ElasticSearch for GIS应用
基础介绍
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
集群部署
ES的集群配置非常简单。
环境需求:
- Ubuntu 14.04 LTS、
- jre-8u101-linux-x64.tar.gz、
- elasticsearch-2.3.5.tar.gz、
- kibana-4.5.4-linux-x64.tar.gz
https://www.elastic.co/products/elasticsearch

1、安装Ubuntu OS
2、下载JRE,解压后配置JAVA_HOME
3、下载ES包,解压到一个非root用户下,如supermap用户,修改配置文件$ES_HOME/config/elasticsearch.yml
supermap@ubuntu14:~/elasticsearch-2.3.5/config$ grep ^[a-z] elasticsearch.yml
cluster.name: my-application
node.name: node-1
network.host: 192.168.12.169
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.12.169"]
当在一个局域网内设置一个ES的集群名称(如my-application),如果新添加一个新的机器,就会自动加入到该集群中,可以为集群的节点设置nodename(node-1),设置本机的host,建议IP,设置默认的端口号9200,设置允许加入到集群中来discovery.zen.ping.unicast.hosts。
当然,该配置文件还有比较多其他参数,感兴趣可以一一研究。
170集群配置如下:
supermap@ubuntu14:~/elasticsearch-2.3.5/config$ grep ^[a-z] elasticsearch.yml
cluster.name: my-application
node.name: node-2
network.host: 192.168.12.170
http.port: 19200
discovery.zen.ping.unicast.hosts: ["192.168.12.169"]
175集群配置如下:
supermap@ubuntu14:~/elasticsearch-2.3.5/config$ grep ^[a-z] elasticsearch.yml
cluster.name: my-application
node.name: node-3
network.host: 192.168.12.175
http.port: 29200
discovery.zen.ping.unicast.hosts: ["192.168.12.169"]
注意,设置不同的nodename ,IP地址以及端口号。
然后我启动ES的服务,例如登陆169,$ES_HOME/bin,通过nohup ./elasticsearch &后台服务运行即可。其他机器也是同样,这样ES的集群就部署完毕了。
ES基础介绍
ES从名称来看就是为搜索而生的,特别是各大互联网公司使用的分布式日志解决方案ELK,主要为数据提供比较快速的搜索性能,当然ES不仅可以提供搜索功能,也可以提供存储功能,而且在ES的数据结构中,Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包含多个文档(documents)(行),然后每个文档包含多个字段(Fields)(列)。
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> FieldsES是支持分布式的,开篇就讲到,他可以非常轻松的支持PB级别的数据量,而且实现千余台服务器的横向扩展能力,Elasticsearch在分布式概念上做了很大程度上的透明化,在教程中你不需要知道任何关于分布式系统、分片、集群发现或者其他大量的分布式概念。所有的教程你既可以运行在你的笔记本上,也可以运行在拥有100个节点的集群上,其工作方式是一样的。
Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
- 将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
- 将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
- 冗余每一个分片,防止硬件故障造成的数据丢失。
- 将集群中任意一个节点上的请求路由到相应数据所在的节点。
- 无论是增加节点,还是移除节点,分片都可以做到无缝的扩展和迁移。
ElasticSearch的插件介绍
可能你会觉得,我还是想直观的了解一下ES的分片机制,非常高兴地随着ES这个开源软件收到各个厂商和开发者的关注,大家不断的往ES进行插件的扩展,有很多官方和第三方开发的插件,下面以分词、同步、数据传输、脚本支持、站点、其它这几个类别进行划分。
当然,这次跟大家介绍一个类似于(数据库查看器功能的)elasticsearch-head插件,既可以对集群进行简单管理,同时查看各个索引的数据信息,而且可以直观的查看分片的布局。
安装插件也比较简单,只需要进入$ES_HOME/bin目前,执行如下命令即可
elasticsearch/bin/plugin install mobz/elasticsearch-headhttp://192.168.12.169:9200/_plugin/head/进行查看。如图所示,我已经安装了两台集群(集群是陆续安装的)同时已经导入了一些数据。
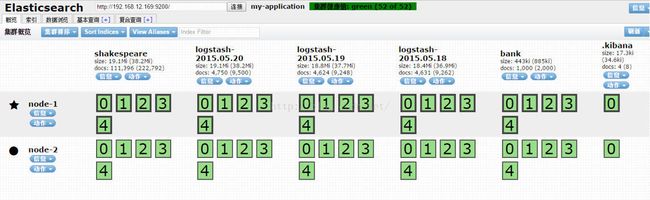
我们可以看到集群的绿色健康信息(会有红,黄,绿三种颜色表示),该机器目前有两台服务器,node-1前面是黑色五星,表面是master,node-2是黑色圈圈,表明为非master,默认每一个数据导入都会有5个分片和1个复制,所以看到每个index都包含五个黑色粗边方框和五个细边方框,也就是1个副本,如果我们在该基础上添加一个node-3节点,我们可以看到。


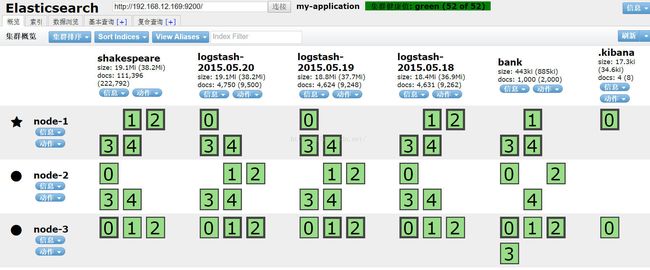
他会自动的,陆续的有变紫颜色的片进行迁移到node-3,最后变成如上图所示,到系统感觉分别的比较均衡为止。
当然,ES head还有比较多的查询管理功能。
ElasticSearch+Kibana的GIS应用
说了这么多,仿佛还没有看到ES与GIS有什么关联,其实,ES已经包含了地理位置的概念,也就是他可以接受带有空间位置坐标的信息,包括geopoint和geoshape(线面),同时可以实现空间聚合,geohash等功能

接下来,我们就做一个演示,将数据导入到ES里面,然后通过kibana进行地理数据的聚合演示。
关于kibana部署,只需下载上述安装包,然后解压,修改/config/kibana.yml配置文件
supermap@ubuntu14:~/kibana-4.5.4-linux-x64/config$ grep ^[a-z] kibana.yml
server.port: 5601
server.host: "192.168.12.169"
elasticsearch.url: "http://192.168.12.169:9200"
1、下载数据
2、创建mapping
curl -XPUT http://192.168.12.169:9200/logstash-2015.05.18 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://192.168.12.169:9200/logstash-2015.05.19 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';
curl -XPUT http://192.168.12.169:9200/logstash-2015.05.20 -d '
{
"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}
';3、导入数据
curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl4、打开kibana界面http://192.168.12.169:5601/
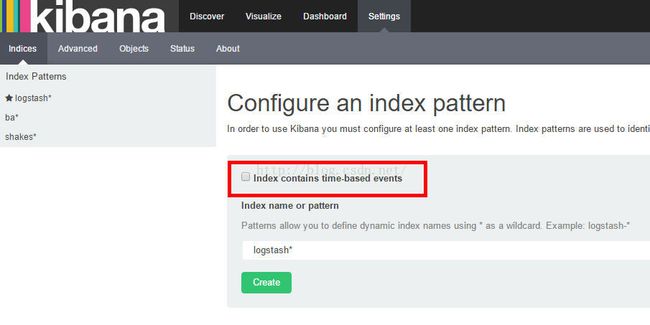
创建indices,不勾选index containes time-based events
5、创建tile map
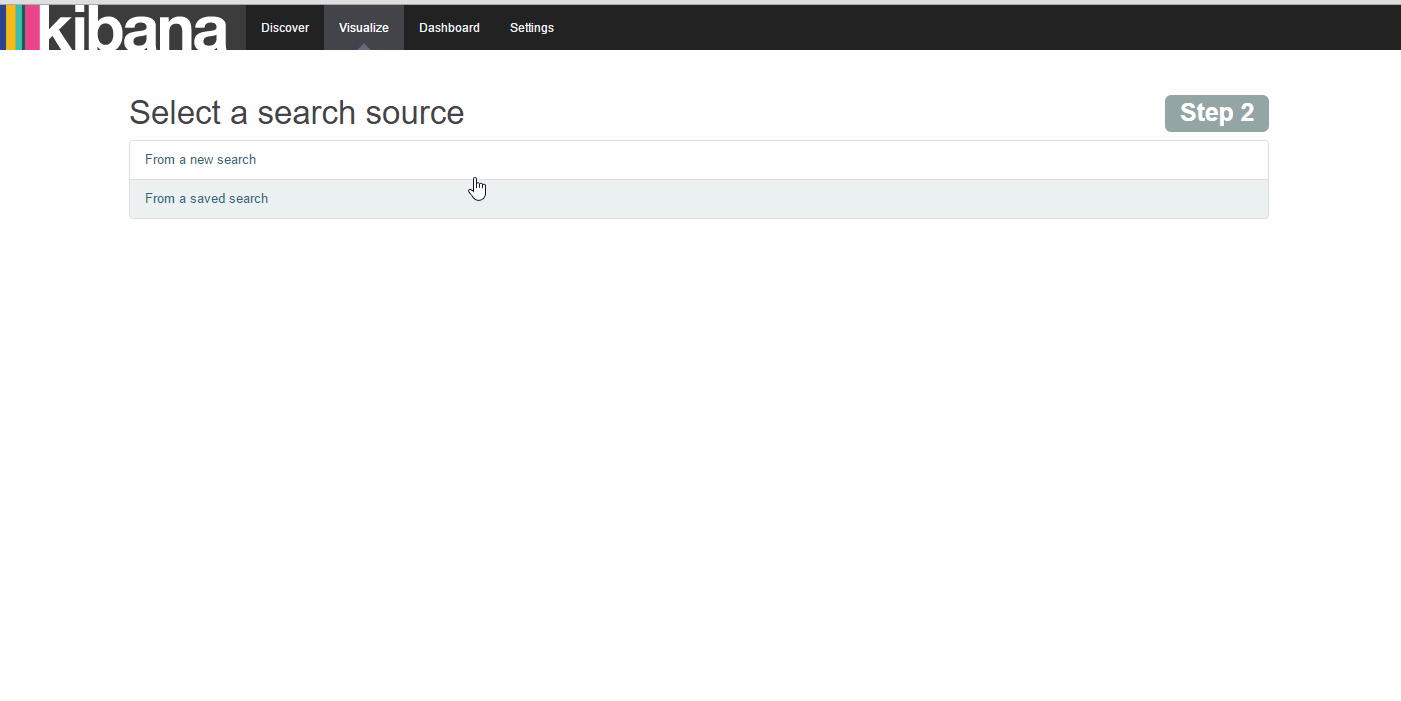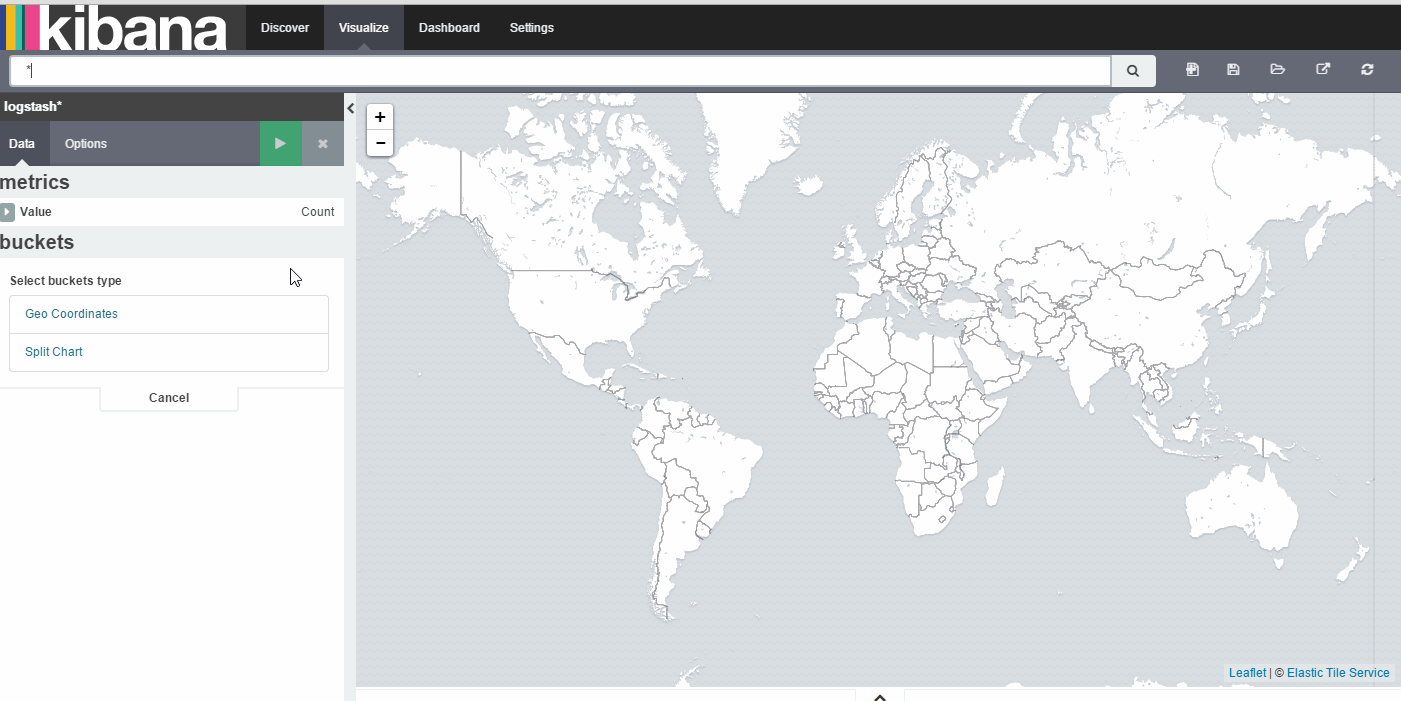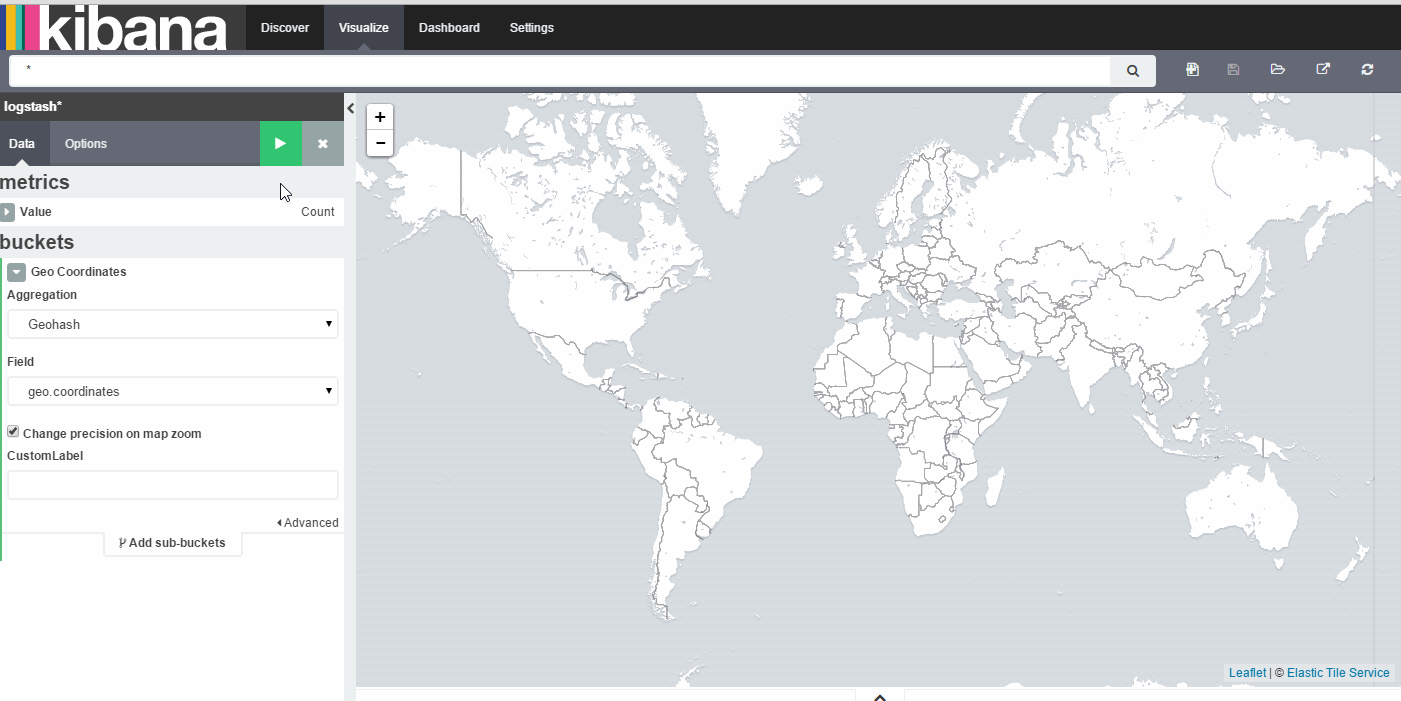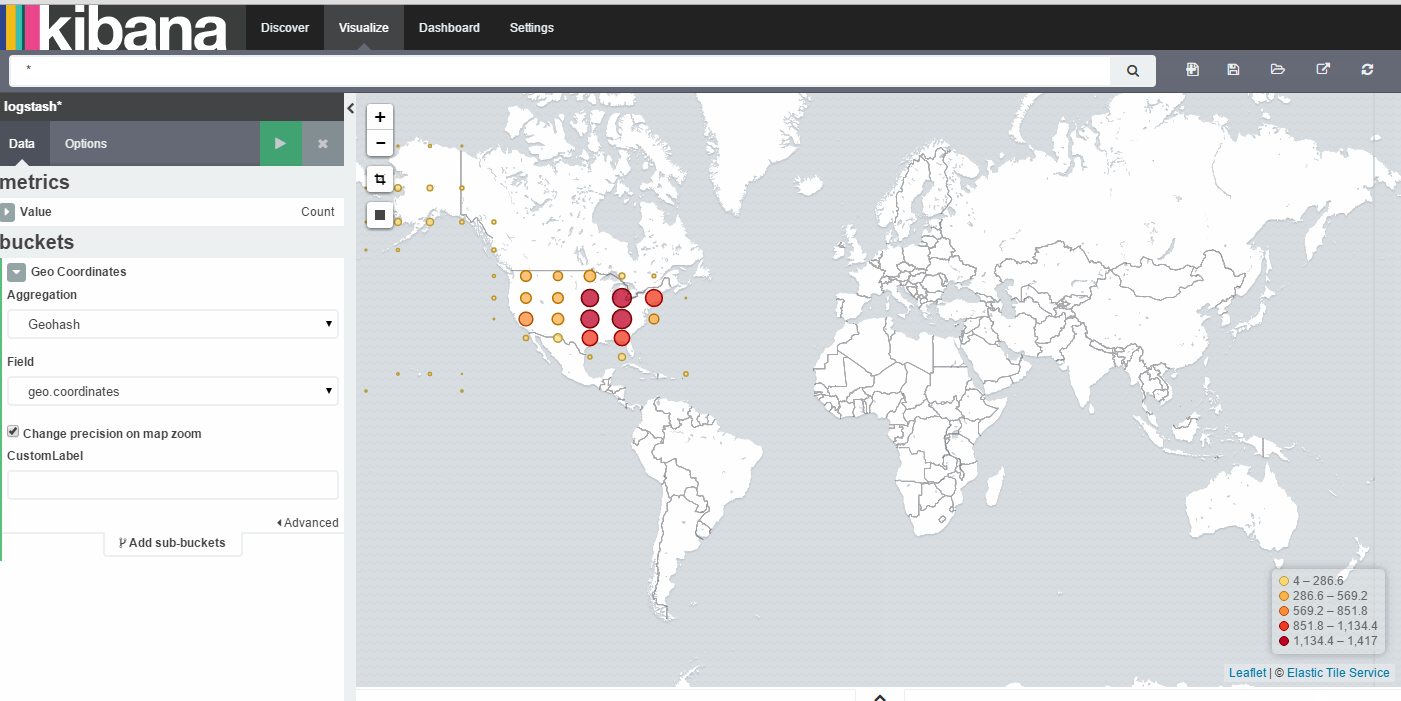
更多延伸
其实,使用ES更好的应用,还在于大数据量实时数据的检索和存储,如果你觉得使用ES扩展存储,ES-hadoop,也可以满足通过HDFS进行分布式存储,通过ES进行实时数据的检索。