Kubernetes之服务发现Service
一、service的概念
在Kubernetes中,Pod是有生命周期的,当Pod的生命周期结束之后,Pod会被重新分配IP。这样就会导致一个问题:在Kubernetes集群中,如果一组Pod(称为backend)为其他Pod(称为frontend)提供服务,那么那些frontend该如何发现并连接到作为backend的Pod呢?
Kubernetes中service是一组提供相同功能的Pods的抽象,并为他们提供一个同意的入口。借助Service,应用可以方便的实现服务发现于负载均衡,并实现应用的零宕机升级。Service通过spec.selector来选取后端服务,一般配合ReplicationController或者Deployment来保证后端容器的正常运行。
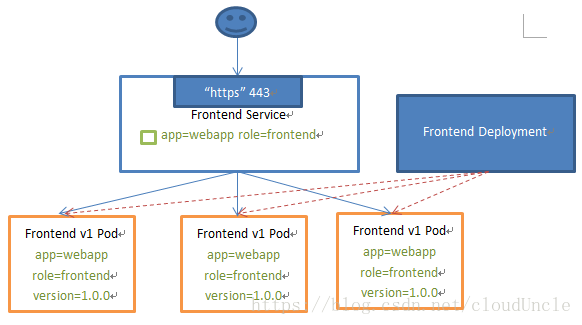
Service能够提供负载均衡的能力,但是在使用上有以下限制:
- 只提供4层负载均衡能力,而没有7层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上4层负载均衡是不支持的
- 使用NodePort类型的Service时,需要在集群外部部署外部的负载均衡器
- 使用LoadBalancer类型的Service时,Kubernetes必须运行在特定的云服务上
二、Service的类型
有以下四种类型:
-
ClusterIp:默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP
-
NodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过
: NodePort来访问该服务 -
LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部负载均衡器,并将请求转发到
: NodePort -
ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。没有任何类型代理被创建,这只有kubernetes 1.7或更高版本的kube-dns才支持
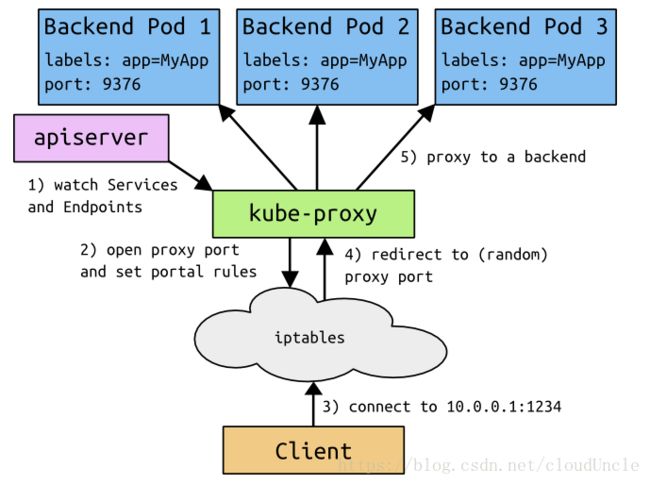
-
ClusterIP
clusterIP主要在每个node节点使用iptables,将发向clusterIP对应端口的数据,转发到kube-proxy中。然后kube-proxy自己内部实现有负载均衡的方法,并可以查询到这个service下对应pod的地址和端口,进而把数据转发给对应的pod的地址和端口 -
NodePort
nodePort的原理在于在node上开了一个端口,将向该端口的流量导入到kube-proxy,然后由kube-proxy进一步到给对应的pod -
LoadBalancer
loadBalancer和nodePort其实是同一种方式。区别在于loadBalancer比nodePort多了一步,就是可以调用cloud provider去创建LB来向节点导流。
1. ClusterIP
此模式会提供一个集群内部的虚拟IP(与Pod不在同一网段),以供集群内部的Pod之间通信使用。
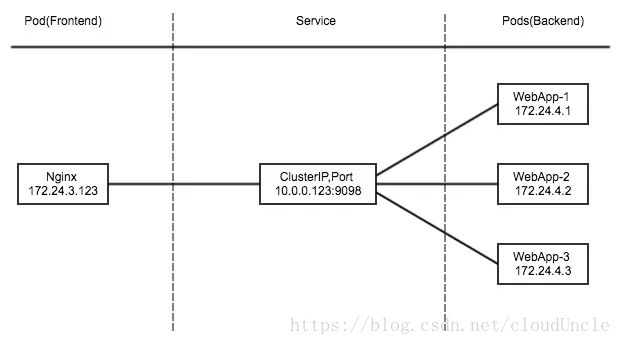
为了实现图上的功能,主要需要以下几个组件的协同工作:
- apiserver 用户通过kubectl命令向apiserver发送创建service的命令,apiserver接收到请求后将数据存储到etcd中
- kube-proxy kubernetes的每个节点中都有一个叫做kube-porxy的进程,这个进程负责感知service,pod的变化,并将变化的信息写入本地的iptables规则中
- iptables 使用NAT等技术将virtualIP的流量转至endpoint中
1.1. 发布一个deployment,并指定replicas为3
创建myapp-deploy.yaml文件
[root@master manifests]# vim myapp-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
env: test
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v2
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
保存退出。
使用kubectl apply命令创建deployment
[root@master manifests]# kubectl apply -f myapp-deploy.yaml
deployment.apps/myapp-deploy created
查看创建好的deployment和pod
[root@master manifests]# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
myapp-deploy 3 3 3 3 7s
[root@master manifests]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy-6d9c8d8797-4k8hl 1/1 Running 0 10s
myapp-deploy-6d9c8d8797-bllxq 1/1 Running 0 10s
myapp-deploy-6d9c8d8797-bvhw2 1/1 Running 0 10s
这样就创建好了副本数为3的deployment了。
1.2. 发布一个service,并指定步骤1中的label
创建myapp-service.yaml文件
[root@master manifests]# vim myapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: ClusterIP
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
使用kubectl apply命令创建service
[root@master manifests]# kubectl apply -f myapp-service.yaml
service/myapp created
[root@master manifests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 12d
myapp ClusterIP 10.100.68.105 80/TCP 4s
这样就创建好ClusterIP类型的service了。此时myapp的Cluster-IP(也可以称为VirtualIP)为10.100.68.105。
查看myapp的endpoint信息:
[root@master manifests]# kubectl get endpoints
NAME ENDPOINTS AGE
kubernetes 192.168.116.130:6443 12d
myapp 10.244.1.29:80,10.244.2.32:80,10.244.2.33:80 10m
然后查看刚刚创建出来的pod的信息:
[root@master manifests]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-6d9c8d8797-4k8hl 1/1 Running 0 33m 10.244.1.29 node1
myapp-deploy-6d9c8d8797-bllxq 1/1 Running 0 33m 10.244.2.33 node2
myapp-deploy-6d9c8d8797-bvhw2 1/1 Running 0 33m 10.244.2.32 node2
可以发现myapp对应的endpoint刚好是三个pod的地址
1.3. 查看iptables,观察其NAT表中的信息(只截取了部分和这个servcie有关的信息)
查看iptables中NAT表的命令:iptables -t nat -nvL
[root@master manifests]# iptables -t nat -nvL
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
86 5488 KUBE-SERVICES all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service portals */
268 16156 DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
....
....
Chain KUBE-SERVICES (2 references)
pkts bytes target prot opt in out source destination
...
...
0 0 KUBE-MARK-MASQ tcp -- * * !10.244.0.0/16 10.100.68.105 /* default/myapp:http cluster IP */ tcp dpt:80
0 0 KUBE-SVC-JOCJVTCKLKOLHFVR tcp -- * * 0.0.0.0/0 10.100.68.105 /* default/myapp:http cluster IP */ tcp dpt:80
...
...
Chain KUBE-SVC-JOCJVTCKLKOLHFVR (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-SEP-AJTG34DMLXUWJC3E all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ statistic mode random probability 0.33332999982
0 0 KUBE-SEP-S4C5QHO5KWOWFNCG all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ statistic mode random probability 0.50000000000
0 0 KUBE-SEP-4H47DMTPBM73YXWU all -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */
...
...
Chain KUBE-SEP-AJTG34DMLXUWJC3E (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.244.1.29 0.0.0.0/0 /* default/myapp:http */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ tcp to:10.244.1.29:80
...
...
Chain KUBE-SEP-S4C5QHO5KWOWFNCG (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.244.2.32 0.0.0.0/0 /* default/myapp:http */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ tcp to:10.244.2.32:80
...
...
Chain KUBE-SEP-4H47DMTPBM73YXWU (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ all -- * * 10.244.2.33 0.0.0.0/0 /* default/myapp:http */
0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ tcp to:10.244.2.33:80
在PREROUTING链中会先匹配到KUBE-SERVICES这个Chain;
所有destination IP为10.100.68.105的包都转到KUBE-SVC-JOCJVTCKLKOLHFVR这个Chain;
这里能看到请求会平均执行KUBE-SEP-AJTG34DMLXUWJC3E,KUBE-SEP-S4C5QHO5KWOWFNCG,KUBE-SEP-4H47DMTPBM73YXWU这三个Chain;
最后我们看一下KUBE-SEP-AJTG34DMLXUWJC3E这条Chain:这条Chain使用了DNAT规则将流量转发到10.244.1.29:80这个地址上,这样从其他Pod发出来的流量通过本地的iptables规则将流量转到myapp Service定义的Pod上。
2. NodePort
对于这种类型,Kubernetes将会在每个Node上打开一个端口并且每个Node的端口都是一样的,通过
修改myapp-service.yaml,将Service的type改为NodePort类型。
[root@master manifests]# vim myapp-service.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp
namespace: default
spec:
type: **NodePort**
selector:
app: myapp
release: stabel
ports:
- name: http
port: 80
targetPort: 80
保存退出。
[root@master manifests]# kubectl apply -f myapp-service.yaml
service/myapp configured
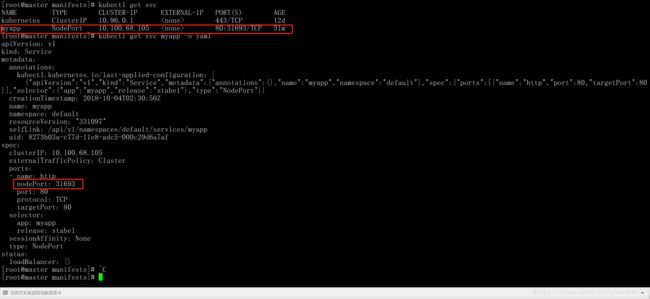
可以看到kubernetes已经随机给我们分配了一个NodePort端口了。
观察iptables中的变化,KUBE-NODEPORTS这个Chain中增加了如下内容
Chain KUBE-NODEPORTS (1 references)
pkts bytes target prot opt in out source destination
0 0 KUBE-MARK-MASQ tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ tcp dpt:31693
0 0 KUBE-SVC-JOCJVTCKLKOLHFVR tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* default/myapp:http */ tcp dpt:31693
可以看到流量会转到KUBE-SVC-JOCJVTCKLKOLHFVR这个Chain中处理一次,也就是ClusterIP中提到的通过负载均衡将流量平均分配到3个endpoint上。
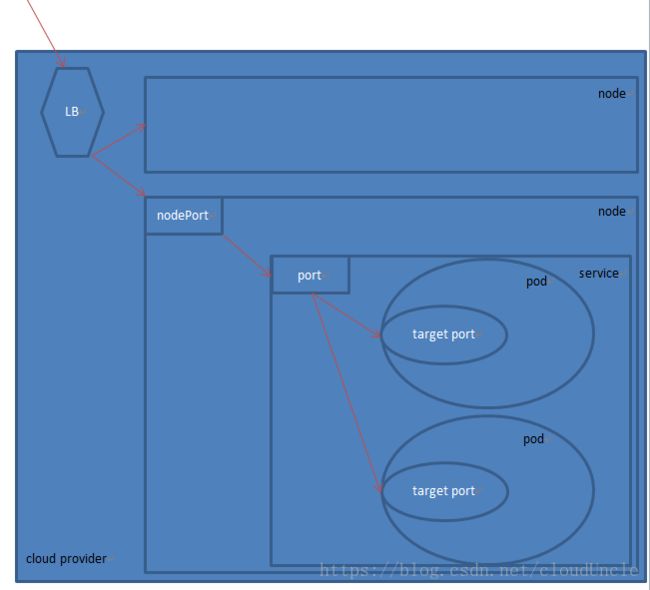
3. LoadBalancer
这种类型Service需要借助cloud provider能力创建LB来向节点导流。
4. ExternalName
这种类型的Service通过返回CNAME和它的值,可以将服务映射到externalName字段的内容(例如:foo.bar.example. com)。
ExternalName Service是Service的特例,它没有selector,也没有定义任何的端口和Endpoint。相反的,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当查询主机my-service.prod.svc.cluster.local(SVC_NAME.NAMESPACE.svc.cluster.local)时,集群的DNS服务将返回一个值my.database.example.com的CNAME记录。访问这个服务的工作方式和其他的相同,唯一不同的是重定向发生在DNS层,而且不会进行代理或转发。
三、Service的实现模式
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现一种VIP(虚拟IP)的形式,而不是ExternalName的形式。在Kubernetes v1.0版本中,代理完全在userspace。在Kubernetes v1.1版本中,新增了iptables代理,但并不是默认的运行模式。从Kubernetes v1.2起,默认就是iptables代理。在Kubernetes v1.8.0-beta.0中,添加了ipvs代理。在Kubernetes v1.0版本中,Service是“4层”(TCP/UDP over IP)概念。在Kubernetes v1.1版本中,新增了Ingress API(beta版),用来表示“7层”(HTTP)服务。
kube-proxy这个组件始终监视着apiserver中有关service的变动信息,获取任何一个与service资源相关的变动状态,通过watch监视,一旦有servcie资源相关的变动和创建,kube-proxy都要转换为当前节点上的能够实现调度的规则(例如:iptables、ipvs)。
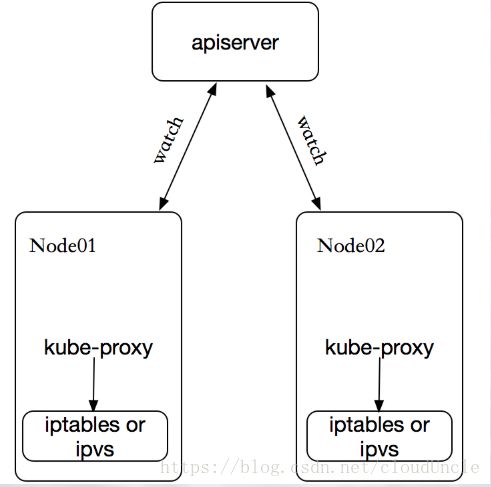
3.1. userspace代理模式
这种模式下,当Client Pod请求内核空间的service ip后,把请求转到用户空间kube-porxy监听的端口,由kube-proxy处理后,再由kube-proxy将请求转给内核空间的service ip,再由service ip根据请求转给各节点中的service pod。
由此可见这个模式将流量反复的从用户空间进出内核空间,这样带来的性能损耗是非常大的。
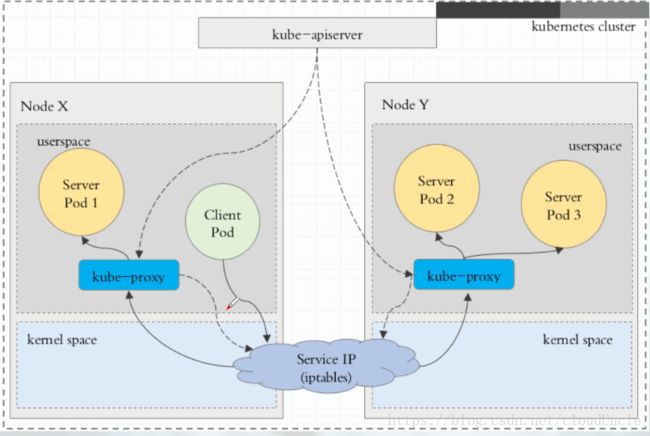
3.2. iptables代理模式
这种模式下,Client Pod直接请求本地内核service ip,根据iptables规则直接将请求转发到各pod上,因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。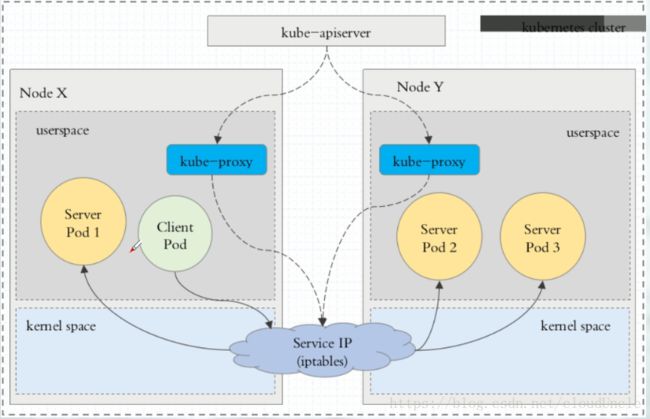
3.3. ipvs代理模式
这种模式下,Client Pod请求到达内核空间时,根据ipvs规则直接分发到各Pod上。kube-proxy会监视Kubernetes Service对象和Endpoints,调用netlink接口以相应的创建ipvs规则并定期与Kubernetes Service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter的hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快的重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq:不排队调度
注意: ipvs代理模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式
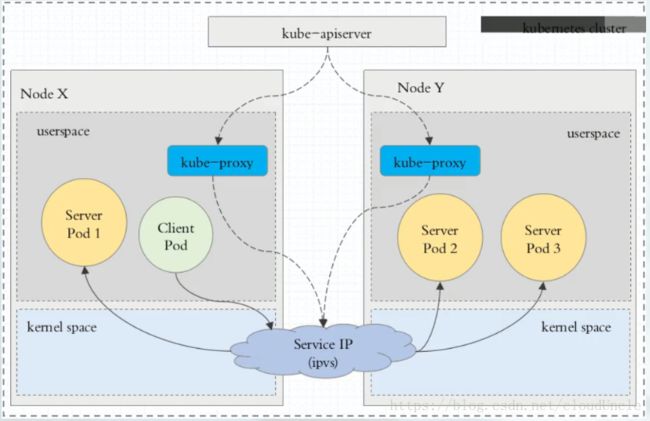
如果某一个服务后端pod发生变化,标签选择器适应的pod又多一个,适应的信息会立即反映到apiserver上,而kube-proxy一定可以watch到etcd中的信息变化,而将它立即转为ipvs或iptables规则中,这一切都是动态和实时的,删除一个pod也是同样的原理。如图:

四、Headless Service
有时不需要或不想要负载均衡,以及单独的Service IP。遇到这种情况,可以通过指定Cluster IP(spec.clusterIP)的值为“None”来创建Headless Service。
这个选项允许开发人员自由的寻找他们自己的方式,从而降低与Kubernetes系统的耦合性。应用仍然可以使用一种自注册的模式和适配器,对其他需要发现机制的系统能够很容易的基于这个API来构建。
对这类Service并不会分配Cluster IP,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由。DNS如何实现自动配置,依赖于Service时候定义了selector。
(1)编写headless service配置清单
[root@k8s-master mainfests]# cp myapp-svc.yaml myapp-svc-headless.yaml
[root@k8s-master mainfests]# vim myapp-svc-headless.yaml
apiVersion: v1
kind: Service
metadata:
name: myapp-headless
namespace: default
spec:
selector:
app: myapp
release: canary
clusterIP: "None" #headless的clusterIP值为None
ports:
- port: 80
targetPort: 80
(2)创建headless service
[root@k8s-master mainfests]# kubectl apply -f myapp-svc-headless.yaml
service/myapp-headless created
[root@k8s-master mainfests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 36d
myapp NodePort 10.101.245.119 80:30080/TCP 1h
myapp-headless ClusterIP None 80/TCP 5s
redis ClusterIP 10.107.238.182 6379/TCP 2h
(3)使用coredns进行解析验证
[root@k8s-master mainfests]# dig -t A myapp-headless.default.svc.cluster.local. @10.96.0.10
; <<>> DiG 9.9.4-RedHat-9.9.4-61.el7 <<>> -t A myapp-headless.default.svc.cluster.local. @10.96.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 62028
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 5, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;myapp-headless.default.svc.cluster.local. IN A
;; ANSWER SECTION:
myapp-headless.default.svc.cluster.local. 5 IN A 10.244.1.18
myapp-headless.default.svc.cluster.local. 5 IN A 10.244.1.19
myapp-headless.default.svc.cluster.local. 5 IN A 10.244.2.15
myapp-headless.default.svc.cluster.local. 5 IN A 10.244.2.16
myapp-headless.default.svc.cluster.local. 5 IN A 10.244.2.17
;; Query time: 4 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Thu Sep 27 04:27:15 EDT 2018
;; MSG SIZE rcvd: 349
[root@k8s-master mainfests]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP 36d
[root@k8s-master mainfests]# kubectl get pods -o wide -l app=myapp
NAME READY STATUS RESTARTS AGE IP NODE
myapp-deploy-69b47bc96d-4hxxw 1/1 Running 0 1h 10.244.1.18 k8s-node01
myapp-deploy-69b47bc96d-95bc4 1/1 Running 0 1h 10.244.2.16 k8s-node02
myapp-deploy-69b47bc96d-hwbzt 1/1 Running 0 1h 10.244.1.19 k8s-node01
myapp-deploy-69b47bc96d-pjv74 1/1 Running 0 1h 10.244.2.15 k8s-node02
myapp-deploy-69b47bc96d-rf7bs 1/1 Running 0 1h 10.244.2.17 k8s-node02
(4)对比含有ClusterIP的service解析
[root@k8s-master mainfests]# dig -t A myapp.default.svc.cluster.local. @10.96.0.10
; <<>> DiG 9.9.4-RedHat-9.9.4-61.el7 <<>> -t A myapp.default.svc.cluster.local. @10.96.0.10
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 50445
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;myapp.default.svc.cluster.local. IN A
;; ANSWER SECTION:
myapp.default.svc.cluster.local. 5 IN A 10.101.245.119
;; Query time: 1 msec
;; SERVER: 10.96.0.10#53(10.96.0.10)
;; WHEN: Thu Sep 27 04:31:16 EDT 2018
;; MSG SIZE rcvd: 107
[root@k8s-master mainfests]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 36d
myapp NodePort 10.101.245.119 80:30080/TCP 1h
myapp-headless ClusterIP None 80/TCP 11m
redis ClusterIP 10.107.238.182 6379/TCP 2h
从以上的演示可以看到对比普通的service和headless service,headless service做dns解析是直接解析到pod的,而servcie是解析到ClusterIP的,那么headless有什么用呢?这将在statefulset中应用到,这里暂时仅仅做了解什么是headless service和创建方法。