centos7二进制安装kubernetes1.12添加证书配置
kubernetes基础安装请看以下文档
https://blog.csdn.net/ciqingloveless/article/details/82348490
其中证书配置部分可以查看
https://blog.csdn.net/ciqingloveless/article/details/81741988
一 服务配置
1 配置Kubernetes CNI(所以节点)
export CNI_URL=https://github.com/containernetworking/plugins/releases/download
mkdir -p /opt/cni/bin && cd /opt/cni/bin
wget "${CNI_URL}/v0.7.1/cni-plugins-amd64-v0.7.1.tgz" | tar –zx
tar -xvf cni-plugins-amd64-v0.7.1.tgz2 安装CFSSL
export CFSSL_URL=https://pkg.cfssl.org/R1.2
wget ${CFSSL_URL}/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget ${CFSSL_URL}/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
wget ${CFSSL_URL}/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo
chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson /usr/local/bin/cfssl-certinfo3建立CA与产生TLS凭证
3.1 在master1中获取部署文件
在一台master执行就可以,后面会将生成文件复制到所有master
yum -y install git
git clone https://github.com/kairen/k8s-manual-files.git ~/k8s-manual-files
cd ~/k8s-manual-files/pki3.2 ETCD
在k8s-m1建立/etc/etcd/ssl文件夹,并产生 Etcd CA:
export DIR=/etc/etcd/ssl
mkdir -p ${DIR}
cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare ${DIR}/etcd-ca产生Etcd凭证:
cfssl gencert \
-ca=${DIR}/etcd-ca.pem \
-ca-key=${DIR}/etcd-ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,192.168.200.221 \
-profile=kubernetes \
etcd-csr.json | cfssljson -bare ${DIR}/etcd注:
1、-hostname=127.0.0.1,192.168.200.221有几个etcd写几个,本文只有一个
删除不必要的文件,检查并/etc/etcd/ssl目录是否成功建立以下文件:
$ rm -rf ${DIR}/*.csr
$ ls /etc/etcd/ssl
etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem复制文件至其他Etcd节点,这边为所有master节点:
scp -r /etc/etcd 192.168.200.222:/etc/注:
1、本文只有一个etcd不需要执行复制指令,这里就是描述
3.3 Kubernetes组件
export K8S_DIR=/etc/kubernetes
export PKI_DIR=${K8S_DIR}/pki
export KUBE_APISERVER=https://192.168.200.221:6443
mkdir -p ${PKI_DIR}
cfssl gencert -initca ca-csr.json | cfssljson -bare ${PKI_DIR}/ca
ls ${PKI_DIR}/ca*.pem注:
1、KUBE_APISERVER=https://192.168.200.221:6443中的ip地址在多master情况下应该填写为vip-ip(vip-ip不能有机器占用,是用lvs进行的负载均衡),本机只有一个master所以直接写了master的IP地址
3.4建立TLS凭证
3.4.1 API Server
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-hostname=10.96.0.1,192.168.200.221,127.0.0.1,kubernetes.default \
-profile=kubernetes \
apiserver-csr.json | cfssljson -bare ${PKI_DIR}/apiserver
ls ${PKI_DIR}/apiserver*.pem注:
1、 -hostname=10.96.0.1,192.168.200.221,127.0.0.1,kubernetes.default中10.96.0.1是文中超链接第一个的ClusterIP
2、 -hostname=10.96.0.1,192.168.200.221,127.0.0.1,kubernetes.default中192.168.200.221应该是apiserver的ip地址
3.4.2 Front Proxy Client
此凭证将被用于 Authenticating Proxy 的功能上,而该功能主要是提供 API Aggregation 的认证。首先通过以下指令产生 CA:
cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare ${PKI_DIR}/front-proxy-ca
ls ${PKI_DIR}/front-proxy-ca*.pem
/etc/kubernetes/pki/front-proxy-ca-key.pem /etc/kubernetes/pki/front-proxy-ca.pem接着产生 Front proxy client 凭证:
cfssl gencert \
-ca=${PKI_DIR}/front-proxy-ca.pem \
-ca-key=${PKI_DIR}/front-proxy-ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
front-proxy-client-csr.json | cfssljson -bare ${PKI_DIR}/front-proxy-client
ls ${PKI_DIR}/front-proxy-client*.pem
/etc/kubernetes/pki/front-proxy-client-key.pem /etc/kubernetes/pki/front-proxy-client.pem3.4.3 Controller Manager
凭证会建立system:kube-controller-manager的使用者(凭证 CN),并被绑定在 RBAC Cluster Role 中的system:kube-controller-manager来让 Controller Manager 组件能够存取需要的 API object。这边通过以下指令产生 Controller Manager 凭证:
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
manager-csr.json | cfssljson -bare ${PKI_DIR}/controller-manager
ls ${PKI_DIR}/controller-manager*.pem
/etc/kubernetes/pki/controller-manager-key.pem /etc/kubernetes/pki/controller-manager.pem接着利用kubectl来产生Controller Manager的kubeconfig档:
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/controller-manager.conf
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=${PKI_DIR}/controller-manager.pem \
--client-key=${PKI_DIR}/controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/controller-manager.conf
kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=${K8S_DIR}/controller-manager.conf
kubectl config use-context system:kube-controller-manager@kubernetes \
--kubeconfig=${K8S_DIR}/controller-manager.conf3.4.4 Scheduler
凭证会建立system:kube-scheduler的使用者(凭证 CN),并被绑定在 RBAC Cluster Role 中的system:kube-scheduler来让 Scheduler 组件能够存取需要的 API object。这边通过以下指令产生 Scheduler 凭证:
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
scheduler-csr.json | cfssljson -bare ${PKI_DIR}/scheduler
ls ${PKI_DIR}/scheduler*.pem
/etc/kubernetes/pki/scheduler-key.pem /etc/kubernetes/pki/scheduler.pem接着利用kubectl来产生Scheduler的kubeconfig文件:
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/scheduler.conf
kubectl config set-credentials system:kube-scheduler \
--client-certificate=${PKI_DIR}/scheduler.pem \
--client-key=${PKI_DIR}/scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/scheduler.conf
kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=${K8S_DIR}/scheduler.conf
kubectl config use-context system:kube-scheduler@kubernetes \
--kubeconfig=${K8S_DIR}/scheduler.conf3.4.5 Admin
Admin 被用来绑定 RBAC Cluster Role 中 cluster-admin,当想要操作所有 Kubernetes 集群功能时,就必须利用这边产生的 kubeconfig 文件案。这边通过以下指令产生 Kubernetes Admin 凭证:
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare ${PKI_DIR}/admin
ls ${PKI_DIR}/admin*.pem
/etc/kubernetes/pki/admin-key.pem /etc/kubernetes/pki/admin.pem接着利用kubectl来产生Admin的kubeconfig文件:
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/admin.conf
kubectl config set-credentials kubernetes-admin \
--client-certificate=${PKI_DIR}/admin.pem \
--client-key=${PKI_DIR}/admin-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/admin.conf
kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=${K8S_DIR}/admin.conf
kubectl config use-context kubernetes-admin@kubernetes \
--kubeconfig=${K8S_DIR}/admin.conf3.4.6 Masters Kubelet
这边使用 Node authorizer 来让节点的 kubelet 能够存取如 services、endpoints 等 API,而使用 Node authorizer 需定义 system:nodes 群组(凭证的 Organization),并且包含system:node:的使用者名称(凭证的 Common Name)。
首先在k8s-m1节点产生所有 master 节点的 kubelet 凭证,这边通过下面脚本来产生:
for NODE in k8smaster ; do
echo "--- $NODE ---"
cp kubelet-csr.json kubelet-$NODE-csr.json;
sed -i "s/\$NODE/$NODE/g" kubelet-$NODE-csr.json;
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-hostname=$NODE \
-profile=kubernetes \
kubelet-$NODE-csr.json | cfssljson -bare ${PKI_DIR}/kubelet-$NODE;
rm kubelet-$NODE-csr.json
done
ls ${PKI_DIR}/kubelet*.pem注:
1、k8smaster为服务器IP
产生完成后,将kubelet凭证复制到所有master节点上:
for NODE in k8smaster; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p ${PKI_DIR}"
scp ${PKI_DIR}/ca.pem ${NODE}:${PKI_DIR}/ca.pem
scp ${PKI_DIR}/kubelet-$NODE-key.pem ${NODE}:${PKI_DIR}/kubelet-key.pem
scp ${PKI_DIR}/kubelet-$NODE.pem ${NODE}:${PKI_DIR}/kubelet.pem
rm ${PKI_DIR}/kubelet-$NODE-key.pem ${PKI_DIR}/kubelet-$NODE.pem
done接着利用 kubectl 来产生 kubelet 的 kubeconfig 文件,这边通过脚本来产生所有master节点的文件:
for NODE in k8smaster; do
echo "--- $NODE ---"
ssh ${NODE} "cd ${PKI_DIR} && \
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config set-credentials system:node:${NODE} \
--client-certificate=${PKI_DIR}/kubelet.pem \
--client-key=${PKI_DIR}/kubelet-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config set-context system:node:${NODE}@kubernetes \
--cluster=kubernetes \
--user=system:node:${NODE} \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config use-context system:node:${NODE}@kubernetes \
--kubeconfig=${K8S_DIR}/kubelet.conf"
done3.4.7 Service Account Key
Kubernetes Controller Manager 利用 Key pair 来产生与签署 Service Account 的 tokens,而这边不通过 CA 做认证,而是建立一组公私钥来让 API Server 与 Controller Manager 使用:
openssl genrsa -out ${PKI_DIR}/sa.key 2048
openssl rsa -in ${PKI_DIR}/sa.key -pubout -out ${PKI_DIR}/sa.pub
ls ${PKI_DIR}/sa.*删除不必要文件
当所有文件建立与产生完成后,将一些不必要文件删除:
rm -rf ${PKI_DIR}/*.csr \
${PKI_DIR}/scheduler*.pem \
${PKI_DIR}/controller-manager*.pem \
${PKI_DIR}/admin*.pem \
${PKI_DIR}/kubelet*.pem复制文件至其他节点
凭证将复制到其他master节点:
for NODE in k8smaster; do
echo "--- $NODE ---"
for FILE in $(ls ${PKI_DIR}); do
scp ${PKI_DIR}/${FILE} ${NODE}:${PKI_DIR}/${FILE}
done
done复制kubeconfig文件至其他master节点:
for NODE in k8smaster; do
echo "--- $NODE ---"
for FILE in admin.conf controller-manager.conf scheduler.conf; do
scp ${K8S_DIR}/${FILE} ${NODE}:${K8S_DIR}/${FILE}
done
done3.4.8
在首先k8s-m1节点展示进入k8s-manual-files目录,并依序执行下述指令来完成部署:
cd ~/k8s-manual-files
export NODES="k8smaster"
./hack/gen-configs.sh
./hack/gen-manifests.sh
rm -rf /etc/kubernetes/manifests/*注:
1、NODES为master服务器机器名,已经配置完免登录,免登录如何配置参考上一篇文章
确认上述两个产生文件步骤完成后,即可设定所有master节点的 kubelet systemd 来启动 Kubernetes 组件。首先复制下列文件到指定路径:
for NODE in k8smaster; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /var/lib/kubelet /var/log/kubernetes /var/lib/etcd /etc/systemd/system/kubelet.service.d"
scp master/var/lib/kubelet/config.yml ${NODE}:/var/lib/kubelet/config.yml
scp master/systemd/kubelet.service ${NODE}:/lib/systemd/system/kubelet.service
scp master/systemd/10-kubelet.conf ${NODE}:/etc/systemd/system/kubelet.service.d/10-kubelet.conf
done4 Kubernetes Masters
本节将说明如何部署与设定Kubernetes Master角色中的各组件,在开始前先简单了解一下各组件功能:
1. kubelet:负责管理容器的生命周期,定期从 API Server 取得节点上的预期状态(如网络、储存等等配置)资源,并呼叫对应的容器接口(CRI、CNI 等)来达成这个状态。任何 Kubernetes 节点都会拥有该组件。
2. kube-apiserver:以 REST APIs 提供 Kubernetes 资源的 CRUD,如授权、认证、访问控制与 API 注册等机制。
3. kube-controller-manager:通过核心控制循环(Core Control Loop)监听 Kubernetes API 的资源来维护集群的状态,这些资源会被不同的控制器所管理,如 Replication Controller、Namespace Controller 等等。而这些控制器会处理着自动扩展、滚动更新等等功能。
4. kube-scheduler:负责将一个(或多个)容器依据排程策略分配到对应节点上让容器引擎(如 Docker)执行。而排程受到 QoS 要求、软硬件约束、亲和性(Affinity)等等规范影响。
5. Etcd:用来保存集群所有状态的 Key/Value 储存系统,所有 Kubernetes 组件会通过 API Server 来跟 Etcd 进行沟通来保存或取得资源状态。
6. HAProxy:提供多个 API Server 的负载平衡(Load Balance)。
7. Keepalived:建立一个虚拟 IP(VIP) 来作为 API Server 统一存取端点。
而上述组件除了 kubelet 外,其他将通过 kubelet 以 Static Pod 方式进行部署,这种方式可以减少管理 Systemd 的服务,并且能通过 kubectl 来观察启动的容器状况。
以下部分与全容器话部署有差异
此处跳过了Keepalived安装,Keepalived安装可以参考其他文档,用于apiserver的vip-ip,由于我只有一个master所以省略。
4.1 编辑etcd配置文件
4.1.1 编辑服务文件
vi /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
[Service]
Type=notify
WorkingDirectory=/app/etcd/work
EnvironmentFile=/etc/etcd/etcd.conf
ExecStart=/usr/bin/etcd $ETCD_ARGS
[Install]
WantedBy=multi-user.target4.1.2 编辑etcd配置文件
vi /etc/etcd/etcd.conf
ETCD_ARGS="--config-file=/etc/etcd/config.yml"4.1.3 编辑config.yml
mkdir -p /app/etcd/{wal,data,work}
echo '' > /etc/etcd/config.yml
vi /etc/etcd/config.yml
name: 'k8smaster'
data-dir: /app/etcd/data/
wal-dir: /app/etcd/wal/
snapshot-count: 10000
heartbeat-interval: 100
election-timeout: 1000
quota-backend-bytes: 0
listen-peer-urls: 'https://0.0.0.0:2380'
listen-client-urls: 'https://0.0.0.0:2379'
max-snapshots: 5
max-wals: 5
cors:
initial-advertise-peer-urls: 'https://192.168.200.221:2380'
advertise-client-urls: 'https://192.168.200.221:2379'
discovery:
discovery-fallback: 'proxy'
discovery-proxy:
discovery-srv:
# example: hostname=https://ip:2380, ...,
initial-cluster: 'k8smaster=https://192.168.200.221:2380'
initial-cluster-token: 'k8s-etcd-cluster'
initial-cluster-state: 'new'
strict-reconfig-check: false
enable-v2: true
enable-pprof: true
proxy: 'off'
proxy-failure-wait: 5000
proxy-refresh-interval: 30000
proxy-dial-timeout: 1000
proxy-write-timeout: 5000
proxy-read-timeout: 0
client-transport-security:
ca-file: '/etc/etcd/ssl/etcd-ca.pem'
cert-file: '/etc/etcd/ssl/etcd.pem'
key-file: '/etc/etcd/ssl/etcd-key.pem'
client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/etcd-ca.pem'
auto-tls: true
peer-transport-security:
ca-file: '/etc/etcd/ssl/etcd-ca.pem'
cert-file: '/etc/etcd/ssl/etcd.pem'
key-file: '/etc/etcd/ssl/etcd-key.pem'
peer-client-cert-auth: true
trusted-ca-file: '/etc/etcd/ssl/etcd-ca.pem'
auto-tls: true
debug: false
log-package-levels:
log-output: default
force-new-cluster: false4.1.4 启动etcd服务
systemctl daemon-reload
systemctl enable etcd.service
systemctl start etcd.service4.1.5 验证etcd服务
systemctl status etcd.service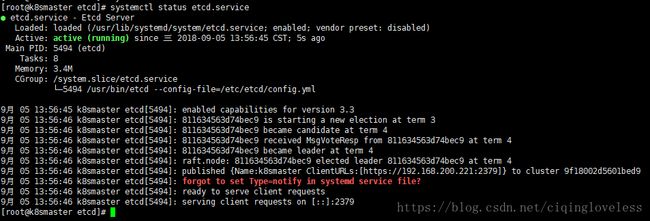
4.2 apiserver服务
4.2.1 复制kubernetes相关二进制文件
将kube-apiserver、kube-controller-manager和kube-scheduler等文件复制到/usr/bin目录下
4.2.2 设置apiserver服务文件
vi /usr/lib/systemd/system/kube-apiserver.service
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=etcd.service
Wants=etcd.service
[Service]
EnvironmentFile=/etc/kubernetes/apiserver
ExecStart=/usr/bin/kube-apiserver $KUBE_API_ARGS
Restart=on-failure
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target4.2.3 编辑encryption/config.yml
vi /etc/kubernetes/encryption/config.yml4.2.3编辑配置文件
mkdir -p /etc/kubernetes
vi /etc/kubernetes/apiserver
KUBE_API_ARGS="--v=0 \
--logtostderr=true \
--allow-privileged=true \
--bind-address=0.0.0.0 \
--secure-port=6443 \
--insecure-port=0 \
--advertise-address=192.168.200.221 \
--service-cluster-ip-range=10.96.0.0/12 \
--service-node-port-range=2000-32767 \
--etcd-servers=https://192.168.200.221:2379 \
--etcd-cafile=/etc/etcd/ssl/etcd-ca.pem \
--etcd-certfile=/etc/etcd/ssl/etcd.pem \
--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \
--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \
--kubelet-client-certificate=/etc/kubernetes/pki/apiserver.pem \
--kubelet-client-key=/etc/kubernetes/pki/apiserver-key.pem \
--service-account-key-file=/etc/kubernetes/pki/sa.pub \
--requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.pem \
--proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.pem \
--proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client-key.pem \
--requestheader-allowed-names=front-proxy-client \
--requestheader-group-headers=X-Remote-Group \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-username-headers=X-Remote-User \
--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname \
--disable-admission-plugins=PersistentVolumeLabel \
--enable-admission-plugins=NodeRestriction \
--authorization-mode=Node,RBAC \
--enable-bootstrap-token-auth=true \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=128 \
--audit-log-path=/var/log/kubernetes/audit.log \
--audit-policy-file=/etc/kubernetes/audit/policy.yml \
--experimental-encryption-provider-config=/etc/kubernetes/encryption/config.yml \
--event-ttl=1h"注:
- –service-cluster-ip-range=10.96.0.0/12 为集群内部ip
- –advertise-address=192.168.200.221为apiservice绑定ip,如有keepalive写vip-ip
- –etcd-servers=https://192.168.200.221:2379为etcd地址,有多个写多个逗号隔开
4.3 kube-controller-manager服务
4.3.1 设置kube-controller-manager服务文件
vi /usr/lib/systemd/system/kube-controller-manager.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https//github.com/GoogleCloudPlatform/kubernetes
After=kube-apiserver.service
Requires=kube-apiserver.service
[Service]
EnvironmentFile=/etc/kubernetes/controller-manager
ExecStart=/usr/bin/kube-controller-manager $KUBE_CONTROLLER_MANAGER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target编辑kube-controller-manager配置文件
vi /etc/kubernetes/controller-manager
KUBE_CONTROLLER_MANAGER_ARGS="--v=0 \
--logtostderr=true \
--address=127.0.0.1 \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-private-key-file=/etc/kubernetes/pki/sa.key \
--kubeconfig=/etc/kubernetes/controller-manager.conf \
--leader-elect=true \
--use-service-account-credentials=true \
--node-monitor-grace-period=40s \
--node-monitor-period=5s \
--pod-eviction-timeout=2m0s \
--controllers=*,bootstrapsigner,tokencleaner \
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \
--node-cidr-mask-size=24"4.4 kube-scheduler服务
4.4.1 设置kube-scheduler服务文件
vi /usr/lib/systemd/system/kube-scheduler.service
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=kube-apiserver.service
Requires=kube-apiserver.service
[Service]
EnvironmentFile=/etc/kubernetes/scheduler
ExecStart=/usr/bin/kube-scheduler $KUBE_SCHEDULER_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target4.4.2 编辑kube-scheduler配置文件
vi /etc/kubernetes/scheduler
KUBE_SCHEDULER_ARGS="--v=0 \
--logtostderr=true \
--address=127.0.0.1 \
--leader-elect=true \
--kubeconfig=/etc/kubernetes/scheduler.conf"4.6 同步文件
将上诉文件scp至所有master服务器
4.5 启动服务
分别在所有master上启动
systemctl daemon-reload
systemctl enable kube-apiserver.service
systemctl start kube-apiserver.service
systemctl enable kube-controller-manager.service
systemctl start kube-controller-manager.service
systemctl enable kube-scheduler.service
systemctl start kube-scheduler.service4.6 建立 TLS Bootstrapping
由于本教程采用 TLS 认证来确保 Kubernetes 集群的安全性,因此每个节点的 kubelet 都需要通过 API Server 的 CA 进行身份验证后,才能与 API Server 进行沟通,而这过程过去都是采用手动方式针对每台节点(master与node)单独签署凭证,再设定给 kubelet 使用,然而这种方式是一件繁琐的事情,因为当节点扩展到一定程度时,将会非常费时,甚至延伸初管理不易问题。
而由于上述问题,Kubernetes 实现了 TLS Bootstrapping 来解决此问题,这种做法是先让 kubelet 以一个低权限使用者(一个能存取 CSR API 的 Token)存取 API Server,接着对 API Server 提出申请凭证签署请求,并在受理后由 API Server 动态签署 kubelet 凭证提供给对应的node节点使用。具体作法请参考 TLS Bootstrapping 与 Authenticating with Bootstrap Tokens。
4.6.1在k8s-master1建立bootstrap使用者的kubeconfig
export TOKEN_ID=$(openssl rand 3 -hex)
export TOKEN_SECRET=$(openssl rand 8 -hex)
export BOOTSTRAP_TOKEN=${TOKEN_ID}.${TOKEN_SECRET}
export KUBE_APISERVER="https://192.168.200.221:6443"kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
kubectl config set-credentials tls-bootstrap-token-user \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
kubectl config set-context tls-bootstrap-token-user@kubernetes \
--cluster=kubernetes \
--user=tls-bootstrap-token-user \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
kubectl config use-context tls-bootstrap-token-user@kubernetes \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf4.6.2接着在k8s-m1建立TLS Bootstrap Secret
export KUBECONFIG=/etc/kubernetes/admin.conf
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-${TOKEN_ID}
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
token-id: "${TOKEN_ID}"
token-secret: "${TOKEN_SECRET}"
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token
EOF
secret/bootstrap-token-e371c7 created4.6.3建立TLS Bootstrap Autoapprove RBAC来提供自动受理CSR
$ cd ~/k8s-manual-files/
$ kubectl apply -f master/resources/kubelet-bootstrap-rbac.yml
clusterrolebinding.rbac.authorization.k8s.io/kubelet-bootstrap created
clusterrolebinding.rbac.authorization.k8s.io/node-autoapprove-bootstrap created
clusterrolebinding.rbac.authorization.k8s.io/node-autoapprove-certificate-rotation created4.7 验证Master节点
cp /etc/kubernetes/admin.conf ~/.kube/config
kubectl get cs
5 Kubernetes Nodes
本节将说明如何建立与设定 Kubernetes Node 节点,Node 是主要执行容器实例(Pod)的工作节点。这过程只需要将 PKI、Bootstrap conf 等文件复制到机器上,再用 kubelet 启动即可。
在开始部署前,在k8smaster将需要用到的文件复制到所有node节点上:
cd ~/k8s-manual-files/
for NODE in k8snode1; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /etc/kubernetes/pki/"
for FILE in pki/ca.pem pki/ca-key.pem bootstrap-kubelet.conf; do
scp /etc/kubernetes/${FILE} ${NODE}:/etc/kubernetes/${FILE}
done
done5.1 部署与设定
确认文件都复制后,即可设定所有node节点的 kubelet systemd 来启动 Kubernetes 组件。首先在k8s-m1复制下列文件到指定路径:
cd ~/k8s-manual-files
for NODE in k8snode1; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /var/lib/kubelet /var/log/kubernetes /var/lib/etcd /etc/systemd/system/kubelet.service.d /etc/kubernetes/manifests"
scp node/var/lib/kubelet/config.yml ${NODE}:/var/lib/kubelet/config.yml
done5.2 kubelet服务
5.2.1 设置kubelet服务
vi /usr/lib/systemd/system/kubelet.service
[Unit]
Description=Kubernetes Kubelet Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/app/kubernetes/kubelet
EnvironmentFile=/etc/kubernetes/kubelet
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_SYSTEM_ARGS $KUBELET_EXTRA_ARGS
Restart=on-failure
[Install]
WantedBy=multi-user.target5.2.2 配置文件
vi /etc/kubernetes/kubelet
KUBELET_KUBECONFIG_ARGS="--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf \
--kubeconfig=/etc/kubernetes/kubelet.conf"
KUBELET_SYSTEM_ARGS="--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin"
KUBELET_CONFIG_ARGS="--config=/var/lib/kubelet/config.yml"5.2.3 启动服务
for NODE in k8snode1; do
ssh ${NODE} "systemctl enable kubelet.service && systemctl start kubelet.service"
done5.2.4 验证服务
在master节点
kubectl get csr5.2.5 开启查询日志权限
cd /root/k8s-manual-files
kubectl apply -f master/resources/apiserver-to-kubelet-rbac.yml
二 Kubernetes Core Addons部署
1 Kubernetes Proxy
1.1 启动linux中的IPVS(所有节点执行)
cat << EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
ipvs_modules_dir="/usr/lib/modules/\`uname -r\`/kernel/net/netfilter/ipvs"
for i in \`ls \$ipvs_modules_dir | sed -r 's#(.*).ko.xz#\1#'\`; do
/sbin/modinfo -F filename \$i &> /dev/null
if [ \$? -eq 0 ]; then
/sbin/modprobe \$i
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs
cp /etc/sysconfig/modules/ipvs.modules /lib/modules
kube-proxy 是实现 Kubernetes Service 资源功能的关键组件,这个组件会通过 DaemonSet 在每台节点上执行,然后监听 API Server 的 Service 与 Endpoint 资源对象的事件,并依据资源预期状态通过 iptables 或 ipvs 来实现网络转发,而本次安装采用 ipvs。
1.2 生成kube-proxy证书与私钥
export K8S_DIR=/etc/kubernetes
export PKI_DIR=${K8S_DIR}/pki
export KUBE_APISERVER=https://192.168.200.221:6443
cd /root/k8s-manual-files/pki
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
kube-proxy-csr.json | cfssljson -bare ${PKI_DIR}/kube-proxy
ls ${PKI_DIR}/kube-proxy*.pem接着利用kubectl来产生kube-proxy的kubeconfig档:
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/kube-proxy.conf
kubectl config set-credentials system:kube-proxy \
--client-certificate=${PKI_DIR}/kube-proxy.pem \
--client-key=${PKI_DIR}/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/kube-proxy.conf
kubectl config set-context system:kube-proxy@kubernetes \
--cluster=kubernetes \
--user=system:kube-proxy \
--kubeconfig=${K8S_DIR}/kube-proxy.conf
kubectl config use-context system:kube-proxy@kubernetes \
--kubeconfig=${K8S_DIR}/kube-proxy.conf在k8s-m1通过kubeclt执行下面指令来建立,并检查是否部署成功:
1.2 设置kubelet服务
vi /usr/lib/systemd/system/kube-proxy.service
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.service
Requires=network.service
[Service]
EnvironmentFile=/etc/kubernetes/proxy
ExecStart=/usr/bin/kube-proxy $KUBE_PROXY_ARGS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target1.3 配置文件
vi /etc/kubernetes/proxy
KUBE_PROXY_ARGS="--masquerade-all \
--feature-gates=SupportIPVSProxyMode=true \
--proxy-mode=ipvs \
--ipvs-min-sync-period=5s \
--ipvs-sync-period=5s \
--ipvs-scheduler=rr \
--kubeconfig=/etc/kubernetes/kube-proxy.conf \
--cluster-cidr=10.96.0.0/12"1.4 将配置文件拷贝到所有节点
for NODE in k8smaster k8snode1; do
echo "--- $NODE ---"
scp ${K8S_DIR}/kube-proxy.conf ${NODE}:${K8S_DIR}/kube-proxy.conf
scp -r ${PKI_DIR}/kube-proxy*.pem ${NODE}:${PKI_DIR}/
scp /etc/kubernetes/proxy ${NODE}:/etc/kubernetes/proxy
scp /usr/lib/systemd/system/kube-proxy.service ${NODE}:/usr/lib/systemd/system/kube-proxy.service
done1.5 启动服务
for NODE in k8snode1; do
ssh ${NODE} "systemctl enable kube-proxy.service && systemctl start kube-proxy.service"
done
2 CoreDNS
本节将通过 CoreDNS 取代 Kube DNS 作为集群服务发现组件,由于 Kubernetes 需要让 Pod 与 Pod 之间能够互相沟通,然而要能够沟通需要知道彼此的 IP 才行,而这种做法通常是通过 Kubernetes API 来取得达到,但是 Pod IP 会因为生命周期变化而改变,因此这种做法无法弹性使用,且还会增加 API Server 负担,基于此问题 Kubernetes 提供了 DNS 服务来作为查询,让 Pod 能够以 Service 名称作为域名来查询 IP 地址,因此用户就再不需要关切实际 Pod IP,而 DNS 也会根据 Pod 变化更新资源纪录(Record resources)。
CoreDNS 是由 CNCF 维护的开源 DNS 项目,该项目前身是 SkyDNS,其采用了 Caddy 的一部分来开发服务器框架,使其能够建构一套快速灵活的 DNS,而 CoreDNS 每个功能都可以被实作成一个插件的中间件,如 Log、Cache、Kubernetes 等功能,甚至能够将源纪录储存至 Redis、Etcd 中。
在k8s-m1通过kubeclt执行下面指令来建立,并检查是否部署成功:
2.1 下载镜像
由于国外镜像被墙,所以需要修改一下配置文件
vi /root/k8s-manual-files/addons/coredns/coredns-dp.yml
将如图位置修改为
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.1.3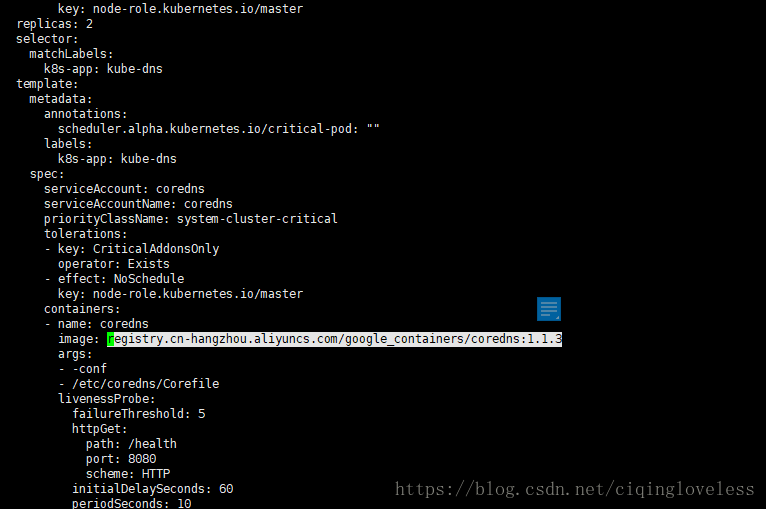
2.2 启动服务
因为需要下载镜像所以启动根据网速会不同
cd /root/k8s-manual-files/addons
$ kubectl create -f coredns/
$ kubectl -n kube-system get po -l k8s-app=kube-dns这边会发现 Pod 处于Pending状态,这是由于 Kubernetes 的集群网络没有建立,因此所有节点会处于NotReady状态,而这也导致 Kubernetes Scheduler 无法替 Pod 找到适合节点而处于Pending,为了解决这个问题,下节将说明与建立 Kubernetes 集群网络。
注:
1、若 Pod 是被 DaemonSet 管理的话,则不会 Pending,不过若没有设定hostNetwork则会出问题。

3 Kubernetes集群网路
Kubernetes 在默认情况下与 Docker 的网络有所不同。在 Kubernetes 中有四个问题是需要被解决的,分别为:
• 高耦合的容器到容器沟通:通过 Pods 与 Localhost 的沟通来解决。
• Pod 到 Pod 的沟通:通过实现网络模型来解决。
• Pod 到 Service 沟通:由 Services object 结合 kube-proxy 解决。
• 外部到 Service 沟通:一样由 Services object 结合 kube-proxy 解决。
而 Kubernetes 对于任何网络的实现都需要满足以下基本要求(除非是有意调整的网络分段策略):
• 所有容器能够在没有 NAT 的情况下与其他容器沟通。
• 所有节点能够在没有 NAT 情况下与所有容器沟通(反之亦然)。
• 容器看到的 IP 与其他人看到的 IP 是一样的。
庆幸的是 Kubernetes 已经有非常多种的网络模型以网络插件(Network Plugins)方式被实现,因此可以选用满足自己需求的网络功能来使用。另外 Kubernetes 中的网络插件有以下两种形式:
• CNI plugins:以 appc/CNI 标准规范所实现的网络,详细可以阅读 CNI Specification。
• Kubenet plugin:使用 CNI plugins 的 bridge 与 host-local 来实现基本的 cbr0。这通常被用在公有云服务上的 Kubernetes 集群网络。
3.1 网路部署与设定
从上述了解 Kubernetes 有多种网络能够选择,而本教学选择了 Calico 作为集群网络的使用。Calico 是一款纯 Layer 3 的网络,其好处是它整合了各种云原生平台(Docker、Mesos 与 OpenStack 等),且 Calico 不采用 vSwitch,而是在每个 Kubernetes 节点使用 vRouter 功能,并通过 Linux Kernel 既有的 L3 forwarding 功能,而当数据中心复杂度增加时,Calico 也可以利用 BGP route reflector 来达成。
由于 Calico 提供了 Kubernetes resources YAML 文件来快速以容器方式部署网络插件至所有节点上,因此只需要在k8s-m1通过 kubeclt 执行下面指令来建立:
修改配置文件
也是由于镜像被墙, 所以修改配置文件
vi /root/k8s-manual-files/cni/calico/v3.1/calico.yml
将quay.io/calico/typha:v0.7.4替换为registry.cn-hangzhou.aliyuncs.com/criss/quay.io-calico-typha:v0.7.4
将quay.io/calico/cni:v3.1.3替换为registry.cn-hangzhou.aliyuncs.com/criss/quay.io-calico-cni:v3.1.3$ cd ~/k8s-manual-files
$ sed -i 's/192.168.0.0\/16/10.244.0.0\/16/g' cni/calico/v3.1/calico.yml
$ kubectl create -f cni/calico/v3.1/1、这边要记得将CALICO_IPV4POOL_CIDR的网络修改 Cluster IP CIDR。此配置为10.244.0.0为集群ip
2、另外当节点超过 50 台,可以使用 Calico 的 Typha 模式来减少通过 Kubernetes datastore 造成 API Server 的负担
部署后通过kubectl检查是否有启动:
$ kubectl -n kube-system get po -l k8s-app=calico-node3.2 检查是否成功
kubectl -n kube-system get po -l k8s-app=calico-node
kubectl -n kube-system get po -l k8s-app=kube-dns
kubectl get node
3.3 问题排查
若无法启动可以用如下代码进行日志查看,根据日志进行错误排查
kubectl -n kube-system logs calico-node-hqlvd calico-node
kubectl -n kube-system logs calico-node-hqlvd install-cni