java 线程池详解
1:将低资源消耗.通过重复利用已创建的线程降低线程创建和销毁造成的消耗,如果你不使用线程池,而是自己去创建线程,比如要100个线程你都要去创建的话,内存也吃不消,这就大大消耗了内存,既然你创建消耗了内存,所以你线程执行完销毁也是需要消耗内存的.
2:提高响应速度:当任务达到时,认为可以不需要等待线程创建就能立即执行
3:提高线程的可管理性:线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,这是指消耗cpu,因为cpu要分配时间片给线程执行,还会降低系统的稳定性,线程多了,出错的概率就越大,并发本来就比较难把握.
当我们向线程池提交一个任务之后,线程池是如何处理这个任务呢?线程池处理线程的流程如下:
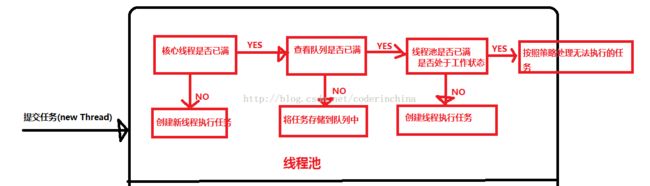
1:线程池判断核心线程池里的线程是否都在执行.如果不是,则创建一个新的工作线程来执行,如果核心线程池里的都在执行任务,则进入第二步:
2:线程池判断工作队列是否已满,如果工作队列没有满,则将新提交的任务存储在这个工作队列里,如果工作队列满了,则进入第三步
3:判断线程池的线程是否都处于工作状态,如果没有,则创建一个新的工作线程来执行任务,如果已经满了,则交给饱和策略来处理这个任务.
现在画一个流程图对线程池的流程做个梳理:
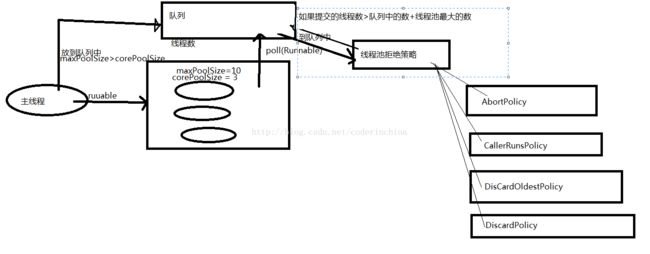
在java中线程池用ThreadPoolExecutor类表示,要实例化这个对象呢?有二种方法,一种是直接new,一种是通过jdk给我们提供的工具类Executors,Executors是单例的
现在看下ThreadPoolExecutor类的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) 参数说明:
1:corePoolSize:线程池中核心线程数,当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行任务也会创建线程,等到需要执行的任务大于线程池中的核心线程数,就不会再创建,如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程
2:maximumPoolSize:线程池最大线程数,也就是线程池允许创建的最多线程数,如果队列满了,并且已创建的线程数小于线程池设置的最多线程数,则线程池会再创建新的线程执行任务,注意,如果使用了无界的任务队列这个参数就不起什么作用.
3:keepAliveTime:(线程活动保持的时间)线程池的工作线程空闲后,保持存活的时间,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率
4:unit(线程活动保持时间的单位):可选的单位有天DAYS,小时HOURS,分钟MINUTES,毫秒MILLISECONDS,微妙MICROSECONDS,千分之一毫秒和纳秒NANOSECONDS=千分之一微妙
5:workQueue(阻塞队列),用于保存等待执行任务的阻塞队列,jdk提高了好几种阻塞队列,这个会等下细讲6:threadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置一个更有意义的名字,一般很少使用.
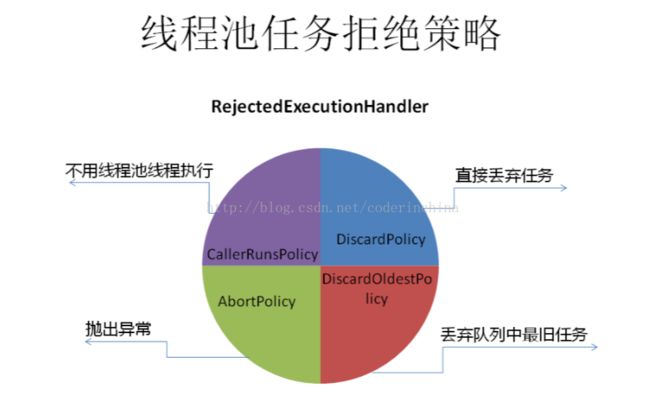
7:handler(饱和策略),当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务,这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常,在jdk1.5中线程池框架提供了4种策略:AbortPolicy:直接抛出异常CallerRunsPolicy:只用调用者所在线程来执行任务DisCardOldestPolicy:遗弃队列里最近的一个任务,并执行当前任务.DiscardPolicy:不处理,直接遗弃,来自网上的一张图:
线程池执行二种方式
当我们创建好了线程池对象后,就可以向线程池提交任务,提交任务有种方式,分别有execute()和submit(),
execute()方法提交任务不需要返回值,所以无法判断任务是否被线程池执行成功
submit():执行线程有返回值,线程池会返回一个Future类型的对象,通过这个future对象判断任务是否执行成功,并且可以通过future对象的get方法来获取返回值,get()方法会阻塞当前线程直到任务完成,
关闭线程池
关闭线程可以调用线程池的shutdown()方法或者shutdownNow()方法,它的原理是遍历线程池中的所有正在执行任务的线程,然后每个线程调用interrupt方法来中断线程,所以无法响应中断的线程可能无法终止,但是这个二个方法有一定的区别:shutdownNow()首先将线程池的状态设置为stop,然后尝试停止所有正在执行或者暂停执行的线程,并返回等待执行任务的列表,而shutdown()只是将线程池的状态设置为SHUTDOWN状态,然后中断所有没有正在执行任务的线程.只要调用了这二个方法中的其中一个,isShutdown方法会返回true,当所有的任务都已关闭,才表示线程池关闭成功,这时调用isTerminaed方法会返回true,至于要调用哪一种方法来关闭线程池,应该由提交到线程池的任务特性来决定,通常调用shutdown方法来关闭线程池,如果任务不一定要执行完,则可以调用shutdownNow方法
线程池其他方法
public long getTaskCount()获取执行任务的个数
protected void beforeExecute(Thread t, Runnable r)在线程池执行前
protected void afterExecute(Runnable r, Throwable t)在线程池执行后
protected void terminated() { }线程池是否执行完毕
public int getActiveCount()获取正在执行任务的个数
public int getPoolSize() 获取线程池的大小
public boolean remove(Runnable task)移除一个任务
public BlockingQueue
public long getKeepAliveTime(TimeUnit unit)获取保持线程池存活的时间
public int getCorePoolSize()获取核心线程数
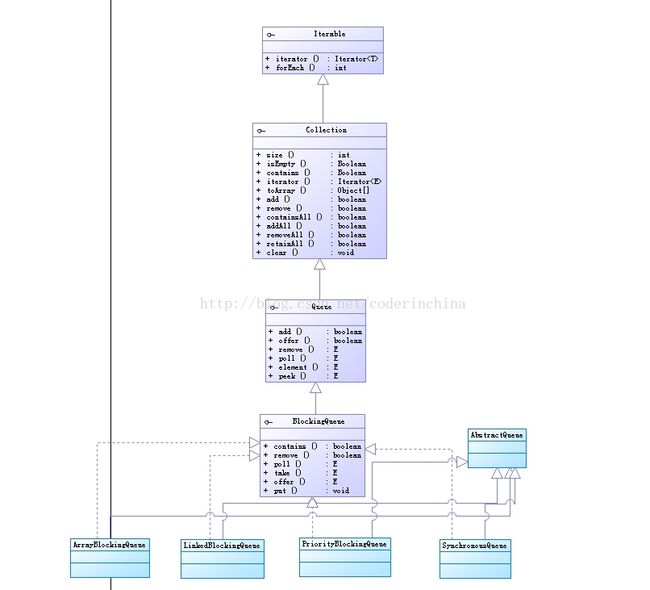
之前构造函数中有一个参数是队列,现在讲下java中常用的队列
阻塞队列
阻塞队列(BlockingQueue)是一个支持二个附加操作的队列,插入和移除方法
插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满
移除方法:在队列为空时,获取元素的线程会等待队列非空,阻塞队列常用于的场景是生产者和消费者,生产者是向队列中添加线程,消费者是从队列中获取线程
如果BlockQueue是空的,从BlockingQueue获取线程操作将会被阻断进入等待状态,直到BlockingQueue有线程时会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作
阻塞队列插入有三个方法 add(),offer(),put(),但是这三个方法是有区别的:
add():加一个线程到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则报异常
offer():将线程加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
put():将线程加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续,处于一直阻塞的状态
阻塞队列移除也有对应的几个方法:remove(),poll(),take()
remove()方法直接删除队头的元素:
pool()方法取出并删除队头的元素,当队列为空,返回null;
take()方法取出并删除队头的元素,当队列为空,则会一直等待直到队列有新元素可以取出,或者线程被中断抛出异常
注意:如果是无界阻塞队列,队列不可能出现 满的情况,所以使用put或者offer方法永远不会被阻塞,而且使用offer方法时,该方法会永远返回true
jdk5提供了4中阻塞队列:
ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序,这个要懂数据结构才好,可惜我现在不懂数据结构,
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高ArrayBlockingQueue,静态工厂方法Executors.newFixedThreadPool()使用了这个队列,默认此队列最大的长度为Integer.MAX_VALUE
SynchronousQueue:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于ArrayBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列,它支持公平访问队列,默认情况下线程采用非公平性策略访问队列默认情况下是非公平,如果把设置为公平访问队列的话,就调用带boolean类型的构造函数,传递true就会采用先进先出的顺序访问队列
PriorityBlockingQueue:一个具有优先级的无限阻塞队列.默认情况下元素采取自然顺序升序排列,也可以自定义类实现compareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序,需要注意的是不能保证同优先级元素的排序
现在把类图画下:
平时开发工作中,一般使用线程池都是使用一个工具类去创建一个线程池,这个类就是Executors,其关系类图如下:
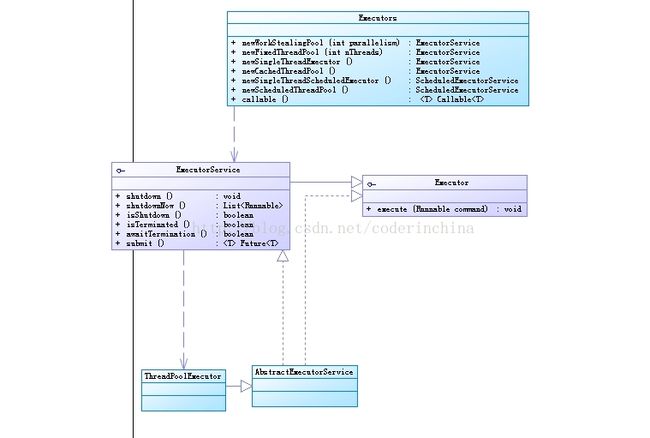
Executor框架介绍
Executor框架主要由3部分组成
1:任务,包括被执行需要实现的接口,Runnable或者是Callable接口.
2:任务的执行,包括任务执行机制的核心类Exector,以及继承Executor的ExecutorService接口,Executor框架有二个关键类实现了ExecutorService接口(ThreadPoolExecutor和ScheduledThreadPoolExecutor)
3:异步计算的结果,包括接口Future和实现Future接口的FutureTask类.
ThreadPoolExecutor通常是使用Executors工厂类来创建,Executors可以创建三种类型的ThreadPoolExecutor,分别是
1:创建固定个数的线程数,
ExecutorService executorService = Executors.newFixedThreadPool(5);
2:创建单个线程数:
ExecutorService executorService = Executors.newSingleThreadExecutor()
3:创建带缓存的线程池
ExecutorService executorService = Executors.newCachedThreadPool();
当然Executors还可以创建定时调度的线程池
Executors.newScheduledThreadPool(5);
这个返回的是ScheduledExecutorService对象,它继承了ExecutorService接口,ScheduledExecutorService适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景.
Executors.newFixedThreadPool()
fixedThreadPool被称为可重用固定线程数的线程池.源码如下:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} 这篇博客好久没一直没把剩下的写完,今天就把剩下的写完。
调用Executors.newFixedThreadPool(5)获取的线程池后执行execute()的流程如下:

因为是采用了无界队列LinkedBlockingQueue,所以有几个参数是无效的,maximumpoolSize,keepAliveTime,以及线程池的拒绝策略.
Executors.newSingleThreadExecutor()
Executors.newSingleThreadExecutor()是使用单个工作线程的线程池,源码如下:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue())) 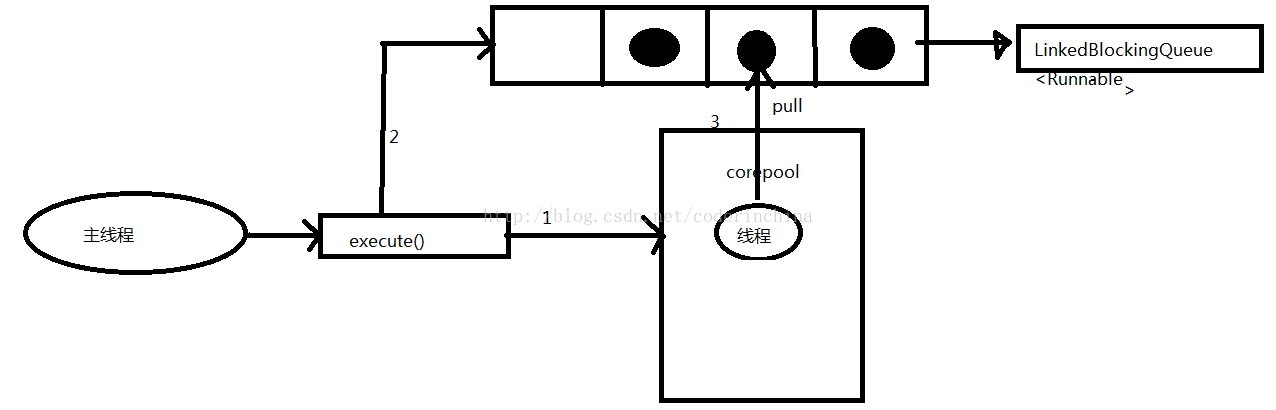
它的原理其实有一个线程轮询的去判断corePool是否等于1,不等于1就从队列中去取一个线程来执行,
Executors.newCachedThreadPool()
源码如下:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
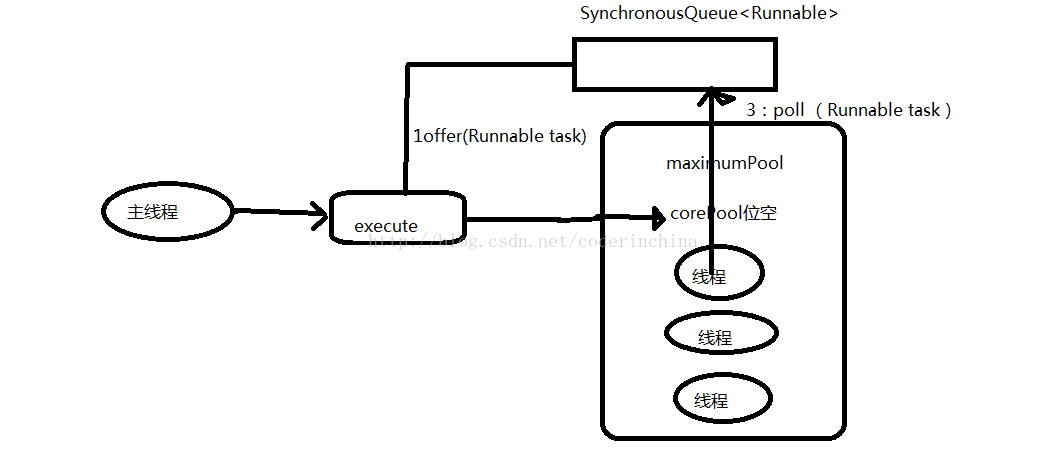
} 工作流程如下:
流程说明:
1:首先执行SynchronousQueue.off(Runnable task),如果当前maximumPool中有空闲线程正在执行SynchronousQueue.poll(),那么主线程执行offer操作与空闲线程执行的pool操作匹配成功(也就是判断是否超过了60秒),主线程把任务交给空闲线程执行,execute()方法执行完成,如果超过60秒就走第二步
2:当初始maximumPool为空时,或者maximumPool中当前没有空闲线程时,将没有线程行SynchronousQueue.poll()
,这种情况下将失败,此时会创建一个新线程执行任务,execute()方法执行完成.
3:在第二步新创建的线程将任务执行完后,会执行SynchronousQueue.poll(),这个poll操作会让空闲线程最多在SynchronousQueue中等待60秒,如果60秒钟内主线程提交了一个新任务,那么这个时候空闲线程将执行主线程提交的新任务,否则这个空闲线程将会终止,由于空闲60秒的空闲线程会被终止,因此长时间保持空闲的SynchronousQueue不会使用任何资源.
缓存线程池任务传递的示意图如下:

线程池拒绝策略
比如有这样一个需求,我一次性下载30个文件,
ThreadPoolManager.java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.RejectedExecutionHandler;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolManager {
private static ThreadPoolManager instance=new ThreadPoolManager();
private LinkedBlockingQueue> taskQuene=new LinkedBlockingQueue<>();
private ThreadPoolExecutor threadPoolExecutor;
public static ThreadPoolManager getInstance() {
return instance;
}
private ThreadPoolManager()
{
threadPoolExecutor=new ThreadPoolExecutor(5,10,5, TimeUnit.SECONDS,new ArrayBlockingQueue(5), handler);
threadPoolExecutor.execute(runable);
}
private Runnable runable =new Runnable() {
@Override
public void run() {
while (true)
{
FutureTask futrueTask=null;
try {
System.out.println("等待队列 "+taskQuene.size());
futrueTask= (FutureTask) taskQuene.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
if(futrueTask!=null)
{
threadPoolExecutor.execute(futrueTask);
}
}
}
};
private RejectedExecutionHandler handler=new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
taskQuene.put(new FutureTask
public class HttpTask implements Runnable {
private String name;
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
@Override
public void run() {
System.out.println(name+"线程执行完毕");
}
}
import java.util.concurrent.FutureTask;
public class Test {
public static void main(String[] args) {
for(int i=0;i<15;i++){
HttpTask httpTask=new HttpTask();
httpTask.setName("第"+i+"个");
try {
ThreadPoolManager.getInstance().execte(new FutureTask 等待队列 0
等待队列 14
等待队列 13
第0个线程执行完毕
等待队列 12
第2个线程执行完毕
等待队列 11
第3个线程执行完毕
第1个线程执行完毕
第4个线程执行完毕
等待队列 10
等待队列 9
第5个线程执行完毕
第6个线程执行完毕
等待队列 8
等待队列 7
第7个线程执行完毕
第8个线程执行完毕
等待队列 6
等待队列 5
等待队列 4
等待队列 3
等待队列 2
等待队列 1
第9个线程执行完毕
第11个线程执行完毕
第14个线程执行完毕
等待队列 0
第10个线程执行完毕
第13个线程执行完毕
第12个线程执行完毕
这里就使用了线程池的拒绝策略
RejectedExecutionHandler handler = new ThreadPoolExecutor.DiscardOldestPolicy();
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();
RejectedExecutionHandler handler = new ThreadPoolExecutor.CallerRunsPolicy();
RejectedExecutionHandler handler = new ThreadPoolExecutor.AbortPolicy();
创建四种策略如下,这些都是RejectedExecutionHandler 的内部类.
总的流程如下: