语音识别——kaldi基于GMM的单音素模型 训练部分
文章目录
- 1. gmm-init-mono 模型初始化
- 2. compile-train-graghs 训练图初始化
- 3. align-equal-compiled 特征文件均匀分割
- 4. gmm-acc-stats-ali 累积模型重估所需数据
- 5. gmm-sum-accs 并行数据合并
- 6. gmm-est 声音模型参数重估
- 7. gmm-boost-silence 模型平滑处理
- 8. gmm-align-compiled 特征重新对齐
- 9. train_mono.sh 整体流程详解
转载注明出处。
1. gmm-init-mono 模型初始化
gmm-init-mono --train-feats=ark:feats.ark topo 39 0.mdl tree0.mdl中使用初始化的状态转换概率,其中 pdf模型共享参数。tree中的树为提出两个问题,第一个问题为各个音素是什么,第二个问题为状态为第几个。
实例:
- 将特征进行均值方差归一化后抽取一阶差分和二阶差分:
/home/speech.AI/kaldi/src/featbin/apply-cmvn scp:cmvn.scp scp:copy-feats.scp ark:- | /home/speech.AI/kaldi/src/featbin/add-deltas ark:- ark:delta.ark
- 利用提取的39维特征进行进行模型初始化:
gmm-init-mono --train-feats=ark:delta.ark topo 39 0.mdl tree
2. compile-train-graghs 训练图初始化
- 使用
compile-train-graghs生成训练用的FST,是每个句子构造一个FST网络:
Usage: compile-train-graphs [options]
e.g.: compile-train-graphs tree 1.mdl lex.fst ark:train.tra ark:graphs.fsts
其中的ark:train.tra一般通过ark:sym2int.pl -f 2- words.txt text|利用词典将文本信息转化为对应的音素序号。
下面是我的路径下的测试命令:
/home/speech.AI/kaldi/src/bin/compile-train-graphs 0.tree 0.mdl ../data/lang/L.fst 'ark:/home/speech.AI/kaldi/egs/wsj/s5/utils/sym2int.pl -f 2- words.txt text|' ark:graphs.fsts
3. align-equal-compiled 特征文件均匀分割
- 使用
align-equal-compiled根据我们得到的训练用的fst对特征文件进行均匀分割。 - 需要留意,切割的文件中间都掺杂着SIL单词,但是标注中没有体现,我还不知道为何,切对齐文件每个状态的帧数也不相同。
Usage: align-equal-compiled
e.g.: align-equal-compiled ark:graphs.fsts ark:delta.ark ark:equal.ali
- 对文件的每一帧进行均匀标准,具体算法不了解:
[2 1 1 1 1 1 1 1 1 6 5 5 5 5 5 5 5 5 11 10 10 10 10 10 10 10 10 13 15 15 15 15 15 15 15 15 8 5 5 5 5 5 5 5 5 18 17 17 17 17 17 17 17 17 26 25 25 25 25 25 25 25 25 28 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 4 1 1 1 1 1 1 1 1 14 15 15 15 15 15 15 15 15 12 10 10 10 10 10 10 10 10 18 17 17 17 17 17 17 17 17 26 25 25 25 25 25 25 25 25 28 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 2 1 1 1 1 1 1 1 1 6 5 5 5 5 5 5 5 5 11 10 10 10 10 10 10 10 10 13 15 15 15 15 15 15 15 15 8 5 5 5 5 5 5 5 5 18 17 17 17 17 17 17 17 17 26 25 25 25 25 25 25 25 25 28 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 3 1 1 1 1 1 1 1 1 9 10 10 10 10 10 10 10 10 7 5 5 5 5 5 5 5 5 14 15 15 15 15 15 15 15 15 9 10 10 10 10 10 10 10 10 7 5 5 5 5 5 5 5 5 13 15 15 15 15 15 15 15 15 7 5 5 5 5 5 5 5 5 14 15 15 15 15 15 15 15 15 12 10 10 10 10 10 10 10 10 18 17 17 17 17 17 17 17 17 26 25 25 25 25 25 25 25 25 28 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 4 1 1 1 1 1 1 1 13 15 15 15 15 15 15 15 15 7 5 5 5 5 5 5 5 16 15 15 15 15 15 15 15 18 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 24 23 23 23 23 23 23 23 3 1 1 1 1 1 1 1 11 10 10 10 10 10 10 10 13 15 15 15 15 15 15 15 6 5 5 5 5 5 5 5 11 10 10 10 10 10 10 10 14 15 15 15 15 15 15 15 9 10 10 10 10 10 10 10 8 5 5 5 5 5 5 5 18 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 24 23 23 23 23 23 23 23 3 1 1 1 1 1 1 1 11 10 10 10 10 10 10 10 16 15 15 15 15 15 15 15 18 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 24 23 23 23 23 23 23 23 20 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 24 23 23 23 23 23 22 23 2 1 1 1 1 1 1 1 7 5 5 5 5 5 5 5 14 15 15 15 15 15 15 15 12 10 10 10 10 10 10 10 18 17 17 17 17 17 17 17];
均匀分割后的每一帧trans-id的标注,不知道为何每个音素的时间并不相同,也不知道原因。
且每个单词中间都出现了未被标注的静音音素。

实例:
home/speech.AI/kaldi/src/bin/align-equal-compiled ark:graphs.fsts ark:delta.ark ark:equal.ali
4. gmm-acc-stats-ali 累积模型重估所需数据
Usage: gmm-acc-stats-ali [options]
e.g.: gmm-acc-stats-ali 1.mdl scp:train.scp ark:1.ali 1.acc
-
对于每一帧的特征和其对齐(transition-id):
- 对于转移模型(TM),累积tid出现的次数;
- 对于AM,由tid得到pdf-id,也就是找到对应该pdf-id的DiagGmm对象,更新与该DiagGmm对象相关的AccumDiagGmm的参数,也就是计算得到三个GMM参数更新公式的分子部分(包括每一混合分量的后验(occupancy_中保存 ∑ n j = 1 γ j k ∑nj=1γ^jk ∑nj=1γjk)、每一分量的后验乘以当前帧的特征(mean_accumulator_中保存 ∑ n j = 1 γ j k y j ∑nj=1γ^jkyj ∑nj=1γjkyj, M x D MxD MxD维)、每一分量的后验乘以 当前帧的特征每一维的平方(variance_accumulator_中保存 ∑ n j = 1 γ j k y 2 j ∑nj=1γ^jky2j ∑nj=1γjky2j, M x D MxD MxD维))
-
处理完所有数据后,将TM和AM的累积量写到一个文件中:x.JOB.acc中
实例:
/home/speech.AI/kaldi/src/gmmbin/gmm-acc-stats-ali 0.mdl ark:delta.ark ark:equal.ali 0.acc
5. gmm-sum-accs 并行数据合并
gmm-acc-stats-ali生成的累计量分散在JOB个文件中,该程序将分散的对应同一trans-id、pdf-id的累计量合并在一起
如果不是多个线程就不必进行合并。
Usage: gmm-sum-accs [options] ...
E.g.: gmm-sum-accs 1.acc 1.1.acc 1.2.acc
6. gmm-est 声音模型参数重估
- 作用:Do Maximum Likelihood re-estimation of GMM-based acoustic model.调用gmm-est对0.mdl进行重新估计,该程序对基于GMM的声学模型进行最大似然重新估计,生成exp/mono/1.mdl
Usage: gmm-est [options]
e.g.: gmm-est 1.mdl 1.acc 2.mdl
实例:
/home/speech.AI/kaldi/src/gmmbin/gmm-est 0.mdl 0.acc 1.mdl
7. gmm-boost-silence 模型平滑处理
- 作用:修改基于GMM的模型以(通过某个因素)提升与指定电话相关的所有概率(可以是所有静音电话,或者仅用于可选静音)。 注意:这是通过修改GMM权重来完成的。 如果沉默模型与其他模型共享GMM,则它将修改可能对应于静音的所有模型的GMM权重
- Modify GMM-based model to boost (by a certain factor) all probabilities associated with the specified phones (could be all silence phones, or just the ones used for optional silence). Note: this is done by modifying the GMM weights. If the silence model shares a GMM with other models, then it will modify the GMM weights for all models that may correspond to silence.
Usage: gmm-boost-silence [options]
e.g.: gmm-boost-silence --boost=1.5 1:2:3 1.mdl 1_boostsil.mdl
实例:
/home/speech.AI/kaldi/src/gmmbin/gmm-boost-silence --boost=1.0 1 1.mdl 1_new.mdl
8. gmm-align-compiled 特征重新对齐
- 使用新的模型和原来的训练状态图对原来的特征文件进行重新对齐。
Usage: gmm-align-compiled [options] [scores-wspecifier]
e.g.: gmm-align-compiled 1.mdl ark:graphs.fsts scp:train.scp ark:1.ali
- 或者重新编译新的训练状态图然后对齐:
or: compile-train-graphs tree 1.mdl lex.fst 'ark:sym2int.pl -f 2- words.txt text|' ark:- | gmm-align-compiled 1.mdl ark:- scp:train.scp t, ark:1.ali
实例:
- 首先重新生成训练图:
/home/speech.AI/kaldi/src/bin/compile-train-graphs 0.tree 1.mdl ../data/lang/L.fst 'ark:/home/speech.AI/kaldi/egs/wsj/s5/utils/sym2int.pl -f 2- words.txt text|' ark:graphs_new.fsts
- 然后使用新的解码图进行对齐:
/home/speech.AI/kaldi/src/gmmbin/gmm-align-compiled 1.mdl ark:graphs_new.fsts ark:delta.ark ark,t:ali1.txt
然后就可以获得新的对齐标注:
3 1 12 10 10 10 18 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 26 25 25 25 28 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 29 29 29 29 29 29 2 7 5 5 5 13 15 15 15 15 15 7 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 14 15 15 15 15 15 9 10 7 5 5 5 13 15 15 15 15 15 15 8 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 18 17 17 17 17 17 17 17 17 17 26 25 25 25 25 28 27 27 27 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 29 29 2 1 1 1 1 1 6 5 9 10 10 10 10 10 8 5 5 5 5 5 5 5 5 5 5 18 17 17 17 17 17 26 25 25 25 28 27 27 27 27 27 27 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 29 29 29 2 8 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 18 17 17 17 17 17 17 17 17 26 25 25 25 25 25 25 25 25 25 28 27 27 27 27 27 27 27 30 29 29 29 29 29 29 29 29 29 2 1 1 1 1 1 1 1 1 1 1 1 1 8 5 5 5 5 5 18 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 21 21 24 23 23 23 23 3 1 1 1 1 1 1 12 10 10 10 10 10 18 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 19 19 19 22 21 21 21 21 21 21 24 23 23 23 23 23 23 23 2 1 1 1 1 1 1 8 5 5 5 18 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 20 19 19 19 19 19 19 19 19 22 21 21 21 24 23 23 23 23 23 20 19 19 19 19 19 19 19 22 21 21 21 21 21 21 21 21 24 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 23 2 1 1 1 8 18 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17 17];
- 重新对齐的文件如下所示:
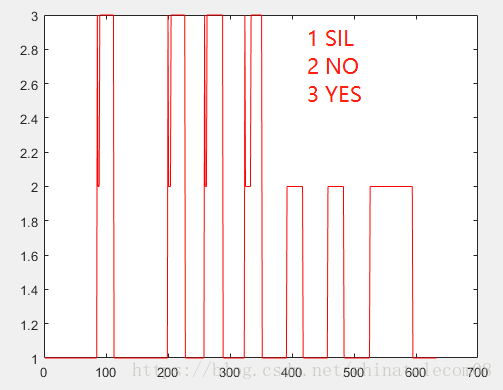
- 常用的可选项为
--beam=16,调整参数可以得到不同的对齐结果。
/home/speech.AI/kaldi/src/gmmbin/gmm-align-compiled --beam=16 1.mdl ark:graphs_new.fsts ark:delta.ark ark,t:ali1.txt
9. train_mono.sh 整体流程详解
整个脚本的思想就是:
1. gmm-init-mono 模型初始化
2. compile-train-graghs 训练图初始化
3. align-equal-compiled 特征文件均匀分割
4. gmm-acc-stats-ali 累积模型重估所需数据
5. gmm-sum-accs 并行数据合并
6. gmm-est 声音模型参数重估
7. gmm-boost-silence 模型平滑处理
8. gmm-align-compiled 特征重新对齐
9. 重复n次执行:7->8->4->5->6(重新对齐->参数重新估计)
10. 输出最终参数
#!/bin/bash
# Copyright 2012 Johns Hopkins University (Author: Daniel Povey)
# Apache 2.0
# To be run from ..
# Flat start and monophone training, with delta-delta features.
# This script applies cepstral mean normalization (per speaker).
# Begin configuration section.
nj=4
cmd=run.pl
scale_opts="--transition-scale=1.0 --acoustic-scale=0.1 --self-loop-scale=0.1"
num_iters=40 # Number of iterations of training 训练迭代次数
max_iter_inc=30 # Last iter to increase #Gauss on. 高斯数递增的最大次数
totgauss=1000 # Target #Gaussians.
careful=false
boost_silence=1.0 # Factor by which to boost silence likelihoods in alignment 强制改变某些音素的似然概率因子,见下面的代码
realign_iters="1 2 3 4 5 6 7 8 9 10 12 14 16 18 20 23 26 29 32 35 38";
config= # name of config file.
stage=-4
power=0.25 # exponent to determine number of gaussians from occurrence counts
norm_vars=false # deprecated, prefer --cmvn-opts "--norm-vars=false"
cmvn_opts= # can be used to add extra options to cmvn. cmvn选项
# End configuration section.
echo "$0 $@" # Print the command line for logging
if [ -f path.sh ]; then . ./path.sh; fi
. parse_options.sh || exit 1;
if [ $# != 3 ]; then
echo "Usage: steps/train_mono.sh [options] "
echo " e.g.: steps/train_mono.sh data/train.1k data/lang exp/mono"
echo "main options (for others, see top of script file)"
echo " --config # config containing options"
echo " --nj # number of parallel jobs"
echo " --cmd (utils/run.pl|utils/queue.pl ) # how to run jobs."
exit 1;
fi
data=$1
lang=$2
dir=$3
oov_sym=`cat $lang/oov.int` || exit 1;#静音符号表
# 按照任务数,将训练数据分成多份,每个任务处理一份数据。
mkdir -p $dir/log
echo $nj > $dir/num_jobs
sdata=$data/split$nj;
[[ -d $sdata && $data/feats.scp -ot $sdata ]] || split_data.sh $data $nj || exit 1;
# 特征归一化选项,这里默认指定要对variance进行归一化,还可从外部接收其他归一化选项,如果外部指定不对variance进行归一化,则外部指定生效。
$norm_vars && cmvn_opts="--norm-vars=true $cmvn_opts"
echo $cmvn_opts > $dir/cmvn_opts # keep track of options to CMVN.
feats="ark,s,cs:apply-cmvn $cmvn_opts --utt2spk=ark:$sdata/JOB/utt2spk scp:$sdata/JOB/cmvn.scp scp:$sdata/JOB/feats.scp ark:- | add-deltas ark:- ark:- |"
example_feats="`echo $feats | sed s/JOB/1/g`";
echo "$0: Initializing monophone system."
[ ! -f $lang/phones/sets.int ] && exit 1;
shared_phones_opt="--shared-phones=$lang/phones/sets.int"
if [ $stage -le -3 ]; then
# Note: JOB=1 just uses the 1st part of the features-- we only need a subset anyway.
# 获取特征的维度
if ! feat_dim=`feat-to-dim "$example_feats" - 2>/dev/null` || [ -z $feat_dim ]; then
feat-to-dim "$example_feats" -
echo "error getting feature dimension"
exit 1;
fi
# Flat-start(又称为快速启动),作用是利用少量的数据快速得到一个初始化的 HMM-GMM 模型和决策树
# $lang/topo 中定义了每个音素(phone)所对应的 HMM 模型状态数以及初始时的转移概率
# --shared-phones=$lang/phones/sets.int 选项指向的文件,即$lang/phones/sets.int(该文件生成roots.txt中开头为share split的部分,表示同一行元素共享pdf,允许进行决策树分裂),文件中同一行的音素(phone)共享 GMM 概率分布。tree文件由sets.int产生。
# --train-feats=$feats subset-feats --n=10 ark:- ark:-| 选项指定用来初始化训练用的特征,一般采用少量数据,程序内部会计算这批数据的means和variance,作为初始高斯模型。sets.int中所有行的初始pdf都用这个计算出来的means和variance进行初始化。
$cmd JOB=1 $dir/log/init.log \
gmm-init-mono $shared_phones_opt "--train-feats=$feats subset-feats --n=10 ark:- ark:-|" $lang/topo $feat_dim \
$dir/0.mdl $dir/tree || exit 1;
fi
# 计算当前高斯数,(目标高斯数 - 当前高斯数)/ 增加高斯迭代次数 得到每次迭代需要增加的高斯数目
numgauss=`gmm-info --print-args=false $dir/0.mdl | grep gaussians | awk '{print $NF}'`
incgauss=$[($totgauss-$numgauss)/$max_iter_inc] # per-iter increment for #Gauss
# 构造训练的网络,从源码级别分析,是每个句子构造一个phone level 的fst网络。
# $sdaba/JOB/text 中包含对每个句子的单词(words level)级别标注, L.fst是字典对于的fst表示,作用是将一串的音素(phones)转换成单词(words)
# 构造monophone解码图就是先将text中的每个句子,生成一个fst(类似于语言模型中的G.fst,只是相对比较简单,只有一个句子),然后和L.fst 进行composition 形成训练用的音素级别(phone level)fst网络(类似于LG.fst)。
# fsts.JOB.gz 中使用 key-value 的方式保存每个句子和其对应的fst网络,通过 key(句子) 就能找到这个句子的fst网络,value中保存的是句子中每两个音素之间互联的边(Arc),例如句子转换成音素后,标注为:"a b c d e f",那么value中保存的其实是 a->b b->c c->d d->e e->f 这些连接(kaldi会为每种连接赋予一个唯一的id),后面进行 HMM 训练的时候是根据这些连接的id进行计数,就可以得到转移概率。
if [ $stage -le -2 ]; then
echo "$0: Compiling training graphs"
$cmd JOB=1:$nj $dir/log/compile_graphs.JOB.log \
compile-train-graphs $dir/tree $dir/0.mdl $lang/L.fst \
"ark:sym2int.pl --map-oov $oov_sym -f 2- $lang/words.txt < $sdata/JOB/text|" \
"ark:|gzip -c >$dir/fsts.JOB.gz" || exit 1;
fi
if [ $stage -le -1 ]; then
echo "$0: Aligning data equally (pass 0)"
$cmd JOB=1:$nj $dir/log/align.0.JOB.log \
# 训练时需要将标注跟每一帧特征进行对齐,由于现在还没有可以用于对齐的模型,所以采用最简单的方法 -- 均匀对齐
# 根据标注数目对特征序列进行等间隔切分,例如一个具有5个标注的长度为100帧的特征序列,则认为1-20帧属于第1个标注,21-40属于第2个...
# 这种划分方法虽然会有误差,但待会在训练模型的过程中会不断地重新对齐。
align-equal-compiled "ark:gunzip -c $dir/fsts.JOB.gz|" "$feats" ark,t:- \| \
# 对对齐后的数据进行训练,获得中间统计量,每个任务输出到一个acc文件。
# acc中记录跟HMM 和GMM 训练相关的统计量:
# HMM 相关的统计量:两个音素之间互联的边(Arc) 出现的次数。
# 如上面所述,fst.JOB.gz 中每个key对于的value保存一个句子中音素两两之间互联的边。
# gmm-acc-stats-ali 会统计每条边(例如a->b)出现的次数,然后记录到acc文件中。
# GMM 相关的统计量:每个pdf-id 对应的特征累计值和特征平方累计值。
# 对于每一帧,都会有个对齐后的标注,gmm-acc-stats-ali 可以根据标注检索得到pdf-id,
# 每个pdf-id 对应的GMM可能由多个单高斯Component组成,会先计算在每个单高斯Component对应的分布下这一帧特征的似然概率(log-likes),称为posterior。
# 然后:
# (1)把每个单高斯Component的posterior加到每个高斯Component的occupancy(占有率)计数器上,用于表征特征对于高斯的贡献度,
# 如果特征一直落在某个高斯的分布区间内,那对应的这个值就比较大;相反,如果一直落在区间外,则表示该高斯作用不大。
# gmm-est中可以设置一个阈值,如果某个高斯的这个值低于阈值,则不更新其对应的高斯。
# 另外这个值(向量)其实跟后面GMM更新时候的高斯权重weight的计算相关。
# (2)把这一帧数据加上每个单高斯Component的posterior再加到每个高斯的均值累计值上;
# 这个值(向量)跟后面GMM的均值更新相关。
# (3)把这一帧数据的平方值加上posterior再加到每个单高斯Component的平方累计值上;
# 这个值(向量)跟后面GMM的方差更新相关。
# 最后将均值累计值和平方累计值写入到文件中。
gmm-acc-stats-ali --binary=true $dir/0.mdl "$feats" ark:- \
$dir/0.JOB.acc || exit 1;
fi
# In the following steps, the --min-gaussian-occupancy=3 option is important, otherwise
# we fail to est "rare" phones and later on, they never align properly.
# 根据上面得到的统计量,更新每个GMM模型,AccumDiagGmm中occupancy_的值决定混合高斯模型中每个单高斯Component的weight;
# --min-gaussian-occupancy 的作用是设置occupancy_的阈值,如果某个单高斯Component的occupancy_低于这个阈值,那么就不会更新这个高斯,
# 而且如果 --remove-low-count-gaussians=true,则对应得单高斯Component会被移除。
if [ $stage -le 0 ]; then
gmm-est --min-gaussian-occupancy=3 --mix-up=$numgauss --power=$power \
$dir/0.mdl "gmm-sum-accs - $dir/0.*.acc|" $dir/1.mdl 2> $dir/log/update.0.log || exit 1;
rm $dir/0.*.acc
fi
beam=6 # will change to 10 below after 1st pass
# note: using slightly wider beams for WSJ vs. RM.
x=1
while [ $x -lt $num_iters ]; do
echo "$0: Pass $x"
if [ $stage -le $x ]; then
if echo $realign_iters | grep -w $x >/dev/null; then
echo "$0: Aligning data"
# gmm-boost-silence 的作用是让某些phones(由第一个参数指定)对应pdf的weight乘以--boost 参数所指定的数字,强行提高(如果大于1)/降低(如果小于1)这个phone的概率。
# 如果多个phone共享同一个pdf,程序中会自动做去重,乘法操作只会执行一次。
mdl="gmm-boost-silence --boost=$boost_silence `cat $lang/phones/optional_silence.csl` $dir/$x.mdl - |"
# 执行force-alignment操作。
# --self-loop-scale 和 --transition-scale 选项跟HMM 状态跳转相关,前者是设置自转因子,后者是非自传因子,可以修改这两个选项控制HMM的跳转倾向。
# --acoustic-scale 选项跟GMM输出概率相关,用于平衡 GMM 输出概率和 HMM 跳转概率的重要性。
# --beam 选项用于计算对解码过程中出现较低log-likelihood的token进行裁剪的阈值,该值设计的越小,大部分token会被裁剪以便提高解码速度,但可能会在开始阶段把正确的token裁剪掉导致无法得到正确的解码路径。
# --retry-beam 选项用于修正上述的问题,当无法得到正确的解码路径后,会增加beam的值,如果找到了最佳解码路径则退出,否则一直增加指定该选项设置的值,如果还没找到,就抛出警告,导致这种问题要么是标注本来就不对,或者retry-beam也设计得太小。
$cmd JOB=1:$nj $dir/log/align.$x.JOB.log \
gmm-align-compiled $scale_opts --beam=$beam --retry-beam=$[$beam*4] --careful=$careful "$mdl" \
"ark:gunzip -c $dir/fsts.JOB.gz|" "$feats" "ark,t:|gzip -c >$dir/ali.JOB.gz" \
|| exit 1;
fi
# 更新模型
$cmd JOB=1:$nj $dir/log/acc.$x.JOB.log \
gmm-acc-stats-ali $dir/$x.mdl "$feats" "ark:gunzip -c $dir/ali.JOB.gz|" \
$dir/$x.JOB.acc || exit 1;
$cmd $dir/log/update.$x.log \
gmm-est --write-occs=$dir/$[$x+1].occs --mix-up=$numgauss --power=$power $dir/$x.mdl \
"gmm-sum-accs - $dir/$x.*.acc|" $dir/$[$x+1].mdl || exit 1;
rm $dir/$x.mdl $dir/$x.*.acc $dir/$x.occs 2>/dev/null
fi
# 线性增加混合高斯模型的数目,直到指定数量。
if [ $x -le $max_iter_inc ]; then
numgauss=$[$numgauss+$incgauss];
fi
# 提高裁剪门限。
beam=10
x=$[$x+1]
done
( cd $dir; rm final.{mdl,occs} 2>/dev/null; ln -s $x.mdl final.mdl; ln -s $x.occs final.occs )
utils/summarize_warnings.pl $dir/log
echo Done
# example of showing the alignments:
# show-alignments data/lang/phones.txt $dir/30.mdl "ark:gunzip -c $dir/ali.0.gz|" | head -4
大部分内容参考如下:
心胸决定格局…:Kaldi单音素模型 训练部分
转载请注明出处