计算机视觉技术最新进展【持续更新】
文章目录
- 2019年
- 2019/1/7 全景分割这一年,端到端之路
- 2018年12月
- 2018/12/15 解析深度学习:3 个经典的卷积神经网络案例分析
- 2018/12/13 Channel pruning for Accelerating Very Deep Neural Networks
- 2018/12/12 想要自学深度学习?不用GPU,浏览器就够了
- 2018/12/9 Inception 模型进化史:从 GoogLeNet 到 Inception-ResNet
- 2018/12/6 目标检测中的多尺度检测(Multi-Scale)
- 2018/12/4 NeurIPS 2018最佳论文出炉:UT陈天琦、华为上榜
- 2018/12/3 NeurIPS 2018 Tutorials、Oral内容一览
- 2018/12/2 小样本如何进行深度学习?
- 2018年11月
- 2018/11/30 Google:数据并行对神经网络训练用时的影响
- 2018/11/29 英伟达发布迁移学习工具包,现在可以申请早期试用
- 2018/11/28 机器学习顶会 NIPS 2018 Pre-Proceedings 论文列表
- 2018/11/27 计算机视觉入门教程系列—125页带你回顾CV发展脉络
- 2018/11/20 《机器学习100天》
- 2018/11/10 边界框,分割与目标坐标轴:论自动驾驶场景中识别对于3D场景流估计的重要性
- 2018/11/05 英伟达的“千人摩擦计划”
- 2018/10/23 预训练模型迁移学习
- 2018年10月
- 为中共中央政治局讲授新一代人工智能课程
- 2018年9月
- 欢迎打赏
2019年
2019/1/7 全景分割这一年,端到端之路
http://bbs.cvmart.net/articles/211/quan-jing-fen-ge-zhe-yi-nian-duan-dao-duan-zhi-lu?from=singlemessage
2018年12月
2018/12/15 解析深度学习:3 个经典的卷积神经网络案例分析
解析深度学习:3 个经典的卷积神经网络案例分析
原文来源于魏秀参博士的《解析深度学习:卷积神经网络原理与视觉实践》,本书由周志华老师作序推荐:“市面上深度学习书籍已不少,但专门针对卷积神经网络展开,侧重实践有不失论释者尚不多见。本书基本覆盖了卷积神经网络实践所有涉及环节,作者交代的若干新的技巧亦可一观,读者在实践中或有见益。”
2018/12/13 Channel pruning for Accelerating Very Deep Neural Networks
深度网络加速中的剪枝技术
本文提出了一种新的裁枝方法,用于加速深层卷积神经网络。对于一个训练好的模型,本文方法通过一个2步迭代的算法逐层裁枝,优化函数是LASSO回归和最小二乘法重建误差。进一步,本文将算法推广到多层的裁枝,和多分枝网络的裁枝。结果上,本文的方法减少了累积误差,且适用于各种网络结构。针对于VGG16网络,本文方法可以在加速5倍的条件下,准确率仅下降0.3%;针对ResNet,Xception网络加速2倍,准确率分别下降1.4%,1.0%
2018/12/12 想要自学深度学习?不用GPU,浏览器就够了
GitHub开源项目
2018/12/9 Inception 模型进化史:从 GoogLeNet 到 Inception-ResNet
Inception 模型进化史:从 GoogLeNet 到 Inception-ResNet
2018/12/6 目标检测中的多尺度检测(Multi-Scale)
从 YOLO,ssd 到 FPN,SNIPER,SSD 填坑贴和极大极小目标识别
2018/12/4 NeurIPS 2018最佳论文出炉:UT陈天琦、华为上榜
NeurIPS 2018最佳论文出炉:UT陈天琦、华为上榜
文章结尾有相关链接。
翻滚吧,水瓶君!全日本高中生机器人大赛,“超自然”力量制霸全场
2018/12/3 NeurIPS 2018 Tutorials、Oral内容一览
寒冷冬日NeurIPS热力来袭,Tutorials、Oral内容一览
Papers With Code:一文看尽深度学习这半年
Tutorial: Automatic Machine Learning
机器学习的成功最开始依赖于人类的经验,需要经验丰富的研究人员构建复杂的特征工程和选择合适的机器学习方法、架构并详细的调节各种超参数。但自动机器学习的出现将逐渐改变这一状况,通过机器学习和优化方法来提供一种无须专业知识就可以使用的模型。这一领域十分广泛,包含了超参数优化、神经网络搜索、元学习和迁移学习等方向。这一教程将概述目前前沿的方法和技术。
2018/12/2 小样本如何进行深度学习?
西北工夏勇教授这一份54页《医学影像小数据深度学习》
2018年11月
2018/11/30 Google:数据并行对神经网络训练用时的影响
Google:数据并行对神经网络训练用时的影响
个性化推荐系统,必须关注的五大研究热点
小数据福音!BERT在极小数据下带来显著提升的开源实现
本文介绍了如何实现 BERT 的文本多分类任务,并对比了 Baseline 以及不久前的 State-of-the-Art 模型 ULMFiT。实验结果可以看出 BERT 在此任务中,可以轻松打败先前的 SOTA。
仅17 KB、一万个权重的微型风格迁移网络!
现在有很多用来训练艺术风格迁移模型的现成工具,还有上千种开源实现。其中的多数工具利用 Johnson 等人在《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》中提出的网络架构的变体来实现快速、前馈的风格化。因此,多数迁移模型的大小是 7MB。对于你的应用来说,这个负担并非不可承受,但也并非无足轻重。
研究表明,神经网络的体积通常远远大于所需,数百万的权重中有很多并不重要。因此作者创造了一个体积大大缩小的可靠风格迁移模型:一个只有 11686 个训练权重的 17KB 神经网络。
超详细的Python基础知识实例!
2018/11/29 英伟达发布迁移学习工具包,现在可以申请早期试用
英伟达发布迁移学习工具包,现在可以申请早期试用
最近,英伟达发布了一个迁移学习工具包 (Transfer Learning Toolkit) 。这个基于Python的工具包,打包了许多预训练的模型:常用的ResNet-10,ResNet-18,ResNet-50,GoogLeNet,VGG-16和VGG-19等等都包含在内。
所谓迁移学习,是指预训练的模型已经学习到一些特征,我们要把它学到的东西,通过权重,迁移给另外一个神经网络。
PRCV2018 美图短视频实时分类挑战赛第一名解决方案介绍
2018/11/28 机器学习顶会 NIPS 2018 Pre-Proceedings 论文列表
机器学习顶会 NIPS 2018 Pre-Proceedings 论文列表
NeurIPS 2018 亮点选读:深度推理学习中的图网络与关系表征
推荐:论文:GloMo: Unsupervisedly Learned Relational Graphs (推荐)
迁移学习涉及的关键就是如何从数据中抽取学习到通用性很强的特征。
资源 | 李沐等人开源中文书《动手学深度学习》预览版上线
- 在线书地址:https://zh.diveintodeeplearning.org/index.html
- GitHub 项目:https://github.com/diveintodeeplearning/d2l-zh
2018/11/27 计算机视觉入门教程系列—125页带你回顾CV发展脉络
计算机视觉入门教程系列—125页带你回顾CV发展脉络
在深度学习中处理不均衡数据集
大部分的时候,深度学习项目中数据集的每个类别数量都会不一样,当我们真正关心的是少数的类别的时候,类别均衡技术就是真正的必须的了。本文介绍了处理不均衡数据集的几个方法,值得参考。
我们为什么想要数据是均衡的?
总的来说,我们的少数类别对准确率有很大贡献时,需要数据均衡。
方法:
1.当类别之间的样本数量差别很大的时候。我们可以使用权值均衡的方式来使我们的所有的类别对loss的贡献是相同的,而不用取费力的收集少数类别的样本了。
2.为了确保我们在少数类别上也能有很好的准确率,我们使用focal loss,给与少数类别的样本更高的权值。
3.过采样和欠采样
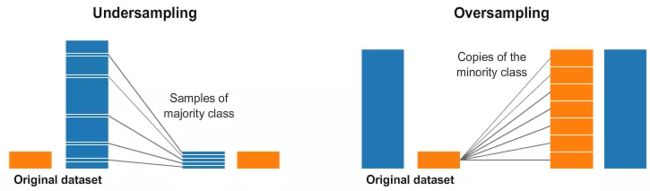
2018/11/20 《机器学习100天》
机器学习100天
深度学习图像识别的未来:机遇与挑战并存
2018/11/10 边界框,分割与目标坐标轴:论自动驾驶场景中识别对于3D场景流估计的重要性
边界框,分割与目标坐标轴:论自动驾驶场景中识别对于3D场景流估计的重要性
2018/11/05 英伟达的“千人摩擦计划”
英伟达的“千人摩擦计划”
2018/10/23 预训练模型迁移学习
预训练模型迁移学习
2018年10月
为中共中央政治局讲授新一代人工智能课程
2018/11/01 高文院士:从大数据时代来到人工智能时代,我们走了多远了?
2018/11/01 高文院士:国家新一代人工智能发展规划
2018/11/01 《习近平:推动我国新一代人工智能健康发展》
2017-07-01 潘云鹤院士:中国新一代人工智能
2018/11/01 国务院印发《新一代人工智能发展规划》
2018/11/01 《人工智能凉了? GitHub年度报告揭示真相 》
2018/10/18 This is AI
2018-10-17 林达华:AI产业化时代 学术研究的价值
2018年9月
2018/09/04 从统计到概率,入门者都能用Python试验的机器学习基础
概率要回答的是这样一个问题:「一个事件发生的几率是多少?」
从统计到概率:「如果我本来就可以计算理论概率,那我为什么还要用统计样本的数值特征,特别是均值和标准差?」
随着试验次数的增加,平均结果会越接近真实概率,即使个别试验本身并不完美。这种想法或数学上称为依概收敛就是「中心极限定理」的一个关键原则。
3σ 准则(也被称为经验法则或 68-95-99.7 法则),是我们观察到有多少数据落在平均值某一距离内的一种表达。
Z-score:「给定一个数据点,它离平均值有多少标准差?」
「一个值离平均值有多远?」==>「一个值与同一组观测值的平均值相差特定距离的可能性有多大?」
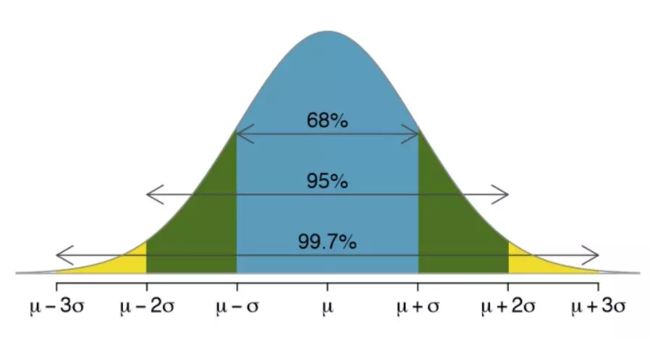
欢迎打赏
