分布式HDFS详解
Hadoop的历史:
Hadoop的思想起源是Google当年发布三篇论文,GFS,Map-Reduce和BigTable。2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,一个微缩版:Nutch。
Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目
Hadoop简介:http://hadoop.apache.org
Hadoop主要包括三大部分:分布式存储系统HDFS (Hadoop Distributed File System ):分布式存储系统、提供了 高可靠性、高扩展性和高吞吐率的数据存储服务;分布式计算框架MapReduce:分布式计算框架(计算向数据移动)、具有易于编程、高容错性和高扩展性等优点;分布式资源管理框架YARN(Yet Another Resource Management):负责集群资源的管理和调度
本文主要介绍HDFS,HDFS的架构如下: 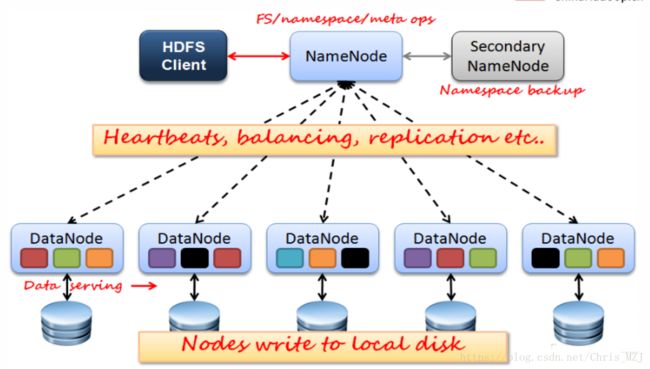
HDFS的架构模型:架构的整体结构
1、文件的元数据MetaData,文件数据:主要包括client服务器上传文件的权限、上传文件的属主以及属组、上传文件的时间、上传文件的block数以及ID号等等,(后面会详解)
2、(主)NameNode节点保存文件元数据:单节点
3、(从)DataNode节点保存文件Block数据(后面讲解):多节点
4、DataNode与NameNode保持心跳,提交Block列表
5、HdfsClient与NameNode交互元数据信息
6、HdfsClient与DataNode交互文件Block数据
存储模型
HDFS的存储模型是Block块,所谓Block块,就是把一个大文件进行固定大小的切割而形成的块,比如一个10M大小的文件,按照1M大小切割可以切成10块,这每一个block就是一个存储模型。而HDFS存储的Block块是每块128M,HDFS中每个DataNode节点都会把自己磁盘按128M大小来分块并编号(BlockId)。当客户端client向HDFS存储数据时,会首先计算文件的block数,blocks=文件的大小/128M,不足128M的文件也算一个block,算出block数就是告诉HDFS我要多少个Block块来存储上传的文件,当上传的文件小于128M时自然是需要一个Block来存储,所以不足128M的文件也算一个block,但是不足128M的文件并不会占满block的存储空间。
对存储模型的总结如下图:

NameNode
接下来讲解NameNode(后面简称NN)节点,NN节点是基于内存存储的,不会与磁盘发生交换,但是可以持久化数据到磁盘。NN的主要是功能是接受客户端client的读写服务,收集DataNode(后面简称DN)汇报的Block列表信息,NN保存的一些元数据信息包括client服务器上传文件的权限、上传文件的属主以及属组、上传文件的时间,(Block列表:Block偏移量),Block 副本位置(由DataNode上报)。NN的持久化是借助于一个快照文件:fsimage,当NN启动时,会创建一个fsimage文件和一个edits文件,edits文件是记录对元素的操作日志,也可以理解为client对HDFS集群的操作日志,HDFS会定期(后面会详讲)地将edits文件中的日志放到fsimage中,由fsimage持久化到磁盘,但是Block的位置信息是不会保存到fsimage中的,因为系统磁盘中的block号是会经常重新分配变动的,没必要存,直接由DN汇报给NN就行。

DataNode
下面是DataNode(DN)节点,DN在HDFS中是由多个的,顾名思义,DN最主要的功能就是存储数据,DN除了存储源数据外,还会存储Block的元数据信息,如BlockId号。DN在HDFS启动时就会向NN汇报block信息,HDFS运行的时候,DN每隔3s就会向NN汇报一次心跳信息,告诉NN我还没挂呢,如果NN10分钟内没有收到DN的心跳信息,就会认为这个DN已经挂掉了,那么就会将DN中的数据重新copy到其他DN节点上。既然这个DN都已经挂掉了,那又怎么copy它存储的数据呢?这是由HDFS的备份机制决定的:
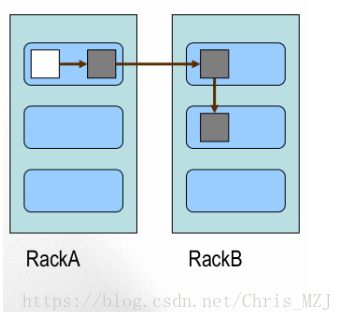
HDFS中会对每一份元数据进行备份,比如client第一次上传一份文件file1到DN1中,HDFS不仅将file1存在DN1中,也会存在另外两台DN中,如下图所示:RackA和RackB表示两个机架,第一个副本:放置在上传文件的DN(RackA的黑色方块);如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。第二个副本:放置在于第一个副本不同的 机架的节点上。第三个副本:与第二个副本相同机架的节点。
Block的副本放置策略:
SecondaryNameNode
HDFS机制考虑到NameNode一个人干活实在太累,又要服务client又要进行元数据的持久化操作的话会使得NameNode压力大增,负荷大了就容易炸,所以给NameNode指派了一个助手叫SecondaryNameNode(后面简称SNN),注意是叫助手,因为SNN是不能都代替NN的在工作的,SNN的任务就是帮助NN做元数据的持久化。
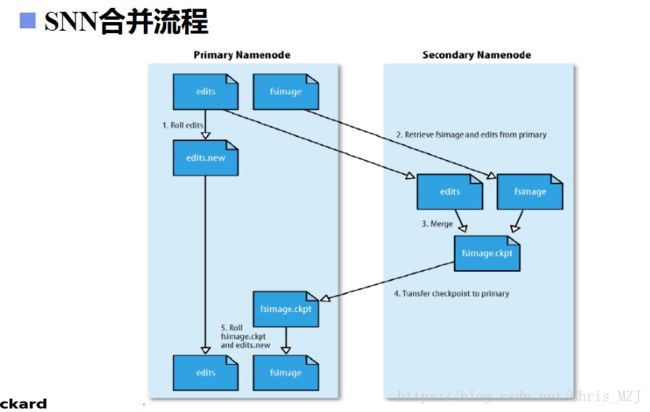
SNN合并流程如下图所示:
NN不断地接受client的读写请求,将产生的元数据存放在edits文件中,而SNN呢就是每隔一定时间就会将NN中的edits文件和fsimage文件拿过来进行合并,如右图所示,拿过来之后呢首先将edits中的元数据重演,所谓重演就是再模拟一遍操作,但是不会操作磁盘中的数据,然后将拿过来的两个文件合并成fsimage.ckpt文件,合并完成就将fsimage.ckpt还给NN,NN拿到fsimage.ckpt之后去掉它的后缀,重新变为fsimage。而在SNN拿走了edits和fsimage之后NN就会创建已个新的edits文件edits.new在接收保存在SNN合并期间client请求产生的元数据,在SNN合并完成后就会将edits.new的后缀去掉。SNN的合并间隔时间是根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒; 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB,也就是说每隔个3600s就会合并一次,edist大于64M也会合并一次,这两个条件,满足一个就合并。
安全模式
安全模式是指HDFS启动时候就进入的短暂的模式,就像windows系统的开机时间的模式一样,在安全模式期间HDFS会做一些准备工作:
namenode启动的时候,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个操作不需要SecondaryNameNode)和一个空的编辑日志。
此刻namenode运行在安全模式。即namenode的文件系统对于客户端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败)。
在此阶段Namenode收集各个datanode的报告,当数据块达到最小副本数以上时,会被认为是“安全”的, 在一定比例(可设置)的数据块被确定为“安全”后,安全模式结束
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数,系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中。
HDFS写流程
介绍了HDFS的这么多该概念一定感觉很抽象生硬,接下来详细解析一波HDFS的读写流程,能让我们更加深入地了解HDFS的工作原理,首先,开局一张图:
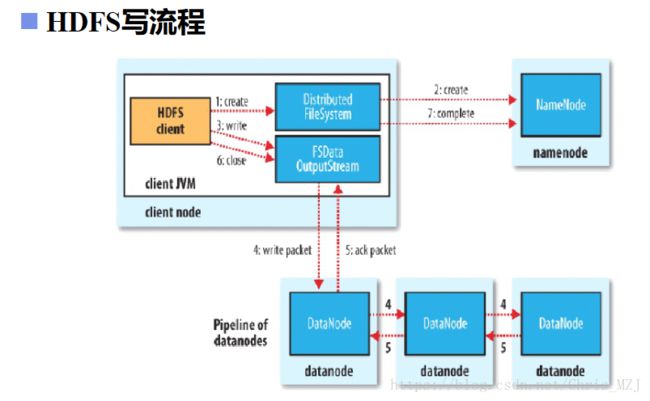
假设此时图中的HDFSclient手上有一个特别大的文件,就1TB吧,client要向HDFS存储这个文件,要进行如下的写过程
1、首先计算这个文件的block数,即:blocks = 1TB/128M,block数计算完成后client会向NameNode发送写请求,并向NN会汇报如下信息:
1)、block数
2)、当前大文件的属主,属组
3)、上传时间
2、NN节点收到client的请求后,会根据client汇报的block数来分配DataNode节点中的block存储列表返回,即先看看DN中有没有这么多的block,有的话就把响应的BlockId号返回给client,同时,会将元数据信息保存到edits文件中.当每过3600s或者edits文件大于64M时,SecondaryNameNode就会将NN中的edits和fsimage文件合并,SNN图中没画出来。
3、client拿到NN返回的BlockId号之后就相当于拿到了访问DataNode的钥匙,就可以写数据了,而HDFS写的过程也比较讲究,为了最大效率地写数据,HDFS采用的是基于DataNode之间的管道机制(Pipeline of DataNodes )写的.
4、管道机制可以粗略地用下图表示,首先client会将大文件的每一个block块再次切割成一个个64k大小的packet,然后HDFS会在要存储文件的三台DataNode(HDFS的备份机制)之间建立一个管道,packet就会流过这个管道,每个DN就从管道到拿数据存储到相应的block块中,这样将大文件以此切割传输直至完成。
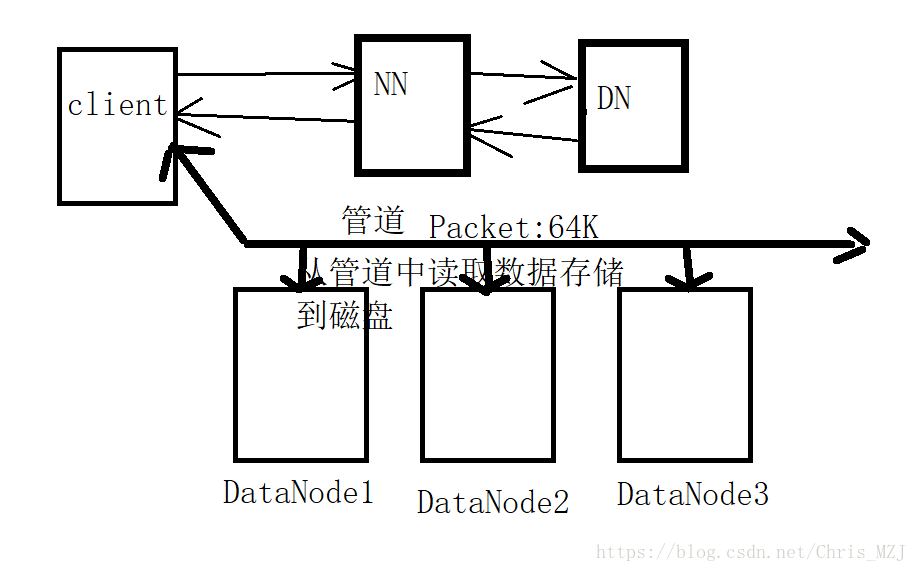
5,6、文件传输完成后返回信息给client,HDFS关闭管道
7、client通知NN我存完数据了,这整个过程就是HDFS的写文件的过程。
HDFS读流程
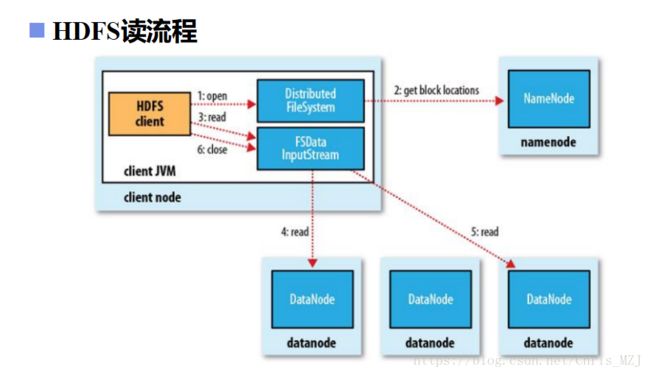
HDFS的读流程比较简单,如下图所示:首先,HDFSclient告诉NameNode我要读什么文件,NameNode就会根据文件名查询DataNode中存储该文件的BlockId号,然后将其返回给client,client拿到BlockId号后直接去DataNode中读取数据即可。(读取过程是线性的向NN获取一部分Block副本位置列表,线性和DN获取Block,最终合并为一个文件在Block副本列表中按距离择优选取)。
HDFS优点
1、高容错性
数据自动保存多个副本
副本丢失后,自动恢复
2、适合批处理
移动计算而非数据
数据位置暴露给计算框架(Block偏移量)
3、适合大数据处理
GB 、TB 、甚至PB 级数据
百万规模以上的文件数量
10K+ 节点
4、可构建在廉价机器上
通过多副本提高可靠性
提供了容错和恢复 机制
HDFS缺点
1、低延迟数据访问(无法满足)
比如毫秒级
低延迟与高吞吐率
2、小文件存取
占用NameNode 大量内存
寻道时间超过读取时间
3、并发写入、文件随机修改
一个文件只能有一个写者
仅支持append
HDFS文件权限 POSIX
HDFS的权控制于linux权限类型,都是可读可写可执行rwx。如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan。HDFS的权限控制是阻止好人做错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁。比如说我去访问别人HDFS文件,这个文件是属主是root用户,而我的client是zhangsan用户,这时候我是没有访问权限的,但是我可以手动地将我的用户名改为root用户,这时就可以访问HDFS了。