MapReduce1和YARN(MapReduce2)运行机制
在hadoop1.x中,通过设置mapred.job.tracker来决定执行mapreduce机制,如果设置为local,则使用本地的作业运行器,如果设置为主机和端口号,则这个地址被解析为一个jobtracker地址,运行器则将作业提交给jobtracker。
在hadoop2.x中,mapreduce运行在YARN上,通过mapreduce.framework.name属性设置,local表示本地运行,classic表示经典mapreduce框架,yarn表示新的框架。
针对MapReduceAPI,由于API是面向用户客户端的,他决定着用户怎么样写MapReduce,和运行机制没有关系,不同运行机制只是表示执行MapReduce的途径不一样而已。
MapReduce1中运行机制
在MapReduce1中包括的实体组件有四部分:
客户端:负责提交MapReduce作业
JobTracker:协调作业运行
TaskTracker:运行作业划分后的任务
分布式文件系统:用来在实体间共享作业文件。
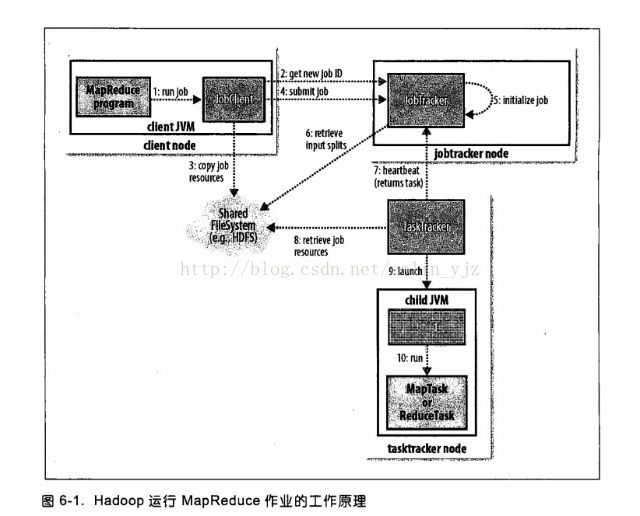
1、通过submit或者waitForCompletion提交作业,waitForCompletion()方法通过每秒循环轮转作业进度,如果发现与上次报告有改变,则将进度报告发送到控制台。其实waitForComplection()方法中还是调用submit()方法。
2、submit()方法中或创建一个JobSubmitter实例,然后JobSubmitter会想JobTracker获取一个JobID
3、将运行作业所需要的资源如JAR文件、配置文件、计算所得的输入分片等复制到一个以作业ID命名的目录下jobtracker的文件系统(在这之前会检查输出说明、计算作业的输入分片)。
4、开始告知JobTracker准备执行作业。
5、作业初始化:当jobtracker接收到JobTracker提交的submitJob()方法之后,会将这个调用放到一个内部序列中,交由作业调度器进行调度,并对其初始化,初始化包括一个表示正在运行的作业的对象,用来封装任务和记录信息,以便跟踪任务的转台和进程。
6、为了创建任务列表,jobtracker需要从文件系统获取已经计算好的输入分片,然后为每个分片创建一个map任务。reduce的个数是通过mapred.reduce.tasks属性决定。
7、tasktracker通过运行一个简单的循环的来定期向jobtracker发送“心跳”(heartbeat),以此来说明tasktracker还存活,并且通过心跳机制,来充当二者之间的信息通道。
8、任务执行:tasktracker已经被分配一个任务,下一步开始运行这个任务,首先第一步他会从共享文件将jar包复制到本地文件系统,从而达到本地化。同事tasktracker会从分布式文件系统将所需的全部文件复制到本地磁盘。第二部是在本地为这个任务创建一个工作目录,并把jar解压在此处。第三部是为这个任务创建一个TaskRunner来运行该任务。
9、TaskRunner启动一个JVM来运行每个任务(这个在图中10)。以便map任务和reduce任务出现任何问题,都不会影响到tasktracker,但是可以重用JVM。
YARN(MapReduce2)运行机制
当集群节点超过4000,MapReduce1面临着瓶颈,这样下一个MapReduce应运而生,由此,YARN(YetAnother Resource Nefotiator)也营运而生。
在MapReduce1中JobTracker负责作业调度和任务监视,追踪任务、重启失败或过慢的任务和进行任务等级这么多工作。YARN将其分为两个独立的守护进程:管理集群上的资源使用的资源管理器ResourceManager(RM)和管理集群上运行任务的生命周期的应用管理器ApplicationMaster(AM)
容器(对应MapReduce1中的任务槽)containers是将资源隔离出来的一种框架,每一个任务对应着一个container,且只能在该Container上运行。应用管理器(AM)和资源管理器(RM)协调这个计算资源containers。
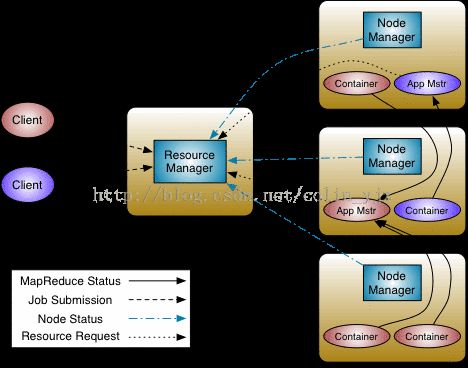
YARN提高了集群的管理和集群的利用率,通过YARN系统,可以运行不同的计算框架。
YARN上的实体:
Client:用来提交作业
ResourceManager:协调集群上的计算资源的分配
NodeManager:负责启动和监控集群上的计算容器(container)
ApplicationMaster:协调运行MapReduce任务,他和应用程序任务运行在container中,这些congtainer有RM分配并且由NM进行管理
DFS:共享实体间的作业文件
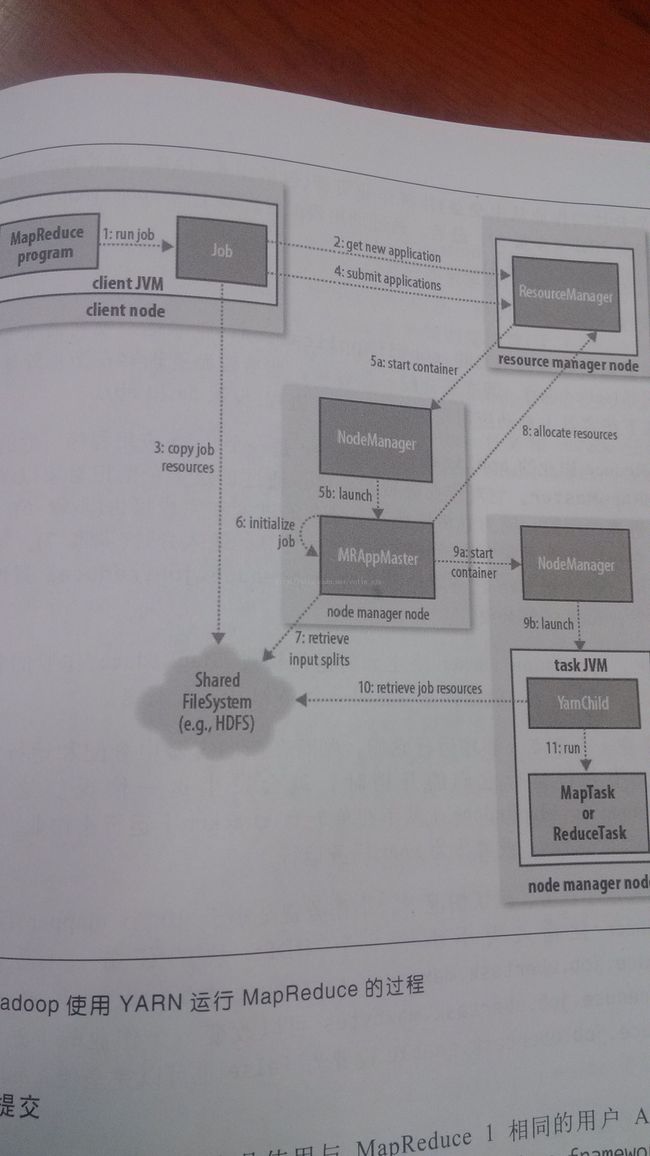
1、作业提交
通过submit或者waitForCompletion提交作业,waitForCompletion()方法通过每秒循环轮转作业进度,如果发现与上次报告有改变,则将进度报告发送到控制台。其实waitForComplection()方法中还是调用submit()方法。
2、从资源管理器ResourceManager获取作业ID,在YARN中叫做应用程序ID。
3、这时候作业客户端检查输出说明、计算输入分片(可以通过yarn.app.mapreduce.am.computer-splits-in-cluster在集群上产生分片),并将作业信息(jar、配置文件、分片信息)复制到HDFS
4、通过submitApplication()方法提交作业。
5a-5b、资源管理器在收到submitApplication()消息后,将请求传递给调度器(Scheduler),调度器为其分配一个容器Container,然后RM在NM的管理下在container中启动程序的ApplicationMaster进程。
6、applicationmaster是一个java应用程序,他的主类是MRAppmaster。applicationmaster对作业进行初始化,创建过个薄记对象以跟踪作业进度。
7、applicationmaster接受来自HDFS在客户端计算的输入分片,对每一个分片创建一个map任务,任务对象,由mapreduce.job.reduces属性设置reduce个数。
uber模式
当任务小的时候就会启动一个JVM运行MapReduce作业,这在MapReduce1中是不允许的,这样的作业在YARN中成为uber作业,通过设置mapreduce.job.ubertask.enable设置为false使用。
那什么是小任务呢?当小于10个mapper且只有1个reducer且输入大小小于一个HDFS块的任务。
但是这三个值可以重新设定:mapreduce.job.ubertask.maxmaps
8、如果作业不适合uber任务运行,applicationmaster就会为所有的map任务和reduce任务向资源管理器申请容器。请求业为任务指定内存需求,map任务和reduce任务的默认都会申请1024MB的内存,这个值可以通过mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来设置。这里的内存分配策略和mapreduce1中不同,在MR1中tasktracker中有固定数量的槽,每个任务运行在一个槽中,槽有最大内存分配限制,这样集群是固定的,当任务使用较少内存时,无法充分是哟欧诺个内存,造成其他任务不能够获取足够内存因而导致作业失败。在YARN中,资源分为更细的粒度,所以避免了以上的问题。应用程序可以申请最小到最大内存限制的任意最小值的倍数的内存容量。默认值是1024~10240,可以通过yarn.scheduler.capacity.minimum-allocation-mb和yarn.scheduler.capacity.maximum-allocation.mb设定。任务可以通过设置mapreduce.map.memory.mb和mapreduce.reduce.memory.mb来请求1GB到10GB的任意1GB的整数倍的内存容量。
9a~9b、资源管理器为任务分配了容器,applicationmaster就通过节点管理器启动容器。该任务由主类YarnChild的java应用程序执行。
10、运行任务之前,首先将资源本地化,包括作业配置、jar文件和所有来自分布式缓存的文件
11、最后执行map任务和reduce任务