Cut, Paste and Learn方法解读
Abstract
问题背景:
- 标注数据的缺乏:在实例检测任务中,部署物体检测模型的一个主要障碍是缺乏大量标注数据。例如,在一个特定的厨房环境中找到包含实例的大型标注数据集是不太可能的。每当面对新的环境和新的物体实例时,都需要进行昂贵的数据收集和标注工作。
研究贡献:
- 解决方法:本文提出了一种简单的方法,可以以最小的努力生成大量标注的实例数据集。
- 关键洞察:研究者的关键洞察是,仅仅确保“局部真实感”(patch-level realism)就能为当前的物体检测模型提供足够的训练信号。
- 方法概述:他们通过自动“剪切”物体实例并将其“粘贴”到随机背景上来生成数据集。
挑战与解决:
- 初步方法的不足:这种直接“剪切-粘贴”的方法会产生像素伪影,这些伪影会导致训练的模型表现不佳。
- 解决方案:研究者展示了如何在训练过程中使检测器忽略这些伪影,并生成能够在真实数据上表现优异的训练数据。
实验结果:
- 性能表现:与现有的合成数据生成方法相比,该方法表现更优。当将该方法生成的合成数据与真实图像结合使用时,在基准数据集上的相对性能提升超过21%。
- 跨领域应用:在跨领域设置中,该方法生成的合成数据仅与10%的真实数据结合使用时,其表现优于仅使用全部真实数据进行训练的模型。

1. Introduction
背景: 想象一下在厨房环境中使用一个物体检测系统。这个系统不仅需要识别不同类型的物体,还需要区分同一类物体的不同实例,例如“你的杯子”和“我的杯子”。尽管在视觉识别方面取得了巨大进展,并在基准检测数据集上有详细的记录,人们可能会期待能够轻松部署一个最先进的系统来满足这一需求。然而,使用最先进的检测系统的最大缺点之一是训练所需的大量标注。对于一个新环境中的新物体,我们可能需要收集数千张具有多样背景和视角的图像,并标注它们的边界框。传统上,视觉研究人员已为一些常见类别(如“人”、“牛”、“羊”等)承担了这一艰巨任务,但这种方法不太可能扩展到所有可能的类别,特别是像厨房中的具体实例。在个性化设置中,我们需要为实例(如“你的杯子”)收集标注。我们认为,收集这些标注是快速部署检测系统在机器人或其他个性化应用中的主要障碍。
替代方案: 最近,一种成功的研究方向是利用合成渲染场景和物体来训练检测系统。这种方法需要付出很多努力来使场景和物体变得逼真,以确保高质量的全局和局部一致性。此外,基于这种合成数据训练的模型由于图像统计的变化,往往难以泛化到真实数据。为了解决这个问题,一种新的研究主题正在兴起,转向使用真实图像的组合,而不是基于图形的渲染。其核心理念是将真实的物体掩膜“粘贴”到真实图像中,从而减少对图形渲染的依赖。一些同时进行的研究通过估计场景几何和布局,然后合成地将物体掩膜放置在场景中以创建逼真的训练图像。然而,场景布局估计步骤可能无法泛化到未见过的场景。在我们的论文中,我们展示了一种无需场景几何估计就能创建训练图像的更简单的方法。
关键洞见: 我们的主要洞见是,像Faster R-CNN这样的最先进的检测方法,甚至是较老的方法(如DPM等),在检测中更关注局部区域特征,而不是全局场景布局。例如,一个杯子检测器主要关注杯子的视觉外观及其与背景的融合,而不太关注杯子出现在场景中的具体位置(如桌面或地面)。我们认为,尽管全局一致性很重要,但在构建合成数据集时,仅确保补丁级别的真实感应足以训练这些检测器。我们使用“补丁级别真实感”这个术语来指代:包含粘贴物体的边界框在人眼中看起来是逼真的。
挑战: 然而,简单地将物体掩膜放置在场景中,会在图像中产生微妙的像素伪影。这些像素空间中的小瑕疵在通过卷积网络的层次传播时,会导致明显不同的特征,训练算法往往会关注这些差异来检测物体,而忽略了建模物体的复杂视觉外观。正如我们的结果所示,这样的模型会导致检测性能的降低。
解决方案: 由于我们的主要目标是创建有助于训练检测器的训练数据,我们通过数据增强和去噪自动编码器等方法生成数据,使训练算法忽略这些伪影,并仅关注物体的外观。我们展示了如何通过在相同的场景下进行相同的物体放置,并仅改变融合参数设置的方法,使检测器对这些微妙的像素伪影变得鲁棒,并改善训练。尽管这些图像并不遵守全局一致性,甚至不考虑场景因素(如光照等),但在它们上进行训练仍能带来高性能的检测器,且付出的努力很少。我们的方法也可以与现有的确保全局一致性的工作结合使用。
实验结果: 使用我们的方法生成的数据在训练检测模型时出乎意料地有效。我们的结果表明,精心策划的实例识别数据集在物体的视觉外观覆盖范围方面存在不足。使用我们的方法,我们能够生成许多具有不同视角/尺度的图像,并以最小的努力覆盖物体的视觉外观。因此,当测试场景与训练场景不同,物体在不同视角/尺度下出现时,我们的性能提升尤为明显。
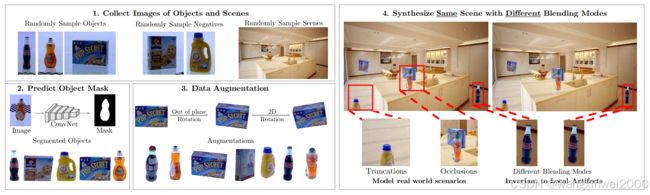
图 2:我们提出了一种用于实例检测的快速合成数据集的简单方法。我们首先从一组实例图像和背景场景图像开始。然后,自动提取物体的掩膜并对物体进行分割。接着,我们将这些物体粘贴到不同场景中,并通过不同的融合方式确保检测模型忽略局部伪影。我们的结果表明,这些合成数据既能与真实数据竞争,又包含互补信息。
图 2:我们提出了一种用于实例检测的快速合成数据集的简单方法。我们首先从一组实例图像和背景场景图像开始。然后,自动提取物体的掩膜并对物体进行分割。接着,我们将这些物体粘贴到不同场景中,并通过不同的融合方式确保检测模型忽略局部伪影。我们的结果表明,这些合成数据既能与真实数据竞争,又包含互补信息。
2. Related Work
早期的实例检测方法依赖于提取图像中的局部特征(如 SIFT、SURF 等),并将这些特征与数据库中的实例进行匹配。然而,这些方法对特征不丰富的物体表现不佳,因此后来形状基方法得到了更多关注。
随着计算资源的增强,特别是GPU的广泛应用,基于卷积神经网络(ConvNet)的检测方法成为主流。这些方法不仅能够泛化到特征丰富和贫乏的物体,还可以通过快速算法实现实时检测,适用于例如机器人等需要快速响应的领域。
然而,这些现代方法依赖大量的标注数据,标注这些数据既费时又昂贵,尤其是在需要快速部署检测系统的场景中。为了解决这个问题,合成数据成为了一个重要的研究方向。合成数据通过渲染3D模型并将其放置在随机背景上来生成,但与真实数据相比,合成数据在图像统计上有所不同,从而影响模型的泛化能力。
在合成数据的研究光谱上,有的工作侧重于生成单个物体在随机背景上的图像,有的则渲染整个场景,而该段作者的研究则位于中间,通过组合真实的物体图像和背景图像来创建新的训练场景。这种方法介于完全渲染和完全真实数据之间,试图在局部特征和全局一致性之间找到一个平衡点。
作者强调,尽管全局一致性对检测系统很重要,但局部特征对于训练检测系统可能更为关键。为此,作者提出了一种方法,确保在训练检测模型时,它对局部的差异具有鲁棒性,使得这些差异不会对最终的检测性能产生负面影响。这种方法在实践中显示出其有效性,尤其是在使用真实图像和背景合成新的训练数据时。

图 3:物体检测与实例检测的对比。实例检测涉及在同一“物体类别”内进行细粒度识别(如图中视觉上相似的咖啡杯),同时还需从不同的视角检测相同的实例(如不同视角下的麦片棒)。在这个例子中,实例识别需要区分6个类别:2种类型的麦片棒和4种类型的咖啡杯。而物体检测只需区分2个类别:咖啡杯和麦片棒。
3. Background
在实例检测中,系统需要准确地定位特定对象,例如特定品牌的麦片或特定的杯子。相比之下,通用对象检测只检测整个类别,如麦片盒或杯子。在实例检测中,错误地定位其他品牌的麦片盒会被视为错误。这种检测常用于机器人、AR/VR等领域,并且可以视为一种细粒度的识别任务。
传统数据集的收集:
构建检测数据集通常包括数据收集和注释两个步骤。通常通过互联网收集图像,但这对实例检测效果不佳,因为难以找到特定实例的图像。实例检测的数据收集需要将对象放置在不同背景下,手动拍摄图像,以确保图像的多样性。注释步骤通常通过众包完成,有时还会结合对象跟踪或3D传感器信息进行增强。
然而,这些步骤对于快速收集实例注释并不合适。首先,即使仅限于同一类型的场景,如厨房,收集的数据可能缺乏多样性,导致在测试时出现偏差。其次,随着图像和实例数量的增加,手动注释需要更多的时间和成本。
4. Approach Overview
我们提出了一种快速收集实例检测数据的简便方法。实验表明,该方法与手动收集数据的效果相当,但所需时间更少且无需人工标注。
理想情况下,我们希望捕获实例的所有视觉多样性。实例在不同视角、比例、方向和光照条件下看起来会有所不同,因此区分这些实例需要数据集具备良好的视点和比例覆盖。随着类别数量增加,数据的长尾分布会影响实例识别问题。通过合成数据,我们可以确保实例和视点的良好覆盖。
方法步骤:
-
收集对象实例图像:我们的方法对数据收集方式不敏感,假设我们拥有涵盖多种视角和背景简单的对象图像。
-
收集场景图像:这些图像将作为训练数据集的背景图像。如果已知测试场景(如智能家居或仓库),可以从这些场景中收集图像。由于我们不计算场景统计信息如几何或布局,因此我们的方法能够轻松应对新场景。
-
预测对象前景掩码:预测前景掩码,将实例像素与背景像素分离,得到可以放置在场景中的对象掩码。
-
将对象实例粘贴到场景中:将提取的对象粘贴到随机选择的背景图像上。放置对象时确保对局部伪影不敏感,以便训练算法不集中在边界的亚像素差异上。我们添加了多种混合模式,并通过不同的混合方式合成同一场景,使算法能够应对这些伪影。此外,我们还增加了数据增强,以确保覆盖多种视角/比例。
融合
直接将对象粘贴到背景图像上会产生边界伪影。图6展示了一些这种伪影的例子。尽管这些伪影看起来微妙,但在训练检测算法时使用这些图像会导致性能下降(如表1所示)。由于当前的检测方法[39]强烈依赖于局部区域的特征,边界伪影会显著降低其性能。融合步骤通过平滑对象和背景之间的边界伪影来改善这一情况。
图6展示了一些融合的例子,其中包括不同的图像变化,例如Poisson融合[37]可以平滑边缘并添加光照变化。虽然这些融合方法无法产生视觉上“完美”的结果,但它们确实提高了训练检测器的性能。
为了进一步减少融合对训练算法的影响,我们合成了完全相同的场景,保持对象位置不变,只是改变使用的融合类型。在表1中,这一方法被标记为“所有融合+相同图像”。在多张仅融合因子不同的图像上进行训练,使得训练算法对这些融合因子不敏感,并在不使用任何融合形式的情况下将性能提高了8个AP点。
