tf custom estimator
- 简介
- train_input_fn
- input_layer
- feature
- feature_column
- tf.feature_column.input_layer
- label
- my_model_fn
- 完整例子
- 参考
简介
官方 github 源文件例子见参考[2] .
不同的神经网络是有共性的, 阶段上分train,eval,pred, 数据上分feature,label,batch_size, 所以官方提倡围绕 Estimator 类来编码, 整个程序由train_input_fn+Feature Columns+ my_model_fn 构成, 风格统一了, 就方便维护与多人交流.
train_input_fn
函数签名一般为train_input_fn(features, labels, batch_size).
该函数的参数是用户自己传的, 通常这么用
# Train the Model.
classifier.train(
input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size),
steps=args.train_steps)该函数返回的是 Dataset对象, 在 Estimator的 train 阶段, 框架会自动调用.dataset.make_one_shot_iterator().get_next() 得到一个batch的数据.
tf.data.Dataset.from_tensor_slices(tensors)
Creates aDatasetwhose elements are slices of the given tensors.tensors参数一般为(features,labels)Dataset#shuffle(buffer_size)Dataset#repeat(count=None)Dataset#batch(batch_size)
input_layer
feature
feature_column
使用诸如tf.feature_column.xxx的对象来对features进行说明.
tf.feature_column.numeric_column(key,shape=(1,),default_value=None, dtype=dtypes.float32,)
普通的数字类型. 注意dtype, 不传的话默认为float类型.tf.feature_column.embedding_column(categorical_column, dimension, combiner='mean',...)
Args:
- combiner
默认值为mean, 一个word对应一个dim维度的向量, 多个word一起的话, 就查表之后求平均.
- combiner
直接看示例代码
import tensorflow as tf
WORD_VEC_DIM = 4
def get_feature_columns():
word_id_column = tf.feature_column.categorical_column_with_vocabulary_list(key='word', vocabulary_list=[
'my', 'name', 'is', 'yichu'])
content_embedding_column = tf.feature_column.embedding_column(word_id_column, WORD_VEC_DIM, ckpt_to_load_from=None,
tensor_name_in_ckpt=None)
return [content_embedding_column]
features = {'word': ['his', 'name', 'is', 'tom']}
my_feature_columns = get_feature_columns()
input_layer = tf.feature_column.input_layer(features, my_feature_columns)
var_init = tf.global_variables_initializer()
table_init = tf.tables_initializer()
with tf.Session() as sess:
sess.run((var_init, table_init))
print(sess.run(input_layer))
"""
[[ 0. 0. 0. 0. ]
[ 0.26500136 -0.22425671 -0.7151153 0.13360171]
[-0.8541851 0.20016764 0.34607974 -0.08984461]
[ 0. 0. 0. 0. ]]
"""
上段代码相当于自动的创建了一个 embedding_matrix, 包装的多也不好用. 我还是喜欢tf.feature_column.numeric_column(key='content_sequence',shape=(MAX_TEXT_LEN))的形式.
tf.feature_column.input_layer
tf.feature_column.input_layer(features,feature_columns,...)Args:
- features
A mapping from key to tensors.
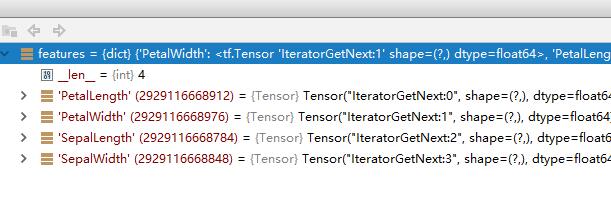
figurefeatures参数的debug 视图. - feature_columns
An iterable containing the FeatureColumns.
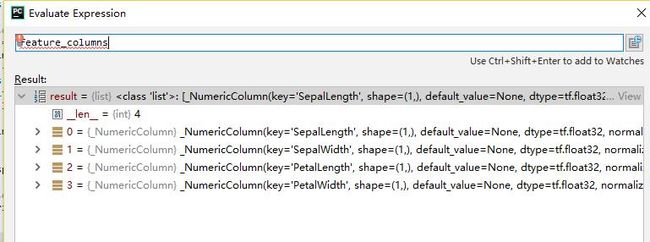
figurefeature_columns参数的debug视图
- features
综合上面两个图, 就可以推知工作原理了: features里面的key与feature_columns的key相对应.
该函数返回的也是tensor, 在网络中的位置类比于 tf.placeholder,可以往下逐层传递了, 但是 its dtype is float32. 我觉得不爽, 明明feature_columns 已经指定了类型, 如果都是 int , 就应该返回才科学. 此时需要借助tf.cast()来做类型转换.
如何debug它返回的tensor呢, 可以在 low-api 中使用 session 读取. 见参考[1].
label
my_model_fn
函数签名是这样的:
def model_fn(
features, # This is batch_features from input_fn
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys
params):创建自己的 Estimator 对象, 并训练 的语句是这样的:
classifier = tf.estimator.Estimator(
model_fn=yichu_dssm_model_fn,
params={'feature_columns': get_feature_columns()})
# train
classifier.train(input_fn=lambda :train_input_fn(batch_size=FLAGS.batch_size), steps=FLAGS.train_steps)完整例子
我的例子见 参考 [3], 与官方教程的区别是:
- 数据源不是pandas的DataFrame, 而是 numpy 的 ndarray
- 四个数值特征合并为一个 shape=(4,) 的特征.
参考
- feature_columns with low-api
- 官方例子,custom_estimator.py
- 我的例子, iris_custom_estimator.py