))
for j in strlist:
print(strlist(j))
![]()
结果为:

可见strlist中字符串类型被函数识别并终止程序运行了。
想用到某个.py文件的函数可以用
from 文件名(不包含.py) import 函数名
如果想用文件中所有的接口
from 文件名(不包含.py) import *
其他的引用方式我也不会,以后遇到了再去查。
也可以去写一个空函数
#空函数
def emptyfun(x):
pass
pass表示什么都不做。
当然函数可以返回许多值,这些值其实是通过tuple返回的
定义函数
#多个返回值
def getposition(x,y):
return x, y
调用这个函数
from func import *
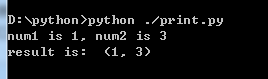
num1 = 0; num2 = 0
num1, num2 = getposition(1,3)
print('num1 is %d, num2 is %d' %(num1,num2))
print('result is: ', getposition(1,3) )
结果为:
2 函数参数分类和使用
1 位置参数
位置参数是普通的参数
如下:
def power(x):
return x*x
2 默认参数
默认参数提供了参数的默认赋值
![]()
#默认参数
def power(x,n = 2):
imul =1
while(n > 0):
imul = x*imul
n = n-1
return imul
![]()
值得注意的是默认参数要指向不可变对象,否则函数重复调用默认参数会被修改
def getList(L=[]):
L.append("end")
return L
重复调用看看结果如何:
#-*-coding:utf-8-*- from func import * L=[] print(getList(L)) print(getList(L))
结果

可以看出默认参数随着函数调用被修改了,所以尽量不要让默认参数指向可变对象,
list就是可变对象。
3 可变参数
可变参数使用和定义都非常方便
定义:
def calsum(*nums):
sum = 0
for i in nums:
sum = sum+ i
return sum
使用:
#-*-coding:utf-8-*- from func import * L=[1,3,5,7,9] print(calsum(*L)) print(calsum(*range(0,101)))
定义可变参数前边加*,使用时可以传入list,tuple等,实参前也加*即可。
4 关键字参数
其实和可变参数类似,关键字参数可以直接传入字典
定义:
![]()
def getinfo2(name, age, **info):
print("姓名:", name, "年龄:", age, "其他信息:", info)
def getinfo3(name,age,**info):
if 'city' in info:
print("有城市信息")
if 'job' in info:
print("有工作记录")
print("姓名:", name, "年龄:", age, "其他信息:", info)
![]()
定义关键字参数在形参前边加**
使用:在实参前加**表示取出字典中所有内容依次传递给函数
from func import *
info ={'性别':'女','job':'学生','city':'上海'}
info2 ={'性别':'男','job':'工人','city':'北京'}
getinfo2('韩梅梅', 23, **info)
getinfo3('李雷',25,**info2)
结果

5 命名关键字参数
命名关键字参数就是传入命名的关键字,如指定传入的关键字参数的key为‘city’,‘type’等等。
举例:
def getinfo8(name, age, *,city, job):
print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job)
def getinfo7(name, age, *infolist, city, job):
print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job, "其他信息:", infolist)
可以看出命名关键字参数格式为(*,指定名称1,指定名称2...)的格式
当明明关键字参数之前的参数为可变参数时,那么不需要*,只需指明指定的几个名成即可
格式为:(*可变参数,指定名称1,指定名称2...)
试着写个代码用一下:
![]()
from func import *
info ={'性别':'女','job':'学生','city':'上海'}
info2 ={'性别':'男','job':'工人','city':'北京'}
getinfo2('韩梅梅', 23, **info)
getinfo3('李雷',25,**info2)
getinfo8('王麻子',70, city ='南京', job = '裁缝')
infolist = ['有犯罪记录','酗酒']
getinfo7('张三',50,*infolist,city ='翰林',job ='无业游民')
![]()
读者自己打印下,看看结果

当然命名关键字参数可以提供默认值
def getinfo4(name, age,*,city='沈阳',job):
print("姓名:", name, "年龄:", age, "城市:", city, "工作:", job)
6 参数混合使用
当参数列表包含位置参数,默认参数,可变参数,关键字参数和明明关键字参数时,
从左到右的顺序为
位置参数,默认参数,可变参数,命名关键字参数,关键字参数
读者可以自己考虑下为什么这么规定
下面定义两个函数:
def getinfo5(name,age,city='沈阳',**info):
print("姓名:", name, "年龄:", age, "城市:", city, "其他信息:", info)
def getinfo6(name,age,city='沈阳',*infolist ,health = '良好', job,**otherinfo):
print("姓名:", name, "年龄:", age, "城市:", city, '工作信息:',job,'\n',
"身体状况", health, "个人备注",infolist,'\n',
"其他信息:", otherinfo)
使用这一系列定义的函数
info5 ={'性别':'男','job':'工人','兴趣':'修自行车'}
baselist=('Linkn',28,'上海','喜欢喝冰啤酒','爱打麻将')
getinfo6(*baselist,**info5)
getinfo5('Linkn',28,'上海',**info5);
函数调用传入实参都可以通过*arg,**dict格式,提高了开发效率
7 递归函数
递归函数和C++一样,先实现一个阶乘的函数
#递归计算阶乘函数
def imul2(num=1):
if num ==1:
return num
else:
return num * imul2(num-1)
print(imul2(3)) 看看结果
同样去实现汉诺塔
编写move(n, a, b, c)函数,它接收参数n,表示3个柱子A、B、C中第1个柱子A的盘子数量,
然后打印出把所有盘子从A借助B移动到C的方法,计算n==3时,移动方法

读者试着自己完成,我是这样实现的
![]()
def move(n,A,B,C):
if n==1:
print("%s --> %s" %(A,C))
return
else:
move(n-1,A,C,B)
move(1,A,B,C)
move(n-1,B,A,C)
![]()
调用
move(3,'A','B','C')
结果为

用递归很简单实现了复杂的逻辑,但是递归有一个问题就是当递归次数过大容易造成栈溢出。
基础先记到这里,下一篇会记录python的特性和函数编程。
恋恋风辰
python自学笔记(二)
https://www.cnblogs.com/secondtonone1/p/6813266.html
通过前文介绍,大体上可以用学过的知识做一些东西了。
这里简单介绍下python参数解析argparse命令。
使用argparse需要引用
import argparse
然后调用
parser = argparse.ArgumentParser()
ArgumentParser()函数可以传一些参数
parser = argparse.ArgumentParser(description='This is a PyMOTW sample program')
参数有很多种类型,读者自己查阅,参考资料的链接:
https://blog.ixxoo.me/argparse.html
接下来添加参数
parser.add_argument('file')
parser.add_argument('-o', '--output')
添加参数 -表示可选参数,用于一个字符,表示缩写
--也是可选参数,用于两个或以上的字符
最后是参数解析
parser.parse_args(['-o', 'output.txt'])
parse_args()运行时,会用'-'来认证可选参数,剩下的即为位置参数。
位置参数不可缺少,可选参数可提供默认值
如果python程序运行,parse_args()会依次处理传入参数,
第一个参数为该python程序的文件名,其余的依次为传入参数。
这些文字看不懂不要紧,试着看看下边的程序和运行结果
![]()
#-*-coding:utf-8-*-
import argparse
#命令行输入参数处理
parser = argparse.ArgumentParser()
parser.add_argument('file') #输入文件
parser.add_argument('-o', '--output') #输出文件
parser.add_argument('--width', type = int, default = 50) #输出字符画宽
parser.add_argument('--height', type = int, default = 30) #输出字符画高
#获取参数
args = parser.parse_args()
IMG = args.file
WIDTH = args.width
HEIGHT = args.height
OUTPUT = args.output
print("IMG is %s" %(IMG))
print("WIDTH is %d" %(WIDTH))
print("HEIGHT is %d" %(HEIGHT))
print("OUTPUT is %s" %(OUTPUT))
![]()
这个程序就是解析命令行参数,然后将输入的参数打印出来
如果不输入参数直接python test.py 试试?

提示缺少位置参数file
试试python test.py test.png
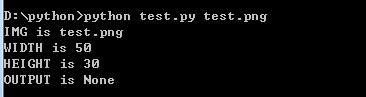
四个命令行参数打印出来了
--height 可选参数为默认值30
--width 可选参数为默认值50
file 位置参数为test.png
-o 为--output的缩写为None,因为没提供默认值。我也没输入-o参数
所以为None
输入python test.py test.png --width 30 -- height 50 -o output.txt

用全称--output录入也可以
python test.py test.png --width 30 -- height 50 --output output.txt

这个过了就可以往下做了,下面安装PIL库,PIL为python处理图形图像的基本库
windows安装的方式为:
http://jingyan.baidu.com/article/ff42efa929e6c8c19f220254.html
Linux安装方式为:
点击链接
下面编写图片转字符画程序:
将文件命名为print.py
1 包含库和函数,定义基本的字符序列
![]()
from PIL import Image
import argparse
#命令行输入参数处理
parser = argparse.ArgumentParser()
parser.add_argument('file') #输入文件
parser.add_argument('-o', '--output') #输出文件
parser.add_argument('--width', type = int, default = 50) #输出字符画宽
parser.add_argument('--height', type = int, default = 30) #输出字符画高
#获取参数
args = parser.parse_args()
IMG = args.file
WIDTH = args.width
HEIGHT = args.height
OUTPUT = args.output
ascii_char = list("$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. ")
![]()
2 编写转换函数
![]()
# 将256灰度映射到70个字符上
def get_char(r,g,b,alpha = 256):
if alpha == 0:
return ' '
length = len(ascii_char)
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
unit = (256.0 + 1)/length
return ascii_char[int(gray/unit)]
![]()
0.2126 * r + 0.7152 * g + 0.0722 * b为官方提供的
灰度计算公式,unit表示一个单元占多少灰度,
gray/unit可以找到对应的单元,从而转换为字符。
3调用get_char完成转换
![]()
if __name__ == '__main__':
im = Image.open(IMG)
im = im.resize((WIDTH,HEIGHT), Image.NEAREST)
txt = ""
for i in range(HEIGHT):
for j in range(WIDTH):
txt += get_char(*im.getpixel((j,i)))
txt += '\n'
print (txt)
#字符画输出到文件
if OUTPUT:
with open(OUTPUT,'w') as f:
f.write(txt)
else:
with open("output.txt",'w') as f:
f.write(txt)
![]()
Image为PIL提供的类,可以看看
Image基本功能
im.getpixel((j,i)) 通过传入横纵坐标,返回tuple
tuple中数据依次为r,g,b,alpha
之前讲过可以通过*() 或*[]实现逐个元素传入。
get_char(*im.getpixel((j,i)))将参数传入返回字符。
之后分别将字符打印出来,并写入文件。
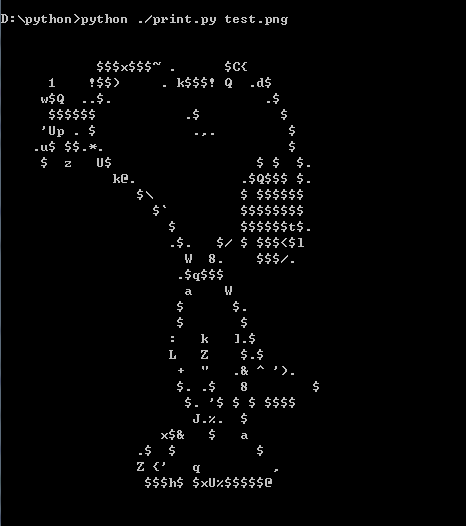
源码下载地址: python图片转字符画
效果如下:

https://www.cnblogs.com/secondtonone1/p/6892928.html
恋恋风辰
python学习笔记(三)高级特性
一、切片
list、tuple常常截取某一段元素,截取某一段元素的操作很常用 ,所以python提供了切片功能。
![]()
L=['a','b','c','d','e','f'] #取索引0,到索引3的元素,不包括索引3 print(L[0:3]) #开始索引为0可以省略 print(L[:3]) #下标1到3 print(L[1:3]) #取最后一个元素 print(L[-1]) #取倒数后两个元素 print(L[-2:]) #取前四个数,每两个取一个 print(L[:4:2]) #所有数,每两个取一个 print(L[::2])
![]()
二、迭代
除了list、tuple可以迭代外,python中的dict类型变量也可以迭代。
![]()
dictor = {'name':'Jul','age':17,'femail':1}
#迭代key
for key in dictor:
print(key)
#迭代value
for value in dictor.values():
print(value)
#迭代key,value
for k,v in dictor.items():
print(k,v)
![]()
可以将list变为索引元素对的形式
for x,y in [(1,2),(3,4),(5,6)]:
print(x,y)
#变为索引元素对
for i,value in enumerate(['A','B','C']):
print(i,value)
同时可以判断一个对象是否可以迭代
for x,y in [(1,2),(3,4),(5,6)]:
print(x,y)
#变为索引元素对
for i,value in enumerate(['A','B','C']):
print(i,value)
三、列表生成式
list函数可以将一组对象组合为列表,[]操作也可以。[]操作的方式称作列表生成式
print([x for x in range(1,11)]) print(list(range(1,11)))
在列表生成式中可以加入一些运算规则,使生成的列表具备运算规则。
![]()
#变为索引元素对
for i,value in enumerate(['A','B','C']):
print(i,value)
#平方
print([x*x for x in range(1,11)])
#偶数平方
print([x*x for x in range(1,11) if x%2 ])
#k:v形式的列表
strdic={'a':'a1','b':'b1','c':'c1'}
print([k+':'+v for k,v in strdic.items()])
#将列表中字符串换为小写
L = ['Hello', 'World', 18, 'Apple', None]
print([s.lower() for s in L if(isinstance(s,str)) ])
![]()
四、生成器
python提供生成器的功能,生成器根据函数或运算规则产生一系列数据,
通过对返回值g调用next(g)可以依次取出生成的数据。
g = (x*2 for x in range(1,11)) print(g) print(next(g))
可以一直调用next(g),直到产生StopIteration异常。
当然也可以通过函数构造生成器,将函数return的关键字换为yield即可。
![]()
#菲波那切数列
def fib(max):
a,b,n = 0,1,0
while n < max:
yield b
a,b=b,a+b
n = n+ 1
return "exit"
![]()
通过下面方式next取出数列中的元素,第三次调用会抛出StopIteration异常。
g=fib(2) print(g) print(next(g)) print(next(g)) #print(next(g))
上面代码中g为迭代器,通过对g不断调用next取出数列中元素。
可以通过检测异常的方式完成遍历,避免程序崩溃。
![]()
g2 = fib(6)
while True:
try:
value = next(g2)
print("value: ", value)
except StopIteration as e:
print("Generator return value is: ", e)
break
![]()
可以用生成器实现杨辉三角,生成器函数为triangles()。

生成器函数triangles()实现如下:
![]()
def triangles():
yield [1]
yield [1,1]
lists = [1,1]
while True:
i = 1
n = len(lists)
newlists = [1]
while i < n:
newlists.append(lists[i-1] + lists[i])
i = i+1
newlists.append(1)
lists = newlists
yield newlists
![]()
五、迭代器
python提供生成器的功能,生成器根据函数或运算规则产生一系列数据,
通过对返回值g调用next(g)可以依次取出生成的数据。g就是迭代器。
有的对象可以迭代但是不是迭代器,只有可以被next调用的对象才是迭代器。
同样可以通过isinstance函数判断迭代器。
![]()
from collections import Iterable
from collections import Iterator
b1 = isinstance([], Iterable)
b2 = isinstance([], Iterator)
print('[] is Iteralbe', b1)
print('[] is Iterator', b2)
b1 = isinstance({},Iterable)
b2 = isinstance({},Iterator)
print('[] is Iteralbe', b1)
print('[] is Iterator', b2)
b1 = isinstance((x*x for x in range(10)), Iterable)
b2 = isinstance((x*x for x in range(10)), Iterator)
print('x*x for x in range(10) isIterable', b1)
print('x*x for x in range(10) isIterator', b2)
#可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
b1 = isinstance(triangles(),Iterable)
b2 = isinstance(triangles(),Iterator)
print('triangles()', b1)
print('triangles()', b2)
![]()
特性就总结到此,下次会总结记录python函数的一些特性。
https://www.cnblogs.com/secondtonone1/p/6903191.html
恋恋风辰
python学习笔记(四) 思考和准备
一、zip的坑
zip()函数接收多个可迭代数列,将数列中的元素重新组合,在3.0中返回迭代器指向
数列首地址,在3.0以下版本返回List类型的列表数列。我用的是3.5版本python,
所以zip返回的是指向地址。
先看几个例子
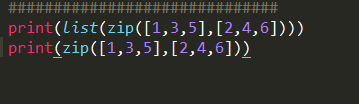
结果:
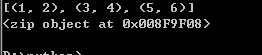
可见,在3.0以上版本,对zip函数返回的结果采用list函数可以转化为列表。
通过列表生成式同样可以将zip结果化为列表。
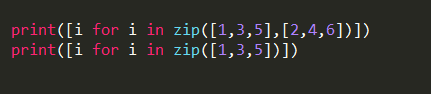
结果:
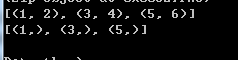
当zip操作的对象为一个列表,那么生成的列表中每个元素(元祖)中
为(n,)形式。
当zip操作的多个列表长度不一样,那么zip返回生成的列表中元素个数
为最短列表长度。

结果为:

list函数可以将一个元祖转化为列表。下面可以将zip返回的数据转化为
我们方便操作的列表元素.
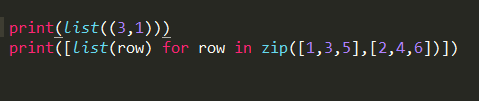
结果:
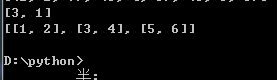
这样将zip函数返回的数据通过list和迭代,生成了二维List,方便以后操作。
下边这段代码在3.0版本以上和3.0版本以下会有不同结果。
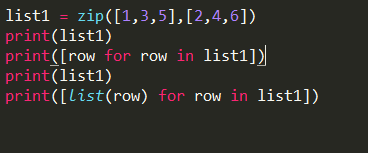
2.7版本结果:
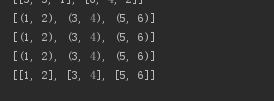
3.0版本结果
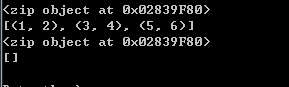
之前提起过zip在3.0以上版本返回迭代器指向内存地址。3.0以下
版本返回的为列表,所以在3.0版本一下输出是符合最初目的。
但是3.0版本python最后一行输出却为空列表[]。
这个原因主要是迭代器在被循环迭代或者访问后,会自动
移动指针,指向下一个要迭代的元素。这和C++是不同的,
C++/C语言需要用户自己控制迭代器移位。
那么肯定有人会说第一句和第三句打印的list1的值相同,
是不是list1迭代器指向的空间没有移动呢?
不是的,只要list1被循环迭代,内部指向空间的地址就会变化,
只是调用print打印list1时,python只返回迭代器指向空间的首地址,
而不会告诉具体指向的地址空间。
修改下代码,看看是不是上文所述那样:
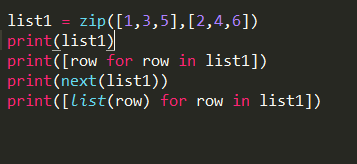
结果:
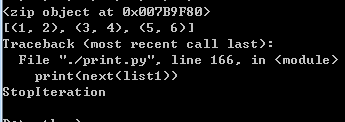
可见,输出list1指向地址内容的时候出现StopIteration异常,
这个异常前几篇介绍过,是因为迭代器已经指向空间的末尾了,
再调用就会出现该异常,所以对于迭代器当遍历迭代后一定要注意
迭代器指向地址变化的问题。
二、迭代器的坑
迭代器的问题就在于被迭代使用后,内部指向的地址空间变化了,
但是打印迭代器,返回的认为迭代器最初指向的内存空间首地址。
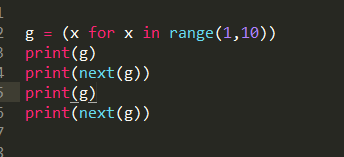
结果:
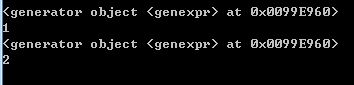
每次打印g返回结果都一样,但是g指向的位置确实变了。
说实话,这种隐藏性的问题应该让别人知道。
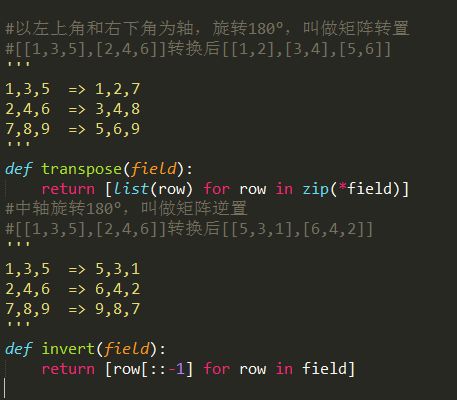
三、矩阵的转置和左右逆置
通过zip函数可以实现矩阵的转置和逆置,
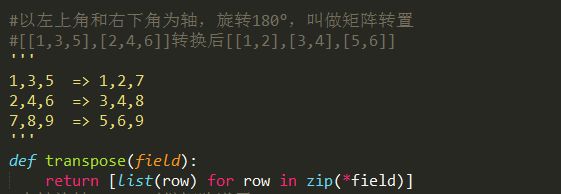
将矩阵按照每一行存储在一个list中,这些list再组合成一个大的list,构成二维list表示矩阵。
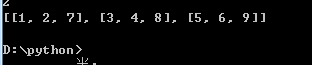
矩阵的转置:
下边的例子可以看效果:

结果:
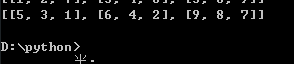
同样的道理,矩阵的左右逆置

结果:
四、format函数介绍
format函数通过{}替代%,实现字符串的动态匹配。

结果:
五、defaultdict函数介绍
实现一个统计字符串个数的功能。
strings = ('puppy', 'kitten', 'puppy', 'puppy',
'weasel', 'puppy', 'kitten', 'puppy')
如果用下边的代码实现统计功能
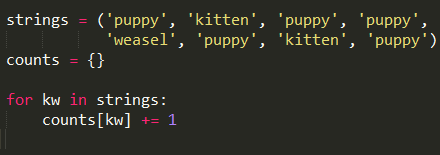
当counts中不存在某个单词,第一次调用counts[kw]+=1会提示报错。
所以有几种方式实现该功能。
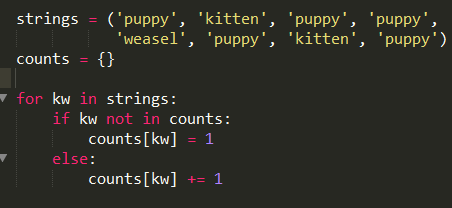
这种方式先判断counts中是否含有关键字,没有就先赋值。
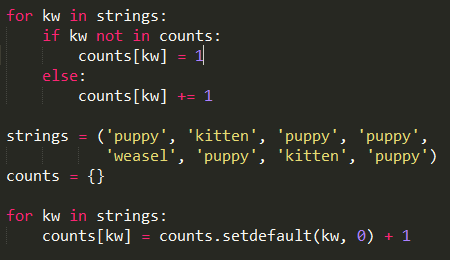
这种方式通过设置counts中关键字对应的默认值,当counts中不存在某个关键字,
那么该关键字对应的value为0,然后该值+1,表示第一次统计。
如果counts中存在该关键字,那么就不执行setdefault函数,关键字对应的value值加1。
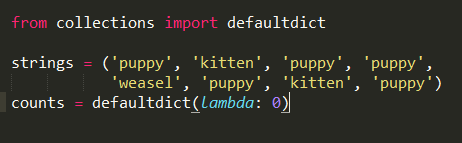
这种方式引用了collections的defaultdict,difaultdict接收一个函数,该函数
返回dict中元素的默认值。
六、any函数介绍
any函数接收一个可迭代对象,一般为list或者tuple,list或者tuple中有一个
元素满足条件any函数就返回true,当所有元素都不满足条件,any返回false

结果:

https://www.cnblogs.com/secondtonone1/p/6907195.html
恋恋风辰
python学习笔记(五) 200行实现2048小游戏
用前文提到的基础知识,和网上流行的2048源码,用python实现该游戏。
先将用户操作和游戏逻辑绑定。
WASD分别对应移动方向上、左、下、右
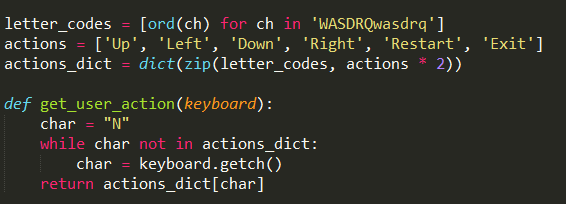
然后实现矩阵的转置和逆置,这样只要实现一个方向的移动,通过转置和逆置就可以得到其他方向
的移动。
基本的函数声明完成了,下面定义GameField类,主要实现游戏逻辑和状态转换。
GameField类和其中包含的一些函数。先看构造函数。
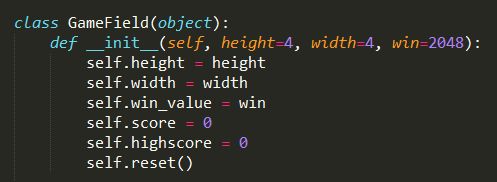
构造棋盘并且刷新棋盘,作为初次游戏的布局。
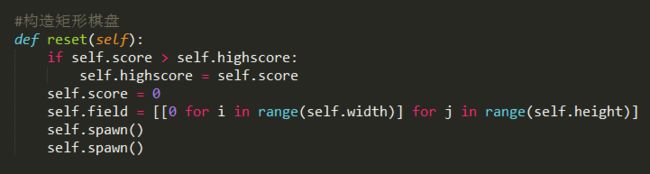
spawn函数为随机某个位置设置随机值。

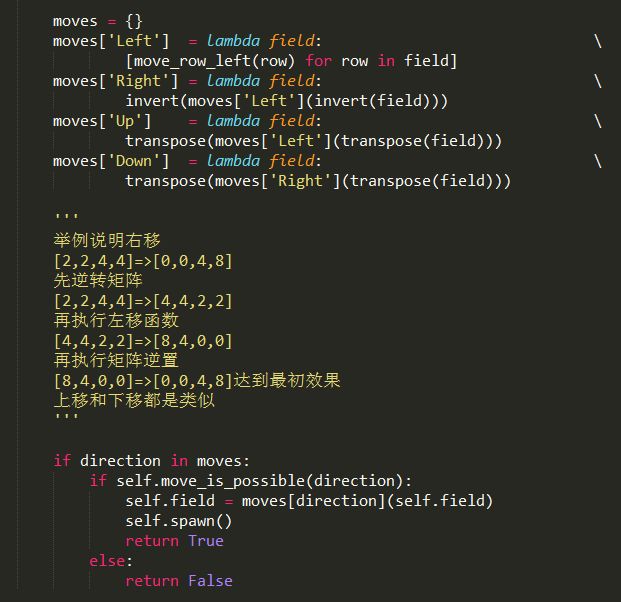
移动函数,这个函数比较复杂,代码也比较多。

move函数内部先定义了左移的函数move_row_left,move_row_left内部定义了tighten和merge函数。
tighten函数作用是先将一行中非0的元素移动到左边排列,剩余的0元素放在右边,可以理解为压缩。
如[0,2,2,4]经过tighten调用后就变为[2,2,4,0]。merge函数的功能是将相邻的相等的元素进行合并,
比如[2,2,8,0]经过merge后变为[0,4,8,0],[0,4,8,0]经过再次tighten调用后变为[4,8,0,0]
所以move_row_left内部实现的就是先对一个队列tighten,然后merge再次tighten达到左侧都是非0,右侧都是0。
move函数最后定义了一个dict,dict的key为方向,value为二维list。这个二维list是通过lambda表达式调用
左移函数以及矩阵逆置和转置等操作生成的。
举例说明右移:通过右移要达到的效果是[2,2,4,4]=>[0,0,4,8],为达到该目的,通过逆置矩阵,左移,再次逆置矩阵即可。
先逆转矩阵
[2,2,4,4]=>[4,4,2,2]
再执行左移函数
[4,4,2,2]=>[8,4,0,0]
再执行矩阵逆置
[8,4,0,0]=>[0,0,4,8]达到最初效果
上移和下移都是类似。
move函数最后通过判断传入direction是否符合标准,如果符合再次判断元素是否可以移动,如果可以移动则取出dict中方向key对应
的value,即二维list,从而得出移动后的棋盘界面。如果所有元素都不能移动,那么判断失败。
判断某个方向是否有元素可以移动,定义了如下函数。
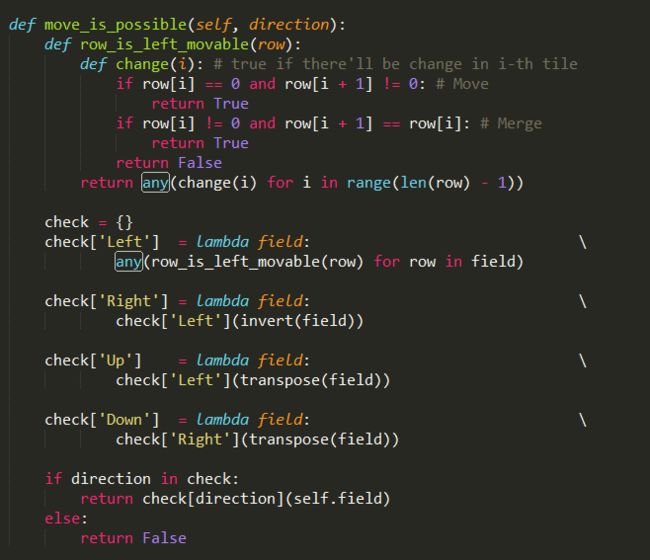
同样是先判断是否可以左移,其他方向能否移动可以通过左移操作和矩阵的转置,逆置判断。
row_is_left_movable是判断是否可以左移操作的函数,内部定义了change函数,
change函数的功能为判断有左右相邻元素可以合并,或者该行有含有0的元素,则返回true,表示该行可以左移。
反之为不可左移,返回false。any函数判断该行所有元素,如果都没有可移动的元素,返回false。
同样是通过check这个dict,结合逆转和转置判断其他方向是否可以移动。如果某个方向所有行都不能移动,
表示矩阵中所有元素不能按照该方向移动了。
下面是判断输赢的函数。
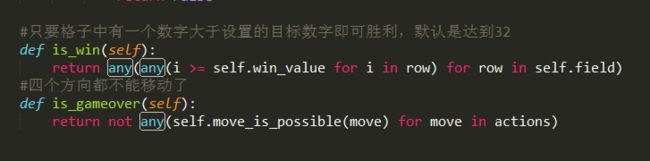
到此为止GameField类介绍完了,下面是main函数。
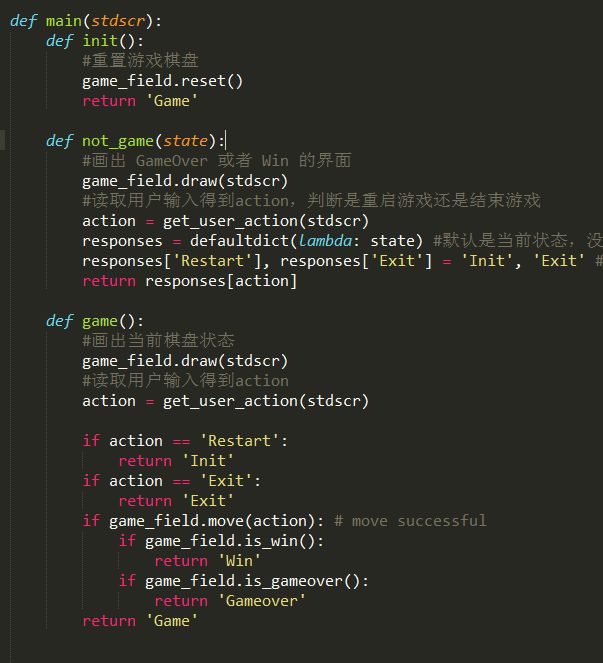
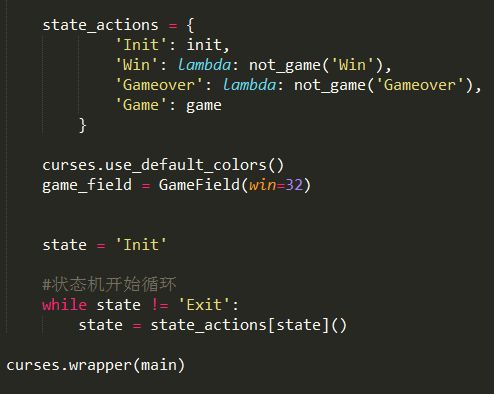
定义了几个状态,通过状态机的方式运行游戏。 curses.wrapper模块。这个函数做了一些初始化的工作,包括上面提到的和颜色的初始化。
然后再执行main函数,最后重置。
源码下载地址:
http://download.csdn.net/detail/secondtonone1/9852914
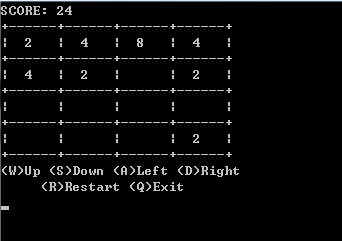
运行上述代码效果如下:
我的公众号,谢谢关注

这是后一篇制作2048游戏的准备,下一篇制作2048小游戏