【JAVA】Webmagic 爬虫框架,带着问题解读源码
无意中发现了一个巨牛的人工智能教程,忍不住分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。点这里可以跳转到教程。
前言
github地址
https://github.com/cwtree/webmagic
WebMagic的设计参考了业界最优秀的爬虫Scrapy,而实现则应用了HttpClient、Jsoup等Java世界最成熟的工具,目标就是做一个Java语言Web爬虫的教科书般的实现。
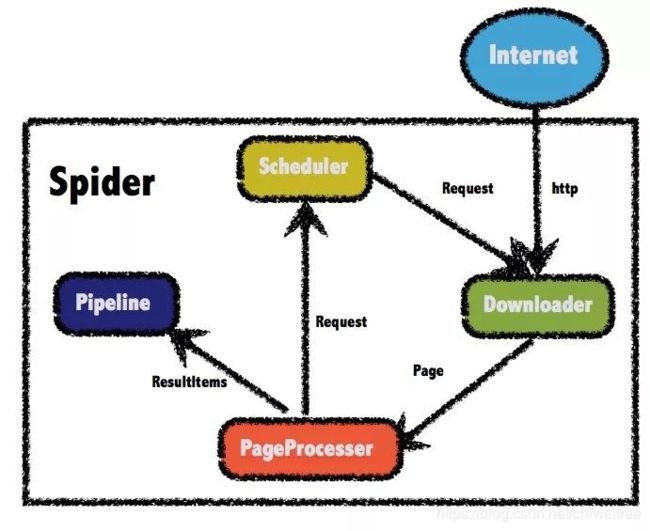
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
以上是webmagic官网的一些概括性介绍,当然官网内容很多,大家可以自行前往http://webmagic.io/docs/zh/
启动

这里显示设置了三个参数
thread
表示启动多少个线程取爬取网页,这里webmagic框架里用的线程池会频繁创建线程和销毁线程,跟以前使用的线程池效果不太一样,因为在性能压测时会发现JVM频繁创建和销毁线程,线程数持续增长。
scheduler
调度器
downloader
网页下载器
当然你可以设置更多的参数,按照实际项目需求来即可。
spider
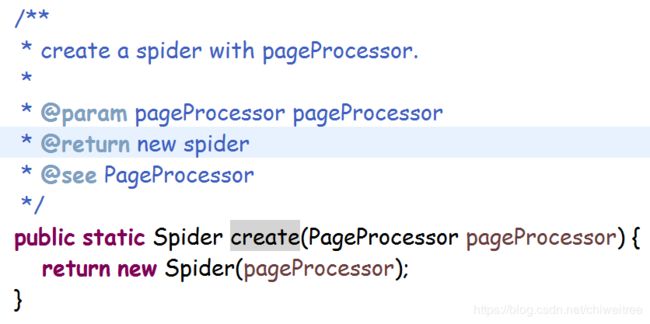
我们是自定义了一个spider,因为我们发现webmagic源码里爬虫的线程数和httpclient的连接池大小共用一个属性,这就很麻烦了,thread线程数我们一般设置为cpu核数两倍固定的,但是httpcleint的连接池完全可以大一些,但是源码里并没有留出这个入口,所以重写spider,改写initComponent的逻辑。
我们先来看看webmagic中httpclientdownloader的实现




一级一级往上看就知道,这个参数最终就是httpclient连接池的大小
为了能设置这个参数并且和spider的线程数不共用同一个参数,我们自定义了一个spider,将webmagic中spider的create和initComponent代码拷贝过来,修改initComponent代码如下:
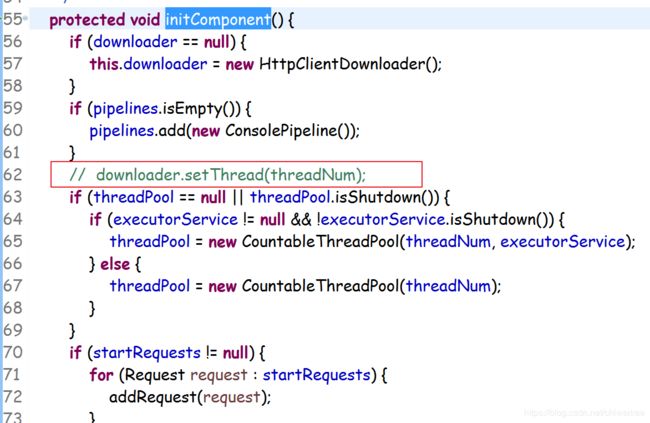
注释掉这一行即可,这行的目的就是为了让spider不去设置httpclient的连接池大小,将其交给后续的组件去设置。

spider是一个实现了runnable接口的类,所以启动时会运行run方法,我们再来看run的实现:
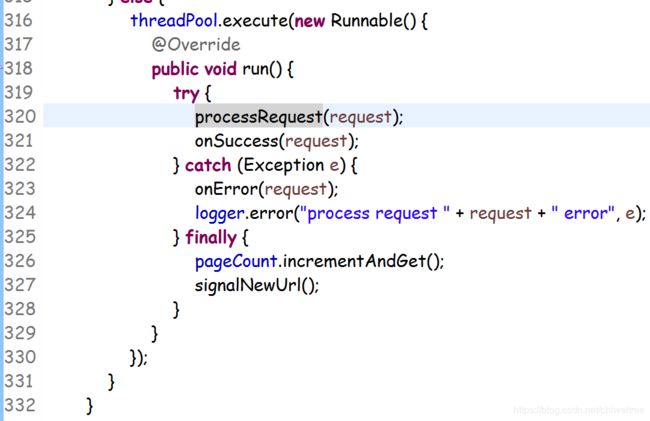
核心就是processRequest方法

![]()
这里的getHttpClient方法就是创建httpclient,连接池大小就是前面httpclientgenerator设置的大小。
所以以上我们就实现了自定义http连接池大小的功能。
scheduler
自定义的scheduler是为了实现可以重复添加相同的url,而且我们是基于redis任务队列来进行生产消费,但是为了提高性能,
Scheduler scheduler = new QueueScheduler().setDuplicateRemover(new NoDuplicateRemover());
这个队列调度器是webmagic框架在内存里维护的
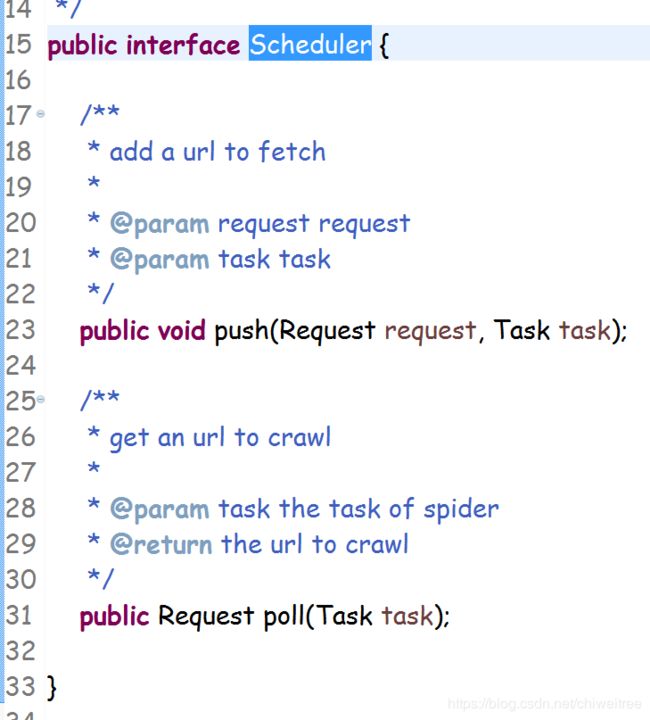
主要就是维护一个内存阻塞队列,支持入队出队操作
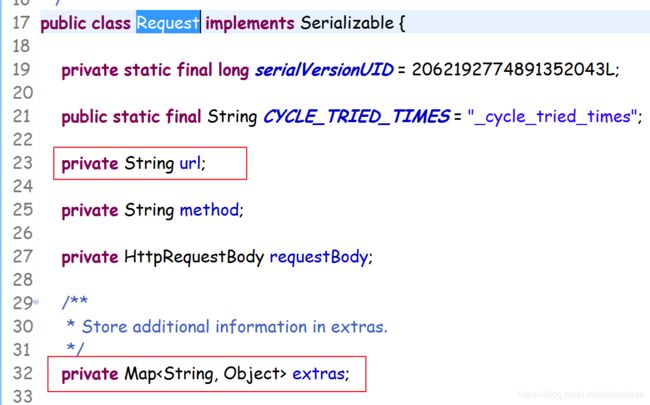
从push方法可以看出,这里push的对象是个Request
downloader
downloader我们是自定义了一个,因为webmagic框架里没有吧网站爬取失败的结果往外传,而我们恰好需要这个信息,所以自定义downloader之后,重写了onerror方法,取获取我们想要的信息
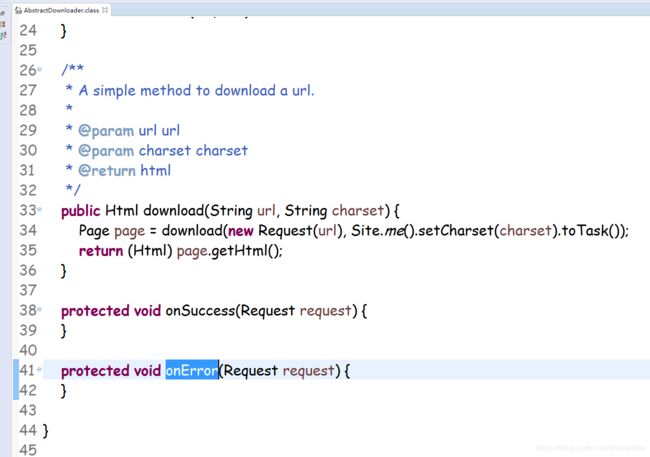
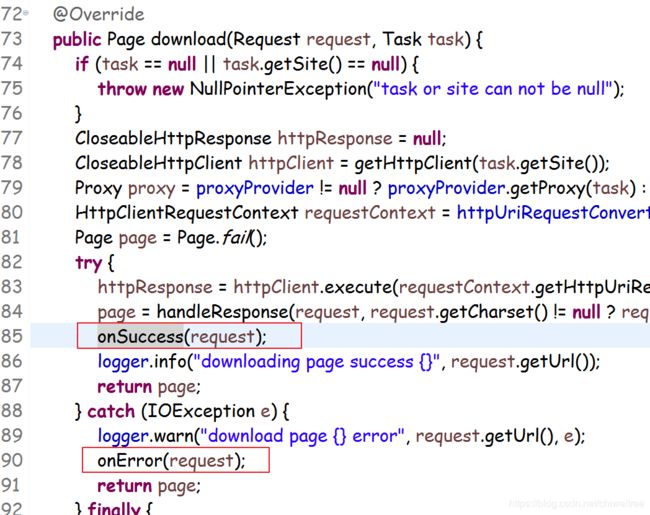
我们重写onError方法,从这个代码看出,如果走到onError基本就可以认为是该网页不可达了,网络原因,所以我们的程序里就通过onError方法来捕获这个网页不可达的失败原因了。
接下来我们看下downloadsuccess的实现
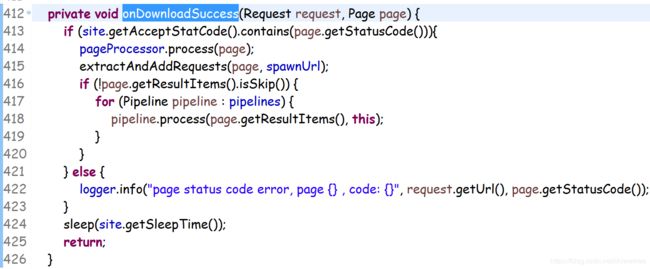
这里webmagic源码实现是只有http code为200才认为是处理成功,否则都是失败,而且失败的原因没有往外抛出,导致外面拿不到这样的原因,即使失败了,不知道咋回事,黑盒

源码里有个set,默认只有200,这了我们同样做了改造,将HTTP状态码,初始化的时候全部加到这个set里,这样可以让webmagic处理时,扩大成功范围,其实404对于爬虫来说是成功的,只是说网页不存在而已,我们自己的程序能拿到404这个状态码就可以了。
HTTPS问题绕过
webmagic爬取HTTPS网站时,报错hostname verifiy error,主机名验证失败,我们深入源码一看究竟
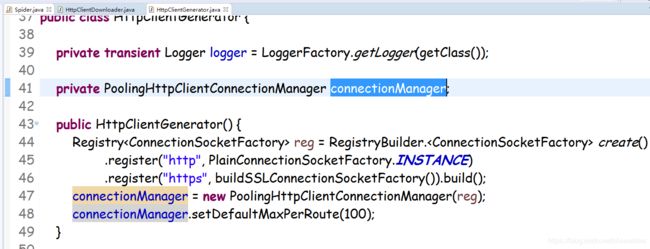
webmagic注册https处理的逻辑遇到过hostname验证错误的情况
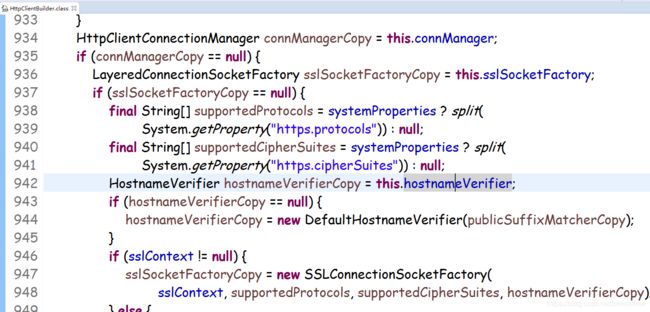

这里有个公用的后缀匹配器去判断hostname是否正确

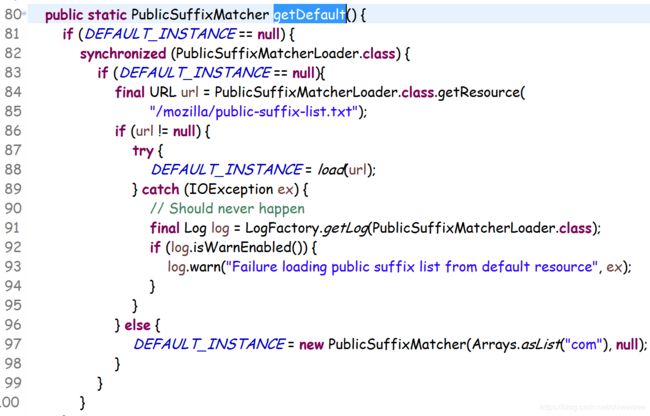
这里的默认匹配器就是校验hostname的后缀,所以当我们爬取一个URL地址是IP的HTTPS网站就会报错,hostname验证错误,因为压根没有后缀一说.com,.cn之类的。
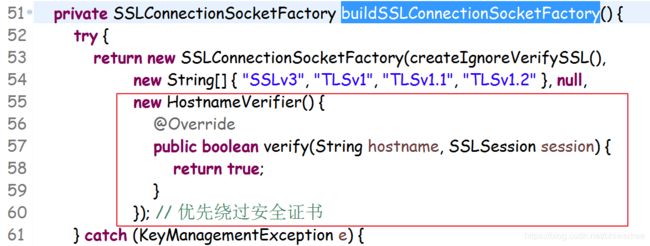
所以们修改了webmagic源码的这块逻辑,很简单,如下:
线程执行流程
最后说说spider里线程执行的流程,直接进入run方法一步一步看:
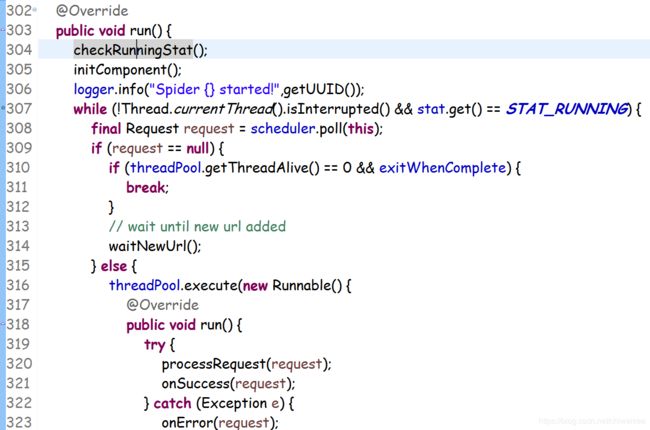
先是一个checkRunningStat的方法
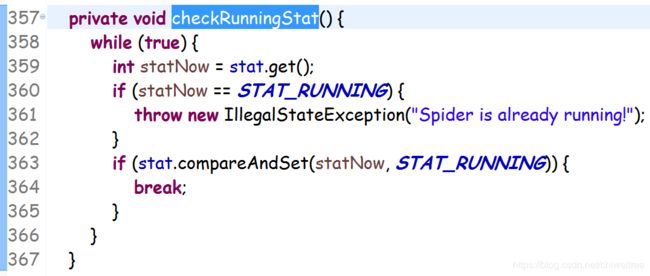
这个方法将当前运行状态改成running,使得后续的while循环能进入执行

初始化组件,这里是webmagic内部自定义了一个线程池

这里是通过初始化一个固定大小的线程池来处理的
线程池初始化完了,后面开始往线程池里面提交任务了

在finally里有个signalNewUrl的方法

这个逻辑是当一个网站处理完了之后,对于即将新加入的网站任务先上锁lock,然后signalAll
既然这里唤醒,必然有一个地方wait等待了
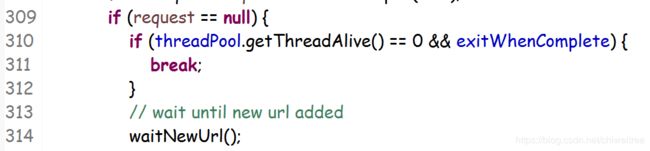

等待的原因是因为线程没有退出,任务没结束,但是还没获取到新的request任务,所以等待了;
后面具体的线程任务就是去爬取页面了download过程。
最后执行完了会shutdown线程,这就是文章开头说的线程频繁创建销毁


以上是我们在使用webmagic框架过程中,通过修改源码来实现自身功能时读到的一些内容,望大家不吝指教。