Hbase入门----【hbase内部原理和架构(★★★★★)、掌握hbase的寻址机制(★★★★★)、hbase表中的rowkey设计(★★★★★★★)】
hbase入门学习笔记
1、目标
- 1、掌握hbase相关概念
- 2、掌握搭建一个hbase集群
- 3、掌握hbase shell 命令行操作
- 4、掌握hbase内部原理和架构(★★★★★)
- 5、掌握hbase的寻址机制(★★★★★)
- 6、掌握hbase表中的rowkey设计(★★★★★★★)
2、hbase概述
2.1 hbase是什么
hbase是
基于hdfs进行数据的分布式存储,具有高可靠、高性能、列存储、可伸缩、实时读写的nosql数据库。
hbase可以存储海量的数据,并且后期查询性能很高,可以实现上亿条数据的查询秒级返回结果。 Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务)
与hadoop一样,Hbase目标主要依靠
横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
2.2 hbase表的特性
- 1、大
- hbase表可以存储海量的数据。
- 2、无模式
- mysql表中每一行列的字段是相同,而hbase表中
每一行数据可以有截然不同的列。
- mysql表中每一行列的字段是相同,而hbase表中
- 3、面向列
- hbase表中的数据可以有很多个列,后期它就是按照不同的列去存储数据,写入到不同的文件中。
- 面向
列族进行存储数据。
- 4、稀疏
- 在hbase表中
为null的列并不占用实际的存储空间。
- 在hbase表中
- 5、数据的多版本
- 对于hbase表中的数据在进行数据更新的时候,它并没有把之前的结果数据直接删除掉,而是保留数据的
多个版本,每一个数据都给一个版本号,这个版本号就是按照我们插入数据的时间戳去确定。
- 对于hbase表中的数据在进行数据更新的时候,它并没有把之前的结果数据直接删除掉,而是保留数据的
- 6、数据类型单一
- 无论是什么类型的数据,最后都被转换成了
字节数组存储在hbase表中
- 无论是什么类型的数据,最后都被转换成了
2.3 hbase表的逻辑视图
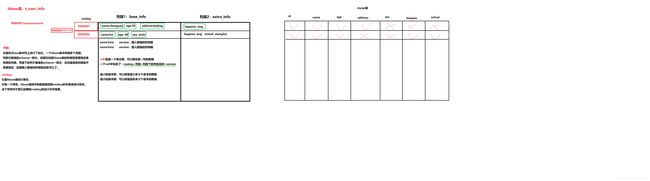
列族: 它是在hbase表中列上进行了划分 , 一个hbase表中有很多个列族 , 列族它是表的schema一部分 , 后期在创建hbase表的时候就需要指定有哪些列族 . 列族下的列不是表的schema一部分 , 在创建表的时候就不需要指定 , 后期插入数据的时候指定就可以了.
访问控制、磁盘和内存的使用统计都是在列族层面进行的。
列族越多,在取一行数据时所要参与IO、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族。一般设置2-3个比较合理。
rowkey: 它是hbase表的行索引 , 它有一个特性 : hbase表中的数据是按照rowkey的字典序进行排序 . 这个特性对于我们后期的rowkey的设计非常重要 . 这个特性,将经常一起读取的行存储放到一起。(位置相关性) Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
cell: 就是一个单元格 , 如图中绿框的就是一个cell . 一个cell包括了 : rowkey+列族+列族下的列的名称+version
3、hbase的集群结构

- 1、client
- 提供了对hbase表操作的一些java接口。
- 2、zookeeper
- 客户端操作hbase表数据需要一个zk集群
- 作用
- 1、zk保存了hbase集群的元数据信息
- 2、zk保存所有hbase表的寻址入口
- 后期通过客户端接口去操作hbase数据的时候,需要连接上zk集群
- 3、通过引入了zk之后,实现了整个hbase集群高可用
- 4、zk保存了HMaster和HRegionServer它们的注册和心跳信息
- 后期哪一个HRegionServer挂掉之后,zk也会感知到,然后把这个信息通知给老大HMaster
- 作用
- 客户端操作hbase表数据需要一个zk集群
- 3、HMaster
- 它是整个hbase集群老大
- 作用
- 1、它接受客户端创建表、删除表的请求。
- 2、它会给HRegionServer分配对应的region,进行数据的管理
- 3、它会把挂掉的HRegionServer所管理的region重新分配给其他的活着的HRegionServer
- 4、它会实现HRegionServer负载均衡,避免某一个HRegionServer管理的region过多。
- 5、可以配置多个 , 用来实现HA
- 作用
- 它是整个hbase集群老大
- 4、HRegionServer
- 它是整合hbase集群的小弟
- 作用
- 1、负责管理HMaster老大给它分配的region
- 2、它会接受到客户端的读写请求
- 3、它会把在运行过程中,变得过大的region数据进行切分
- 作用
- 它是整合hbase集群的小弟
- 5、Region
- 它是整个hbase表中分布式存储的最小单元
- 它的数据是基于hdfs进行存储
- 它是整个hbase表中分布式存储的最小单元
4、hbase集群安装部署
-
前提条件
- 先搭建好zk、hadoop集群
-
1、下载对应的安装包
- http://archive.apache.org/dist/hbase/1.2.1/hbase-1.2.1-bin.tar.gz
- hbase-1.2.1-bin.tar.gz
-
2、规划安装目录
- /export/servers
-
3、上传安装包到服务器中
-
4、解压安装包到指定的规划目录
tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers
-
5、重命名解压目录
mv hbase-1.2.1 hbase
-
6、修改配置文件
-
需要把hadoop安装目录下/etc/hadoop文件夹中
core-site.xmlhdfs-site.xml- 需要把以上2个hadoop的配置文件拷贝到hbase安装目录下的conf文件夹中
cp core-site.xml hdfs-site.xml /export/servers/hbase/conf
-
1、
vim hbase-env.sh#配置java环境变量 export JAVA_HOME=/export/servers/jdk #指定hbase集群由外部的zk集群去管理,不在使用自带的zk集群 export HBASE_MANAGES_ZK=false -
2、
vim hbase-site.xml<property> <name>hbase.rootdirname> <value>hdfs://node-1:9000/hbasevalue> property> <property> <name>hbase.cluster.distributedname> <value>truevalue> property> <property> <name>hbase.zookeeper.quorumname> <value>node-1:2181,node-2:2181,node-3:2181value> property> -
3、
vim regionservers#指定哪些节点是HRegionServer node-2 node-3 -
4、
vim backup-masters#指定哪些节点是备用的Hmaster node-2
-
-
7、配置hbase环境变量
-
vim /etc/profileexport HBASE_HOME=/export/servers/hbase export PATH=$PATH:$HBASE_HOME/bin
-
-
8、分发hbase目录和环境变量
scp -r hbase node2:/export/servers scp -r hbase node3:/export/servers scp /etc/profile node2:/etc scp /etc/profile node3:/etc -
9、让所有hbase节点的环境变量生效
- 在所有节点上执行
source /etc/profile
- 在所有节点上执行
-
10、为了保证集群的可靠性 , 要启动多个HMaster[自己选择]
hbase-daemon.sh start master
注意:使用jdk8的时候,出现了Java HotSpot™ 64-Bit Server VM warning: ignoring
option MaxPermSize=256m; support was removed in 8.0的红色标识。字面意思是MaxPermSize不需要我们配置了,所以我就按照它的方法把default VM arguments中MaxPermSize参数给删掉就不会出现上面的提示了。
5、hbase集群的启动和停止
- 1、启动hbase集群
- 先启动zk和hadoop集群
- 然后通过hbase/bin
start-hbase.sh- 你在哪里启动这个脚本,首先在当前机器启动一个HMaster进程(它就是活着的HMaster)
- 通过regionservers文件在对应的节点来启动HRegionServer
- 通过backup-masters文件在对应的节点来启动备用的HMaster
- 2、停止hbase集群
- 通过hbase/bin
stop-hbase.sh
- 通过hbase/bin
6、hbase集群web管理界面
- 1、启动好hbase集群之后
- 访问地址
- HMaster主机名:16010
- 访问地址
7、hbase shell 命令行操作
-
hbase/bin/hbase shell 进入到hbase shell客户端命令操作
-
1、创建一个表
create 't_user_info','base_info','extra_info' create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'} -
2、查看有哪些表
list 类似于mysql表中sql:show tables -
3、查看表的描述信息
describe 't_user_info' -
4、修改表的属性
#修改列族的最大版本数 alter 't_user_info', NAME => 'base_info', VERSIONS => 3 -
5、添加数据到表中
put 't_user_info','00001','base_info:name','zhangsan' put 't_user_info','00001','base_info:age','30' put 't_user_info','00001','base_info:address','bejing' put 't_user_info','00001','extra_info:school','shanghai' put 't_user_info','00001','base_info:age','40' put 't_user_info','00001','base_info:age','50' put 't_user_info','00001','base_info:age','60' put 't_user_info','00002','base_info:name','lisi' -
6、查询表的数据
//按照条件查询 get 't_user_info','00001' get 't_user_info','00001', {COLUMN => 'base_info'} get 't_user_info','00001', {COLUMN => 'base_info:name'} get 't_user_info','00001',{TIMERANGE => [1544243300660,1544243362660]} get 't_user_info','00001',{COLUMN => 'base_info:age',VERSIONS =>3} //查询某一时间段age的版本 get 't_user_info','00001',{COLUMN =>'base_info:age' ,TIMERANGE =>[1544271764711,1544272199406]} //全表查询 scan 't_user_info' -
7、删除数据
delete 't_user_info','00001','base_info:name' //删除表中某一rowkey字段 deleteall 't_user_info','00001' -
8、删除表
//首先需要将其置为不可用 disable 't_user_info' drop 't_user_info'
7.1 hbase代码开发
过滤器查询 : 过滤器的类型很多,但是可以分为两大类——比较过滤器,专用过滤器
过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
hbase过滤器的比较运算符:
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
Hbase过滤器的比较器(指定比较机制):
BinaryComparator 按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
NullComparator 判断给定的是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator 判断提供的子串是否出现在value中。
Hbase的过滤器分类
-
比较过滤器
- 1.1 行键过滤器RowFilter
Filter filter1 = new RowFilter(CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("row-22"))); scan.setFilter(filter1);- 1.2 列族过滤器FamilyFilter
Filter filter1 = new FamilyFilter(CompareFilter.CompareOp.LESS, new BinaryComparator(Bytes.toBytes("colfam3"))); scan.setFilter(filter1);- 1.3 列过滤器QualifierFilter
filter = new QualifierFilter(CompareFilter.CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("col-2"))); scan.setFilter(filter1);- 1.4 值过滤器 ValueFilter
Filter filter = new ValueFilter(CompareFilter.CompareOp.EQUAL, new SubstringComparator(".4") ); scan.setFilter(filter1); -
专用过滤器
- 2.1 单列值过滤器
SingleColumnValueFilter----会返回满足条件的整行
SingleColumnValueFilter filter = new SingleColumnValueFilter( Bytes.toBytes("colfam1"), Bytes.toBytes("col-5"), CompareFilter.CompareOp.NOT_EQUAL, new SubstringComparator("val-5")); filter.setFilterIfMissing(true); //如果不设置为true,则那些不包含指定column的行也会返回 scan.setFilter(filter1);- 2.2 前缀过滤器
PrefixFilter----针对行键
Filter filter = new PrefixFilter(Bytes.toBytes("row1")); scan.setFilter(filter1);- 2.3 列前缀过滤器
ColumnPrefixFilter
Filter filter = new ColumnPrefixFilter(Bytes.toBytes("qual2")); scan.setFilter(filter1); - 2.1 单列值过滤器
-
完全的代码开发
package com.itck.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
//todo:Hbase Api操作
public class HbaseDemo {
//初始化Configuration对象
private Configuration conf=null;
//初始化链接
private Connection conn = null;
@Before
public void init() throws Exception{
conf= HBaseConfiguration.create();
// 对于hbase的客户端来说,只需要知道hbase所使用的zookeeper集群地址就可以了
// 因为hbase的客户端找hbase读写数据完全不用经过hmaster
conf.set("hbase.zookeeper.quorum","node-1:2181,node-2:2181,node-3:2181");
//获取链接
conn=ConnectionFactory.createConnection(conf);
}
/**
* 建表
* @throws Exception
* hbase shell------> create 'tableName','列族1','列族2'
*/
@Test
public void createTable() throws Exception{
//获取一个表的管理器
Admin admin = conn.getAdmin();
//构造一个表描述器,并指定表名
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("t_user_info".getBytes()));
//构造一个列族描述器,并指定列族名
HColumnDescriptor hcd1 = new HColumnDescriptor("base_info");
// 构造第二个列族描述器,并指定列族名
HColumnDescriptor hcd2 = new HColumnDescriptor("extra_info");
// 为该列族设定一个版本数量
hcd2.setVersions(1, 3);
// 将列族描述器添加到表描述器中
tableDescriptor.addFamily(hcd1).addFamily(hcd2);
//利用表的管理器创建表
admin.createTable(tableDescriptor);
//关闭
admin.close();
conn.close();
}
/**
* 修改表
* @throws Exception
*/ //hbase shell alter 't_user_info' ,'base_info',
@Test
public void modifyTable() throws Exception{
//获取一个表的管理器
Admin admin = conn.getAdmin();
//获取表的描述器
HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("t_user_info"));
//修改已有的ColumnFamily---extra_info最小版本数和最大版本数
HColumnDescriptor hcd1 = tableDescriptor.getFamily("extra_info".getBytes());
hcd1.setVersions(2,5);
// 添加新的ColumnFamily
tableDescriptor.addFamily(new HColumnDescriptor("other_info"));
//表的管理器admin 修改表
admin.modifyTable(TableName.valueOf("t_user_info"),tableDescriptor);
//关闭
admin.close();
conn.close();
}
/**
* put添加数据
* @throws Exception hbase shell put 't_user_info','rk00001','base_info:name','lisi'
*/
@Test
public void testPut() throws Exception {
//构建一个 table对象,通过table对象来添加数据
Table table = conn.getTable(TableName.valueOf("t_user_info"));
//创建一个集合,用于存放Put对象
ArrayList<Put> puts = new ArrayList<Put>();
// 构建一个put对象(kv),指定其行键 例如hbase shell: put '表名','rowkey','列族:列名称','值'
Put put01 = new Put(Bytes.toBytes("user001")); // "user001".getBytes()
put01.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhangsan"));
Put put02 = new Put("user001".getBytes());
put02.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("password"), Bytes.toBytes("123456"));
Put put03 = new Put("user002".getBytes());
put03.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("lisi"));
put03.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put04 = new Put("zhang_sh_01".getBytes());
put04.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang01"));
put04.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put05 = new Put("zhang_sh_02".getBytes());
put05.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang02"));
put05.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put06 = new Put("liu_sh_01".getBytes());
put06.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("liu01"));
put06.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put07 = new Put("zhang_bj_01".getBytes());
put07.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang03"));
put07.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
Put put08 = new Put("zhang_bj_01".getBytes());
put08.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("zhang04"));
put08.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("married"), Bytes.toBytes("false"));
//把所有的put对象添加到一个集合中
puts.add(put01);
puts.add(put02);
puts.add(put03);
puts.add(put04);
puts.add(put05);
puts.add(put06);
puts.add(put07);
puts.add(put08);
//一起提交所有的记录
table.put(puts);
table.close();
conn.close();
}
/**
* 读取数据 get:一次读一行
* @throws Exception hbase shell : get 't_user_info',"rowkey"
*/
@Test
public void testGet() throws Exception {
//获取一个table对象
Table table = conn.getTable(TableName.valueOf("t_user_info"));
// 构造一个get查询参数对象,指定要get的是哪一行
Get get = new Get("user001".getBytes());
//返回查询结果数据
Result result = table.get(get);
//获取结果中的所有cell
List<Cell> cells = result.listCells();
//遍历所有的cell
for(Cell c:cells){
//获取行键
byte[] rowArray = c.getRowArray(); //00001
//获取列族
byte[] familyArray = c.getFamilyArray(); //base_info
//获取列族下的列名称
byte[] qualifierArray = c.getQualifierArray();//username
//列字段的值
byte[] valueArray = c.getValueArray(); // zhangsan
//打印rowArray、familyArray、qualifierArray、valueArray
// System.out.println(new String(rowArray));
// System.out.println(new String(familyArray));
// System.out.println(new String(qualifierArray));
// System.out.println(new String(valueArray));
//按指定位置截取,获取rowArray、familyArray、qualifierArray、valueArray
System.out.print(new String(rowArray, c.getRowOffset(), c.getRowLength()));
System.out.print(" "+new String(familyArray, c.getFamilyOffset(), c.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, c.getQualifierOffset(), c.getQualifierLength()));
System.out.println(" " + new String(valueArray, c.getValueOffset(), c.getValueLength()));
}
//关闭
table.close();
conn.close();
}
/**
* scan 批量查询数据
* @throws Exception hbase shell scan 't_user_info'
*/
@Test
public void testScan() throws Exception {
//获取table对象
Table table = conn.getTable(TableName.valueOf("t_user_info"));
//获取scan对象
Scan scan = new Scan();
//获取查询的数据
ResultScanner scanner = table.getScanner(scan);
//获取ResultScanner所有数据,返回迭代器
Iterator<Result> iter = scanner.iterator();
//遍历迭代器
while (iter.hasNext()) {
//获取当前每一行结果数据
Result result = iter.next();
//获取当前每一行中所有的cell对象
List<Cell> cells = result.listCells();
//迭代所有的cell
for(Cell c:cells){
//获取行键
byte[] rowArray = c.getRowArray();
//获取列族
byte[] familyArray = c.getFamilyArray();
//获取列族下的列名称
byte[] qualifierArray = c.getQualifierArray();
//列字段的值
byte[] valueArray = c.getValueArray();
//打印rowArray、familyArray、qualifierArray、valueArray
System.out.println(new String(rowArray, c.getRowOffset(), c.getRowLength()));
System.out.print(new String(familyArray, c.getFamilyOffset(), c.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, c.getQualifierOffset(), c.getQualifierLength()));
System.out.println(" " + new String(valueArray, c.getValueOffset(), c.getValueLength()));
}
System.out.println("-----------------------");
}
//关闭
table.close();
conn.close();
}
/**
* 删除表中的列数据
* @throws Exception hbase shell delete 't_user_info','user001','base_info:password'
*/
@Test
public void testDel() throws Exception {
//获取table对象
Table table = conn.getTable(TableName.valueOf("t_user_info"));
//获取delete对象,需要一个rowkey
Delete delete = new Delete("user001".getBytes());
//在delete对象中指定要删除的列族-列名称
delete.addColumn("base_info".getBytes(), "password".getBytes());
//执行删除操作
table.delete(delete);
//关闭
table.close();
conn.close();
}
/**
* 删除表
* @throws Exception hbase shell disable 't_user_info' drop 't_user_info'
*/
@Test
public void testDrop() throws Exception {
//获取一个表的管理器
Admin admin = conn.getAdmin();
//删除表时先需要disable,将表置为不可用,然后在delete
admin.disableTable(TableName.valueOf("t_user_info"));
admin.deleteTable(TableName.valueOf("t_user_info"));
admin.close();
conn.close();
}
/**
* 过滤器使用
* @throws Exception
*/
@Test
public void testFilter() throws Exception {
// 针对行键的前缀过滤器
// Filter pf = new PrefixFilter(Bytes.toBytes("liu"));//"liu".getBytes()
// testScan(pf);
// 行过滤器 需要一个比较运算符和比较器
// RowFilter rf1 = new RowFilter(CompareOp.LESS, new BinaryComparator(Bytes.toBytes("user002")));
// testScan(rf1);
//
// RowFilter rf2 = new RowFilter(CompareOp.EQUAL, new SubstringComparator("01"));//rowkey包含"01"子串的
// testScan(rf2);
//针对指定一个列的value的比较器来过滤
// ByteArrayComparable comparator1 = new RegexStringComparator("^zhang"); //以zhang开头的
// ByteArrayComparable comparator2 = new SubstringComparator("si"); //包含"si"子串
// SingleColumnValueFilter scvf = new SingleColumnValueFilter("base_info".getBytes(), "username".getBytes(), CompareOp.EQUAL, comparator2);
// testScan(scvf);
//针对列族名的过滤器 返回结果中只会包含满足条件的列族中的数据
// FamilyFilter ff1 = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("base_info")));
// FamilyFilter ff2 = new FamilyFilter(CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base")));
// testScan(ff1);
//针对列名的过滤器 返回结果中只会包含满足条件的列的数据
// QualifierFilter qf1 = new QualifierFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("password")));
// QualifierFilter qf2 = new QualifierFilter(CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("user")));
// testScan(qf2);
//多个过滤器同时使用 select * from t1 where id >10 or age <30
FamilyFilter ff2 = new FamilyFilter(CompareOp.EQUAL, new BinaryPrefixComparator(Bytes.toBytes("base")));
ColumnPrefixFilter cf = new ColumnPrefixFilter("password".getBytes());
FilterList filterList = new FilterList(Operator.MUST_PASS_ALL);
filterList.addFilter(ff2);
filterList.addFilter(cf);
testScan(filterList);
}
//定义一个方法,接受一个过滤器,返回结果数据
public void testScan(Filter filter) throws Exception {
Table table = conn.getTable(TableName.valueOf("t_user_info"));
Scan scan = new Scan();
//设置过滤器
scan.setFilter(filter); //select * from user where age >30
ResultScanner scanner = table.getScanner(scan);
Iterator<Result> iter = scanner.iterator();
//遍历所有的Result对象,获取结果
while (iter.hasNext()) {
Result result = iter.next();
CellScanner cellScanner = result.cellScanner();
while (cellScanner.advance()) {
Cell current = cellScanner.current();
byte[] rowArray = current.getRowArray();
byte[] familyArray = current.getFamilyArray();
byte[] valueArray = current.getValueArray();
byte[] qualifierArray = current.getQualifierArray();
//打印结果
System.out.println(new String(rowArray, current.getRowOffset(), current.getRowLength()));
System.out.print(new String(familyArray, current.getFamilyOffset(), current.getFamilyLength()));
System.out.print(":" + new String(qualifierArray, current.getQualifierOffset(), current.getQualifierLength()));
System.out.println(" " + new String(valueArray, current.getValueOffset(), current.getValueLength()));
}
System.out.println("-----------------------");
}
}
}
8、hbase的内部原理
8.1 系统架构
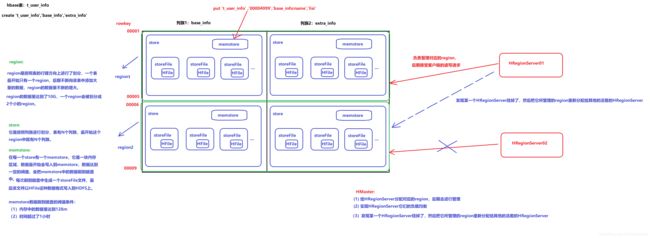
region: region是按照表的行键方向进行了划分 , 一个表最开始只有一个region , 后期不断向该表中添加大量的数据 , region的数据量不断的增大 .当region的数据量达到了10G, 一个region会被划分成两个小的region .
store: 它是按照行族进行划分 , 表有N个列族 .
memstore: 在每一个store有一个memstore , 数据达到一定的阈值 , 会把memstore中的数据刷到磁盘中 . 每次刷到磁盘中生成一个storeFile文件 , 最后该文件以HFile这种数据格式写入到HDFS上 .memstore数据刷到磁盘的阈值条件 :
(1) 内存中的数据量达到128M
(2) 时间超过了1小时
HMaster:(1) 给HRegionServer分配对应的region , 后期去进行管理
(2) 实现HRegionServer的负载均衡
(3) 发现某一个HRegionServer挂掉了 , 然后把它所管理的region重新分配到其他的或者的HRegionServer
具体每一个的职责 :
Client
1 包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如region的位置信息。
Zookeeper
1 保证任何时候,集群中只有一个master
2 存贮所有Region的寻址入口----root表在哪台服务器上。
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master职责
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 HDFS上的垃圾文件回收
5 处理schema更新请求
Region Server职责
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
8.2 物理存储
-
- 整体结构
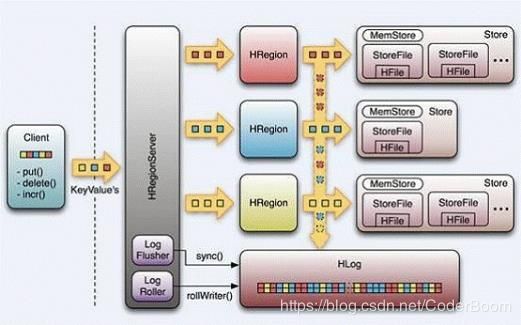
1 Table中的所有行都按照row key的字典序排列。 WAL
2 Table 在行的方向上分割为多个Hregion。
3 region按大小分割的(默认10G),每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
4 Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个regionserver上的。
5 HRegion虽然是负载均衡的最小单元,但并不是物理存储的最小单元。事实上,HRegion由一个或者多个Store组成,每个store保存一个column family。每个Strore又由一个memStore和0至多个StoreFile组成。如上图
-
- STORE FILE & HFILE结构
StoreFile以HFile格式保存在HDFS上。
附 : HFile的格式为 :
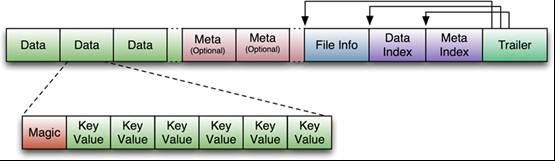
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
-
- Memstore与storefile
一个region由多个store组成,每个store包含一个列族的所有数据。
Store包括位于内存的memstore和位于硬盘的storefile。
客户端检索数据时,先在memstore找,找不到再找storefile。
-
- HLog(WAL log)
WAL 意为Write ahead log(http://en.wikipedia.org/wiki/Write-ahead_logging),该机制用于数据的容错和恢复,Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中(HLog文件格式见后续),HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据)。
HLog文件就是一个普通的Hadoop Sequence File:
-
HLog Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
-
HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
9、hbase的寻址机制

hbase查询效率高的原因是因为其寻址机制
- 每一个region都有其rowkey的起始值 , 当数据很大时 , 此时就会产生大量的region
- 此时我们就想到了增加一张表作为索引表1 , 保存原始数据中startRowkey , endRowkey , regionserver_id , region_id , 相对于原始表要小很多 , 有自己的startRowkey和endRowkey , 但是多张表又导致索引表1数据也变得比较庞大 , 我们还是采用构建索引表的方法 , 构建索引表2
- 此时大量数据的索引信息就减少了很多 , 一般此时都能大部分解决了 , 此时zk上就保存索引表2 , 由哪一个regionserver所管理的region上
- 当我们查询时 , 找到索引表2的中存储相关信息的regionServer , 依次向前查找 , 知道我们找到元数据中对应的region , 此时采用布隆过滤器找到对应字段组成最终结果返回给客户端
扩展 :
布隆过滤器: 它是作用在每一个storeFile , 可以快速的跳过不包括当前要查询的rowkey的文件 , 快速找到包含该rowkey的目标文件当我们要查找的是一个条件查询,怎么做?
一般我们会选择按照rowkey查询 , 因为它性能最快 , 这里是由于可以使用到上面的hbase的寻址机制 , 按照条件进行查询 , 这个时候由于整个表有大量的region , 每一个Region中有大量的storeFile , 每一个storeFile都有可能存在满足条件的数据 , 就需要依次进入到每一个文件中 , 进行遍历匹配比较 .
spark中默认的meta表就是索引表1 , 另外一张表(我们称之为ROOT)就是索引表2
现在假设我们要从Table2里面查询一条RowKey是RK10000的数据。那么我们应该遵循以下步骤:
-
从.META.表里面查询哪个Region包含这条数据。
-
获取管理这个Region的RegionServer地址。
-
连接这个RegionServer, 查到这条数据。
系统如何找到某个row key (或者某个 row key range)所在的region
bigtable 使用三层类似B+树的结构来保存region位置。
第一层: 保存zookeeper里面的文件,它持有root region的位置。
第二层:root region是.META.表的第一个region其中保存了.META.表其它region的位置。通过root region,我们就可以访问.META.表的数据。
第三层: .META.表它是一个特殊的表,保存了hbase中所有数据表的region 位置信息。
说明:
(1) root region永远不会被split,保证了最需要三次跳转,就能定位到任意region 。
(2).META.表每行保存一个region的位置信息,row key 采用表名+表的最后一行编码而成。
(3) 为了加快访问,.META.表的全部region都保存在内存中。
(4) client会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行最多6次网络来回,才能定位到正确的region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。
总结
Region定位流程:
a) 寻找RegionServer
ZooKeeper–> -ROOT-(单Region)–> .META.–> 用户表
b) -ROOT-表
表包含.META.表所在的region列表,该表只会有一个Region;
Zookeeper中记录了-ROOT-表的location。
c) .META.表
表包含所有的用户空间region列表,以及RegionServer的服务器地址
9.2 读写过程
-
读请求过程:
-
1) 客户端通过zookeeper以及root表和meta表找到目标数据所在的regionserver
-
(2)联系regionserver查询目标数据
-
(3)regionserver定位到目标数据所在的region,发出查询请求
-
(4)region先在memstore中查找,命中则返回
-
(5)如果在memstore中找不到,则在storefile中扫描(可能会扫描到很多的storefile----bloomfilter布隆过滤器)
补充:布隆过滤器参数类型有2种:
Row、row+col
-
-
写请求过程:
- (1)client向region server提交写请求
- (2)region server找到目标region
- (3)region检查数据是否与schema一致
- (4)如果客户端没有指定版本,则获取当前系统时间作为数据版本
- (5)将更新写入WAL log
- (6)将更新写入Memstore
- (7)判断Memstore的是否需要flush为StoreFile文件。
细节描述:
hbase使用MemStore和StoreFile存储对表的更新。
数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时,系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了。
当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(minor_compact, major_compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行split,等分为两个StoreFile。
由于对表的更新是不断追加的,compact时,需要访问Store中全部的 StoreFile和MemStore,将他们按row key进行合并,由于StoreFile和MemStore都是经过排序的,并且StoreFile带有内存中索引,合并的过程还是比较快。
- Region管理
(1) region分配
任何时刻,一个region只能分配给一个region server。master记录了当前有哪些可用的region server。以及当前哪些region分配给了哪些region server,哪些region还没有分配。当需要分配的新的region,并且有一个region server上有可用空间时,master就给这个region server发送一个装载请求,把region分配给这个region server。region server得到请求后,就开始对此region提供服务。
(2) region server上线
master使用zookeeper来跟踪region server状态。当某个region server启动时,会首先在zookeeper上的server目录下建立代表自己的znode。由于master订阅了server目录上的变更消息,当server目录下的文件出现新增或删除操作时,master可以得到来自zookeeper的实时通知。因此一旦region server上线,master能马上得到消息 .
(3) region server下线
当region server下线时,它和zookeeper的会话断开,zookeeper而自动释放代表这台server的文件上的独占锁。master就可以确定:
1、region server和zookeeper之间的网络断开了。
2、 region server挂了。
无论哪种情况,region server都无法继续为它的region提供服务了,此时master会删除server目录下代表这台region server的znode数据,并将这台region server的region分配给其它还活着的同志。
-
Master工作机制
- master上线
(1) 从zookeeper上
获取唯一一个代表active master的锁,用来阻止其它master成为活着的master。(2)扫描zookeeper上的servermaster启动进行以下步骤:
父节点,获得当前可用的region server列表。
(3)和每个region server通信,获得当前已分配的region和region server的对应关系。
(4)扫描.META.region的集合,计算得到当前还未分配的region,将他们放入待分配region列表。
- master下线
由于
master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region 上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。因此master下线短时间内对整个hbase集群没有影响。 -
HBase容错性- Master容错:Zookeeper重新选择一个新的Master
- 无Master过程中,数据读取仍照常进行;
- 无Master过程中,负载均衡无法进行;
- RegionServer容错:定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割并派送给新的RegionServer
- Zookeeper容错:Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
- Master容错:Zookeeper重新选择一个新的Master
10、Hbase高级应用
10.1 建表高级属性
- 1、BLOOMFILTER 默认是Row
布隆过滤可以每列族单独启用- Default = ROW 对行进行布隆过滤
- 对 ROW,行键的哈希在每次插入行时将被添加到布隆。
- 对 ROWCOL,行键 + 列族 + 列族修饰的哈希将在每次插入行时添加到布隆
- 使用方法:
create 'table',{BLOOMFILTER =>'ROW'} 启用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟
- 使用方法:
- VERSIONS 默认是1 这个参数的意思是数据保留1个版本,如果我们认为我们的数据没有这么大的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为1 能节约2/3的空间
- 使用方法:
create 'table',{VERSIONS=>'2'} - 附:
MIN_VERSIONS=> '0'是说在compact操作执行之后,至少要保留的版本
- 使用方法:
- COMPRESSION
默认值是NONE即不使用压缩- 这个参数意思是
该列族是否采用压缩,采用什么压缩算法 - 使用方法:
create 'table',{NAME=>'info',COMPRESSION=>'SNAPPY'}
- 这个参数意思是
| Algorithm | % remaining | Encoding | Decoding |
|---|---|---|---|
| GZIP | 13.4% | 21 MB/s | 118 MB/s |
| LZO | 20.5% | 135 MB/s | 410 MB/s |
| Zippy/Snappy | 22.2% | 172 MB/s | 409 MB/s |
如果建表之初没有压缩,后来想要加入压缩算法,可以通过alter修改schema
-
4、alter
-
使用方法:
- 如 修改压缩算法
disable 'table' alter 'table',{NAME=>'info',COMPRESSION=>'snappy'} enable 'table' 但是需要执行major_compact 'table' 命令之后 才会做实际的操作
-
-
5、TTL : 默认是2147483647 即:Integer.MAX_VALUE 值大概是68年
- 这个参数是说明该列族数据的存活时间,单位是s
这个参数可以根据具体的需求对数据设定存活时间,超过存过时间的数据将在表中不在显示,待下次major compact的时候再彻底删除数据
-
6、describe ‘table’ 这个命令查看了create table 的各项参数或者是默认值
-
7、
disable_all 'toplist.*'disable_all 支持正则表达式,并列出当前匹配的表的如下
toplist_a_total_1001 toplist_a_total_1002 toplist_a_total_1003 toplist_a_total_1004
......
Disable the above 25 tables (y/n)? 并给出确认提示
-
8、drop_all 这个命令和disable_all的使用方式是一样的
-
9、hbase表
预分区----手动分区默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候,所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入HBase时,会按照region分区情况,在集群内做数据的负载均衡。- 命令方式:
create 't1', 'f1',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'} - api的方式
bin/hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f info
参数: test_table是表名 HexStringSplit 是split 方式 -c 是分10个region -f 是family- 这样就可以将表预先分为15个区,减少数据达到storefile 大小的时候自动分区的时间消耗,并且还有以一个优势,
就是合理设计rowkey 能让各个region 的并发请求平均分配(趋于均匀) 使IO 效率达到最高,但是预分区需要将filesize 设置一个较大的值,设置哪个参数呢,hbase.hregion.max.filesize 这个值默认是10G 也就是说单个region ,默认大小是10G
10.2 hbase行键设计
-
表结构设计
- 1、列族数量的设定
- 以用户信息为例,可以将必须的基本信息存放在一个列族,而一些附加的额外信息可以放在另一列族
- 2、行键的设计
- 将需要批量查询的数据尽可能连续存放
- CMS系统----多条件查询 : 尽可能将查询条件关键词拼装到rowkey中,查询频率最高的条件尽量往前靠
- 1、列族数量的设定
-
Hbase的设计原则
- HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有以下几种方式:
- 通过get方式,指定rowkey获取唯一一条记录
- 通过scan方式,设置startRow和stopRow参数进行范围匹配
- 全表扫描,即直接扫描整张表中所有行记录
- HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有以下几种方式:
-
rowkey长度原则
- rowkey是一个二进制码流,可以是任意字符串,最大长度64kb,实际应用中一般为10-100bytes,以byte[]形式保存,一般设计成定长。
建议越短越好,不要超过16个字节- 数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长会极大影响HFile的存储效率
- MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
-
rowkey唯一原则
- 必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,
将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
- 必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,
-
rowkey散列原则
- 如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,
建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。 - 因为如果高位是相同的字段 , 会造成热点问题
- 如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,
-
热点问题
- HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。
- 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。下面是一些常见的避免热点的方法以及它们的优缺点:
- 加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
- 哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据。
- 反转 :
第三种防止热点的方法时反转固定长度或者数字格式的rowkey
这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
135****1023------>3201****531
136****9301------>1039****631
- 时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value -
timestamp 追加到key的末尾,例如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
其他的建议 :
尽量减少行键和列族的大小在HBase中,value永远和它的key一起传输的。
列族尽可能越短越好,最好是一个字符。
冗长的属性名虽然可读性好,但是更短的属性名存储在HBase中会更好。
扩展 : 当遇到条件查询时怎么解决
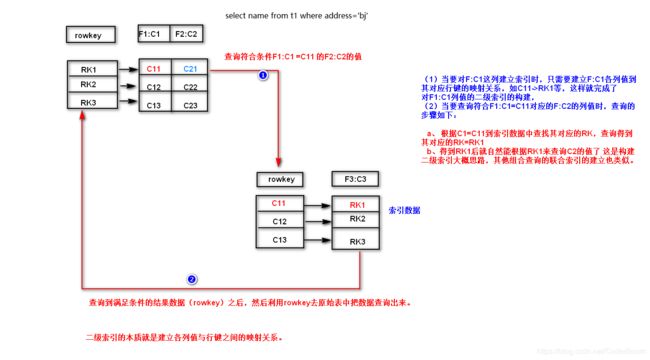
查询条件为 , 当列族F1下的C1字段等于C11的对应的列族F2的C2字段下的值
(1) 当要对F1:C1这列建立索引是 , 只需要建立F1:C1各列值到其对应行键的映射关系 , 如C11->RK1等 , 这样就完成了对F1:C1列值的二级索引的构建
(2) 当要查询符合F1:C1=C11对应的F2:C2的列值时 , 查询的步骤如下 :
a . 根据C1 = C11到索引数据中查找对应的RK , 查询得到其对应对的RK = RK1
b . 得到RK1后就自然能够根据RK1来查询C2的值了 , 这是构建二级索引大概思路 , 其他组合查询的联合索引的建立也类似 .
二级索引的本质就是建立各列值与行键之间的映射关系