ZF-net
免责声明:本文仅代表个人观点,如有错误,请读者自己鉴别;如果本文不小心含有别人的原创内容,请联系我删除;本人心血制作,若转载请注明出处
摘要:
1、这篇文章的motivation 是 :CNN性能良好,但是我们不知道它为何性能良好,也不知道它怎么可以被提高?
2、本文介绍了一种新方法实现中间层和分类器的可视化
3、采用消融学习,来得到中间层的作用
4、我们的模型具有很好的泛化能力,当分类器重新训练时,在calteck-101和calteck-256等数据集上性能非常好。
引言:
1、CNN的性能举世瞩目,由下面几个原因导致上述结果:1> 大量有类标的数据集; 2)强有力的GPU计算,使训练复杂模型成为可能
3)更好的归一化策略,例如dropout
2、但是,我们还是不清楚复杂模型的内部操作,也不知道他们为何能取得这么好的效果,在一个科学立场,如果不知道模型的内部机制,那么模型的发 展就是实验和误差了
3、 本文使用反卷积的方式实现可视化,可以看到特征的演化,以及发现模型潜在的问题
4、为了得到场景的哪一部分对于分类很重要,我们将输入图像的不同部分遮住(堵塞),,(控制变量法)
方法:
1、使用监督模型,输入图像x,输出标签y(one-of-C 编码)
2、卷积、池化、修正线性单元、正则化以及softmax 分类器
3、损失函数:交叉熵, 求解方法:SGD
4、使用反卷积实现可视化:为了看到中间层的作用,我们提供了一种新方法将map 回溯到输入像素空间,反池化,修正线性单元, 反卷积
1) 反池化 ,池化过程不可逆,但是我们可以记下池化区域中最大值的位置,反池化时直接返还到相同位置
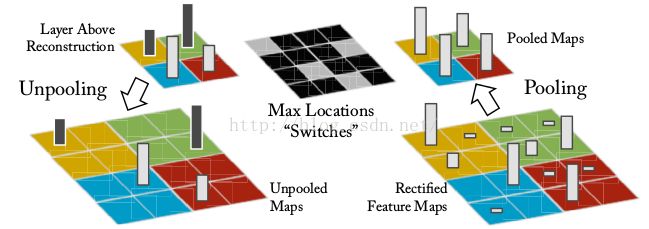
2)修正线性单元
不管是向前传,还是往回传,我们都需要特征map为正值,所以修正线性的逆变换还是自己
3) 反卷积
与BP的敏感项往回传类似,将卷积核转置然后与特征map卷积(卷积方式为“full”)
本文并没有使用正则方法,这种方法的缺点是只能看到一种激活函数的作用,而不能看到多种激活函数的综合作用

训练细节:
1、网络框架
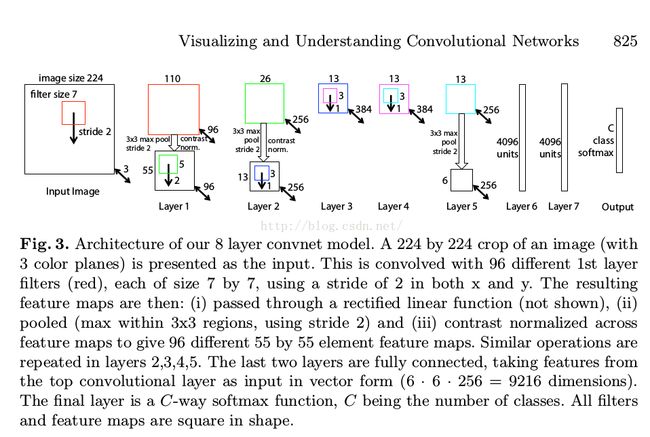
2、数据集:ImageNet2012训练集(1.3 million images,1000 类)
resize:256*256 -->标签保存转换(扩展10 倍)
batchsize:128 ,学习速率:0.01 动量:0.9 , 卷积核 :0.01 偏置 :0 ,dropout:0.5
优化方法:SGD
3、在第一层的可视化看到一些卷积核占据统治地位,所以重新正则化了卷积核,谁的RMS超过0.1,就重新正则化为0.1
RMS值实际就是有效值,就是一组统计数据的平方的平均值的平方根。 RMS=(X1平方+X2平方+......+Xn平方)/n 的1/2次方。
卷积可视化:
1、特征可视化

找到activation的前 9 名,分别回传到像素空间,证明不同的结构刺激map以及对应于输入改变的不变性,如上图的第 5 层,第 1 行 ,第 2 列,这些 patches看起来基本没有相似的地方,但是可视化证明主要是特征图主要是后景的草,而不是前景的目标。
这个回传也证明了网络特征的分层结构:第2层主要是边,角,和颜色组合,第 3层更负责的不变性,得到相似纹理特征,第 4 层得到显著的变化,更像事物的类别了,第 5 层显示全部的物体以更显著的位置变化
2、训练期间的特征演变,如下图所示
上图表示了最强activation的演变,一个指定的特征map回传到像素空间,结果图的突然跳跃发生在最强activation的起源(位置),前几层在经过较少代数后可以收敛,但是后几层需要较多代数才可以收敛,证明模型需要训练只到完全收敛
3、结构选取:因为之前的结构在实现第一层以及第三层可视化时,只要高频和低频部分,所以将滤波器的尺寸从 11*11 -->7*7,stride从4变为2,而且,这么改变也提高了准确率。
4、堵塞灵敏度 在图片分类时,模型到底是识别出目标在图像的位置,还是只是使用周围的纹理信息,我们将图像的不同部分分别堵塞,并监控分类器输出,以此来系统的回答这个问题,最终结果是模型确实是定位出目标在场景的位置。图6 显示了最高卷积层的最强特征图,除了这个特征图的激活值(空间位置的总结)作为一个阻塞位置的方程。当阻塞位置在图像位置的可视化区域时,我们看到了特征图的激活值的显著下降。这个明显那说明了图像结构明显激活了特征map。
实验:
1、
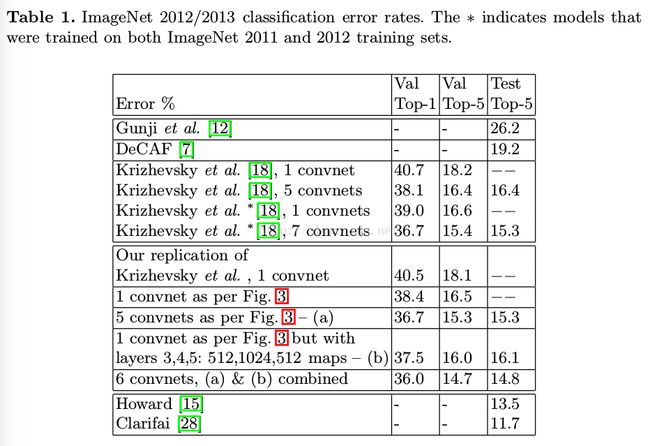
2、保持模型的深度很重要。随意拿掉一层都会让准确率下降

4、特征分析

总结:
1、本问题出了一种新的可视化方法
2、使用可视化方法发现模型问题,并得到更好结果
3、网络的深度对模型非常重要
4、用ImageNet训练模型,泛化到Calteck256等数据集上,验证模型的繁华能力
5、如果能找到更好的lossfunction即允许一个图片多个目标,效果可能会更好