【笔记2-3】李宏毅深度强化学习笔记(三)Q-Learning
李宏毅深度强化学习- Q-Learning
- Q-Learning介绍
- 基本思想
- Q-Learning:
- 关于Q-Learning 的几点建议
- 连续行动下的 Q-Learning
李宏毅深度强化学习课程 https://www.bilibili.com/video/av24724071
李宏毅深度强化学习笔记(一)Outline
李宏毅深度强化学习笔记(二)Proximal Policy Optimization (PPO)
李宏毅深度强化学习笔记(四)Actor-Critic
李宏毅深度强化学习笔记(五)Sparse Reward
李宏毅深度强化学习笔记(六)Imitation Learning
李宏毅深度强化学习课件
Q-Learning介绍
基本思想
Q-learning – value-base
什么是Critic:
critic并不直接决定采取什么行动,但是会用来衡量一个actor的好坏
critic的输出值取决于被评估的actor
状态价值函数 V π ( s ) V^\pi(s) Vπ(s):
对于actor π \pi π, 给定状态s,期望得到的累积收益,该值取决于状态s和actor π \pi π
如何估计状态价值函数 V π ( s ) V^\pi(s) Vπ(s):
- 基于蒙特卡洛的方法Monte-Carlo (MC)
critic 观察 π \pi π 进行游戏的整个过程, 直到该游戏回合结束再计算累积收益(通过比较期望收益和实际收益G,来训练critic)
Tip: 有时一个游戏回合可能会很长,这个等到游戏回合结束再计算收益的方法训练起来会很慢,因此引入另外一种方法 Temporal-difference(TD) - 时序分差方法Temporal-difference (TD)
时序分差算法计算的是两个状态之间的收益差. (通过比较期望差异与实际差异r之间的差别来训练critic)
MC vs. TD
由于从游戏中获取的收益是一个随机变量,而MC方法是各状态下收益的加总,相对而言,MC方法得到的实际累积收益G的方差会很大.
相比较而言,TD只考虑状态之间的收益差,因此方差较小,但是由于没有从整体收益进行考虑,因此该方法的准确性不能得到保证
状态-行动价值方程 (another critic) Q π ( s , a ) Q^\pi(s, a) Qπ(s,a):
对于给定的actor π \pi π, 在状态s采取行动a预计能够得到的累计收益
Q-Learning:
- 使用一个初始的actor π \pi π 与环境进行互动
- 学习该actor对应的 Q function
- 一定存在另外一个表现更好的actor π ′ \pi' π′ , 用这个更好的actor来替代原来的actor
- 重复上述步骤
更好的 π ′ \pi' π′ 的含义是,对于所有的状态s,一定有 “采取 π ′ \pi' π′获得的状态价值函数不小于 π \pi π得到的状态价值函数 ”,那么 π ′ \pi' π′就是由对Q求argmax返回的actor

Tips:
- π ′ \pi' π′ 不包含额外的参数,它只取决于Q
- 对于连续的action不适用
证明 ( π ′ \pi' π′的存在性):

Tip1: Target network
计算Q的方式与TD类似,但是,在训练的过程中,由 s t s_t st 和 s t + 1 s_{t+1} st+1 生成的值是不固定的,在这种情况下训练会比较困难。
因此,在训练的时候,用来计算 的网络会被固定 s t + 1 s_{t+1} st+1,称为固定网络,于是,目标问题就变成了一个回归问题。
如下图,当前时间t网络生成的Q值与下一个时间网络生成的Q值(固定)之间应该只相差 r t r_t rt,因此需要用真实的 r t r_t rt 与模型计算出来的 r t r_t rt 进行回归逼近。

Tip2: Exploration
对于Q方程,它是policy的基础,这会导致actor每次都会选择具有更大Q值的行动action,对于收集数据而言是一个弊端,可以采用以下方法解决:
- Epsilon Greedy (在训练的过程中 ϵ \epsilon ϵ 的值会逐渐减小)
下述公式的含义是,在采取action的时候,actor会有 1 − ϵ 1-\epsilon 1−ϵ 的概率选择使得Q值最大的a,随着训练时间变长, ϵ \epsilon ϵ 的值逐渐减小,在后期actor选择最大Q值对应的a才会变大。
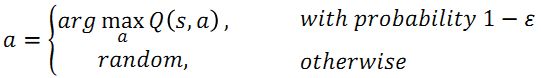
- Boltzmann Exploration (和 policy gradient 类似, 根据一个概率分布来进行采样)

Tip3: Replay Buffer
step1: 用 π \pi π 和环境互动
step2: 将步骤1中互动得到的经验放入一个 buffer (放在buffer里面的经验来自不同的policy,当buffer满了的时候,移除旧的经验)
(这里所说的经验是指集合 s t , a t , r t , s t + 1 {s_t, a_t, r_t, s_{t+1}} st,at,rt,st+1)
step3: 在每一次迭代中,学习 Q π ( s , a ) Q^\pi (s,a) Qπ(s,a): 1. 部分采样 2. 更新 Q-function
step4: 找到一个比 π \pi π 更好的 π ′ \pi' π′
step5: 重复上述步骤
典型的 Q-Learning 算法
先对Q function进行初始化,并令目标Q function和初始Q function相等。
在每个episode中,对于每个时间t:
- 给定状态state s t s_t st,基于使用epsilon greedy的Q采取行动action a t a_t at
- 得到对应的回报reward r t r_t rt 以及新的状态state s t + 1 s_{t+1} st+1
- 将收集到的 { s t , a t , r t , s t + 1 } \{s_t, a_t, r_t, s_{t+1}\} {st,at,rt,st+1}存入reply buffer
- 从reply buffer当中任意采样得到 { s i , a i , r i , s i + 1 } \{s_i, a_i, r_i, s_{i+1}\} {si,ai,ri,si+1}(通常是取一部分样本)
- 目标值为 y = r i + m a x a Q ^ ( s i + 1 , a ) y = r_i + max_{a} \hat{Q}(s_{i+1},a) y=ri+maxaQ^(si+1,a)
- 根据目标值进行回归,不断更新Q的参数,使得计算出来的 Q ( s i , a i ) Q(s_i, a_i) Q(si,ai) 接近于真实值y
- 每C步更新一次 Q ^ = Q \hat{Q} = Q Q^=Q

关于Q-Learning 的几点建议
Double DQN
由于Q值总是基于使得Q最大的action得出的,因此会趋向于被高估,于是引入double DQN
double DQN的真实Q值往往比Q-learning高
- 为什么 Q 经常被高估
因为目标值 r t + m a x Q ( s t + 1 , a ) r_t+maxQ(s_{t+1}, a) rt+maxQ(st+1,a) 总是倾向于选择被高估的行动action - double DQN 是如何工作的?
使用两个Q function(因此称为double), 一个用来选择行动action,另外一个用来计算Q值,通常会选择target network来作为另外一个用于计算Q值的Q‘ function.

如果Q高估了 a 从而被选择, Q’ 会给这个被选择的a一个合适的Q值
入股Q’会高估某个action a,这个action并不会被Q选择到
Dueling DQN
只对网络结构进行改变!

这里计算出来的值有两个:
V(s): 表示静态环境,状态s所具有的价值.
A(s,a): 表示在状态s下采取行动a时的 advantage function
这种类型的网络结构可以用来学习不被行动action影响下的state的价值
通常,在计算 A(s,a) 时,使用单个行动对应的 advantage function 的值减去在该状态下采取所有行动所获得的 advantage function 的值的平均值,因此,对于一个状态下的所有action,具有零和特征。(normalise 在和 V ( s ) V(s) V(s)相加之间进行)
此外,如果只需要通过改变V(s)的值就能改变某个状态下所有的Q的话,会比较方便
Prioritized Experience Replay
简单地说,在训练的过程中,对于在经验buffer里面的样本,那些具有更好的TD 误差的样本会有更高的概率被采样,这样可以加快训练速度。
在这个过程中,参数更新的过程也会有相应的更改。
Multi-step: Combination of MC and TD
此处,模型需要学习多步累积起来的回报reward,也就是说将MC和TD进行了折中,同时引入了一个超参数,即累积reward的步长N

Noisy Net:
Epsilon Greedy vs. Noisy Net
Epsilon Greedy: 在行动上加噪声
即便给定相同的状态state,agent也有可能采取不同的行动,因此,实际上这里并没有真正意义上的policy
Noisy Net: 在参数上加噪声
在每个episode开始时,在Q function的参数上引入噪声,但在每一个episode内,参数不会发生改变。给定同样的state,agent会采取同一个action

Distributional Q-function
状态-行动价值函数 Q π ( s , a ) Q^\pi(s,a) Qπ(s,a) 是累积收益的期望值,也就是说是价值分布的均值。然而,有的时候不同的分布得到的均值可能一样,但我们并不知道实际的分布是什么。
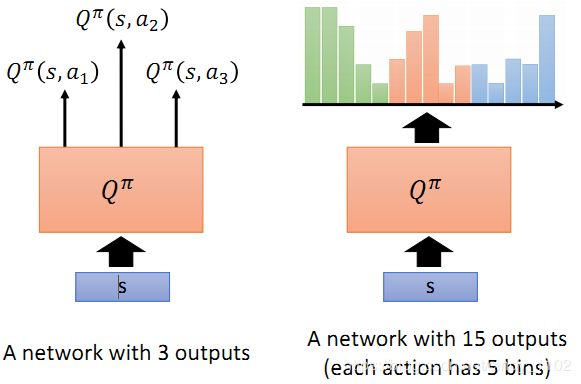
Distributional Q-function 认为可以输出Q值的分布,当具有相同的均值时,选择具有较小方差(风险)的那一个
但实际上,这个方法很难付诸实践。
Rainbow:

上述图像表明 DDQN 对于rainbow来说用处不大,这是因为DDQN是用来解决高估问题的,而这个问题在 distributional Q function 中已经得到了解决
连续行动下的 Q-Learning
连续行动:
在某些情况下,action是一个连续向量(比如驾驶类游戏,需要决定一个连续的角度)
在这种情况下,Q learning 并不是一个用来寻找最佳action的好方法
解决方式一:
采样一系列行动,看哪个行动会返回最大的Q值
解决方式二:
使用梯度上升来解决这个优化问题(具有较高的计算成本)
解决方式三:
设计一个网络来使得这个优化过程更简单

这里 ∑ \sum ∑ 和 μ \mu μ 是高斯分布的方差和均值,因此,该矩阵 ∑ \sum ∑ 一定是正定的。
要让Q值较高,意味着要使得 ( a − μ ) 2 (a-\mu)^2 (a−μ)2 的值更小,也就是说 a= μ \mu μ.
解决方式四:
不使用 Q-learning
具体细节将在下一个笔记中进行介绍
