【机器学习实战】决策树预测Titanic遇难者生还情况
一、导入数据
#导入pandas用于数据分析
import pandas as pd
#利用pandas的read_csv模块直接从互联网手机泰坦尼克号乘客数据
titanic = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt')
#观察前几行数据
titanic.head()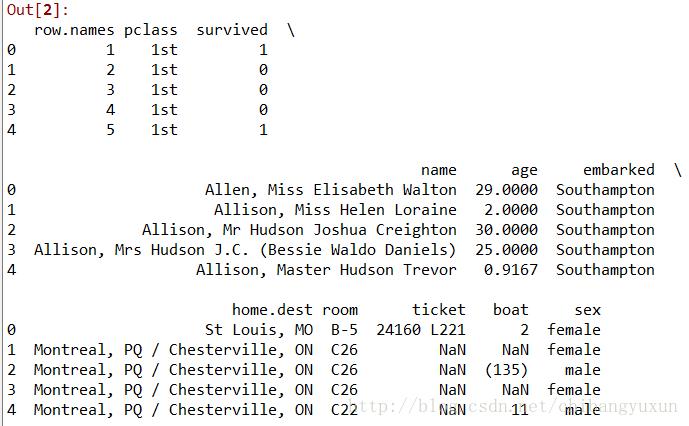
二、分析数据
#查看数据统计特性
titanic.info()RangeIndex: 1313 entries, 0 to 1312
Data columns (total 11 columns):
row.names 1313 non-null int64
pclass 1313 non-null object
survived 1313 non-null int64
name 1313 non-null object
age 633 non-null float64
embarked 821 non-null object
home.dest 754 non-null object
room 77 non-null object
ticket 69 non-null object
boat 347 non-null object
sex 1313 non-null object
dtypes: float64(1), int64(2), object(8)
memory usage: 112.9+ KB#特征选择,sex,age,pclass这些特征很有可能是决定幸免与否的关键因素
X=titanic[['pclass','age','sex']]
y=titanic['survived']#对当前选择的特征进行探查
X.info()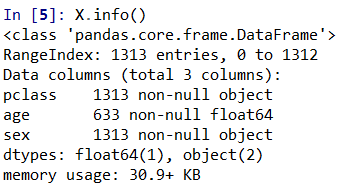
1)可以发现,age这个数据列只有633个
2)pclass与sex都是类别类型的,需要转化为数值类型
#填充age缺失值,使用平均数或中位数
X['age'].fillna(X['age'].mean(),inplace=True)
#查看数据特征
X.info()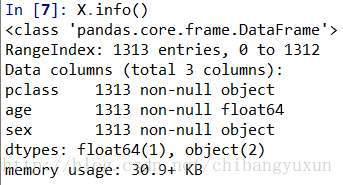
三、数据拆分及转换
#数据分割,拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)
#特征转换
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False)
X_train = vec.fit_transform(X_train.to_dict(orient='record'))
print(vec.feature_names_)
#对预测数据进行同样的特征转换
X_test = vec.transform(X_test.to_dict(orient='record'))四、模型训练及评估
#导入决策树模型并对测试特征数据进行预测
from sklearn.tree import DecisionTreeClassifier
#使用默认配置初始化决策树分类器
dtc = DecisionTreeClassifier()
#训练数据进行模型学习
dtc.fit(X_train,y_train)
#决策树模型对特征数据进行预测
y_predict=dtc.predict(X_test)#模型评估
from sklearn.metrics import classification_report
#输出预测准确性
print(dtc.score(X_test,y_test))
#输出更加详细的分类性能
print(classification_report(y_predict,y_test,target_names=['died','survived']))
#使用随机森林分类器进行集成模型的训练以及预测分析
from sklearn.ensemble import RandomForestClassifier
rfc=RandomForestClassifier()
rfc.fit(X_train,y_train)
rfc_y_pred=rfc.predict(X_test)
#输出随机森林分类器在测试集上的分类准确性性
print(rfc.score(X_test,y_test))
print(classification_report(rfc_y_pred,y_test))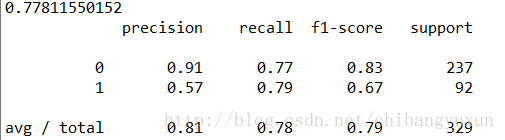
#使用梯度提升决策树进行集成O型的训练及预测分析
from sklearn.ensemble import GradientBoostingClassifier
gbc=GradientBoostingClassifier()
gbc.fit(X_train,y_train)
gbc_y_pred=gbc.predict(X_test)
#输出梯度提升树在测试集上的分类准确性
print(gbc.score(X_test,y_test))
print(classification_report(gbc_y_pred,y_test))
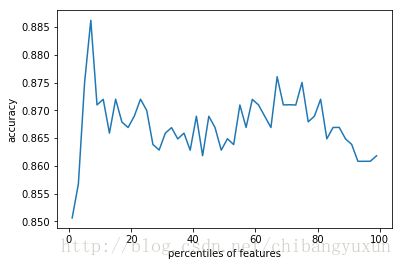
五、查看不同特征选择对模型性能的影响
#方案二:分离数据特征与预测目标
X=titanic.drop(['row.names','name','survived'],axis=1)
#填充age缺失值,使用平均数或中位数
X['age'].fillna(X['age'].mean(),inplace=True)
#查看数据特征
X.info()
#填充缺失值
X.fillna('UNKNOWN',inplace=True)#数据分割,拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=33)#通过交叉验证方法,按照固定间隔的百分比筛选特征,并作图展示性能随特征筛选比例的变化
from sklearn.cross_validation import cross_val_score
import numpy as np
percentiles=range(1,100,2)
results=[]
for i in percentiles:
fs = feature_selection.SelectPercentile(feature_selection.chi2,percentile=i)
X_train_fs=fs.fit_transform(X_train,y_train)
scores=cross_val_score(dtc,X_train_fs,y_train,cv=5)
results=np.append(results,scores.mean())
print(results)#绘制特征选择评估结果
import pylab as pl
pl.plot(percentiles,results)
pl.xlabel('percentiles of features')
pl.ylabel('accuracy')
pl.show()