编译原理第六、七章总结
第六章属性文法和语法制导翻译
属性文法是在上下文无关文法的基础上为每个文法符号(终结符或非终结符)配备若干个相关的“值”(称为属性)。
属性代表与文法符号相关的信息,和变量一样,可以进行计算和传递。(例:类型、值、代码序列、符号表内容等)属性通常分为两类:综合属性(自下而上传递信息)和继承属性(自上而下传递信息)。注意,终结符只有综合属性,非终结符既有综合也有继承。
语义规则:属性计算的过程即是语义处理的过程,对于文法的每一个产生式配备一组属性的计算规则,则称为语义规则。包括属性计算、静态语义检查、符号操作、代码生成等。
考虑非终结符A,B和C,其中,A有一个继承属性a和一个综合属性e,B有综合属性b,C有继承属性c。
产生式 A → BC 应该有计算c和e的规则
C.c := B.b + 1
A.e := A.a + B.b
其中属性A.a和B.b在其他地方计算。
从概念上讲,基于属性文法的处理过程通常如下:
输入串®语法树®依赖图®语义规则计算次序®计算结果
这种由源程序的语法结构所驱动的处理办法就是语法制导翻译法。
在一棵语法树中的节点的继承属性和综合属性之间的相互依赖关系可以由称作依赖图的有向图来表示。注:b依赖于c表示为 c→b。
良义文法是指属性文法不存在属性之间的循环依赖关系。
假设语法树已经建立起了,并且树中已带有开始符号的继承属性和终结符的综合属性。然后以某种次序遍历语法树,直至计算出所有的属性。最常用的遍历方法是深度优先,从左到右的遍历方法,如果需要,可使用多次遍历。
与树遍历的属性计算方法不同,一遍扫描的处理方法是在语法分析的同时计算属性值,而不是语法分析构造语法树之后进行属性的计算,而且无需构造实际的语法树。
从语法树中去掉对翻译不必要的信息,而获得更有效的源程序中间表示。这种经变换后的语法树称之为抽象语法树。在抽象语法树中,操作符和关键字都不作为叶结点出现,而是把它们作为内部结点,即这些叶结点的父结点。
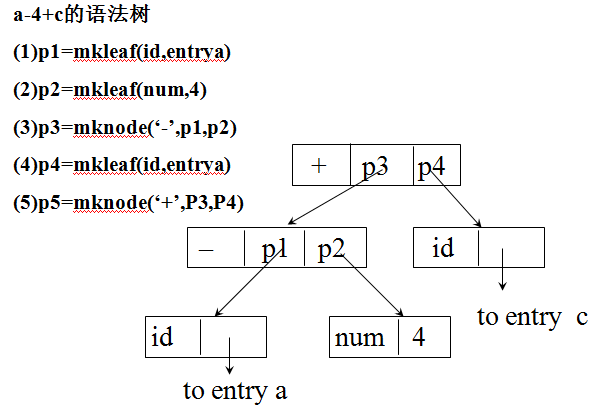
建立表达式的语法树使用的函数
1. mknode(op,left,right)
建立一个运算符号结点,标号是op,两个域left和right指向运算分量结点的指针。
2. mkleaf(id,entry)
建立一个标识符结点,由标号id标识,一个域entry指向标识符符号表中相应的项。
3. mkleaf(num,val)
建立一个数结点,标号为num ,域val用于存放数的值.返回新建立结点的指针。
例:
S属性文法只含有综合属性。
L属性文法的定义
如果每个产生式A ®X1 X2 …Xn 的每条语义规则计算的属性是A的综合属性;或者是Xj 的继承属性,1 £ j £ n, 但它仅依赖:
该产生式中Xj左边符号X1, X2,…, Xj-1的属性;
A的继承属性
S属性文法包含于L属性文法
翻译模式是语法制导定义的一种便于翻译的书写形式。其中属性与文法符号相对应,语义规则或语义动作用花括号{}括起来,可被插入到产生式右部的任何合适的位置上。
这是一种语法分析和语义动作交错的表示法,他表达在按深度优先遍历分析树的过程中何时执行语义动作。翻译模式给出了使用语义规则进行计算的顺序。可看成是分析过程中翻译的注释。
用翻译模式构造自顶向下翻译。
1.从翻译模式中消除左递归
2.关于左递归翻译模式更一般化的讨论
第七章语义分析和中间代码产生
“中间代码生成”程序的任务是把经过语法分析和语义分析而获得的源程序中间表示翻译为中间代码表示。方法:语法制导翻译。
语义分析的任务是:
1.审查每一个语法结构的静态语义,即验证语法正确的结构是否有意义。
如:赋值语句:x:=x+y,左边变量类型与右边变量类型是否一致。
2.在语义正确的基础上生成一种中间代码或目标代码。
语义分析的范围是:
1.确定类型:确定标识符所关联的数据类型。
2.类型检查:按语言的类型规则,检查运算的合法性与运算分量类型的一致性,必要时作类型转换。
3.识别含义:根据语言的语义定义(形式或非形式),识别程序中各构造成分组合到一起的含义,并作相应的语义处理(生成中间代码或目标代码)。
4.控制流检查:控制流语句必须转移到合法的地方。如C中,break语句规定跳出最内层的循环或switch语句。
5.一致性检查:在很多场合要求对象只能被说明一次。如:pascal语言规定同一个标识符在一个分程序中只能被说明一次等。
6.相关名字检查:如:Ada,循环或块可以有一个名字,它出现在这些结构的开头或结尾。编译程序必须检查这两个地方用的名字是否相同。
7.其它:如名字的作用域分析等也是语义分析的工作。
中间语言的表示形式:后缀式,三地址代码(包括三元式、四元式、简洁三元式),DAG图表示。
后缀式表示法,即逆波兰表示法。图表示法包括DAG与抽象语法树。三地址代码可以看成是DAG或抽象语法树的一种线性表示。
三地址语句的种类:
(1)赋值语句 x:=y op z,op为二目算术算符或逻辑算符;
(2)赋值语句 x:=op y ,op为一目算符,如一目减uminus、逻辑非not、移位算符及转换算符;
(3)无条件转移语句gotoL;
(4)条件转移语句 if xrelop y goto L,关系运算符号relop(< ,=,>= 等等);
(5)复制语句 x:=y;
(6)过程调用语句 paramx 和 call p, n ;
过程返回语句 returny;
(7)索引赋值 x:=y[i]及 x[i] :=y ;
(8)地址和指针赋值 x=&y,x=* y
和 * x=y。
三地址代码的具体实现:
1.四元式 op, arg1, arg2, result
2.三元式 op,arg1, arg2
3.间接三元式 间接码表+三元式表

数组地址计算(常量部分+变量部分):
一维数组计算:bace-low*w+ i*w
多维数组计算:
常量部分: c=((...((low1*n2+low2)*n3+low3)...)*nk+lowk) * w
变量部分:v=((...((i1*n2+i2)*n3+i3...)*nk+ik)*w
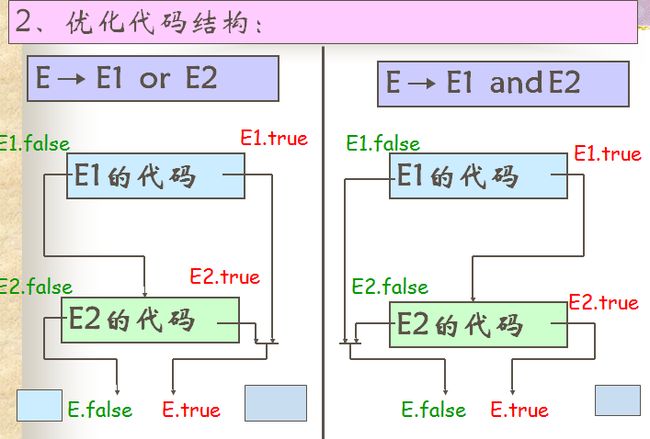
布尔表达式: 用布尔运算符号(and,or,not)作用到布尔变量或关系表达式上而组成
布尔表达式的作用:
1.用作计算逻辑值
2.用作控制流语句如if-then,if-then-else和while-do等之中的条件表达式

用四元式实现三地址码,真假出口可表示为:
真出口:
(jnz,a,_,P)表示 if a goto P
(jrop,x,y,P)表示 if x rop y goto P
假出口:
(j,_,_,P)表示 goto P
本章总结:第六章介绍了属性文法和语法制导翻译,第七章介绍了相应的方法和技术应用与语义分析和中间代码产生。通过昨天的考试,我大体知道了老师想考察的重点,考试之前就有了一定的掌握,考试之后回来回顾,觉得更加娴熟了。不过还有一些方面掌握的不好,还需要多回顾。