Cloudera提供了一个可扩展的,灵活的集成平台,可以轻松管理企业中快速增长的数据量和各种数据。 Cloudera产品和解决方案使您能够部署和管理Apache Hadoop和相关项目,操纵和分析数据,并保持数据的安全和受保护。
先决条件
Ubuntu或Debian.x主机一台
Target
部署CDH伪分布式Hadoop集群应用
部署好的版本
[root@localhost ~]# hadoop version
Hadoop 2.6.0-cdh5.13.1
Subversion http://github.com/cloudera/hadoop -r 0061e3eb8ab164e415630bca11d299a7c2ec74fd
Compiled by jenkins on 2017-11-09T16:34Z
Compiled with protoc 2.5.0
From source with checksum 16d5272b34af2d8a4b4b7ee8f7c4cbe
This command was run using /usr/lib/hadoop/hadoop-common-2.6.0-cdh5.13.1.jar
偶然间查到了cdh官网的伪分布式安装教程
这里做下笔记和记录.
开始部署
(笔者以Ubuntu14.04 trusty版本为例)
1.JAVA环境
$ wget -O jdk-8u161-linux-x64.tar.gz http://download.oracle.com/otn-pub/java/jdk/8u161-b12/2f38c3b165be4555a1fa6e98c45e0808/jdk-8u161-linux-x64.tar.gz?AuthParam=1516468871_b215348d2df9e7db8a6827383239383e
$ mkdir -p /usr/lib/jvm
$ tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/lib/jvm/
Set the Java_Home
$ vim /etc/environment
JAVA_HOME="/usr/lib/jvm/jdk1.8.0_161"
#保存退出
$ source /etc/environment
$ update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_161/bin/java 1
$ update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/jdk1.8.0_161/bin/javac 1
$ update-alternatives --install /usr/bin/jps jps /usr/lib/jvm/jdk1.8.0_161/bin/jps 1
2.Download the CDH 5 Package
| OS Version | Click this Link |
|---|---|
| Wheezy | Wheezy link |
| Precise | Precise link |
| Trusty | Trusty link |
笔者此时系统为Ubuntu14.04故选择Trusty Linux下载
$ wget http://archive.cloudera.com/cdh5/one-click-install/trusty/amd64/cdh5-repository_1.0_all.deb
$ dpkg -i cdh5-repository_1.0_all.deb
For instructions on how to add a CDH 5 Debian repository or build your own CDH 5 Debian repository, see https://www.cloudera.com/documentation/enterprise/5-4-x/topics/cdh_ig_cdh5_install.html#topic_4_4_1__section_dfx_p51_nj
3.Install CDH 5
$ curl -s http://archive.cloudera.com/cdh5/ubuntu/trusty/amd64/cdh/archive.key | sudo apt-key add -
$ sudo apt-get update -y
$ sudo apt-get install hadoop-conf-pseudo -y
4.Starting Hadoop
查看安装好的文件默认存放位置
[root@localhost ~]# dpkg -L hadoop-conf-pseudo
/etc/hadoop/conf.pseudo
/etc/hadoop/conf.pseudo/README
/etc/hadoop/conf.pseudo/core-site.xml
/etc/hadoop/conf.pseudo/hadoop-env.sh
/etc/hadoop/conf.pseudo/hadoop-metrics.properties
/etc/hadoop/conf.pseudo/hdfs-site.xml
/etc/hadoop/conf.pseudo/log4j.properties
/etc/hadoop/conf.pseudo/mapred-site.xml
/etc/hadoop/conf.pseudo/yarn-site.xml
设置下hadoop-env.sh文件的JAVA_HOME (这是个小bug必须显示设置)
$ vim /etc/hadoop/conf.pseudo/hadoop-env.sh
#Set the JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_161
#保存退出
$ source /etc/hadoop/conf.pseudo/hadoop-env.sh
无需改动,开始部署
Step 1.格式化namenode sudo -u hdfs hdfs namenode -format
[root@localhost ~]# sudo -u hdfs hdfs namenode -format
18/01/21 00:13:39 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = root
..........................................
18/01/21 00:13:41 INFO common.Storage: Storage directory /var/lib/hadoop-hdfs/cache/root/dfs/name has been successfully formatted.
...........................................
18/01/21 00:13:41 INFO util.ExitUtil: Exiting with status 0
18/01/21 00:13:41 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/127.0.0.1
************************************************************/
Step 2: 启动HDFS集群
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
[root@localhost ~]# for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done
starting datanode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-datanode-localhost.out
Started Hadoop datanode (hadoop-hdfs-datanode): [ OK ]
starting namenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-namenode-localhost.out
Started Hadoop namenode: [ OK ]
starting secondarynamenode, logging to /var/log/hadoop-hdfs/hadoop-hdfs-secondarynamenode-localhost.out
Started Hadoop secondarynamenode: [ OK ]
#为了确认服务是否以及启动,可以使用jps命令或者查看webUI:http://localhost:50070
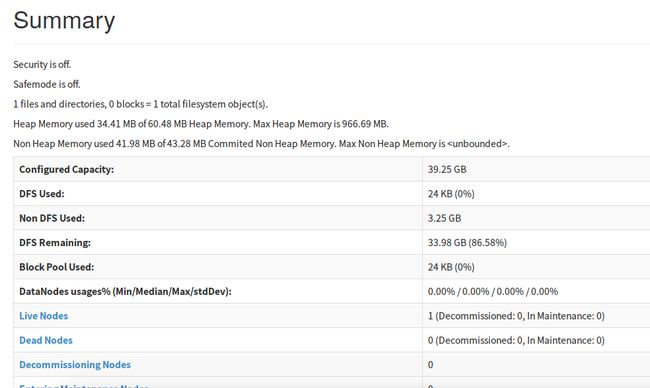
Step 3: Create the directories needed for Hadoop processes.
建立Hadoop进程所需的相关目录
/usr/lib/hadoop/libexec/init-hdfs.sh
[root@localhost ~]# /usr/lib/hadoop/libexec/init-hdfs.sh
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /tmp'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chmod -R 1777 /tmp'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /var'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /var/log'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chmod -R 1775 /var/log'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chown yarn:mapred /var/log'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /tmp/hadoop-yarn'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn'
....................................
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /user/oozie/share/lib/sqoop'
+ ls '/usr/lib/hive/lib/*.jar'
+ ls /usr/lib/hadoop-mapreduce/hadoop-streaming-2.6.0-cdh5.13.1.jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -put /usr/lib/hadoop-mapreduce/hadoop-streaming*.jar /user/oozie/share/lib/mapreduce-streaming'
+ ls /usr/lib/hadoop-mapreduce/hadoop-distcp-2.6.0-cdh5.13.1.jar /usr/lib/hadoop-mapreduce/hadoop-distcp.jar
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -put /usr/lib/hadoop-mapreduce/hadoop-distcp*.jar /user/oozie/share/lib/distcp'
+ ls '/usr/lib/pig/lib/*.jar' '/usr/lib/pig/*.jar'
+ ls '/usr/lib/sqoop/lib/*.jar' '/usr/lib/sqoop/*.jar'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chmod -R 777 /user/oozie'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chown -R oozie /user/oozie'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /var/lib/hadoop-hdfs/cache/mapred/mapred/staging'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chmod 1777 /var/lib/hadoop-hdfs/cache/mapred/mapred/staging'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chown -R mapred /var/lib/hadoop-hdfs/cache/mapred'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -mkdir -p /user/spark/applicationHistory'
+ su -s /bin/bash hdfs -c '/usr/bin/hadoop fs -chown spark /user/spark/applicationHistory'
Step 4: Verify the HDFS File Structure:
确认HDFS的目录结构hadoop fs -ls -R /
[root@localhost ~]# sudo -u hdfs hadoop fs -ls -R /
drwxrwxrwx - hdfs supergroup 0 2018-01-20 16:42 /benchmarks
drwxr-xr-x - hbase supergroup 0 2018-01-20 16:42 /hbase
drwxrwxrwt - hdfs supergroup 0 2018-01-20 16:41 /tmp
drwxrwxrwt - mapred mapred 0 2018-01-20 16:42 /tmp/hadoop-yarn
drwxrwxrwt - mapred mapred 0 2018-01-20 16:42 /tmp/hadoop-yarn/staging
drwxrwxrwt - mapred mapred 0 2018-01-20 16:42 /tmp/hadoop-yarn/staging/history
drwxrwxrwt - mapred mapred 0 2018-01-20 16:42 /tmp/hadoop-yarn/staging/history/done_intermediate
drwxr-xr-x - hdfs supergroup 0 2018-01-20 16:44 /user
drwxr-xr-x - mapred supergroup 0 2018-01-20 16:42 /user/history
drwxrwxrwx - hive supergroup 0 2018-01-20 16:42 /user/hive
drwxrwxrwx - hue supergroup 0 2018-01-20 16:43 /user/hue
drwxrwxrwx - jenkins supergroup 0 2018-01-20 16:42 /user/jenkins
drwxrwxrwx - oozie supergroup 0 2018-01-20 16:43 /user/oozie
................
Step 5: Start YARN
启动Yarn管理器
service hadoop-yarn-resourcemanager startservice hadoop-yarn-nodemanager startservice hadoop-mapreduce-historyserver start
[root@localhost ~]# service hadoop-yarn-resourcemanager start
starting resourcemanager, logging to /var/log/hadoop-yarn/yarn-yarn-resourcemanager-localhost.out
Started Hadoop resourcemanager: [ OK ]
[root@localhost ~]# service hadoop-yarn-nodemanager start
starting nodemanager, logging to /var/log/hadoop-yarn/yarn-yarn-nodemanager-localhost.out
Started Hadoop nodemanager: [ OK ]
[root@localhost ~]# service hadoop-mapreduce-historyserver start
starting historyserver, logging to /var/log/hadoop-mapreduce/mapred-mapred-historyserver-localhost.out
STARTUP_MSG: java = 1.8.0_161
Started Hadoop historyserver: [ OK ]
通过jps查看相关服务是否启动.
[root@localhost ~]# jps
5232 ResourceManager
3425 SecondaryNameNode
5906 Jps
5827 JobHistoryServer
3286 NameNode
5574 NodeManager
3162 DataNode
Step 6: 创建用户目录
[root@localhost ~]# sudo -u hdfs hadoop fs -mkdir /taroballs/
[root@localhost ~]# hadoop fs -ls /
Found 6 items
drwxrwxrwx - hdfs supergroup 0 2018-01-20 16:42 /benchmarks
drwxr-xr-x - hbase supergroup 0 2018-01-20 16:42 /hbase
drwxr-xr-x - hdfs supergroup 0 2018-01-20 16:48 /taroballs
drwxrwxrwt - hdfs supergroup 0 2018-01-20 16:41 /tmp
drwxr-xr-x - hdfs supergroup 0 2018-01-20 16:44 /user
drwxr-xr-x - hdfs supergroup 0 2018-01-20 16:44 /var
在Yarn上运行一个简单的例子
#首先在root用户下建立个Input文件夹
[root@localhost ~]# hadoop fs -mkdir input
[root@localhost ~]# hadoop fs -ls /user/root/
Found 1 items
drwxr-xr-x - root supergroup 0 2018-01-20 17:51 /user/root/input
#然后put一些东西上去
[root@localhost ~]# hadoop fs -put /etc/hadoop/conf/*.xml input/
[root@localhost ~]# hadoop fs -ls input/
Found 4 items
-rw-r--r-- 1 root supergroup 2133 2018-01-20 17:54 input/core-site.xml
-rw-r--r-- 1 root supergroup 2324 2018-01-20 17:54 input/hdfs-site.xml
-rw-r--r-- 1 root supergroup 1549 2018-01-20 17:54 input/mapred-site.xml
-rw-r--r-- 1 root supergroup 2375 2018-01-20 17:54 input/yarn-site.xml
Set HADOOP_MAPRED_HOME
#Set HADOOP_MAPRED_HOME
[root@localhost ~]# vim /etc/hadoop/conf.pseudo/hadoop-env.sh
#Add the HADOOP_MAPRED_HOME
export HADOOP_MAPRED_HOME=/usr/lib/hadoop-mapreduce
#保存退出
[root@localhost ~]# source /etc/hadoop/conf.pseudo/hadoop-env.sh
运行Hadoop MR实例
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input outputroot23 'dfs[a-z.]+'
#运行Hadoop simple
root@localhost:~# hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar grep input outputroot23 'dfs[a-z.]+'
18/01/21 03:12:39 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/01/21 03:12:40 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
18/01/21 03:12:40 INFO input.FileInputFormat: Total input paths to process : 4
18/01/21 03:12:40 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:967)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.endBlock(DFSOutputStream.java:705)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:894)
18/01/21 03:12:40 INFO mapreduce.JobSubmitter: number of splits:4
18/01/21 03:12:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1516474398700_0001
18/01/21 03:12:41 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
18/01/21 03:12:41 INFO impl.YarnClientImpl: Submitted application application_1516474398700_0001
18/01/21 03:12:41 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1516474398700_0001/
18/01/21 03:12:41 INFO mapreduce.Job: Running job: job_1516474398700_0001
18/01/21 03:12:54 INFO mapreduce.Job: Job job_1516474398700_0001 running in uber mode : false
18/01/21 03:12:54 INFO mapreduce.Job: map 0% reduce 0%
18/01/21 03:13:12 INFO mapreduce.Job: map 25% reduce 0%
18/01/21 03:13:13 INFO mapreduce.Job: map 50% reduce 0%
18/01/21 03:13:15 INFO mapreduce.Job: map 75% reduce 0%
18/01/21 03:13:16 INFO mapreduce.Job: map 100% reduce 0%
18/01/21 03:13:20 INFO mapreduce.Job: map 100% reduce 100%
18/01/21 03:13:21 INFO mapreduce.Job: Job job_1516474398700_0001 completed successfully
18/01/21 03:13:21 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=330
FILE: Number of bytes written=720333
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=8847
HDFS: Number of bytes written=470
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=4
Launched reduce tasks=1
Data-local map tasks=4
Total time spent by all maps in occupied slots (ms)=68685
Total time spent by all reduces in occupied slots (ms)=6005
Total time spent by all map tasks (ms)=68685
Total time spent by all reduce tasks (ms)=6005
Total vcore-milliseconds taken by all map tasks=68685
Total vcore-milliseconds taken by all reduce tasks=6005
Total megabyte-milliseconds taken by all map tasks=70333440
Total megabyte-milliseconds taken by all reduce tasks=6149120
Map-Reduce Framework
Map input records=261
Map output records=10
Map output bytes=304
Map output materialized bytes=348
Input split bytes=466
Combine input records=10
Combine output records=10
Reduce input groups=10
Reduce shuffle bytes=348
Reduce input records=10
Reduce output records=10
Spilled Records=20
Shuffled Maps =4
Failed Shuffles=0
Merged Map outputs=4
GC time elapsed (ms)=1690
CPU time spent (ms)=2760
Physical memory (bytes) snapshot=999096320
Virtual memory (bytes) snapshot=12652204032
Total committed heap usage (bytes)=582303744
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=8381
File Output Format Counters
Bytes Written=470
18/01/21 03:13:22 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
18/01/21 03:13:22 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
18/01/21 03:13:22 INFO input.FileInputFormat: Total input paths to process : 1
18/01/21 03:13:22 INFO mapreduce.JobSubmitter: number of splits:1
18/01/21 03:13:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1516474398700_0002
18/01/21 03:13:22 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
18/01/21 03:13:22 INFO impl.YarnClientImpl: Submitted application application_1516474398700_0002
18/01/21 03:13:22 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1516474398700_0002/
18/01/21 03:13:22 INFO mapreduce.Job: Running job: job_1516474398700_0002
18/01/21 03:13:31 INFO mapreduce.Job: Job job_1516474398700_0002 running in uber mode : false
18/01/21 03:13:31 INFO mapreduce.Job: map 0% reduce 0%
18/01/21 03:13:39 INFO mapreduce.Job: map 100% reduce 0%
18/01/21 03:13:47 INFO mapreduce.Job: map 100% reduce 100%
18/01/21 03:13:47 INFO mapreduce.Job: Job job_1516474398700_0002 completed successfully
18/01/21 03:13:47 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=330
FILE: Number of bytes written=287359
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=600
HDFS: Number of bytes written=244
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=4323
Total time spent by all reduces in occupied slots (ms)=4566
Total time spent by all map tasks (ms)=4323
Total time spent by all reduce tasks (ms)=4566
Total vcore-milliseconds taken by all map tasks=4323
Total vcore-milliseconds taken by all reduce tasks=4566
Total megabyte-milliseconds taken by all map tasks=4426752
Total megabyte-milliseconds taken by all reduce tasks=4675584
Map-Reduce Framework
Map input records=10
Map output records=10
Map output bytes=304
Map output materialized bytes=330
Input split bytes=130
Combine input records=0
Combine output records=0
Reduce input groups=1
Reduce shuffle bytes=330
Reduce input records=10
Reduce output records=10
Spilled Records=20
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=194
CPU time spent (ms)=1270
Physical memory (bytes) snapshot=339116032
Virtual memory (bytes) snapshot=5066223616
Total committed heap usage (bytes)=170004480
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=470
File Output Format Counters
Bytes Written=244
root@localhost:~# hadoop fs -ls outputroot23/
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-01-21 03:13 outputroot23/_SUCCESS
-rw-r--r-- 1 root supergroup 244 2018-01-21 03:13 outputroot23/part-r-00000
root@localhost:~# hadoop fs -cat outputroot23/part-r-00000
1 dfs.safemode.min.datanodes
1 dfs.safemode.extension
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.namenode.checkpoint.dir
1 dfs.domain.socket.path
1 dfs.datanode.hdfs
1 dfs.datanode.data.dir
1 dfs.client.read.shortcircuit
1 dfs.client.file
大功告成~CDH伪分布式Hadoop集群搭建成功~这一篇的java环境变量问题可把我搞懵了,bug一直解决了好几个钟头才把hadoop环境变量和java环境变量设置好,不提了~
对了,如文章有勘误,欢迎斧正~