H.264-AVC视频编码原理及实现
一视频相关概念
1.1视频
时间连续的图像序列称为视频。

1.2相关性
图像本身具有的自己特性,图像与图像之间具有一定的关联性。
时间相关性:一幅图像中的大部分元素都同样存在于其相邻的图像(前后)之中。
空间相关性:一幅图像中相邻像素之间具有相关性。
统计相关性:图像在保存的过程中,通过不同的统计方法,可以得到比原始数据较少的数据。
1.3 YUV图像格式
试验表明,人眼对于图像中的亮度分量(明暗)最敏感,对于图像中的色度(颜色)分量相对来讲敏感度相差。

1.4 DTS和PTS
DTS:Decoder Time Stamp,用来表示图像的解码时间。
PTS:Presentation Time Stamp,用来表示图像的显示时间。
引入这两变量主要是因为,在存在双向参考帧时,图像在编码图像的顺序和编码输出的顺序不同。


1.5 重构帧
在编码的过程中,需要对已经编码的图像进行解码,解码后的图像称作重构帧(restructure frame)。重构帧将作为其后编码图像的参考帧。
1.6 逐行和隔行
逐行比较好理解,假设一帧图像的大小是704x576,那么逐行的话就是576行。
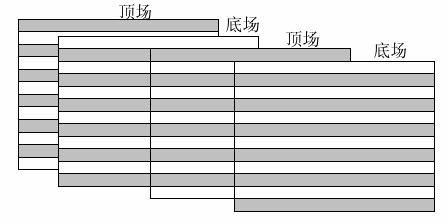
隔行图像,是早期电视信号中引入的概念,把一帧图像分为上下两场,两场图像在时间上具有先后,但传输时同时传送到显示端,显示端在显示按各自的时间分开进行显示。该方式主要是利用了人眼的余辉效应,通过隔行显示,提高了显示的流畅性。

二视频编码基本原理
2.1 原理图
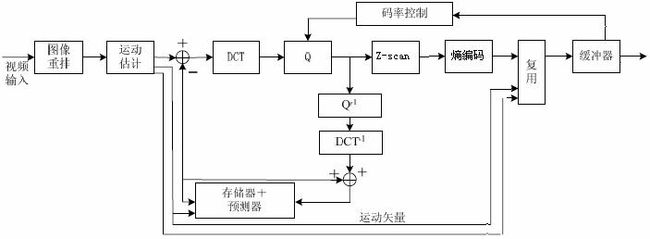
目前常用的视频编码算法基本上都是以运动估计和以块为单位的时-频变换为基础。
运动估计,处理了相邻视频帧中的相同部分。
时-频变换,使得数据块的能量更加集中地分布。常用的时-频变换是DCT变换。
2.2 运动估计
运动估计(Motion Estimation),相邻视频帧之间的内容存在一定的相关性。把图像分成若干块,通过一定的搜索算法,在邻近帧中找到和该块最相似的块,这个过程称为运动估计,二者之间的相对偏移量称为运动矢量。
在编码的过程中,对运动矢量和预测的参差进行编码。通过运动估计减少了帧间的时间冗余。
常用的运动估计的匹配算法有:
常用运动估计的搜索算法有:

1 全匹配法
光栅方式扫描所有像素,找到最匹配的块位置。

2 二维对数法
又称五点搜索,边缘点以原步长继续搜索,中心点或边界点步长减半。
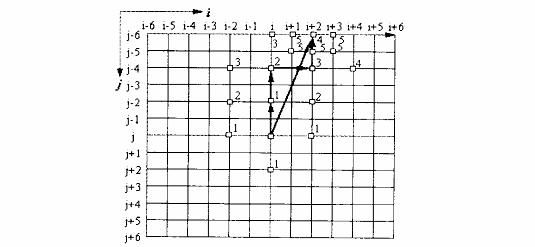
3 三步搜索
又称8点搜索,每次确定下一步的搜索点,并将步长减半。

4 领域搜索
根据邻近已编码MB的位置,确定中心的,如果原点最匹配,停止搜索,如果最匹配点是搜索框边缘,继续以该点为中心进行搜索。
5 其它
菱形搜索
钻石搜索
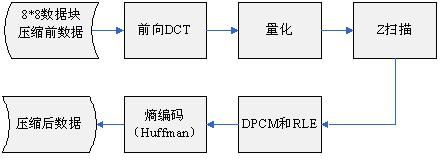
2.3 DCT
对数据块进行空域到时域的变换,能量更加集中。
转换公式:

对于一个8x8的数据块(表1)经过DCT后转换成表2:

在DCT的转换过程中,当u=0,v=0时,F(0,0)代表了整个8*8图像块的均值,F(0,0)称为直流系数(DC),其余变换后的63个数,称为交流系数(AC)。交流系数距离直流系数越远,交流系数的频率越高。

2.4 量化
量化:目的是使保存数据的比特数降低,手段是把一批输入值对应到一个输出级上,结果降低了数据的精度。
量化示例:

结论:经过量化后的数据,在进行解码还原时势必导致图像的失真。量化的精度,决定了图像还原时的失真程度,精度越高,失真越小,反映在码率上,就是量化精度越高,码率越大。
帧内编码和帧间编码采用的不同量化方式
编码时对量化值进行编码传输。
量化公式:

2.5 Z-Scan
DCT加量化后的数据,能量都集中在左上角,在进行数据保存时采用Z扫描的顺序进行保存。

经过Z扫描后,直流系数和交流系数的低频部分,会排在新数组的前面,而交流系数的高频部分排到后面,而高频中大部分数的值大多都是0,这样我们就把可以得到一长串的“0”的序列,为下一步的编码做好准备。
2.6 熵编码
原理:信息冗余
常用的熵编码有:
RLE:行程长度编码,是针对交流系数进行编码的,它的编码原理是,使用一个字节的高4位表示连续的0的个数,使用它的低4位表示编码下一个非0系数所需要的位数,跟在后面的是非0系数的值。
Huffman:在变长编码中,对出现概率大的符号赋予短码字,对出现概率小的符号赋予长码字。

其它:CAVLC,CABAC
2.7 重构
模拟解码器对已经编码的数据进行解码,解码后的视频数据作为其后编码的视频的参考帧数据。
三MPEG-2编码
3.1 I帧编码
MPEG-2编码宏块大小为16x16,分解4个8x8Y数据块和2个CrCb数据块。
I帧编码后的重构见下节。
3.2 B,P帧编码
B,P帧以16x16宏块大小为单位进行ME,其后操作和I帧相同;对于所有帧都要在量化进行重构,重构后的重构帧作为其后编码帧的参考帧。

3.3 P帧MB的运动估计
P帧进行前向预测,参考其编码的I帧或P帧。在对P帧中的MB进行运动估计时,一般会先参考该宏块左方、上方和右上方的宏块的运动矢量,找到最佳的匹配块位置。P帧中MB的最终编码类型,还需要比较帧内编码(Intra)和帧间(Inter)编码的MSE,来确定最终的编码类型。因此在P帧中,一般会有帧内和帧间两种编码类型。
同时,在MPEG-2中,增加了1/2像素搜索,这样增加了匹配的准确度。
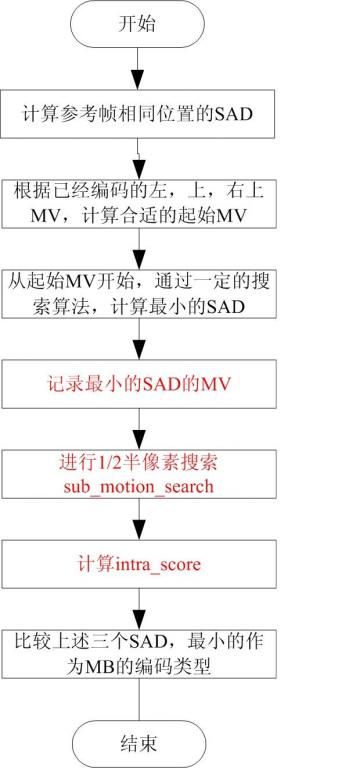
3.4 B帧的MB的运动估计
B帧的宏块可能存在的编码类型有:I类型,P类型,B类型和Bi类型。
具体的ME过程如下:
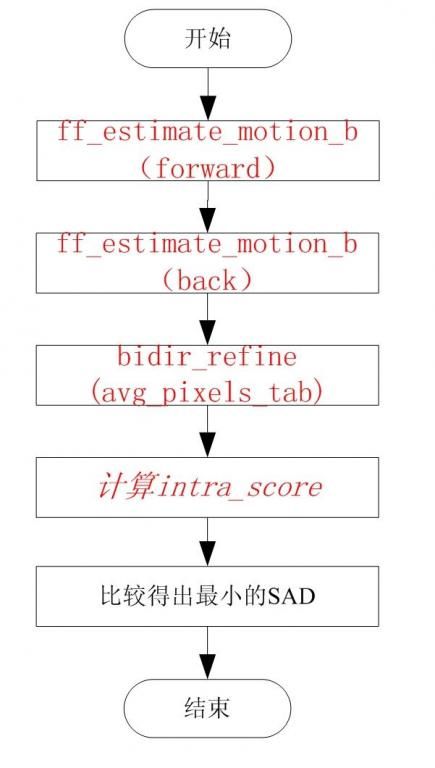
由上图我们可以看到,在进行B块的运动估计时,需要对forward,Back,Bidir,itnra四种方式进行比较,得到最佳的SAD作为最终的编码类型。
3.5 Skip MB和I_PCM MB
在MPEG-2编码时,有一些MB不需要进行编码,这样的MB称为Skip MB。Skip MB需要满足的基本条件包括:
1 运动矢量为0
2 CBP为0
有些编码器也其它的条件限制,比如在FFMPEG中,Skip MB不可以是非右边和下边的边界点。
I_PCM,直接传输图像像素值,不经过任何变换。应用场合包括:
1. 图像本身不规则,编码比不编码使用的比特数还多。
更精确地传输图像
四FFMPEG代码结构
4.1 FFMPEG简介
FFmpeg is a complete solution to record, convert and stream audio and video. It includes libavcodec, the leading audio/video codec library. FFmpeg is developed under Linux, but it can compiled under most operating systems, including Windows.
组成部分:
- ffmpeg 是一个命令列工具,用来对视讯档案转换格式,也支援对电视卡即时编码
- ffserver 是一个 HTTP 多媒体即时广播串流服务器,支援时光平移
- ffplay 是一个简单的播放器,基于 SDL 与 FFmpeg 函式库
- libavcodec 包含了全部 FFmpeg 音讯/视讯 编解码函式库
- libavformat 包含 demuxers 和 muxer 函式库
- libavutil 包含一些工具函式库
- libpostproc 对于视讯做前处理的函式库
- libswscale 对于影像作缩放的函式库
相关网站:
http://ffmpeg.org/
http://www.ffmpeg.com.cn/index.php
4.2 FFMPEG的代码体系结构
FFMPEG包括了多种视音频的CODEC,对于每种CODEC,FFMPEG要求提供一个满足结构体AVCodec的数据结构:
/**
* AVCodec.
*/
typedef struct AVCodec {
const char *name;
enum CodecType type;
enum CodecID id;
int priv_data_size;
int (*init)(AVCodecContext *);
int (*encode)(AVCodecContext *, uint8_t *buf, int buf_size, void *data);
int (*close)(AVCodecContext *);
int (*decode)(AVCodecContext *, void *outdata, int *outdata_size,
uint8_t *buf, int buf_size);
int capabilities;
#if LIBAVCODEC_VERSION_INT < ((50<<16)+(0<<8)+0)
void *dummy; // FIXME remove next time we break binary compatibility
#endif
struct AVCodec *next;
void (*flush)(AVCodecContext *);
const AVRational *supported_framerates; ///array of supported framerates, or NULL if any, array is terminated by {0,0}
const enum PixelFormat *pix_fmts; ///array of supported pixel formats, or NULL if unknown, array is terminanted by -1
} AVCodec;
这个数据结构中主要包括了CODEC的标识及各种操作函数,如decode 或encode等。这样FFPMEG提供一个统一的调用接口,具体调用哪种CODEC由CODEC标识和操作函数来决定。
一般CODEC的函数调用顺序包括:
avcodec_init
avcodec_register_all
avcodec_find_encoder/decoder
avcodec_open
avcodec_encode_video/encoder_video/ encode_audio/encoder_audio
avcodec_close
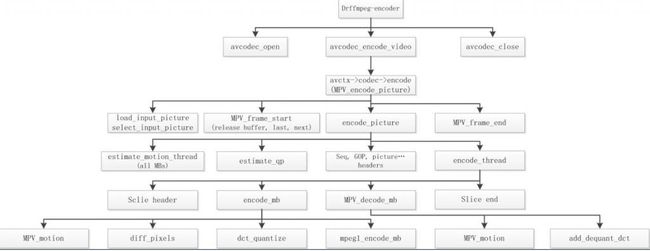
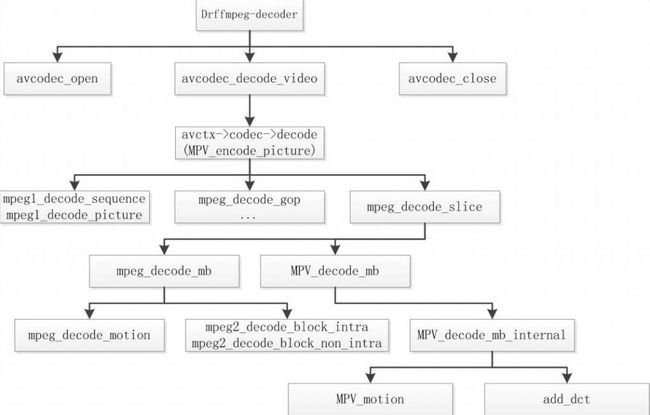
4.3 FFMPEG中的MPEG-2代码流程
4.3.1Encoder
4.3.2 Decoder
五H.264/AVC编码
5.1 编码原理图
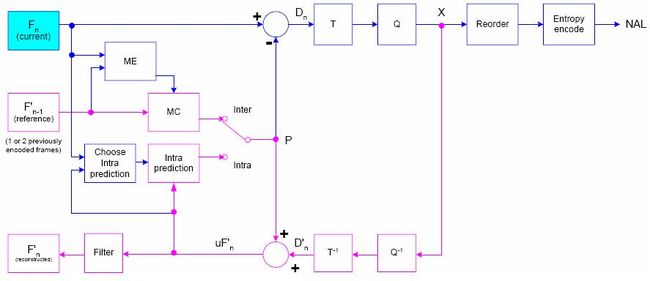
对比上图和基本原理图,我们会发现只是多了一个Fitler,那么H.264和MPEG-2编码之间的区别只是在于这一个Filter吗?
H.264和MPEG-2编码效率的主要提升在于以下几方面的主要区别:
n 帧内预测编码
n 多帧参考
n ME时宏块和ME时细化宏块,子宏块比较,¼像素ME
n 多帧参考
n 更高效的熵编码CAVLC和CABAC
n Deblock Filter
5.2 H.264的Profile
到目前为止,H.264共有四个级别的Profile:

各个Profile的特点在图中已经标明,这些不同的特点决定不同Profile的不同应用场合。
Baseline:一般用在可视电话,会议电视,无线通信等实时通讯情况下。
Main:运行隔行,主要用于数字电视与数字视频存储。
Extended:支持码流的切换,主要用于流媒体。
High:用在高清分辨率的场合。
由上图我们可知,各等级之间并不是子集的关系。
5.3 帧内预测编码
我们知道,在MPEG-2中,帧内编码就是直接对MB进行DCT变换,然后保存相关的参数。在H.264中,对帧内编码引入了预测编码,所谓帧内预测就是在对MB进行DCT变换前,先根据其周围已编码的MB或sub-MB进行预测,仅对预测后的残差和预测方式进行编码。
针对16x16和4x4,H.264提供了多种预测方式。
5.3.1 4x4帧内预测编码
4x4预测适用于细节较多的MB。
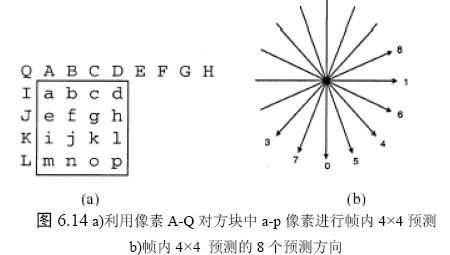
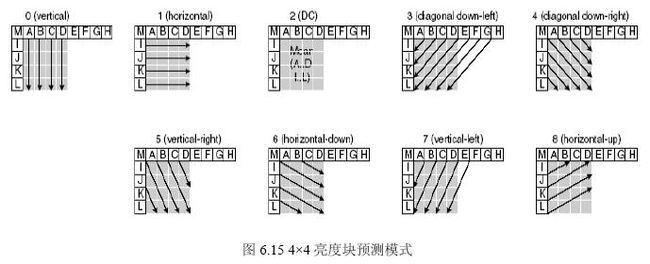
4x4预测编码共9种方式:


5.3.2 16x16帧内预测编码
16x16预测适合平坦区域的MB的。
5.3.3色度8x8帧内预测
每个帧内编码宏块的8×8 色度成分由已编码左上方色度像素预测而得,两种色度成分常用同一种预测模式。4 种预测模式类似于帧内16×16 预测的4 种预测模式,只是模式编号不同。其中DC(模式0)、水平(模式1)、垂直(模式2)、平面(模式3)。
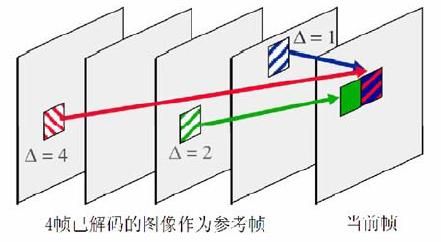
5.4 多帧参考
在H.264中,参考帧最多数目可以达到16个。H.264维护了两个List用于保存参考帧图像,List中图像基于POC进行排序,包括了前向参考和后向参考的图像。
5.5 帧间ME
5.5.1帧间ME的宏块及宏块分割
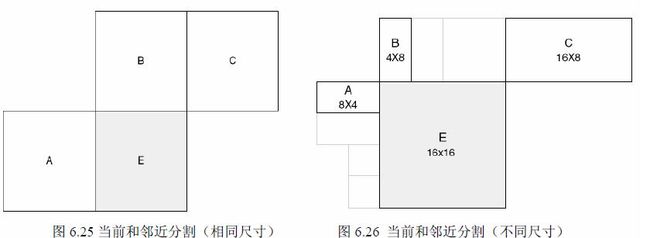
l 宏块分割
ME时16x16MB有以下几种分割方式:

色度块分割则为相应的亮度的一半。
下图是一个预测后的残差帧:
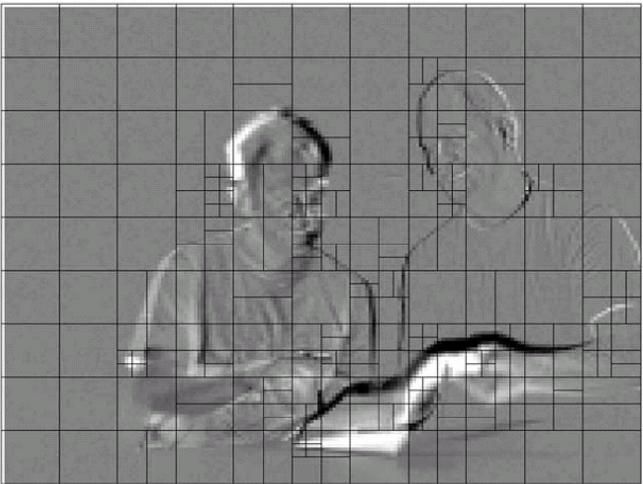
我们可以看到在平坦区域一般是16x16分割,在细节较多的区域采用较细的分割。
l MV预测
预测矢量MVp 基于已计算MV 和MVD(预测与当前的差异)并被编码和传送。MVp 则取决于运动补偿尺寸和邻近MV 的有无。
其中:
1) 传输分割不包括16×8 和8×16 时,MVp 为A、B、C 分割MV 的中值;
2) 16×8 分割,上面部分MVp 由B 预测,下面部分MVp 由A 预测;
3) 8×16 分割,左面部分MVp 由A 预测,右面部分MVp 由C 预测;
4) 跳跃宏块(skipped MB),同1)。
l 1/2,1/4像素搜索
1/2像素内插:
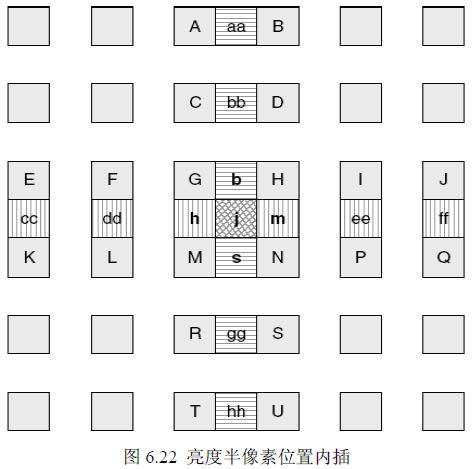
内插算法:
![]()
1/4内插:

1/4内插算法在1/2基础上通过线性进行。
![]()
5.6 熵编码
n CAVLC
n CABAC
5.7 Deblock filter
块效应的产生,是由于预测时基于方块进行的。在进行量化后,方块的边界有时变得非常明显。
n 解码完的一帧数据进行Deblocking
n Intra编码的MB没有进行Deblocking

去块效应的具体方法:

六X264代码结构
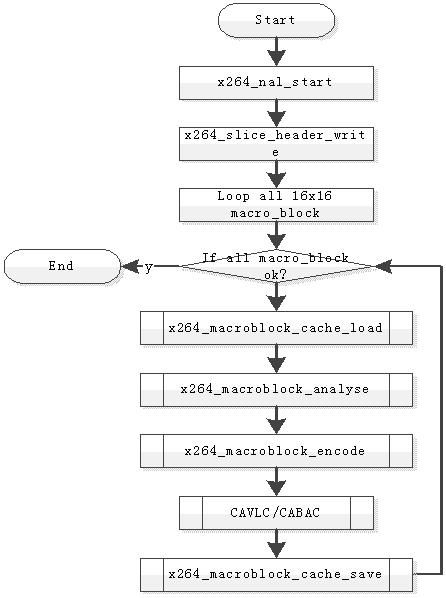
6.1 整体结构

6.2 Encoder 函数
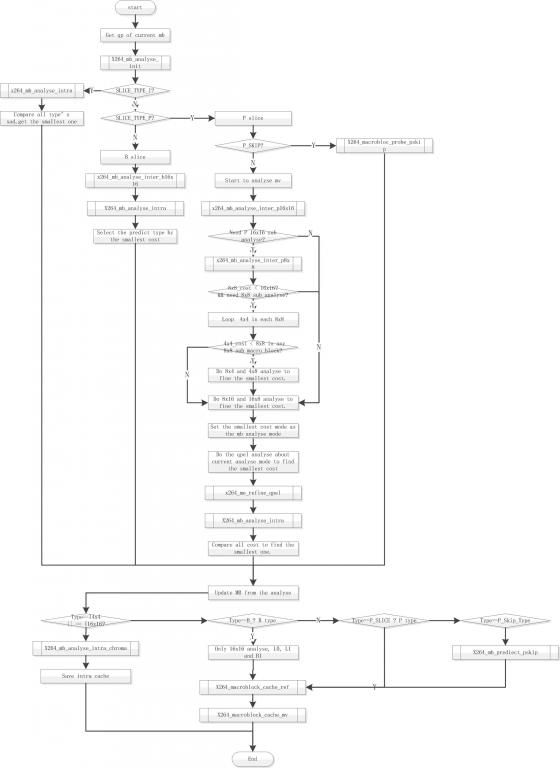
七实例解析
× 降低已经编码视频流的码率:仅修改量化系数,重新进行熵编码。
× Mpeg-2转码H.264:
1 直接使用Mpeg-2中的运动矢量。
2 在Mpeg-2运动矢量的基础上增加H.264的多帧搜索和子宏块搜索。
× 已编码视频叠加LOGO:
1 对LOGO区域和对LOGO边缘宏块进行重新编码。
2 对其它区域使用原来的编码参数。