linux安装hadoop集群(2)-配置安装
上篇 linux安装hadoop集群(1)-准备工作
本篇 linux安装hadoop集群(2)-配置安装
1 集群结构
| 节点名称 | NN1 | NN2 | DN | RM | NM |
| hpmaster | NameNode | DataNode | NodeManager | ||
| hpslave1 | SecondaryNameNode | DataNode | ResourceManager | NodeManager | |
| hpslave2 | DataNode | NodeManager |
2 下载
hadoop-2.7.6下载地址
3 解压
hpmaster将hadoop包解压在/usr/local/目录
tar zxvf hadoop-2.7.6.tar.gz -C /usr/loca/
/usr/local/hadoop-2.7.6
4 配置环境变量
hpmaster配置环境变量
[root@hpmaster ~]# vim /etc/profile
在/etc/profile文件中添加如下命令
export HADOOP_HOME=/usr/local/hadoop-2.7.6
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[root@hpmaster hadoop]# source /etc/profile
5 创建hadoop相关目录
hpmaster创建目录
/usr/local/hadoop-2.7.6/dfs/name
/usr/local/hadoop-2.7.6/dfs/data
/usr/local/hadoop-2.7.6/temp
6 配置hadoop配置文件
core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
slaves hadoop-env.sh yarn-env.sh mapred-env.sh
hpmaster进入目录 /usr/local/hadoop-2.7.6/etc/hadoop
7 配置core-site.xml
配置如下内容:
[root@hpmaster hadoop]# vim core-site.xml
fs.defaultFS
hdfs://hpmaster:9000
hadoop.tmp.dir
/usr/local/hadoop-2.7.6/temp
8 配置hdfs-site.xml
配置如下内容:
dfs.replication
3
dfs.namenode.secondary.http-address
hpslave1:50090
dfs.namenode.name.dir
/usr/local/hadoop-2.7.6/dfs/name
dfs.namenode.data.dir
/usr/local/hadoop-2.7.6/dfs/data
9 配置mapred-site.xml
配置如下内容:
[root@hpmaster hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@hpmaster hadoop]# vim mapred-site.xml
mapreduce.framework.name
yarn
10 配置yarn-site.xml
配置如下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hpslave1
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.vmem-pmem-ratio
4
11 配置slaves
配置如下内容:
[root@hpmaster hadoop]# vi slaves
[root@hpmaster hadoop]# cat slaves
删除默认的localhost
hpmaster
hpslave1
hpslave2
12 修改hadoop-env.sh
修改如下内容:
[root@hpmaster hadoop]# vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_181
13 修改mapred-env.sh
修改如下内容:
[root@hpmaster hadoop]# vim mapred-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_181
14 修改yarn-env.sh
修改如下内容:
[root@hpmaster hadoop]# vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_181
15 分发hadoop文件夹
定位到 /usr/local ,拷贝hadoop文件夹到远程服务器,这样保证三台服务器的hadoop的配置一致
[root@hpmaster local]# pwd
/usr/local
[root@hpmaster local]# scp -r hadoop-2.7.6/ root@hpslave1:/usr/local/
[root@hpmaster local]# scp -r hadoop-2.7.6/ root@hpslave2:/usr/local/
16 其他hadoop节点
hpmaster需要配置hadoop环境变量,其他服务器不需要配置hadoop环境变量
17 启动集群
第一次启动,需要格式化namenode
[root@hpmaster hadoop-2.7.6]# pwd
/usr/local/hadoop-2.7.6
[root@hpmaster hadoop-2.7.6]# ./bin/hdfs namenode -format

启动Hdfs
root@hpmaster hadoop-2.7.6]# pwd
/usr/local/hadoop-2.7.6
[root@hpmaster hadoop-2.7.6]# ./sbin/start-dfs.sh
Starting namenodes on [hpmaster]
hpmaster: starting namenode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-root-namenode-hpmaster.out
hpmaster: starting datanode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-root-datanode-hpmaster.out
hpslave1: starting datanode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-root-datanode-hpslave1.out
hpslave2: starting datanode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-root-datanode-hpslave2.out
Starting secondary namenodes [hpslave1]
hpslave1: starting secondarynamenode, logging to /usr/local/hadoop-2.7.6/logs/hadoop-root-secondarynamenode-hpslave1.out启动Yarn
注意:Namenode和ResourceManger,不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn
Yarn 配置在 hpslave1,要从hpslave1 启动
[root@hpslave1 hadoop-2.7.6]# ./sbin/start-yarn.sh
20 验证启动成功
[root@hpmaster hadoop-2.7.6]# jps
1761 Bootstrap
4033 DataNode
3897 NameNode
4249 Jps[root@hpslave1 hadoop-2.7.6]# jps
3792 SecondaryNameNode
4418 NodeManager
4548 Jps
1829 Bootstrap
3989 ResourceManager
3723 DataNode[root@hpslave2 ~]# jps
4039 Jps
3753 DataNode
1594 Bootstrap
3914 NodeManager
以后启动hadoop集群只要启动Hdfs和Yarn即可
21 停止集群
停止Hdfs
[root@hpmaster hadoop-2.7.6]# pwd
/usr/local/hadoop-2.7.6
[root@hpmaster hadoop-2.7.6]# ./sbin/stop-dfs.sh
停止yarn
[root@hpslave1 hadoop-2.7.6]# ./sbin/stop-yarn.sh
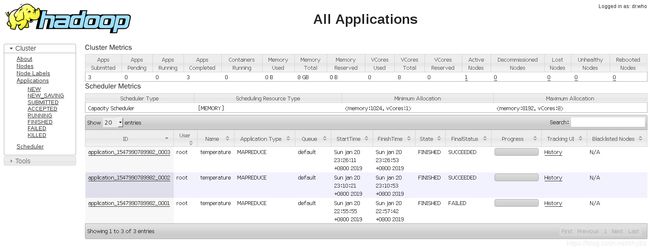
22 监控平台
http://hpslave1:8088/cluster
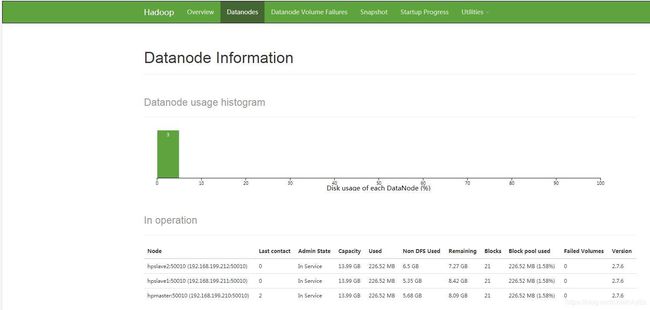
http://192.168.199.210:50070/dfshealth.html#tab-datanode

http://hpmaster:50070/explorer.html