Tensorflow下使用SSD训练自己的数据集
Tensorflow下使用SSD训练自己的数据集
1、数据集格式转换。
① 将自己的数据集做成VOC2007格式,直接将VOC2007文件夹粘贴到SSD-Tensorflow-master目录下。
② 修改datasets文件夹中pascalvoc_common.py文件中的训练类。
#原始的
# VOC_LABELS = {
# 'none': (0, 'Background'),
# 'aeroplane': (1, 'Vehicle'),
# 'bicycle': (2, 'Vehicle'),
# 'bird': (3, 'Animal'),
# 'boat': (4, 'Vehicle'),
# 'bottle': (5, 'Indoor'),
# 'bus': (6, 'Vehicle'),
# 'car': (7, 'Vehicle'),
# 'cat': (8, 'Animal'),
# 'chair': (9, 'Indoor'),
# 'cow': (10, 'Animal'),
# 'diningtable': (11, 'Indoor'),
# 'dog': (12, 'Animal'),
# 'horse': (13, 'Animal'),
# 'motorbike': (14, 'Vehicle'),
# 'person': (15, 'Person'),
# 'pottedplant': (16, 'Indoor'),
# 'sheep': (17, 'Animal'),
# 'sofa': (18, 'Indoor'),
# 'train': (19, 'Vehicle'),
# 'tvmonitor': (20, 'Indoor'),
# }
#修改后的
VOC_LABELS = {
'none': (0, 'Background'),
'gun': (1, 'gun'),
'knife': (2, 'knife'),
}
③ 修改datasets文件夹中的pascalvoc_to_tfrecords.py文件。
修改文件的83行读取方式为’rb‘,如果你的文件不是.jpg格式,也可以修改图片的类型。
# Read the image file.
filename = directory + DIRECTORY_IMAGES + name + '.jpg'
image_data = tf.gfile.FastGFile(filename, 'rb').read()修改文件的67行,设置将几张图片转为一个tfrecords。
# TFRecords convertion parameters.
RANDOM_SEED = 4242
SAMPLES_PER_FILES = 1 # 一张图片转为一个tfrecords④ 在SSD-Tensorflow-master目录下创建tfrecords_文件夹,做以下改动后运行tf_convert_data.py文件。
Linux下:在SSD-Tensorflow-master目录下创建tf_conver_data.sh,文件写入内容如下:
DATASET_DIR=./VOC2007/ #VOC数据保存的文件夹(VOC的目录格式未改变)
OUTPUT_DIR=./tfrecords_ #自己建立的保存tfrecords数据的文件夹
python ./tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}
Windows+pychram:配置pycharm-->run-->Edit Configuration
Script parameters中写入:--dataset_name=pascalvoc --dataset_dir=./VOC2007/ --output_name=voc_2007_train --output_dir=./tfrecords_
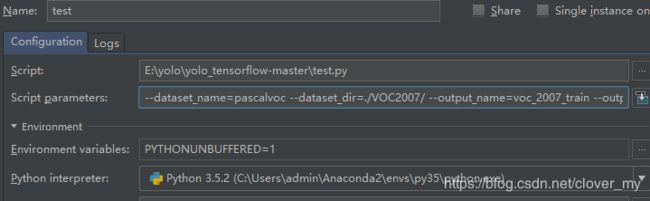
⑤ 生成后的结果。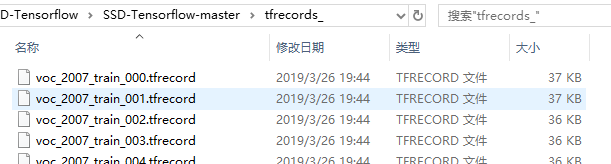
2、训练模型。
① 修改train_ssd_network.py文件,设置训练参数(此处可进行学习率等参数的修改,也可以不修改,在使用cmd命令运行文件时进行设置)。
# 修改135行
tf.app.flags.DEFINE_integer(
'num_classes', 3, 'Number of classes to use in the dataset.') # 自己的类别数+1
# 修改154行,设置迭代次数,max-step为None时会无限训练
tf.app.flags.DEFINE_integer('max_number_of_steps', 6000,
'The maximum number of training steps.')② 修改nets目录下的ssd_vgg_300.py文件(使用此网络结构时) 。
# 修改94-97行
default_params = SSDParams(
img_shape=(300, 300), # 输入的size
num_classes=3, # 修改为自己的类别数+1
no_annotation_label=3, # 修改为自己的类别数+1③ 修改eval_ssd_network.py文件。
# 65-66行
tf.app.flags.DEFINE_integer(
'num_classes', 3, 'Number of classes to use in the dataset.') # 修改为自己的类别数+1④ 修改datasets目录下的pascalvoc_2007.py文件。
# 原始文件
# (Images, Objects) statistics on every class.
# TRAIN_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (238, 306), # 238为该类训练图像总数,306为该类训练图像中框的总数
# 'bicycle': (243, 353),
# 'bird': (330, 486),
# 'boat': (181, 290),
# 'bottle': (244, 505),
# 'bus': (186, 229),
# 'car': (713, 1250),
# 'cat': (337, 376),
# 'chair': (445, 798),
# 'cow': (141, 259),
# 'diningtable': (200, 215),
# 'dog': (421, 510),
# 'horse': (287, 362),
# 'motorbike': (245, 339),
# 'person': (2008, 4690),
# 'pottedplant': (245, 514),
# 'sheep': (96, 257),
# 'sofa': (229, 248),
# 'train': (261, 297),
# 'tvmonitor': (256, 324),
# 'total': (5011, 12608),
# }
# TEST_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (1, 1),
# 'bicycle': (1, 1),
# 'bird': (1, 1),
# 'boat': (1, 1),
# 'bottle': (1, 1),
# 'bus': (1, 1),
# 'car': (1, 1),
# 'cat': (1, 1),
# 'chair': (1, 1),
# 'cow': (1, 1),
# 'diningtable': (1, 1),
# 'dog': (1, 1),
# 'horse': (1, 1),
# 'motorbike': (1, 1),
# 'person': (1, 1),
# 'pottedplant': (1, 1),
# 'sheep': (1, 1),
# 'sofa': (1, 1),
# 'train': (1, 1),
# 'tvmonitor': (1, 1),
# 'total': (20, 20),
# }
# SPLITS_TO_SIZES = {
# 'train': 5011,
# 'test': 4952,
# }
# SPLITS_TO_STATISTICS = {
# 'train': TRAIN_STATISTICS,
# 'test': TEST_STATISTICS,
# }
# NUM_CLASSES = 20
# 修改后
# (Images, Objects) statistics on every class.
TRAIN_STATISTICS = {
'none': (0, 0),
'gun': (77, 77),
'knife': (77, 77),
'total': (154, 154),
}
TEST_STATISTICS = {
'none': (0, 0),
'gun': (1, 1),
'knife': (1, 1),
'total': (2, 2),
}
SPLITS_TO_SIZES = {
'train': 154,
'test': 66,
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
NUM_CLASSES = 2 # 自己的训练类别数3、加载预训练模型。
下载预训练好的vgg16模型,解压出vgg_16.ckpt文件放入checkpoint文件中。
下载地址参考:目标检测SSD+Tensorflow 训练自己的数据集
链接:https://pan.baidu.com/s/1diWbdJdjVbB3AWN99406nA 密码:ge3x
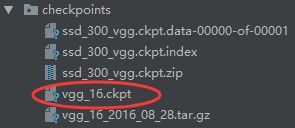
Linux:新建一个.sh文件,文件里写入
DATASET_DIR=./tfrecords_/
TRAIN_DIR=./train_model/
CHECKPOINT_PATH=./checkpoints/vgg_16.ckpt
python3 ./train_ssd_network.py \
--train_dir=./train_model/ \ #训练生成模型的存放路径
--dataset_dir=./tfrecords_/ \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=./checkpoints/vgg_16.ckpt \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
Windows+pycharm:在上述的run中Edit Configuration配置,打开命令运行代码
python ./train_ssd_network.py --train_dir=./train_model/ --dataset_dir=./tfrecords_/ --dataset_name=pascalvoc_2007 --dataset_split_name=train --model_name=ssd_300_vgg --checkpoint_path=./checkpoints/vgg_16.ckpt --checkpoint_model_scope=vgg_16 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --save_summaries_secs=60 --save_interval_secs=600 --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --learning_rate_decay_factor=0.94 --batch_size=24 --gpu_memory_fraction=0.9
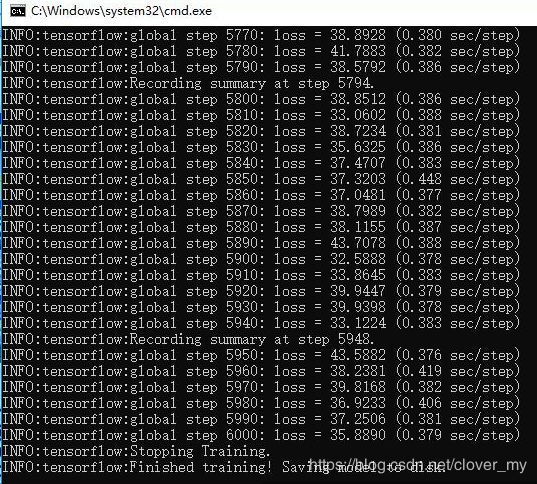
4、参考
目标检测SSD+Tensorflow 训练自己的数据集
目标检测 -- SSD (tensorflow 版) 逐行逐句解读
Windows下TensorFlow+SSD遇到的问题