分布式计算-MapReduce
分布式计算-MapReduce
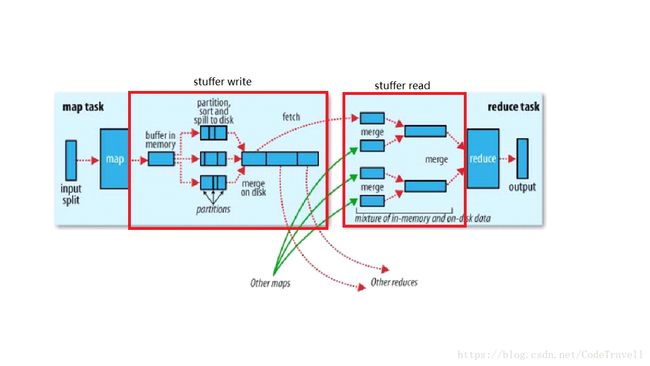
假设计算搭建在HDFS上,因为HDFS block块是按照字节来切割,切割时块与块之间极有可能出现乱码,所有每一个split切块会比block略大或者略小,对每一个split的处理分大致为4步。
-
map task
map task将处理后的每一条记录打上标签(分区),便于最后选择reduce task处理,分区是由分区器进行分区,默认的分区器是HashPartitioner,分区的策略是根据key的HashCode与reduce task的个数取模。 -
shuffle write
数据进入buffer后每一条记录由3部分组成:分区号,key和value。
map task一条条往buffer中去写,一旦写入到80M,此时这80M的内存将会被封锁,封锁后会对这80M数据进行combiner(小的聚合),然后进行一次排序,排序根据分区号和key,将相同的分区号的数据放在一起,并且分区内数据有序,排序完成后就开始将数据溢写到磁盘上,此时的磁盘文件中数据都是同一个分区并且内部有序的文件,每进行一次溢写就会生成一个磁盘小文件。在这80M内存被封锁时,剩下20M内存会并行的写入数据。
map task处理完毕后,会将磁盘上的小文件合并成一个有序的大文件(归并排序),每一个map task都会生成一个这样有序的大文件 -
shuffle read
从map端读取相应的分区数据,将分区数据写入到内存中,内存满了就会溢写,溢写之前会进行排序,当把所有的数据取出来后,会将溢写产生的磁盘小文件进行合并并排序,形成有序的大文件,产生有序的大文件就是为了提高分组的效率,减少数据的遍历。归根结底,四次排序都是为了提高最后的分组效率 -
reduce task
每一组数据调用reduce函数,输出结果
MapReduce->Application->资源调度器->任务调度器->分布式并行计算 -
Hadoop1.X版本
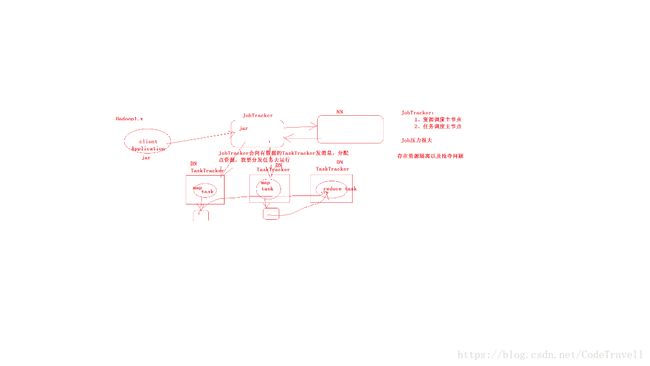
在hadoop1.x版本时,HDFS自带资源调度器和任务调度器,称之为JobTracker。JobTracker负责资源的调度,和任务的分配,容易出现单点故障,而且在资源隔离以及抢夺方面存在问题,所有在2.X版本被废除了。 -
Hadoop2.X版本

在Hadoop2.x版本时,HDFS配有了一个资源管理器ResourceManager,只负责资源的调度,而任务的分配需要Application自己实现,这样就解决了资源隔离和抢夺的问题。
如上图,当client向HDFS发出请求时(请求启动一个ApplicationMaster),ResourceManager会随机选择一个节点启动ApplicationMaster,ApplicationMaster会从client拿到生成NameNode返回的列表,并向ResourceManager申请资源,ResourceManager会优先找到本地存有要处理的数据的节点以减少网络传输,ApplicationMaster申请到资源后会分配计算任务到节点上然后进行计算。
ApplicationMaster如果挂掉,整个任务就会停止,此时ResourceManager会重启ApplicationMaster,如果ResourceManager挂掉,Zookeeper会启动备用的ResourceManager。
如果其他的计算框架想要运行到yarn集群上,此时需要实现ApplicationMaster这个组件。
未完待续…