构建完全分布式的Hadoop2.x
最近开始学Hadoop,嗨,也是一把辛酸泪,找到适合的好书不容易啊,不唠叨了,开始吧。
这次我只用了两台机子,一个自己的笔记本电脑,deepin系统,作为Master节点,另一个阿里云服务器,Ubuntu系统,作为node节点(其实也够了,第三、第四台的配置和第二台是一样的,只是名字不同,哈哈)
第一步,配置hosts文件,主要用于确定各个节点主机的IP地址,方面后续访问(每个主机都需要添加同样的内容)
sudo vim /etc/hosts在文件中添加各个节点主机的IP地址及节点名称(包括本机,且ip要全为局域网ip或全为公网ip,每个机子都要添加一样的master和node1),如图:

格式为:IP地址 节点名称(例:111.12.32.12 master)
第二步,由于Hadoop是通过ssh来管理远程守护进程的,因此我们需要安装ssh,以及rsync(这是一个远程数据同步备份工具)
sudo apt-get install ssh
sudo apt-get install rsync在每一台机子上执行如下语句,遇到需要输入时直接回车(为了可以免密码登录主机进行管理,省去了频繁输入密码的)
ssh-keygen -t rsa为了实现免密码登录,我们还需要将公钥导出为authorized_keys,首先我们在Master节点主机上执行以下命令
cd ~/.ssh
cat id_rsa.pub >>authorized_keys此时,我们已经在Master节点主机上免密登录本机了,请看图中圈出的部分
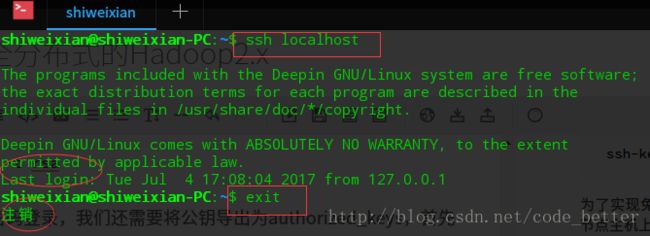
OK,小有所成,但我们还需免密登录远程主机呢,不急,我们通过scp把Master主机上的authorized_keys上传到node节点主机的~/.ssh目录中:
scp ~/.ssh/authorized_keys 远程主机用户名@远程主机地址:~/.ssh
例:
scp ~/.ssh/authorized_keys weixian@node:~/.ssh此时,我们可以在Master主机上免密登录node节点机器:

然后我们再把node节点机器上的公钥也添加到authorized_keys,这样也可以在node机器上免密登录(个人觉得这一步主要是为了可以免密启动Hadoop,如果少了这一步,你会发现启动Hadoop要输入n次密码。。)
# 登录node节点主机后执行以下命令
cd ~/.ssh
cat id_rsa.pub >>authorized_keysOK,前戏完成,开始我们的重头戏,Hadoop的安装(先在一个主机下载,配置,配置完成后通过scp拷贝到其他主机即可):
首先,下载Hadoop,这里我使用的最新稳定版:2.8.0
# 自己找一个合适的目录就行
cd ~/software
# 下载并解压
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
tar -zxvf hadoop-2.8.0.tar.gz解压后进入Hadoop目录的etc/hadoop之中,修改core-site.xml为:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/data/hadoop_tmpvalue>
property>
configuration>修改hdfs-site.xml为:
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.name.dirname>
<value>~/data/hdfs/namevalue>
property>
<property>
<name>dfs.name.dirname>
<value>~/data/hdfs/namevalue>
property>
configuration>修改mapred-site.xml为:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>修改yarn-site.xml为:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8081value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8082value>
property>
configuration>修改slaves文件(运行DataNode和NodeManager的机器列表,每行一个):
master
node1然后,安装jdk并配置jdk和Hadoop的环境变量,下载oracle的jdk并解压到/usr/lib中,修改jdk文件夹名字为jdk(略过不说),修改/etc/profile:
sudo gedit /etc/profile在末尾添加如下内容:
#JAVA_HOME和HADOOP_HOME的路径根据实际情况修改
JAVA_HOME=/usr/lib/jdk
HADOOP_HOME=/home/weixian/software/hadoop-2.8.0
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
export JAVA_HOME
export HADOOP_HOME
export PATH使环境变量生效:
source /etc/profile验证效果:
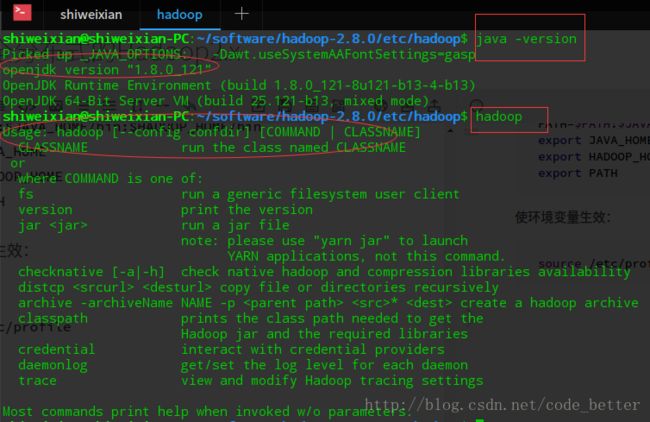
在第一次启动Hadoop之前,我们首先需要格式化HDFS:
hadoop namenode -format只是个Hadoop新手,好不容易才搞通,如果有什么不对的地方,欢迎指教!