语音识别——基于深度学习的中文语音识别tutorial(代码实践)
文章目录
- 利用thchs30为例建立一个语音识别系统
- 1. 特征提取
- 2. 数据处理
- 下载数据
- 2.1 生成音频文件和标签文件列表
- 定义函数`source_get`,获取音频文件及标注文件列表
- 确认相同id对应的音频文件和标签文件相同
- 2.2 label数据处理
- 定义函数`read_label`读取音频文件对应的拼音label
- 为label建立拼音到id的映射,即词典
- 有了词典就能将读取到的label映射到对应的id
- 总结:
- 2.3 音频数据处理
- 由于声学模型网络结构原因(3个maxpooling层),我们的音频数据的每个维度需要能够被8整除。
- 总结:
- 2.4 数据生成器
- 确定batch_size和batch_num
- shuffle
- generator
- padding
- 3. 模型搭建
- 3.1 构建模型组件
- 3.2 搭建cnn+dnn+ctc的声学模型
- 4. 模型训练及推断
- 4.1 模型训练
- 4.2 模型推断
利用thchs30为例建立一个语音识别系统
- 数据处理
- 搭建模型
- DFCNN
论文地址:http://xueshu.baidu.com/usercenter/paper/show?paperid=be5348048dd263aced0f2bdc75a535e8&site=xueshu_se
代码地址:https://github.com/audier/my_ch_speech_recognition/tree/master/tutorial
语言模型代码实践tutorial也有啦:
基于CBHG结构:https://blog.csdn.net/chinatelecom08/article/details/85048019
基于自注意力机制:https://blog.csdn.net/chinatelecom08/article/details/85051817
1. 特征提取
input为输入音频数据,需要转化为频谱图数据,然后通过cnn处理图片的能力进行识别。
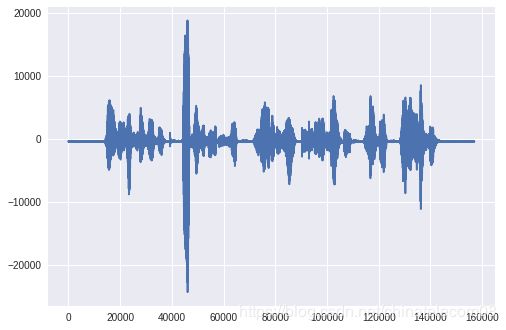
1. 读取音频文件
import scipy.io.wavfile as wav
import matplotlib.pyplot as plt
import os
# 随意搞个音频做实验
filepath = 'test.wav'
fs, wavsignal = wav.read(filepath)
plt.plot(wavsignal)
plt.show()
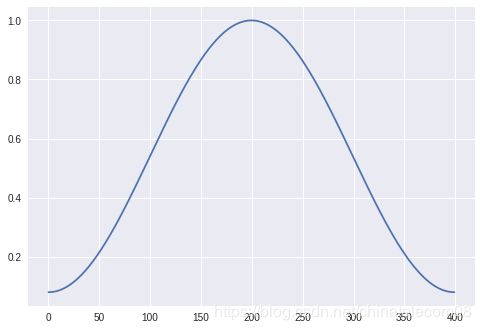
2. 构造汉明窗
import numpy as np
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1))
plt.plot(w)
plt.show()
3. 对数据分帧
- 帧长: 25ms
- 帧移: 10ms
采样点(s) = fs
采样点(ms)= fs / 1000
采样点(帧)= fs / 1000 * 帧长
time_window = 25
window_length = fs // 1000 * time_window
4. 分帧加窗
# 分帧
p_begin = 0
p_end = p_begin + window_length
frame = wavsignal[p_begin:p_end]
plt.plot(frame)
plt.show()
# 加窗
frame = frame * w
plt.plot(frame)
plt.show()
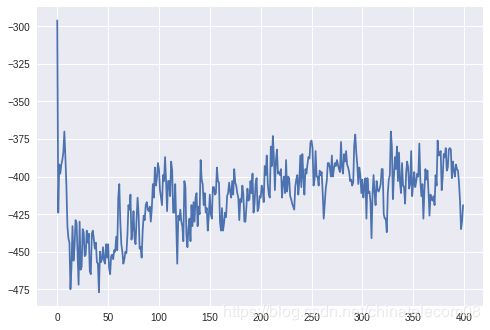
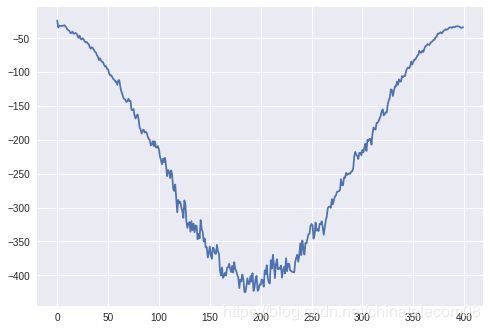
5. 傅里叶变换
所谓时频图就是将时域信息转换到频域上去,具体原理可百度。人耳感知声音是通过
from scipy.fftpack import fft
# 进行快速傅里叶变换
frame_fft = np.abs(fft(frame))[:200]
plt.plot(frame_fft)
plt.show()
# 取对数,求db
frame_log = np.log(frame_fft)
plt.plot(frame_log)
plt.show()
- 分帧
- 加窗
- 傅里叶变换
import numpy as np
import scipy.io.wavfile as wav
from scipy.fftpack import fft
# 获取信号的时频图
def compute_fbank(file):
x=np.linspace(0, 400 - 1, 400, dtype = np.int64)
w = 0.54 - 0.46 * np.cos(2 * np.pi * (x) / (400 - 1) ) # 汉明窗
fs, wavsignal = wav.read(file)
# wav波形 加时间窗以及时移10ms
time_window = 25 # 单位ms
window_length = fs / 1000 * time_window # 计算窗长度的公式,目前全部为400固定值
wav_arr = np.array(wavsignal)
wav_length = len(wavsignal)
range0_end = int(len(wavsignal)/fs*1000 - time_window) // 10 # 计算循环终止的位置,也就是最终生成的窗数
data_input = np.zeros((range0_end, 200), dtype = np.float) # 用于存放最终的频率特征数据
data_line = np.zeros((1, 400), dtype = np.float)
for i in range(0, range0_end):
p_start = i * 160
p_end = p_start + 400
data_line = wav_arr[p_start:p_end]
data_line = data_line * w # 加窗
data_line = np.abs(fft(data_line))
data_input[i]=data_line[0:200] # 设置为400除以2的值(即200)是取一半数据,因为是对称的
data_input = np.log(data_input + 1)
#data_input = data_input[::]
return data_input
- 该函数提取音频文件的时频图
import matplotlib.pyplot as plt
filepath = 'test.wav'
a = compute_fbank(filepath)
plt.imshow(a.T, origin = 'lower')
plt.show()

2. 数据处理
下载数据
thchs30: http://www.openslr.org/18/
2.1 生成音频文件和标签文件列表
考虑神经网络训练过程中接收的输入输出。首先需要batch_size内数据需要统一数据的shape。
格式为:[batch_size, time_step, feature_dim]
然而读取的每一个sample的时间轴长都不一样,所以需要对时间轴进行处理,选择batch内最长的那个时间为基准,进行padding。这样一个batch内的数据都相同,就能进行并行训练啦。
source_file = 'data_thchs30'
定义函数source_get,获取音频文件及标注文件列表
形如:
E:\Data\thchs30\data_thchs30\data\A11_0.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_1.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_10.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_100.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_102.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_103.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_104.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_105.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_106.wav.trn
E:\Data\thchs30\data_thchs30\data\A11_107.wav.trn
def source_get(source_file):
train_file = source_file + '/data'
label_lst = []
wav_lst = []
for root, dirs, files in os.walk(train_file):
for file in files:
if file.endswith('.wav') or file.endswith('.WAV'):
wav_file = os.sep.join([root, file])
label_file = wav_file + '.trn'
wav_lst.append(wav_file)
label_lst.append(label_file)
return label_lst, wav_lst
label_lst, wav_lst = source_get(source_file)
print(label_lst[:10])
print(wav_lst[:10])
['data_thchs30/data/A23_73.wav.trn', 'data_thchs30/data/C4_681.wav.trn', 'data_thchs30/data/D12_793.wav.trn', 'data_thchs30/data/A19_137.wav.trn', 'data_thchs30/data/D11_898.wav.trn', 'data_thchs30/data/B33_491.wav.trn', 'data_thchs30/data/C7_546.wav.trn', 'data_thchs30/data/C32_671.wav.trn', 'data_thchs30/data/D32_817.wav.trn', 'data_thchs30/data/A32_115.wav.trn']
['data_thchs30/data/A23_73.wav', 'data_thchs30/data/C4_681.wav', 'data_thchs30/data/D12_793.wav', 'data_thchs30/data/A19_137.wav', 'data_thchs30/data/D11_898.wav', 'data_thchs30/data/B33_491.wav', 'data_thchs30/data/C7_546.wav', 'data_thchs30/data/C32_671.wav', 'data_thchs30/data/D32_817.wav', 'data_thchs30/data/A32_115.wav']
确认相同id对应的音频文件和标签文件相同
for i in range(10000):
wavname = (wav_lst[i].split('/')[-1]).split('.')[0]
labelname = (label_lst[i].split('/')[-1]).split('.')[0]
if wavname != labelname:
print('error')
2.2 label数据处理
定义函数read_label读取音频文件对应的拼音label
def read_label(label_file):
with open(label_file, 'r', encoding='utf8') as f:
data = f.readlines()
return data[1]
print(read_label(label_lst[0]))
def gen_label_data(label_lst):
label_data = []
for label_file in label_lst:
pny = read_label(label_file)
label_data.append(pny.strip('\n'))
return label_data
label_data = gen_label_data(label_lst)
print(len(label_data))
zhe4 ci4 quan2 guo2 qing1 nian2 pai2 qiu2 lian2 sai4 gong4 she4 tian1 jin1 zhou1 shan1 wu3 han4 san1 ge5 sai4 qu1 mei3 ge5 sai4 qu1 de5 qian2 liang3 ming2 jiang4 can1 jia1 fu4 sai4
13388
为label建立拼音到id的映射,即词典
def mk_vocab(label_data):
vocab = []
for line in label_data:
line = line.split(' ')
for pny in line:
if pny not in vocab:
vocab.append(pny)
vocab.append('_')
return vocab
vocab = mk_vocab(label_data)
print(len(vocab))
1209
有了词典就能将读取到的label映射到对应的id
def word2id(line, vocab):
return [vocab.index(pny) for pny in line.split(' ')]
label_id = word2id(label_data[0], vocab)
print(label_data[0])
print(label_id)
zhe4 ci4 quan2 guo2 qing1 nian2 pai2 qiu2 lian2 sai4 gong4 she4 tian1 jin1 zhou1 shan1 wu3 han4 san1 ge5 sai4 qu1 mei3 ge5 sai4 qu1 de5 qian2 liang3 ming2 jiang4 can1 jia1 fu4 sai4
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 9, 20, 21, 19, 9, 20, 22, 23, 24, 25, 26, 27, 28, 29, 9]
总结:
我们提取出了每个音频文件对应的拼音标签label_data,通过索引就可以获得该索引的标签。
也生成了对应的拼音词典.由此词典,我们可以映射拼音标签为id序列。
输出:
- vocab
- label_data
print(vocab[:15])
print(label_data[10])
print(word2id(label_data[10], vocab))
['zhe4', 'ci4', 'quan2', 'guo2', 'qing1', 'nian2', 'pai2', 'qiu2', 'lian2', 'sai4', 'gong4', 'she4', 'tian1', 'jin1', 'zhou1']
can1 jin1 shi4 ca1 zui3 he2 shou2 zhi3 de5 bei1 bian1 qing3 yong4 can1 zhi3 ca1 shi4 lian3 shang4 de5 han4 huo4 zhan1 shang5 de5 shui3 zhi1 qing3 yong4 zi4 ji3 de5 shou3 juan4 ca1 diao4
[27, 13, 199, 200, 201, 63, 202, 203, 22, 204, 205, 206, 207, 27, 203, 200, 199, 208, 120, 22, 17, 209, 210, 211, 22, 31, 212, 206, 207, 213, 214, 22, 215, 216, 200, 217]
2.3 音频数据处理
音频数据处理,只需要获得对应的音频文件名,然后提取所需时频图即可。
其中compute_fbank时频转化的函数在前面已经定义好了。
fbank = compute_fbank(wav_lst[0])
print(fbank.shape)
(1026, 200)
plt.imshow(fbank.T, origin = 'lower')
plt.show()

由于声学模型网络结构原因(3个maxpooling层),我们的音频数据的每个维度需要能够被8整除。
fbank = fbank[:fbank.shape[0]//8*8, :]
print(fbank.shape)
(1024, 200)
总结:
- 对音频数据进行时频转换
- 转换后的数据需要各个维度能够被8整除
2.4 数据生成器
确定batch_size和batch_num
total_nums = 10000
batch_size = 4
batch_num = total_nums // batch_size
shuffle
打乱数据的顺序,我们通过查询乱序的索引值,来确定训练数据的顺序
from random import shuffle
shuffle_list = [i for i in range(10000)]
shuffle(shuffle_list)
generator
batch_size的信号时频图和标签数据,存放到两个list中去
def get_batch(batch_size, shuffle_list, wav_lst, label_data, vocab):
for i in range(10000//batch_size):
wav_data_lst = []
label_data_lst = []
begin = i * batch_size
end = begin + batch_size
sub_list = shuffle_list[begin:end]
for index in sub_list:
fbank = compute_fbank(wav_lst[index])
fbank = fbank[:fbank.shape[0] // 8 * 8, :]
label = word2id(label_data[index], vocab)
wav_data_lst.append(fbank)
label_data_lst.append(label)
yield wav_data_lst, label_data_lst
batch = get_batch(4, shuffle_list, wav_lst, label_data, vocab)
wav_data_lst, label_data_lst = next(batch)
for wav_data in wav_data_lst:
print(wav_data.shape)
for label_data in label_data_lst:
print(label_data)
(1272, 200)
(792, 200)
(872, 200)
(928, 200)
[27, 13, 199, 200, 201, 63, 202, 203, 22, 204, 205, 206, 207, 27, 203, 200, 199, 208, 120, 22, 17, 209, 210, 211, 22, 31, 212, 206, 207, 213, 214, 22, 215, 216, 200, 217]
[731, 5, 353, 301, 344, 41, 36, 212, 250, 103, 246, 199, 22, 766, 16, 380, 243, 411, 420, 9, 206, 259, 435, 244, 249, 113, 245, 344, 41, 188, 70]
[0, 674, 444, 316, 20, 22, 103, 117, 199, 392, 376, 512, 519, 118, 438, 22, 328, 308, 58, 63, 1065, 198, 624, 472, 232, 159, 163, 199, 392, 376, 512, 519, 173, 22]
[39, 51, 393, 471, 537, 198, 58, 535, 632, 100, 655, 63, 226, 488, 69, 376, 190, 409, 8, 349, 242, 93, 305, 1012, 369, 172, 166, 58, 156, 305, 179, 274, 44, 435]
lens = [len(wav) for wav in wav_data_lst]
print(max(lens))
print(lens)
1272
[1272, 792, 872, 928]
padding
然而,每一个batch_size内的数据有一个要求,就是需要构成成一个tensorflow块,这就要求每个样本数据形式是一样的。
除此之外,ctc需要获得的信息还有输入序列的长度。
这里输入序列经过卷积网络后,长度缩短了8倍,因此我们训练实际输入的数据为wav_len//8。
- padding wav data
- wav len // 8 (网络结构导致的)
def wav_padding(wav_data_lst):
wav_lens = [len(data) for data in wav_data_lst]
wav_max_len = max(wav_lens)
wav_lens = np.array([leng//8 for leng in wav_lens])
new_wav_data_lst = np.zeros((len(wav_data_lst), wav_max_len, 200, 1))
for i in range(len(wav_data_lst)):
new_wav_data_lst[i, :wav_data_lst[i].shape[0], :, 0] = wav_data_lst[i]
return new_wav_data_lst, wav_lens
pad_wav_data_lst, wav_lens = wav_padding(wav_data_lst)
print(pad_wav_data_lst.shape)
print(wav_lens)
(4, 1272, 200, 1)
[159 99 109 116]
同样也要对label进行padding和长度获取,不同的是数据维度不同,且label的长度就是输入给ctc的长度,不需要额外处理
- label padding
- label len
def label_padding(label_data_lst):
label_lens = np.array([len(label) for label in label_data_lst])
max_label_len = max(label_lens)
new_label_data_lst = np.zeros((len(label_data_lst), max_label_len))
for i in range(len(label_data_lst)):
new_label_data_lst[i][:len(label_data_lst[i])] = label_data_lst[i]
return new_label_data_lst, label_lens
pad_label_data_lst, label_lens = label_padding(label_data_lst)
print(pad_label_data_lst.shape)
print(label_lens)
(4, 36)
[36 31 34 34]
- 用于训练格式的数据生成器
def data_generator(batch_size, shuffle_list, wav_lst, label_data, vocab):
for i in range(len(wav_lst)//batch_size):
wav_data_lst = []
label_data_lst = []
begin = i * batch_size
end = begin + batch_size
sub_list = shuffle_list[begin:end]
for index in sub_list:
fbank = compute_fbank(wav_lst[index])
pad_fbank = np.zeros((fbank.shape[0]//8*8+8, fbank.shape[1]))
pad_fbank[:fbank.shape[0], :] = fbank
label = word2id(label_data[index], vocab)
wav_data_lst.append(pad_fbank)
label_data_lst.append(label)
pad_wav_data, input_length = wav_padding(wav_data_lst)
pad_label_data, label_length = label_padding(label_data_lst)
inputs = {'the_inputs': pad_wav_data,
'the_labels': pad_label_data,
'input_length': input_length,
'label_length': label_length,
}
outputs = {'ctc': np.zeros(pad_wav_data.shape[0],)}
yield inputs, outputs
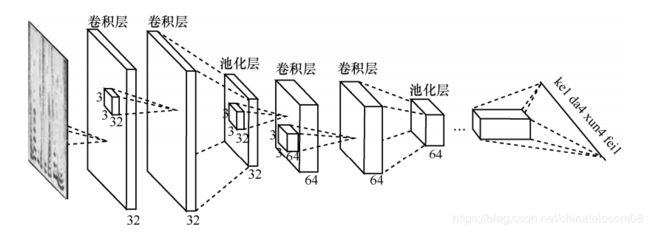
3. 模型搭建
训练输入为时频图,标签为对应的拼音标签,如下所示:
搭建语音识别模型,采用了 CNN+CTC 的结构。
import keras
from keras.layers import Input, Conv2D, BatchNormalization, MaxPooling2D
from keras.layers import Reshape, Dense, Lambda
from keras.optimizers import Adam
from keras import backend as K
from keras.models import Model
from keras.utils import multi_gpu_model
Using TensorFlow backend.
3.1 构建模型组件
- 定义3*3的卷积层
def conv2d(size):
return Conv2D(size, (3,3), use_bias=True, activation='relu',
padding='same', kernel_initializer='he_normal')
- 定义batch norm层
def norm(x):
return BatchNormalization(axis=-1)(x)
- 定义最大池化层,数据的后两维维度都减半
def maxpool(x):
return MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(x)
- dense层
def dense(units, activation="relu"):
return Dense(units, activation=activation, use_bias=True,
kernel_initializer='he_normal')
- 由cnn + cnn + maxpool构成的组合
# x.shape=(none, none, none)
# output.shape = (1/2, 1/2, 1/2)
def cnn_cell(size, x, pool=True):
x = norm(conv2d(size)(x))
x = norm(conv2d(size)(x))
if pool:
x = maxpool(x)
return x
- 添加CTC损失函数,由backend引入
注意:CTC_batch_cost输入为:
- labels 标签:[batch_size, l]
- y_pred cnn网络的输出:[batch_size, t, vocab_size]
- input_length 网络输出的长度:[batch_size]
- label_length 标签的长度:[batch_size]
def ctc_lambda(args):
labels, y_pred, input_length, label_length = args
y_pred = y_pred[:, :, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
3.2 搭建cnn+dnn+ctc的声学模型
class Amodel():
"""docstring for Amodel."""
def __init__(self, vocab_size):
super(Amodel, self).__init__()
self.vocab_size = vocab_size
self._model_init()
self._ctc_init()
self.opt_init()
def _model_init(self):
self.inputs = Input(name='the_inputs', shape=(None, 200, 1))
self.h1 = cnn_cell(32, self.inputs)
self.h2 = cnn_cell(64, self.h1)
self.h3 = cnn_cell(128, self.h2)
self.h4 = cnn_cell(128, self.h3, pool=False)
# 200 / 8 * 128 = 3200
self.h6 = Reshape((-1, 3200))(self.h4)
self.h7 = dense(256)(self.h6)
self.outputs = dense(self.vocab_size, activation='softmax')(self.h7)
self.model = Model(inputs=self.inputs, outputs=self.outputs)
def _ctc_init(self):
self.labels = Input(name='the_labels', shape=[None], dtype='float32')
self.input_length = Input(name='input_length', shape=[1], dtype='int64')
self.label_length = Input(name='label_length', shape=[1], dtype='int64')
self.loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')\
([self.labels, self.outputs, self.input_length, self.label_length])
self.ctc_model = Model(inputs=[self.labels, self.inputs,
self.input_length, self.label_length], outputs=self.loss_out)
def opt_init(self):
opt = Adam(lr = 0.0008, beta_1 = 0.9, beta_2 = 0.999, decay = 0.01, epsilon = 10e-8)
#self.ctc_model=multi_gpu_model(self.ctc_model,gpus=2)
self.ctc_model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=opt)
am = Amodel(1176)
am.ctc_model.summary()
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
the_inputs (InputLayer) (None, None, 200, 1) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, None, 200, 32 320 the_inputs[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, None, 200, 32 128 conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, None, 200, 32 9248 batch_normalization_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, None, 200, 32 128 conv2d_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, None, 100, 32 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, None, 100, 64 18496 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, None, 100, 64 256 conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, None, 100, 64 36928 batch_normalization_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, None, 100, 64 256 conv2d_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, None, 50, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, None, 50, 128 73856 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, None, 50, 128 512 conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, None, 50, 128 147584 batch_normalization_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, None, 50, 128 512 conv2d_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, None, 25, 128 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, None, 25, 128 147584 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, None, 25, 128 512 conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, None, 25, 128 147584 batch_normalization_7[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, None, 25, 128 512 conv2d_8[0][0]
__________________________________________________________________________________________________
reshape_1 (Reshape) (None, None, 3200) 0 batch_normalization_8[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, None, 256) 819456 reshape_1[0][0]
__________________________________________________________________________________________________
the_labels (InputLayer) (None, None) 0
__________________________________________________________________________________________________
dense_2 (Dense) (None, None, 1176) 302232 dense_1[0][0]
__________________________________________________________________________________________________
input_length (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
label_length (InputLayer) (None, 1) 0
__________________________________________________________________________________________________
ctc (Lambda) (None, 1) 0 the_labels[0][0]
dense_2[0][0]
input_length[0][0]
label_length[0][0]
==================================================================================================
Total params: 1,706,104
Trainable params: 1,704,696
Non-trainable params: 1,408
__________________________________________________________________________________________________
4. 模型训练及推断
4.1 模型训练
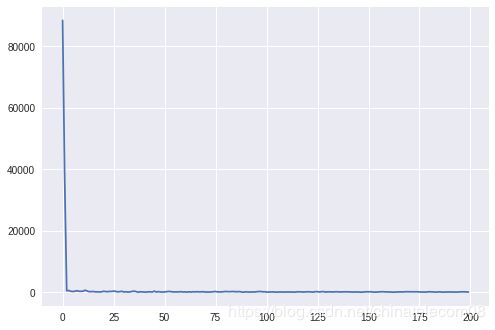
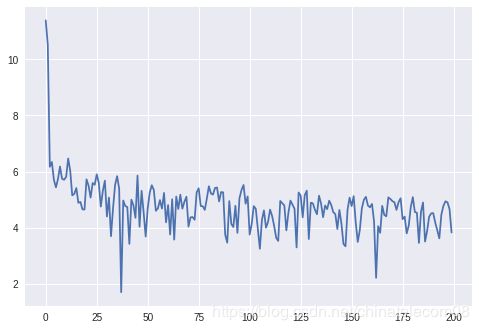
这样训练所需的数据,就准备完毕了,接下来可以进行训练了。我们采用如下参数训练:
-
batch_size = 4
-
batch_num = 10000 // 4
-
epochs = 1
-
准备训练数据,shuffle是为了打乱训练数据顺序
total_nums = 100
batch_size = 20
batch_num = total_nums // batch_size
epochs = 50
source_file = 'data_thchs30'
label_lst, wav_lst = source_get(source_file)
label_data = gen_label_data(label_lst[:100])
vocab = mk_vocab(label_data)
vocab_size = len(vocab)
print(vocab_size)
shuffle_list = [i for i in range(100)]
716
-
使用fit_generator
-
开始训练
am = Amodel(vocab_size)
for k in range(epochs):
print('this is the', k+1, 'th epochs trainning !!!')
#shuffle(shuffle_list)
batch = data_generator(batch_size, shuffle_list, wav_lst, label_data, vocab)
am.ctc_model.fit_generator(batch, steps_per_epoch=batch_num, epochs=1)
this is the 1 th epochs trainning !!!
Epoch 1/1
5/5 [==============================] - 30s 6s/step - loss: 422.8893
this is the 2 th epochs trainning !!!
.....
5/5 [==============================] - 7s 1s/step - loss: 0.4708
this is the 50 th epochs trainning !!!
Epoch 1/1
5/5 [==============================] - 7s 1s/step - loss: 0.4580
4.2 模型推断
- 解码器
def decode_ctc(num_result, num2word):
result = num_result[:, :, :]
in_len = np.zeros((1), dtype = np.int32)
in_len[0] = result.shape[1];
r = K.ctc_decode(result, in_len, greedy = True, beam_width=10, top_paths=1)
r1 = K.get_value(r[0][0])
r1 = r1[0]
text = []
for i in r1:
text.append(num2word[i])
return r1, text
- 模型识别结果解码
# 测试模型 predict(x, batch_size=None, verbose=0, steps=None)
batch = data_generator(1, shuffle_list, wav_lst, label_data, vocab)
for i in range(10):
# 载入训练好的模型,并进行识别
inputs, outputs = next(batch)
x = inputs['the_inputs']
y = inputs['the_labels'][0]
result = am.model.predict(x, steps=1)
# 将数字结果转化为文本结果
result, text = decode_ctc(result, vocab)
print('数字结果: ', result)
print('文本结果:', text)
print('原文结果:', [vocab[int(i)] for i in y])
数字结果: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 9 20 21 19
9 20 22 23 24 25 26 27 28 29 9]
文本结果: ['zhe4', 'ci4', 'quan2', 'guo2', 'qing1', 'nian2', 'pai2', 'qiu2', 'lian2', 'sai4', 'gong4', 'she4', 'tian1', 'jin1', 'zhou1', 'shan1', 'wu3', 'han4', 'san1', 'ge5', 'sai4', 'qu1', 'mei3', 'ge5', 'sai4', 'qu1', 'de5', 'qian2', 'liang3', 'ming2', 'jiang4', 'can1', 'jia1', 'fu4', 'sai4']
原文结果: ['zhe4', 'ci4', 'quan2', 'guo2', 'qing1', 'nian2', 'pai2', 'qiu2', 'lian2', 'sai4', 'gong4', 'she4', 'tian1', 'jin1', 'zhou1', 'shan1', 'wu3', 'han4', 'san1', 'ge5', 'sai4', 'qu1', 'mei3', 'ge5', 'sai4', 'qu1', 'de5', 'qian2', 'liang3', 'ming2', 'jiang4', 'can1', 'jia1', 'fu4', 'sai4']
数字结果: [30 31 32 33 34 35 36 32 37 38 39 40 41 22 15 42 43 44 41 45 46 47 48 3
39 49 50 51 52 42 53 54]
文本结果: ['xian1', 'shui3', 'yan2', 'zhi4', 'fei1', 'ma2', 'zu3', 'yan2', 'chang2', 'da2', 'shi2', 'hua2', 'li3', 'de5', 'shan1', 'ya2', 'dong4', 'xue2', 'li3', 'you3', 'chun1', 'qiu1', 'zhan4', 'guo2', 'shi2', 'qi1', 'gu3', 'yue4', 'zu2', 'ya2', 'mu4', 'qun2']
原文结果: ['xian1', 'shui3', 'yan2', 'zhi4', 'fei1', 'ma2', 'zu3', 'yan2', 'chang2', 'da2', 'shi2', 'hua2', 'li3', 'de5', 'shan1', 'ya2', 'dong4', 'xue2', 'li3', 'you3', 'chun1', 'qiu1', 'zhan4', 'guo2', 'shi2', 'qi1', 'gu3', 'yue4', 'zu2', 'ya2', 'mu4', 'qun2']
数字结果: [55 56 57 11 58 18 59 60 22 61 62 63 64 62 65 66 57 11 58 67 18 59 60 68
32 69 70 22 0 71 72 32 73 74 22 76]
文本结果: ['wo3', 'men5', 'pai1', 'she4', 'le5', 'san1', 'wang4', 'chong1', 'de5', 'yuan3', 'jing3', 'he2', 'jin4', 'jing3', 'te4', 'bie2', 'pai1', 'she4', 'le5', 'cong2', 'san1', 'wang4', 'chong1', 'shen1', 'yan2', 'er2', 'chu1', 'de5', 'zhe4', 'tiao2', 'wan1', 'yan2', 'ni2', 'ning4', 'de5', 'lu4']
原文结果: ['wo3', 'men5', 'pai1', 'she4', 'le5', 'san1', 'wang4', 'chong1', 'de5', 'yuan3', 'jing3', 'he2', 'jin4', 'jing3', 'te4', 'bie2', 'pai1', 'she4', 'le5', 'cong2', 'san1', 'wang4', 'chong1', 'shen1', 'yan2', 'er2', 'chu1', 'de5', 'zhe4', 'tiao2', 'wan1', 'yan2', 'ni2', 'ning4', 'de5', 'xiao3', 'lu4']
数字结果: [77 78 79 80 81 82 83 82 84 79 83 79 84 82 82 80 85 79 79 82 10 86]
文本结果: ['bu2', 'qi4', 'ya3', 'bu4', 'bi4', 'su2', 'hua4', 'su2', 'wei2', 'ya3', 'hua4', 'ya3', 'wei2', 'su2', 'su2', 'bu4', 'shang1', 'ya3', 'ya3', 'su2', 'gong4', 'shang3']
原文结果: ['bu2', 'qi4', 'ya3', 'bu4', 'bi4', 'su2', 'hua4', 'su2', 'wei2', 'ya3', 'hua4', 'ya3', 'wei2', 'su2', 'su2', 'bu4', 'shang1', 'ya3', 'ya3', 'su2', 'gong4', 'shang3']
数字结果: [ 87 13 88 25 89 90 91 92 93 90 94 95 96 97 98 99 84 100
89 101 102 96 103 104 104 77 105 106 107 108 109 28 110 111]
文本结果: ['ru2', 'jin1', 'ta1', 'ming2', 'chuan2', 'si4', 'fang1', 'sheng1', 'bo1', 'si4', 'hai3', 'yang3', 'xie1', 'ji4', 'shu4', 'guang3', 'wei2', 'liu2', 'chuan2', 'you1', 'liang2', 'xie1', 'zhong3', 'yuan2', 'yuan2', 'bu2', 'duan4', 'shu1', 'song4', 'dao4', 'qian1', 'jia1', 'wan4', 'hu4']
原文结果: ['ru2', 'jin1', 'ta1', 'ming2', 'chuan2', 'si4', 'fang1', 'sheng1', 'bo1', 'si4', 'hai3', 'yang3', 'xie1', 'ji4', 'shu4', 'guang3', 'wei2', 'liu2', 'chuan2', 'you1', 'liang2', 'xie1', 'zhong3', 'yuan2', 'yuan2', 'bu2', 'duan4', 'shu1', 'song4', 'dao4', 'qian1', 'jia1', 'wan4', 'hu4']
数字结果: [112 113 114 28 22 115 116 117 118 119 108 20 120 121 122 123 58 124
125 126 127 128 129 130 130 131 132 133 88 134 11]
文本结果: ['yang2', 'dui4', 'zhang3', 'jia1', 'de5', 'er4', 'wa2', 'zi5', 'fa1', 'shao1', 'dao4', 'qu1', 'shang4', 'zhen2', 'suo3', 'kan4', 'le5', 'bing4', 'dai4', 'hui2', 'yi1', 'bao1', 'zhen1', 'yao4', 'yao4', 'yi4', 'qiong2', 'gei3', 'ta1', 'zhu4', 'she4']
原文结果: ['yang2', 'dui4', 'zhang3', 'jia1', 'de5', 'er4', 'wa2', 'zi5', 'fa1', 'shao1', 'dao4', 'qu1', 'shang4', 'zhen2', 'suo3', 'kan4', 'le5', 'bing4', 'dai4', 'hui2', 'yi1', 'bao1', 'zhen1', 'yao4', 'yao4', 'yi4', 'qiong2', 'gei3', 'ta1', 'zhu4', 'she4']
数字结果: [135 89 136 112 137 138 139 112 14 123 132 140 141 142 143 144 39 145
146 143 144 147 148 149 37 119 150 151 152 118 153 154]
文本结果: ['xiang1', 'chuan2', 'sui2', 'yang2', 'di4', 'nan2', 'xia4', 'yang2', 'zhou1', 'kan4', 'qiong2', 'hua1', 'tu2', 'jing1', 'huai2', 'yin1', 'shi2', 'wen2', 'de2', 'huai2', 'yin1', 'pao2', 'chu2', 'shan4', 'chang2', 'shao1', 'yu2', 'nai3', 'tu1', 'fa1', 'qi2', 'xiang3']
原文结果: ['xiang1', 'chuan2', 'sui2', 'yang2', 'di4', 'nan2', 'xia4', 'yang2', 'zhou1', 'kan4', 'qiong2', 'hua1', 'tu2', 'jing1', 'huai2', 'yin1', 'shi2', 'wen2', 'de2', 'huai2', 'yin1', 'pao2', 'chu2', 'shan4', 'chang2', 'shao1', 'yu2', 'nai3', 'tu1', 'fa1', 'qi2', 'xiang3']
数字结果: [ 87 63 155 156 157 69 158 159 22 33 160 107 161 162 163 155 70 58
164 165 51 22 166 167 168 169 170 171 172 173 171 106 174]
文本结果: ['ru2', 'he2', 'ti2', 'gao1', 'shao4', 'er2', 'du2', 'wu4', 'de5', 'zhi4', 'liang4', 'song4', 'qing4', 'ling2', 'ye3', 'ti2', 'chu1', 'le5', 'hen3', 'zhuo2', 'yue4', 'de5', 'jian4', 'jie3', 'na4', 'jiu4', 'shi5', 'zhua1', 'chuang4', 'zuo4', 'zhua1', 'shu1', 'gao3']
原文结果: ['ru2', 'he2', 'ti2', 'gao1', 'shao4', 'er2', 'du2', 'wu4', 'de5', 'zhi4', 'liang4', 'song4', 'qing4', 'ling2', 'ye3', 'ti2', 'chu1', 'le5', 'hen3', 'zhuo2', 'yue4', 'de5', 'jian4', 'jie3', 'na4', 'jiu4', 'shi5', 'zhua1', 'chuang4', 'zuo4', 'zhua1', 'shu1', 'gao3']
数字结果: [ 88 153 120 175 138 176 10 177 178 179 137 22 180 160 3 181 18 182
183 184 185 127 185 118 186 22 187 188 189 43 179 78]
文本结果: ['ta1', 'qi2', 'shang4', 'yun2', 'nan2', 'cheng2', 'gong4', 'xun4', 'lian4', 'ji1', 'di4', 'de5', 'yi2', 'liang4', 'guo2', 'chan3', 'san1', 'lun2', 'mo2', 'tuo2', 'rou2', 'yi1', 'rou2', 'fa1', 'hong2', 'de5', 'shuang1', 'yan3', 'qi3', 'dong4', 'ji1', 'qi4']
原文结果: ['ta1', 'qi2', 'shang4', 'yun2', 'nan2', 'cheng2', 'gong4', 'xun4', 'lian4', 'ji1', 'di4', 'de5', 'yi2', 'liang4', 'guo2', 'chan3', 'san1', 'lun2', 'mo2', 'tuo2', 'rou2', 'yi1', 'rou2', 'fa1', 'hong2', 'de5', 'shuang1', 'yan3', 'qi3', 'dong4', 'ji1', 'qi4']
数字结果: [190 75 5 173 83 22 65 191 192 193 194 153 83 195 20 66 150 145
196 83 63 5 83 197 198 79 82 10 86]
文本结果: ['ma3', 'xiao3', 'nian2', 'zuo4', 'hua4', 'de5', 'te4', 'zheng1', 'yu3', 'shen2', 'yun4', 'qi2', 'hua4', 'feng1', 'qu1', 'bie2', 'yu2', 'wen2', 'ren2', 'hua4', 'he2', 'nian2', 'hua4', 'ke3', 'wei4', 'ya3', 'su2', 'gong4', 'shang3']
原文结果: ['ma3', 'xiao3', 'nian2', 'zuo4', 'hua4', 'de5', 'te4', 'zheng1', 'yu3', 'shen2', 'yun4', 'qi2', 'hua4', 'feng1', 'qu1', 'bie2', 'yu2', 'wen2', 'ren2', 'hua4', 'he2', 'nian2', 'hua4', 'ke3', 'wei4', 'ya3', 'su2', 'gong4', 'shang3']
转载请注明出处:https://blog.csdn.net/chinatelecom08