Oracle 分析函数、聚合函数的简单使用 学习笔记+实例
分析函数也称为窗口函数,其功能为在一定的数据范围进行排序、汇总等,多用于大型报表产生累计值,滑动平均值,中心值以及汇总报表。
1.分析函数结构分析
分析函数语句结构:
function (argument1,argument2,...argumentN)
over ([partition-by-clause] [order-by-clause] [windowing-clause])由标准语句中可以看到分析函数由三部分组成
1.[partition-by-clause] 分区子句
2.[order-by-clause] 排序子句
3.[windowing-clause] 开窗子句
其含义为按照分区语句的条件将数据分区并排序,根据开窗语句选择数据区(即用于执行分析函数的数据具体有哪些),然后根据参数(argument1…)执行分析函数(function)。
分析函数表

2.分析函数实例解析
SELECT d.department_name,e.last_name,e.salary,
rank() over(PARTITION BY d.department_name ORDER BY e.salary DESC) dept_salary_rank1,
percent_rank() over(PARTITION BY d.department_name ORDER BY e.salary DESC) dept_salary_rank2,
row_number() over(PARTITION BY d.department_name ORDER BY e.salary) dept_salary_rank3
FROM employees e, departments d
WHERE 1 = 1
AND e.department_id = d.department_id;执行结果:

语句分析:
(1) rank() over(PARTITION BY d.department_name ORDER BY e.salary DESC) dept_salary_rank1,
1>分区子句:partiton by 这里按照部门名称进行分区
2>排序子句:order by 这里按照薪水进行排序
3>开窗子句:暂未用到
4>分析函数:rank()即按照排序后的顺序进行排名
因此这条语句的意思为按部门进行分区,按降序薪水排序后在新的一列dept_salary_rank1显示他们的排名。
(2) percent_rank() over(PARTITION BY d.department_name ORDER BY e.salary DESC) dept_salary_rank2,
以第15~19行数据为例,percent_rank()意为按照排名标准化为0~1之间的值,5~6行数据中为排名并列的情况。
因此此语句的意思为按部门进行分区,按薪水降序排序后在新的一列dept_salary_rank1显示以0~1之间的标准值显示他们的排名。
(3) row_number() over(PARTITION BY d.department_name ORDER BY e.salary) dept_salary_rank3
row_number()意为对排序后的每一行增加一个唯一编号,此处图中与rank1列不同的原因是这条语句采用的是升序!!!
3.聚合函数的分析模式运算
聚合函数又称为组函数,即sum(),avg(),count()这些常见的数据处理函数,而组函数一般用于搭配group by语句进行分组运算,而其实组函数也可以使用类似分析函数的分析模式来进行数据操作。
其结构如下:
function (argument1,argument2,...argumentN)
over ([partition-by-clause] [order-by-clause] [windowing-clause])即function处使用组函数即可
实例如下:
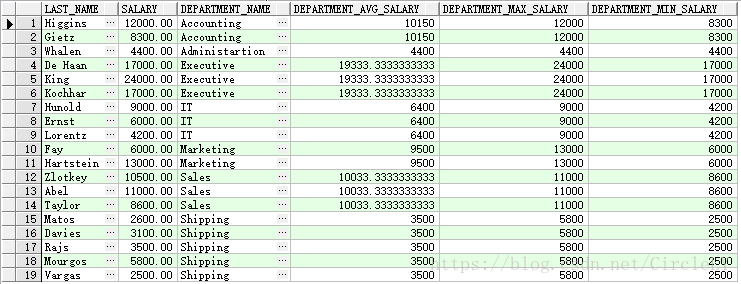
SELECT e.last_name,e.salary,d.department_name,
AVG(e.salary) over(PARTITION BY d.department_name) department_avg_salary,
MAX(e.salary) over(PARTITION BY d.department_name) department_max_salary,
MIN(e.salary) over(PARTITION BY d.department_name) department_min_salary
FROM employees e, departments d
WHERE 1 = 1 AND e.department_id = d.department_id;运行结果:
4.开窗子句
4.1 默认的开窗子句
在未显示的使用开窗语句时,分析函数会使用默认的开窗语句,默认语句如下:rows between unbounded preceding and current row
其含义为从分区的开头行到当前行。
4.2 开窗子句的语法格式
[rows|range] between and [end expr] start expr和end expr两个参数的值可以为unbounded following(无限制的)、current row(当前行)、 n preceding(向前n行)、 n following(向后n行)。
例:rows between unbounded following and unbouned following
即针对当前表中之前的所有数据与之后的所有数据。
注:并非所有的分析函数都可以使用开窗子句。
4.3 使用实例解析
实例代码:
SELECT d.department_name, e.last_name, e.salary,
sum(e.salary) over(PARTITION BY d.department_name) department_sum1_salary,
-- 此处使用默认的开窗子句
SUM(e.salary) over(PARTITION BY d.department_name order by e.salary ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) department_sum2_salary
-- 此处使用自定义开窗子句,为选择上一条数据到下一条数据区域
FROM employees e, departments d
WHERE 1 = 1 AND e.department_id = d.department_id;执行结果:

结果分析:
图中sum1列计算部门薪资总和,sum2列则根据开窗子句选择计算当前数据与上一条数据和下一条数据的薪资总和,对比图中第15~19行sum1列与sum2列的区别,可以明显观察到此结果,因此开窗子句是最后一部筛选数据区域的语句。
以上为本人学习Oracle后的个人理解与总结,如有错误还望指正修改,欢迎交流~
转载留个言哈~