Deep Learning的学习实践 3 -- AutoEncoder
首先,讨论一下原始特征数据的处理,这就是传说中的“特征工程”(Feature Engineering),很重要,但是书上不会写。我这里测试使用的是某运营商,做离网预测的数据。经过初步判断,从众多的特征数据中选取相关的147个特征做训练数据。原始数据类别很多,比如:近三个月漫游通话时长,近一个月主叫通话次数,近二个月拨打本网客服的次数,近一月长途通话费用,手机上网流量,手机价格,套餐类型等。这些特征的单位各不相同,数据值差异很大,而且有很多是ID类数据(枚举值)。大多数机器学习模型面对这样的特征数据,都是很难处理的,因为大多数机器学习模型是需要计算数据之间的“距离”的,这么乱的原始数据,是难以处理的。对于一些简单模型,比如逻辑回归,朴素贝叶斯模型,模型本身做了前提假设,假设每个特征之间是相互没有关系的(这个假设其实是个很强的约束),用这类模型可以直接处理这样的原始特征数据,结果肯定比随机猜测好,一般应用还可以接受。但是使用复杂一些的模型,就会有问题,我用DBN测试这种数据的时候,AUC甚至低于0.5,用SDA的时候稍好一点,也不到0.6。所以,首先要对这些特征做归一化处理,因为这个数据集中正例的比率很小,我这里用的归一化方式,是计算每个特征的后验概率。具体说:对于枚举类型的数据(ID类数值),先计算包含该ID的正例样本数 / 包含该ID的总样本数(即后验概率),然后再归一化:x =(x - 当前列的最小值)/ 当前列的最大值 *100。对于金额,流量等连续值数据,如果数值太多,难以计算后验概率(如果每个值只出现一次,那么计算后验概率的结果就只有0和1/N这两个值了),这时可以直接做归一化:x = (x - 当前列的最小值)/ 当前列的最大值*100,归一化后的数据在0~1之间。(分母乘以100是为了让数据接近于0,避免大量出现1。)注意:训练集的数据这样处理后,测试集数据中的枚举值ID类数据,要用训练集中的数据对应的后验概率的概率值,不能重新计算正例样本数/总样本数,因为测试集中应该是没有标注数据的,是不能判断正例样本数的。如果测试集中有的数据在训练集中没有,可以把该后验概率值设置为0。这种数据归一化的方法在应用中是很好的,各种DNN模型基于归一化后的数据测试,AUC可以大幅提升,比如DBN的AUC可以提高到0.678。但是,对于Deep Learning这种“特征学习”而言,这种特征归一的方法也不好解释其原理,后验概率能否说明原始特征的内在特性,并且经过多层神经网络抽象后是什么东西也比较难理解,总体上,AUC不算高,后面再详细分析。
下面介绍第一种Deep Learning 模型,AutoEncoder。这种模型,每一层是对原始特征数据的一个编码器,其目的是使用神经网络去模拟原始数据,而且与原始数据尽可能的接近。
如下图所示: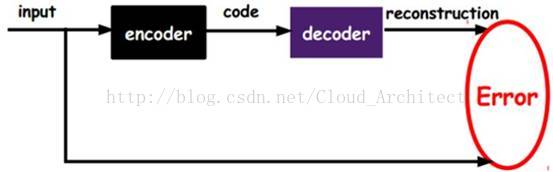
Input是原始数据,encoder就是一层神经网络,输出的是code,就是编码后的数据。实际上训练完后,这一层神经网络不需要decoder(解码器),AutoEncoder只是把Input的原始数据做这一层神经网络的“学习目标”,得到训练好网络参数,就得到了encoder,也就是说学习的目的是通过encoder得到的code要尽量接近原始数据,学习的过程就是减少code与原始数据之间的误差Error,所以decoder的过程其实是这一层神经网络的学习过程,而这一层神经网络在训练完后的输出就是编码后的code。这样做的目的,首先是增加了很多特征,因为这里输出的code,接近于原始特征数据,但不是原始特征,增加特征本身对很多机器学习模型是有用的。
简单的增加特征显然是不够的,所以AutoEncoder 有很多扩展模型,主要的是SparseAutoEncoder(稀疏自编码),和Denoising AutoEncoder(去噪自编码)(Theano中SDA就是多层Denoising AutoEncoder) 。这两种模型的目的都是在大量特征中抛弃一些无用的特征,留下有用的特征(就是关键性的特征),可以理解为表示学习或者特征抽象。
SparseAutoEncoder(稀疏自编码)的基本操作是在encoder编码器其中添加惩罚项参数,使得一些无用的特征权值为0,比如添加L1正则的方法,这样就可以大量减少无用的特征,使其稀疏。“正则化”基本上是对所有复杂的机器学习模型都有用的利器,因为机器学习模型对训练样本的模式学习,随着模型复杂度的上升,很可能会过拟合(模型的表达能力过于逼近训练数据,而忽视了未知的测试数据),造成对测试数据的泛化能力差,“正则化”技术的本质是把loss function的超平面重构问题的求解限制在压缩子集中,也就是用惩罚项,让模型对训练样本的精度和求解的光滑程度(泛化能力)进行一个折中。这种技术的基本原理与“压缩感知”原理有关。
与此类似的方法就是DeepLearning里面有名的正则化方法DropOut,实现很简单,就是每次训练使隐层的一部分神经元不工作,比如随机选择40%的神经元权重设置为0(激活函数的激活值设置为0),再去继续训练模型。该方法起源2012年图像识别的论文“ImageNet Classification with Deep Convolutional”,这种方法可以有效防止过拟合,增加模型的泛化能力,在深度学习领域被广泛使用。
DenoisingAutoEncoder(去噪自编码)的基本操作是训练这层神经网络时,主动添加一些噪声数据,然后再去训练,在添加了噪声数据后,进行训练后,可以使该层神经网络更鲁棒,这个意思就是这样的训练方法使encoder泛化能力更强,其本意是在学习过程中,添加噪声数据,在对学习目标(原始数据)进行学习的时候,引入了更多的特征数据,使用encoder不会过分拟合当前训练的原始特征数据,而面对其他的数据时缺乏拟合能力,所以encoder的学习能力泛化了。可以理解为,在更丰富的数据中(包含噪声数据),去学习目标的难度更大,可以使学习器更好地保留学习目标的核心关键信息。我的理解,这里的算法原理与PCA主成分分析模型的原理类似,学习器可以通过变化率的趋势分析,在大量数据中找到主元方向(就是数据中的核心内容)。
添加噪声数据的方法很多,在Theano的SDA中用了比较简单的方法,就是把输入数据中的一部分设置为0,就是让输入数据被破坏,使用的方法是dA.py中的get_corrupted_input函数,默认是把30%的输入数据设置为0,即代码corruption_level=0.3,而且,这是随机选取30%的数据,因为Pretraining有很多轮迭代,每次迭代选取的30%训练数据会不一样,每次会用不同的局部数据去学习总体数据的关键信息,总体上不丢失原始数据结构,而且可以更好地学习到原始数据中的主要特征。引一段Theano的原文:the stochastic corruption process randomly sets some ofthe inputs (as many as half of them) to zero. Hence the denoising auto-encoderis trying to predict the corrupted (i.e. missing) values from theuncorrupted (i.e., non-missing) values, for randomly selected subsets ofmissing patterns. Note how being able to predict any subset of variables fromthe rest is a sufficient condition for completely capturing the jointdistribution between a set of variables (this is how Gibbs sampling works).
以上说明都是一层AutoEncoder(自编码器),多层AutoEncoder,下一层的输入,就是上一层的输出,每一层是分别训练的,每一层训练完后,输出的是原数据的核心特征数据,每一层都是去学习上一层编码后的新特征,然后输出一个更加核心的特征数据,层层递进,所有隐含层训练完后,就完成了pretraining,这是一个自学习过程,一般训练时间都很长,最后得到特征数据,可以认为是原始数据中最核心的特征。这就是第一篇文中描述“特征抽象”那个示意图的基本过程。这个过程是很神奇的,但这个过程还缺乏理论证明,它为什么会work。Bengio给了一些可能的理论解释:Thedenoising auto-encoder can be understood from different perspectives (themanifold learning perspective, stochastic operator perspective, bottom-up –information theoretic perspective, top-down –generative model perspective).
整个Pretraining的过程都是在用无标注数据去训练DeepLearning神经网络模型的参数(W),得到的结果就是这个神经网络有一个比较好的初始参数,这其实就是Deep Learning的核心价值。也有人说,这就是让神经网络在学习和固化“知识”。然后,还有一个Fineturning的过程,与BP训练方法一致,使用标注数据,对神经网络的参数进行“调优”。最终用最后一层分类器去做分类预测。Pretraining的训练时间远超过Fineturning的时间,下面这个表,可以看一下简单的对比:
1万条训练数据,147个特征,batch_size=1000。
| SDA神经网络 |
Pretraining训练时间(分钟) |
Fineturning时间(分钟) |
| 3个隐层,每层10个神经元,pretraining 3轮迭代,finetunning5轮迭代。 |
6.6 |
4.01 |
| 3个隐层,每层40个神经元,pretraining 10轮迭代,finetunning20轮迭代。 |
65.2 |
32.4 |
| 3个隐层,每层10个神经元,pretraining100轮迭代,finetunning 500轮迭代。 |
262.9 |
9.32 |
Theano中SDA代码的要点说明:
dA是单层的去噪自编码器,它可以独立运行,使用MNIST数据集测试,可以看到
__init__(self,numpy_rng, theano_rng=None, input=None,
n_visible=784, n_hidden=500,
W=None, bhid=None, bvis=None)
#n_visible是特征数,这里是MNIST数据集的特征数,28*28的手写数字图片。n_hidden 是隐层神经元数,这里只有一层。
y =self.get_hidden_values(tilde_x) #通过隐层得到y,即x'
z =self.get_reconstructed_input(y) #使用W的矩阵转置W_prime,重构原始的x
图片的原始特征是像素,最基本的表现方式是灰度,每个像素是0~255之间的数字,0是黑色,255是白色,一般会把每个像素处理成0~1之间的小数(除以255即可),0是黑色,1是白色,对于手写数字图片集MNIST的输入数据(28*28的图片集)处理详细说明参见:http://deeplearning.net/tutorial/gettingstarted.html。dA对MNIST数据集训练后,效果如下图,左边是原始特征,右边是添加30%噪声数据学习后的特征,右边特征要更清晰简洁,更关键一些:


sDA的代码:
sda = SdA(numpy_rng=numpy_rng, n_ins=dimension, #输入层147个神经元,要与特征维度一致
hidden_layers_sizes=[50, 50, 50], #3个隐层,数据量小的话每层10个比较好
n_outs=2) #输出层2个神经元,做二分类问题。
# We nowneed to add a logistic layer on top of the MLP 分类器LR用的特征是隐含层的最后一层的输出。
self.logLayer = LogisticRegression(
input=self.sigmoid_layers[-1].output,
n_in=hidden_layers_sizes[-1], n_out=n_outs)
#finetune是对所有层进行finetune,输入数据还是 train_set_x,验证数据train_set_y,与MLP的方法一致。
#要在训练时返回cost,W,b等参数,便于查看,需要添加outputs参数,最后的LR分类器的权值W,b,最后一个隐层的权值W,b
train_fn = theano.function(inputs=[index],
outputs=[self.finetune_cost, self.logLayer.W, self.logLayer.b,self.sigmoid_layers[self.n_layers-1].W,self.sigmoid_layers[self.n_layers-1].b],
updates=updates,
givens={
self.x: train_set_x[index * batch_size:
(index + 1) * batch_size],
self.y: train_set_y[index * batch_size:
(index + 1) * batch_size]},
name='train')
#对于测试集的测试,可以添加输出数据,输出output分别是:MLP的误差,分类器LR的预测结果y,分类器LR的预测概率。
test_model_result = theano.function(inputs=[index],
outputs=[self.errors, self.logLayer.y_pred, self.logLayer.p_y_given_x],
givens={
self.x: test_set_x[index * batch_size:
(index + 1) * batch_size],
self.y: test_set_y[index * batch_size:
(index + 1) * batch_size]},
name='test_result', mode='DebugMode')
#输出测试数据的预测分类结果和概率,在计算AUC时也需要LR_probality这个概率值。
LR_error,LR_predictResult, LR_probality = test_model_result()
#计算AUC(用了Scikit的metrics包):
probability_Test = LR_probality_all_array[:,1] #取第2列,即为1的概率
fpr, tpr, thresholds = metrics.roc_curve(testLabel_array, probability_Test)
AUC = metrics.auc(fpr, tpr)
#对于Recall,Accuracy,Precision可以自己写函数计算。
随想:
我有时候在想,我们广大的程序猿,可以看做是这个世界的Encoder,正在把现实世界编码模拟放在虚拟的计算机世界中,所以我们广大的程序猿就是这个计算机网络中的神经元, 是计算机网络感知这个世界的“虚拟大脑”的零件…