Redis应用场景1——简单场景
1、计数器
redis incrBy就可以了
2、信号量
1)基本信号量
采用有序集合,进程将为每个尝试获取信号量的进程生成一个唯一标识符(identifier),并将这个标识符用户有序集合的成员,而成员对应的分值则是尝试获取信号量时的Unix时间戳。
进程在尝试获取信号量时,会先删除有序集合中所有时间戳大于超时数值的标识符。为当前进程生成一个标识符,并使用当前时间戳作为分值,将标识符添加到有序集合里。然后检查有序集合中该标识符的排名,如果排名低于可获取信号量总数,则获取到到信号量;如果小于可获取信号量总数,则获取信号量失败,需要将该标识符从有序集合中进行删除。
获取信号量
/**
* @param key sorted set key
* @param identifier 客服端获取信号量的标识符
* @param limit 可以获取信号量的总数
* @param timeout 信号量超时时间
*/
public boolean acquireSemaphore(String key, String identifier, int limit, int timeout) {
long now = System.currentTimeMillis();
Pipeline pipeline = jedis.pipelined();
//清理过期信号拥有者
pipeline.zremrangeByScore(key, Integer.MIN_VALUE, now - timeout);
//尝试获取信号量
pipeline.zadd(key, now, identifier);
pipeline.zrank(key, identifier);
Response> resp = pipeline.exec();
List 释放信号量
/**
* @param key sorted set key
* @param identifier 客服端获取到的信号量标识符
*/
public boolean releaseSemaphore(String key, String identifier) {
return jedis.zrem(key, identifier) > 0L;
}
2)公平信号量
当各个系统的系统时间并不完全相同的时候,基本信号量就会出现问题:系统时间较慢的系统上运行的客户端,将能够偷走系统时间较快的系统上已经取得的信号量,导致信号量变得不公平。我们需要减少不正确的系统时间对信号量获取操作带来的影响,使得只要各个系统的系统时间相差不超过1秒,就不会引起信号量被偷或者信号量提早过期。
为了尽可能的减少系统实际不一致带来的问题,方案通过 计数器 C、信号拥有者有序集合 S1、超时有序集合 S2 解决
实现:
(1) 程序首先通过从 S2有序集合里面移除过期元素的方式来移除超时的信号量
(2) 对 S2有序集合和 S1有序集合执行交集运算,并将计算结果保存到 S1有序集合里面,覆盖 S1 原有的数据
(3) 计数器C 自增生成值添加到 S1里面,程序还需要将当前的系统时间添加到 S2 里面
(4) 程序会检查当前客户端添加的标识符在 S1 集合中的排名是否足够低,如果是的话就表示客户端成功获取了信号量。否则,客户端未获取到信号量,程序需要从 S1 和 S2 中删除该客户端的标识符
获取信号量
/**
* @param s1 信号拥有者有序集合key s1
* @param s2 超时有序集合key s2
* @param counter 计数器
* @param identifier 客服端获取信号量的标识符
* @param limit 可以获取信号量的总数
* @param timeout 信号量超时时间
*/
public boolean acquireFairSemaphore(String s1, String s2, String counter, String identifier, int limit, int timeout){
long now = System.currentTimeMillis();
Pipeline pipeline = jedis.pipelined();
//删除超时的信号量
pipeline.zremrangeByScore(s2, Integer.MIN_VALUE, now - timeout);
pipeline.zinterstore(s1, s1, s2);
//对计数器进行自增操作,并获取计数器在执行自增操作之后的值
Response resp1 = pipeline.incr(counter);
long count = resp1.get();
//尝试获取信号量
pipeline.zadd(s2, now, identifier);
pipeline.zadd(s1, count, identifier);
//通过排名来判断客户端是否获取了信号量
pipeline.zrank(s1, identifier);
Response> resp = pipeline.exec();
if((Long)(resp.get().get(resp.get().size() - 1)) < limit){
return true;
}
//如果没有获取信号量成功,需要删除 超时有序集合 和 信号拥有者有序集合 中该客户段标识符
pipeline.zrem(s1, identifier);
pipeline.zrem(s2, identifier);
pipeline.exec();
return false;
} 释放信号量
/**
* @param s1 信号拥有者有序集合key s1
* @param s2 超时有序集合key s2
* @param identifier 客服端获取信号量的标识符
*/
public void releaseFairSemaphore(String s1, String s2, String identifier){
Pipeline pipeline = jedis.pipelined();
pipeline.zrem(s1, identifier);
pipeline.zrem(s2, identifier);
pipeline.exec();
}刷新信号量
/**
* @param s1 信号拥有者有序集合key s1
* @param s2 超时有序集合key s2
* @param identifier 客服端获取信号量的标识符
*/
public boolean refreshFairSemaphore(String s1, String s2, String identifier){
//zadd 如果identifier 不存在情况会返回1,否则update 返回0
if(jedis.zadd(s2, System.currentTimeMillis(), identifier) > 0L){
//告知调用者,客户端已经丢失该信号量
releaseFairSemaphore(s1, s2, identifier);
return false;
}
//客户端依然持有该信号量
return true;
}
3、最新列表
redis List数据结构的 LPUSH命令构建List,一个个顺序都塞进去就可以啦。不过万一内存清掉了咋办?也简单,查询不到存储key的话,用mysql查询并且初始化一个List到redis中就好了。
4、热搜榜、排名榜、热搜词等
例子:应用热搜榜
数据结构:sorted set
member设置为应用名称,score设置为搜索数,则
(1)排行榜前10名,通过 zrangeByScore 方法获取
(2)某个应用排行数,通过 zrank 方法获取
(3)某个应用搜索数,通过 zscore 方法获取
(4)增加某个应用搜索数 zincrby
5、当前网站登录用户数
通过位图可以简单实现网站在线数目,uid作为网站的位下标,则
(1)获取当前在线用户数,通过 bitcount 获取
6、统计页面UV
使用HyperLogLog,HyperLogLog相对set节省很多内容,它需要占据一定 12k 的存储空间,所以它不适合统计单个用户相关的数据。Redis 对 HyperLogLog 的存储进行了优化,在计数比较小时,它的存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。
但是存在一定的统计误判率,标准误差是 0.81%,但是已经可以满足大部分的UV统计需求
HyperLogLog 数据结构是 Redis 的高级数据结构,它非常有用,但是令人感到意外的是,使用过它的人非常少
(1)用户访问某个页面,pfadd 【页面表标识_yyyyMMdd】 【用户uid】
(2)获取某个页面某天uv,pfcount【页面表标识_yyyyMMdd】
如果在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。其中页面的 UV 访问量也需要合并,可以使用 pfmerge
7、布隆过滤器
布隆过滤器也存在误判,很简单,网上搜一下很多 redis 布隆过滤器文章
8、限流
1)简单限流
系统要限定用户的某个行为在指定的时间里只能允许发生 N 次,如何使用 Redis 的数据结构来实现这个限流的功能?
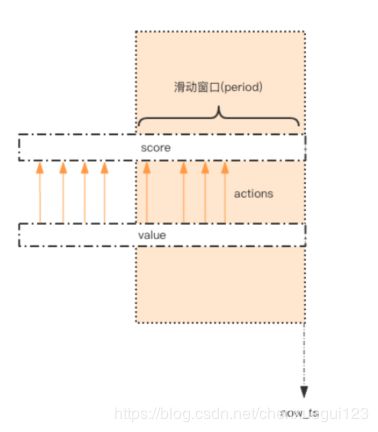
用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个key 保存下来。同一个用户同一种行为用一个 zset 记录。为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。通过统计滑动窗口内的行为数量与阈值 max_count 进行比较就可以得出当前的行为是否允许。
public boolean isActionAllowed(String userId, String actionKey, int period, int maxCount) {
String key = String.format("hist:%s:%s", userId, actionKey);
long nowTs = System.currentTimeMillis();
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.zadd(key, nowTs, "" + nowTs);
pipe.zremrangeByScore(key, 0, nowTs - period * 1000);
Response count = pipe.zcard(key);
pipe.expire(key, period + 1);
pipe.exec();
pipe.close();
return count.get() <= maxCount;
} 因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升Redis 存取效率。但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
2)漏斗限流
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。
9、附近的人
Redis 在 3.2 版本以后增加了地理位置 GEO 模块,意味着我们可以使用 Redis 来实现附近的人
业界比较通用的地理位置距离排序算法是 GeoHash 算法, Redis 也使用 GeoHash 算法。 GeoHash 算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将在挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离也会很接近。当我们想要计算「附近的人时」,首先将目标位置映射到这条线上,然后在这个一维的线上获取附近的点就行了。GeoHash 算法会继续对这个整数做一次 base32 编码 (0-9,a-z 去掉 a,i,l,o 四个字母) 变成一个字符串。在 Redis 里面,经纬度使用 52 位的整数进行编码,放进了 zset 里面, zset 的 value 是元素的 key, score 是 GeoHash 的 52 位整数值。 zset 的 score 虽然是浮点数,但是对于 52 位的整数值,它可以无损存储。
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。
添加位置信息:geoadd
计算两个元素之间的距离:geodist
获取集合中任意元素的经纬度坐标:geopos
获取元素的经纬度编码字符串:geohash
用来查询指定元素附近的其它元素:georadiusbymember
根据给定地理位置坐标获取指定范围内的地理位置集合:georadius