faster-rcnn中的RPN
使用卷积神经网络对图像进行分类已经有很多成熟的方案,而目标检测不仅要对图像中的目标进行分类,而且还要对目标进行定位。一个很简单的思路就是先从一幅完整的图像中选取若干候选区域,然后再对这些候选区域进行分类。RCNN系列的开篇之作就是这么做的。先用传统算法如selective search在原图中提取2000个大小不一的候选区域,这些候选区域本质上也是一幅图像,只是它们都是从原图中提取出来的。显然,这一步完成之后就已知了这些候选区域在原图中的位置了。但是这么做的代价太高,传统的诸如selective search算法效率太低,根本没法做到实时。在 faster-rcnn论文中创造性地提出使用一个叫RPN(Region Proposal Networks)的网络来提取候选区域即RoI,RPN本质上是一个卷积神经网络,它提取RoI使用的是深度学习的思想,而不再是传统图像处理的思路。

图1 Region Proposal Network(RPN)
图1表示的就是RPN网络结构,Faster R-CNN是一个二阶段的目标检测器,它实际上是由RPN和Fast R-CNN两个部分构成。RPN和Fast RCNN共享一部分卷积层。以ResNet101为例,RPN和Fast R-CNN共享conv1至conv4_x(算层数的话是91层),RPN正

是作用于conv4_x的输出的特征图,使用一个n x n(论文中为3x3)的滑动窗口网络在特征图上滑动,每一个滑动窗口都会映射到一个低维的特征向量(256-d for ZF and 512-d for VGG/ResNet, with ReLU)。这一步不要觉得有多神秘,归根到底还是一个卷积核大小为n x n的卷积操作嘛,用代码表示就下面这一句话:
# define the convrelu layers processing input feature map
# stride=1,padding=1
# self.din表示输入的通道数,对于resnet101来说就是1024,512表示输出通道数
self.RPN_Conv = nn.Conv2d(self.din, 512, 3, 1, 1, bias=True)
RPN中在特征图的每一个位置上都要产生k个候选区域,将低维特征向量(256-d/512-d)送入到两个并行的全连接网络中,一个用于分类,一个用于坐标矫正量的回归。分类网络层将有k组输出,每组两个值表示一个候选区域中有目标和无目标的概率。回归网络层也是k组输出,每组为4个坐标矫正量(注意这里不是直接回归出坐标!),由这些坐标矫正量(tx,ty,tw,th)可以计算出预测出的候选区域的坐标值(x,y,h,w)。

公式中,x是坐标预测值,xa是anchor坐标(预设固定值),x*是真实坐标值。其它变量y,w,h以此类推。经过变形,即可得到:
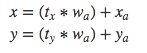
Anchor在哪呢?anchor的中心就是上文中n x n的滑动窗口的中心,作者根据这个滑动窗口的中心点计算出对应到原始图片中的位置。然后作者假定,这个n x n窗口,是从原始图片上通过SPP池化得到的,而这个池化的区域的面积以及比例,就是一个个的anchor。换句话说,对于每个n x n窗口,作者假定它来自k种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚才提到的,n x n窗口中心点所对应的原始图片中的中心点。如此一来,在每个窗口位置,我们都可以根据k个不同长宽比例、不同面积的anchor,逆向推导出它所对应的原始图片中的一个区域,这个区域的尺寸以及坐标,都是已知的。而这个区域,就是我们想要的 proposal。所以我们通过滑动窗口和anchor,成功得到了 W x H x k个原始图片的proposal。