源码走读到这个阶段,其实整个 Hdfs 的交互流程都已经完全走读完了,虽然肯定有一些细节的地方没有进行走读,但是不会影响对整个 Hdfs 的架构认知。
这一篇文章也将是整个 Hdfs 源码走读的最后一篇,在本文中,将介绍 NameNode 、 DataNode 之外的其他节点信息和部分高阶功能。
Federation 与 ViewFS
为了保证 Hdfs 文件系统中的数据一致性,对于同一个文件系统只会有一个 NameNode 负责接收操作请求,即便在 HA 模式下,整个集群中也只会有一个 ActiveNameNode 负责处理消息。
也正是这个原因,在 Hdfs 中存在一个节点数量瓶颈,类似 Android 中的 65536 的方法数限制,在这里也有一个 2^30 个理论上限(LightWeightGSet::computeCapacity中可以看到这个值的来源依据)。
为了解决这个问题,在 Hadoop 0.23.0 中引入了 Federation 的概念,用以解决 Hdfs 横向扩容的需求。

如上图所示,左侧是进行联合部署前的集群情况,NameNode 和 DataNode 之间是一对多的关系,整个 Hdfs 集群中只有一个 NameNode 节点,所有的 DataNode 节点都只同唯一的 NameNode 进行通信。右侧是进行联合部署后的集群情况,NameNode 和 DataNode 之间是多对多的关系,Hdfs 集群中同时存在多个 NameNode 节点,每个节点都是 ActiveNameNode,单个 DataNode 可以存放任意个数的 NameNode 的 Block 数据。
这意味着对于同一个集群,我们可以通过让 DataNode 连接多个 NameNode 使得 NameNode 的文件节点数量不再受限,可以进行任意的水平扩容。
我们知道 NameNode 中会唯一的存在一个 FSDirectory 类负责记录当前的节点信息,每个文件节点都由一个或多个 BlockInfo 构成。为了实现 Federation 能够区分来自不同 NameNode 的 Block 信息,我们认为属于同一个 NameNode 的 BlockInfo 应该属于同一个 BlockPool, 在构造 NameNode 的时候创建一个唯一的 BPId (BlockPoolID),每个 NameNode 通过不同的 BPId 进行区分。
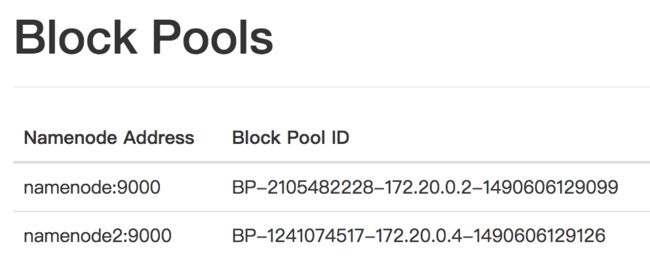
如上图所示,在同一个 DataNode 中,不同的 NameNode 对应不同的 BlockPool。从实现逻辑上来看,在 ${DATA_DIR}/current 下会根据不同 NameNode 返回的不同 BlcokPoolId 生成对应的文件夹,从而使得不同 NameNode 的文件数据彼此物理隔离不相互影响。
引入 Federation 之后,Hdfs 集群中存在多个 NameNode 节点,用户在执行 hadoop 指令的时候必须写上完整的 url 路径才能够访问指定的 NameNode 节点,随着集群节点越来越来,复杂冗余的 hdfs 地址极有可能产生误操作,影响线上数据。为了解决这个问题,Hdfs 中又引入了 ViewFS 的文件挂载概念。
在 core-site.xml 中将 fs.defaultFS 的 schema 配置为 viewfs, 并在 mountTable.xml 中配置对应的挂载信息,即可将不同的文件系统挂载到 ViewFs 这个伪文件系统中。

如上图所示,我们有 /User、/Work、/Tmp 三个工作目录,分别代指不同的 NameNode 和本地文件系统。通过将 NameNodeA 挂载在 /User 路径下,将 NameNodeB 挂载在 /Work 路径下,将本地文件系统挂载在 /Tmp 中,我们可以使用同一个 host 的不同路径访问不同的文件系统。
@Override
protected AbstractFileSystem getTargetFileSystem(final URI uri)
throws URISyntaxException, UnsupportedFileSystemException {
String pathString = uri.getPath();
if (pathString.isEmpty()) {
pathString = "/";
}
return new ChRootedFs(
AbstractFileSystem.createFileSystem(uri, config),
new Path(pathString));
}
具体的实现逻辑可以查看 ViewFs 类,在 ViewFs 中处理请求消息时,会针对不同的挂载点,获取其真实路径,在 getTargetFileSystem 中会根据真实的 uri 地址返回对应的 FileSystem,执行操作。ViewFs 可以理解为一个进行代理分发的接口,将查询不同挂载点的请求数据,分发给对应的 FileSystem 进行请求。
SecondaryNameNode
NameNode 中为了保证文件系统的读取效率,会将整个文件节点信息全部加载到内存中成为 FSDirectory,所有对文件系统的操作,将直接在内存中进行更正,并通过 EditLog 进行逐一记录到磁盘中。
如果 NameNode 挂掉重启时,为了保证已有文件节点信息的完整性,会逐一对 EditLog 进行重演,从而恢复到挂掉前的状态。
对 EditLog 的重演是一个串行的过程,当需要重演的 EditLog 数量过多时,会严重滞后 NameNode 的启动时间。为了降低重演 EditLog 的时间消耗,在 Hdfs 中产生了 CheckPoint 的概念。
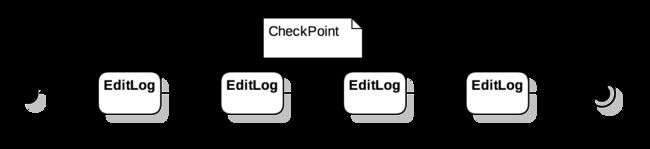
FSDirectory 可以认为是消费 EditLog 之后得到的产物,对于同样的 EditLog,进行相同顺序的处理之后,始终会得到同样的 FSDirectory。如果我们直接保存当前的 FSDirectory 状态,则会同消费这些 EditLog 起到同样的效果。在这里,CheckPoint 被看作是某个特定时间点下 FSDirectory 的序列化产物,它记录着当前时间点 FSDirectory 中所有节点的相关信息。
HA 情况下,此时集群中存在多个 NameNode 节点,其中只有一个是 Active 状态,其他的都处于 Standby 状态下。StandbyNameNode 会读取 ActiveNameNode 的 EditLog 信息,并创建 CheckPoint,相关的分析会在后面的小节中讨论,这里先看非 HA 模式下的实现。
非 HA 模式下,为了周期性对 NameNode 中的文件系统建立 CheckPoint,通常会有一个 SecondaryNameNode 伴随 NameNode 一起启动,他负责周期性对 NameNode 中的文件系统建立 CheckPoint,确保 NameNode 挂掉之后能够快速重启。
通过 start-dfs.sh 启动 Hdfs 集群时,如果发现当前集群非 HA 集群,则会启动对应的 SecondaryNameNode。
SecondaryNameNode 本身是一个 Runnable 对象,在 main 方法中,会构建一个线程类,执行 Runnable。
while (shouldRun) {
Thread.sleep(1000 * period);
if (shouldCheckpointBasedOnCount() ||
monotonicNow >= lastCheckpointTime + 1000 * checkpointConf.getPeriod()) {
doCheckpoint();
}
}
在 SecondaryNameNode::run 中,会不断的进行 while 循环,当发现 NameNode 中执行的 EditLog 超过一定阈值时或者距离上次 CheckPoint 的时间点超过阈值时,会调用 doCheckPoint 方法执行镜像备份操作。
// Tell the namenode to start logging transactions in a new edit file
// Returns a token that would be used to upload the merged image.
CheckpointSignature sig = namenode.rollEditLog();
RemoteEditLogManifest manifest =
namenode.getEditLogManifest(sig.mostRecentCheckpointTxId + 1);
// Fetch fsimage and edits. Reload the image if previous merge failed.
loadImage |= downloadCheckpointFiles(
fsName, checkpointImage, sig, manifest) |
checkpointImage.hasMergeError();
doMerge(sig, manifest, loadImage, checkpointImage, namesystem);
TransferFsImage.uploadImageFromStorage(fsName, conf, dstStorage,
NameNodeFile.IMAGE, txid);
doCheckPoint 中主要分为以下步骤:
- 通过
rollEditLog通知 namenode 节点停止对当前 editLog 文件的写入操作,创建新的 EditLog 文件进行 EditLog 写入,便于后续步骤中下载 EditLog 文件。 - 通过
getEditLogManifest获取从最近的 CheckPoint 点之后的所有 EditLog 的信息,然后通过downloadCheckpointFiles从 NameNode 的 Http 服务器下载相关文件,通过doMerge进行数据合并。 - 通过
uploadImageFromStorage将当前合并生成了 CheckPoint Image 再传输回 NameNode , 作为最近一次的 CheckPoint 点。
之前介绍过 NameNode 中有一个基于 Jetty 的 NameNodeHttpServer,负责提供 NameNode 节点的相关状态,其实除了 NameNode 节点状态之外,他也负责其他的 Http 请求访问,例如 SecondaryNameNode 中的下载 EditLog 和上传 CheckPoint 文件就是通过 NameNodeHttpServer::setupServlets 中注册的 ImageServlet 类进行实现的。
High Availability
在单节点的 NameNode 系统中,我们无法保证整个集群的高可用。如果 NameNode 异常退出,归属于这个 NameNode 的所有节点都将不可访问,会导致整个 NameNode 文件系统无法正常使用。为了解决这个问题,Hdfs 中引入了 HA(High Availability) 的概念。
在 HA 环境下,会由多个 NameNode 构成一个 NameService,整个 NameService 中的每一个 NameNode 都会存放完整的节点信息。通常只会有一个主节点(ActiveNameNode)负责向外提供服务,但是如果主节点异常之后,其他节点(StandbyNameNode)会重新进行选主操作,选出新的主节点。由于每个 NameNode 中都存有相对完整的节点信息,不会影响大多数的节点信息读取。
ActiveNameNode 选举
Hadoop 中引入了 ZooKeeper 来处理服务发现和节点异常。
通过 start-dfs.sh 启动 cluster 时,每个 NameNode 节点上都会启动一个 NameNode,如果判断当前集群是 HA 集群,则还会在每台 NameNode 的节点机器上启动一个 zkfc(ZKFailoverController) 组件。
在 HA 情况下,NameNode 启动之后会默认成为 StandbyNameNode,只负责同步来自 ActiveNameNode 的 EditLog。 伴随着 NameNode 启动的 zkfc 负责进行 ActiveNameNode 的选举以及转换 NameNode 状态变化 。
在 zkfc 中会创建一个 ActiveStandbyElector 处理选举流程。 ActiveStandbyElector 会同配置 ha.zookeeper.quorum 中指定的 ZooKeeper 进行链接,链接成功后,进入选举流程。

zkfc 对应的 ZooKeeper 节点信息如上图所示,hadoop-ha 是每一个 NameService 注册的顶级路径,在它的下方是根据每个 NameService 名称命名的二级路径,在二级路径下是 ActiveStandbyElectorLock 和 ActiveBreadCrumb。 ActiveStandbyElectorLock 是一个临时节点,它的创建 zkfc 被认为是 Active。 ActiveBreadCrumb 中保存着当前的 ActiveNameNode 信息,当 ActiveNameNode 变化时,负责通知之前的 NameNode 切换成 Standby。
具体流程图如下:

当 zkfc 链接上 ZooKeeper 后,尝试判断 ActiveStandbyElectorLock 是否存在,若不存在,则各个 zkfc 均尝试创建这个临时节点,通过 ZooKeeper 的节点机制确保只有一个 Client 能够成功创建这个节点,创建成功的节点将成为主节点,它对应的 NameNode 成为 ActiveNameNode,其他节点成为 StandbyNameNode。
SharedEditLog
在 HA 模式下,一个 NameService 中只有一个 ActiveNameNode 负责接收处理节点操作,其余的 StandbyNameNode 都只负责读取 ActiveNameNode 中的 EditLog 数据,保证节点数据同 ActiveNameNode 一致。
HA 模式提供了两种 SharedEditLog 的模式:
- NFS(Network File System): 每个 NameNode 机器上如果都挂载同一个 NFS,则我们可以像读取本地文件一样,直接从 NFS 中读取 EditLog 信息,由于不同的 NameNode 对应同一个 NFS,因此我们读取到的 EditLog 必然一致,只需要对 EditLog 依次进行重演,即可和 ActiveNameNode 保持同样的状态。 通过 NFS 能够满足 EditLog 的同步,但是相对的,我们对 NTF 的高速和无损要求也较高,因此 NTF 需要被部署在类似 NAS 的专业数据存储服务器上。
- QJM(Quorum Journal Manager): 在不能保证共享磁盘的高速、无损情况下,Hdfs 提供了一个 QJM 的替代方案,通过一个专门的 JournalNode 负责读取 ActiveNameNode 上的 EditLog,StandbyNameNode 通过读取 JournalNode 上的保留下来的 EditLog,间接实现 EditLog 状态同步,从而将 ActiveNameNode 上的文件读取压力转移到了 JournalNode 上。
NameNode 中进入 Standby 模式后,会启动一个 EditLogTailer 负责从设定的 SharedEditLog 中不断读取 EditLog 数据。
// FSEditLog.java
private synchronized void initJournals(List dirs) {
for (URI u : dirs) {
if (u.getScheme().equals(NNStorage.LOCAL_URI_SCHEME)) {
journalSet.add(new FileJournalManager(conf, sd, storage),
required, sharedEditsDirs.contains(u));
} else {
journalSet.add(createJournal(u), required,
sharedEditsDirs.contains(u));
}
}
}
public void selectInputStreams(Collection streams,
long fromTxId, boolean inProgressOk, boolean onlyDurableTxns)
throws IOException {
journalSet.selectInputStreams(streams, fromTxId,
inProgressOk, onlyDurableTxns);
}
// EditLogTailer.java
void doTailEdits() throws IOException, InterruptedException {
streams = editLog.selectInputStreams(lastTxnId + 1, 0,
null, inProgressOk, true);
editsLoaded = image.loadEdits(streams, namesystem);
}
在构建 FSEditLog 的时候,会根据配置文件中不同的 sharededitlog 配置构造出不同的 FileJournalManager 或者 QuorumJournalManager 加入 journalSet 中。
在 StandbyNameNode 的 EditLogTailer 中,从 journalSet 中获取 EditLogInputStream 对象,然后解析成一条条的 EditLog 进行消费。
CheckPoint
在非 HA 模式下,为了避免 NameNode 节点进行 CheckPoint 导致的性能问题,我们选择单独建立 SecondaryNameNode 定时进行 CheckPoint。
在 HA 模式下, StandbyNameNode 只负责同步 EditLog 信息,对性能的要求更低,因此我们将 SecondaryNameNode 的工作分配给了 StandbyNameNode 进行。在 StandbyNameNode 中会开启一个 StandbyCheckPointer 线程,进行定时 CheckPoint。由于 StandbyNameNode 中已经包含了完整的 FSDirectory 信息,不需要再从 ImageServlet 中获取 EditLog。