如何让Kubernetes集群生产可用?

图片来源:veer
本文作者
Steven Wong (VMware)
Michael Gasch (VMware)
文章翻译
Karen Lee
文章来源
K8S技术社区
原文链接
https://kubernetes.io/blog/2018/08/03/out-of-the-clouds-onto-the-ground-how-to-make-kubernetes-production-grade-anywhere
如需转载,请联系原作者授权
“生产级”是什么意思?
安装是安全的
部署通过可重复和记录的过程进行管理
性能可预测且一致
可以安全地更新和更改配置
有日志和监控用来检测和诊断故障和资源短缺
考虑到可用资源(包括对资金、物理空间、电力等的限制),服务“足够高可用”。
恢复过程可用、有记录和经过测试,以便在发生故障时使用
简而言之,生产级意味着预测事故并以最小的痛苦和延迟为恢复做好准备。
本文针对虚拟机管理程序或裸机平台上的内部Kubernetes部署——与主要公有云的可扩展性相比,面临有限的支持资源。但是,如果预算约束限制了可使用的资源,其中一些建议在公有云中也可能有用。
单节点裸机Minikube部署可能既便宜又容易,但不是生产级。相反,你不太可能在零售店、分支机构或边缘地点获得Google的Borg体验,当然也不太可能需要。
即使在处理某些资源限制时,本文也提供了有关实现有价值的Kubernetes部署的一些指南。
01
Kubernetes集群中的关键组件
在深入了解细节之前,了解整体Kubernetes架构至关重要。
Kubernetes集群是基于控制平面和集群worker节点架构的高度分布式系统,如下所示。

通常,API服务器、Controller Manager和Scheduler组件共同位于控制平面(也称为Master)节点的多个实例中。Master节点通常也包括etcd,尽管有高可用性和大型集群场景要求在独立主机上运行etcd。组件可以作为容器运行,并且可选为由Kubernetes监督,即作为静态容器运行。
为了实现高可用性,使用了这些组件的冗余实例。冗余的重要性和要求程度各不相同。
02
从HA的角度看Kubernetes组件

这些组件面临的风险包括硬件故障、软件错误、错误更新、人为错误、网络中断以及导致资源耗尽的过载系统。冗余可以减轻许多这些危害的影响。此外,管理程序平台的资源调度和高可用性功能可以超越使用Linux操作系统、Kubernetes和单独的容器运行时可以实现的功能。
API Server使用负载均衡器之后的多个实例来实现扩展和可用性。负载均衡器是实现高可用性的关键组件。如果你没有负载均衡器,则可能有多个DNS API Server “A”记录。
kube-scheduler和kube-controller-manager参与leader选举过程,而不是使用负载均衡器。由于cloud-controller-manager用于选定的托管基础设施类型,并且这些具有实施变化,因此除了指示它们是控制平面组件之外,不做更多讨论。
在Kubernetes worker节点上运行的pod由kubelet代理管理。每个worker实例都运行kubelet代理和CRI兼容的容器运行时。Kubernetes本身旨在监控和恢复worker节点中断。但对于关键工作负载,可以使用虚拟机管理程序资源管理、工作负载隔离和可用性功能来增强可用性并使性能更具可预测性。
03
etcd
etcd是所有Kubernetes对象的持久存储。etcd集群的可用性和可恢复性应该是生产级Kubernetes部署中的首要考虑因素。
如果能负担得起,五节点etcd集群是最佳实践。为什么?因为你可以在一个上进行维护,但仍能容忍故障。即使只有一个虚拟机管理程序主机可用,三节点集群也是生产级服务的最低建议。除跨越多个可用区域的超大型安装外,不建议使用超过七个节点。
托管etcd集群节点的最低建议是2GB RAM和8GB SSD支持的磁盘。通常,8GB RAM和20GB磁盘就足够了。磁盘性能会影响节点恢复时间。有关详细信息,请参阅https://coreos.com/etcd/docs/latest/op-guide/hardware.html。
在特殊情况下考虑多个etcd集群
对于非常大的Kubernetes集群,请考虑为Kubernetes事件使用单独的etcd集群,以便事件风暴不会影响主要的Kubernetes API服务。如果你使用flannel网络,它会在etcd中保留配置,并且可能有不同的版本要求(而不是Kubernetes),这可能使etcd备份复杂化——考虑为flannel使用专用的etcd集群。
04
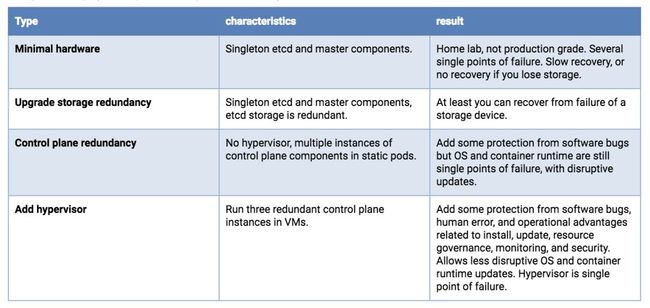
单主机部署
可用性风险包括硬件、软件和人员。如果你只有一台主机,那么使用冗余存储、纠错内存和双电源可以减少硬件故障。在物理主机上运行虚拟机管理程序将允许冗余软件组件的运维,并增加与部署、升级和资源消耗治理相关的运维优势,还在压力下具有可预测且可重复的性能。例如,即使你只能负担运行主服务的单例,也需要在与应用程序工作负载竞争时保护它们免受过载和资源耗尽的影响。与配置Linux调度器优先级、cgroup、Kubernetes标志等相比,虚拟机管理程序可以更有效,更易于管理。
如果主机上的资源允许,可以部署三个etcd VM。每个etcd VM应由不同的物理存储设备支持,或者它们应使用冗余(镜像、RAID等)来使用后备存储的单独分区。
如果你的单个主机有资源,则API服务器、调度器和控制器管理器的双冗余实例将是下一个升级。
单主机部署选项
05
双主机部署
两台主机的情况下,etcd的存储问题与单个主机相同,你需要冗余。你最好运行3个etcd实例。虽然可能有违直觉,但最好将所有etcd节点集中在一台主机上。通过在两台主机上进行2 + 1拆分,无法获得可靠性,因为丢失拥有多数etcd实例的节点会导致中断(无论多数是2还是3)。如果主机不相同,请将整个etcd集群放在最可靠的主机上。
建议运行冗余API Server、kube-scheduler和kube-controller-manager。这些应该在主机之间拆分,以最大程度地降低由于容器运行时、操作系统和硬件故障带来的风险。
在物理主机上运行虚拟机管理程序层将允许使用资源消耗治理来运维冗余软件组件,并且可以具有计划好的的维护运维优势。
双主机部署选项

三个(或更多)主机部署——进入不妥协的生产级服务,建议跨三台主机拆分etcd。单个硬件故障将降低应用程序工作负载容量,但不应导致彻底的服务中断。
对于非常大的集群,将需要更多的etcd实例。
运行虚拟机管理程序层可提供运维优势和更好的工作负载隔离。这超出了本文的范围,但在三个或更多主机级别,可以使用高级功能(集群冗余共享存储、具有动态负载均衡的资源治理、具有实时迁移或故障转移的自动化运行状况监控)。
三个(或更多)主机选项

06
Kubernetes配置设置
应保护master节点和worker节点免受过载和资源耗尽的影响。管理程序功能可用于隔离关键组件和预留资源。还有Kubernetes配置设置可以限制API调用率和每个节点的pod等内容。某些安装套件和商业发行版处理了此问题,但如果你正在执行自定义Kubernetes部署,可能会发现默认值不合适,尤其是在资源较少或集群较大的情况下。
控制平面的资源消耗将与pod的数量和pod流失率相关。非常大和非常小的集群将受益于kube-apiserver请求限制和内存的非默认设置。如果这些太高可能导致超出请求限制和内存不足的错误。
在worker节点上,应根据每个节点上合理的可支持工作负载密度配置Node Allocatable。可以创建命名空间以将worker节点集群细分为具有资源CPU和内存配额的多个虚拟集群。可以配置资源条件不足的kubelet处理。
07
安全
每个Kubernetes集群都有一个集群根Certificate Authority(CA)。需要生成并安装Controller Manager、API Server、Scheduler、kubelet客户端,kube-proxy和管理员证书。如果你使用安装工具或发行版,可能不需要自己动手。下面描述了手动过程。你应准备好在节点替换或扩展时重新安装证书。
由于Kubernetes完全由API驱动,因此控制和限制谁可以访问集群以及允许他们执行哪些操作至关重要。此文档(https://kubernetes.io/docs/tasks/administer-cluster/securing-a-cluster/)介绍了加密和身份验证选项。
Kubernetes应用程序工作负载基于容器镜像。你希望这些镜像的来源和内容值得信赖。这几乎总是意味着你得有本地容器镜像存储库。从公共互联网中提取镜像可能会带来可靠性和安全性问题。你应该选择一个支持镜像签名、安全扫描、推送和拉取镜像的访问控制以及活动记录的存储库。
必须有流程来支持应用主机固件、虚拟机管理程序、操作系统、Kubernetes和其他依赖项的更新。应该进行版本监控以支持审核。
建议:
加强控制平面组件上的安全设置(例如,锁定worker节点)
利用Pod Security Policies
考虑网络解决方案可用的NetworkPolicy集成,包括如何完成跟踪、监控和故障排除。
使用RBAC来推动授权决策和执行。
考虑物理安全性,尤其是在部署到可能无人值守的边缘或远程办公室位置时。包括存储加密,以限制被盗设备的暴露,并防止附加USB密钥等恶意设备。
保护Kubernetes纯文本云提供商凭证(访问密钥、令牌、密码等)。
Kubernetes秘密对象适用于保存少量敏感数据。这些都保留在etcd中。这些可以很容易地用于保存Kubernetes API的凭据,但有时工作负载或集群的扩展本身需要功能更全的解决方案。如果你需要的内容多于内置的秘密对象,HashiCorp Vault项目是一种流行的解决方案。
08
灾难恢复和备份
通过使用多个主机和VM来利用冗余有助于减少某些类别的中断,但是诸如全站点自然灾害、不良更新、被黑客入侵、软件错误或人为错误等情况仍可能导致中断。
生产部署的一个关键部分是做好恢复的准备。
值得注意的是,如果你需要在多个站点进行大规模复制部署,那么你在设计、记录和自动化恢复过程方面的一些投资可能是可重用的。
灾难恢复计划的要素包括备份(可能是复制)、替换、计划好的流程、可以执行流程的人员以及反复的培训。定期的测试练习和混沌工程原理可用于审核准备情况。
你的可用性要求可能要求你保留操作系统、Kubernetes组件和容器镜像的本地副本,以便即使在因特网中断期间也可以进行恢复。在“air-gapped”场景中部署替换主机和节点的能力还可以提供安全性和部署速度优势。
所有Kubernetes对象都存储在etcd上。定期备份etcd集群数据对于在灾难情况下(例如丢失所有主节点)恢复Kubernetes集群非常重要。
备份etcd集群可以使用etcd的内置快照机制完成,并将生成的文件复制到不同故障域中的存储中。快照文件包含所有Kubernetes状态和关键信息。为了保证敏感Kubernetes数据的安全,请加密快照文件。
使用基于磁盘卷的etcd快照恢复可能会出现问题(见#40027)。基于API的备份解决方案(如Ark)可以提供比etcd快照更细粒度的恢复,但更慢。你可以同时使用基于快照和基于API的备份,但至少应该使用一种形式的etcd备份。
请注意,某些Kubernetes扩展可能会在独立的etcd集群中、持久卷上或通过其他机制维持状态。如果此状态至关重要,则应该有备份和恢复计划。
一些关键状态存在于etcd之外。可以通过自动安装/更新工具管理证书、容器镜像以及其他与配置和运维相关的状态。即使可以重新生成这些项目,备份或复制也可以使故障发生后的恢复更快。考虑对以下项目进行备份:
证书和密钥对:CA、API Server、Apiserver-kubelet-client、ServiceAccount
signing、“Front proxy”、Front proxy client
关键DNS记录
IP /子网分配和预留
外部负载均衡器
kubeconfig文件
LDAP或其他身份验证详细信息
云提供商特定的帐户和配置数据
09
后续生产工作负载的注意事项
Anti-affinity规范可用于跨备份主机拆分集群服务,但此时仅在调度pod时才使用这些设置。这意味着Kubernetes可以重新启动集群应用程序的故障节点,但在故障恢复后没有本机机制来重新均衡。这是一个值得单独写篇文章的主题,但补充逻辑可能有助于在主机或工作节点恢复或扩展后实现最佳工作负载放置。 Pod Priority and Preemption功能可用于在由故障或突发工作负载导致资源短缺的情况下指定首选分类。
对于有状态服务,外部挂载卷安装是非集群服务(例如,典型SQL数据库)的标准Kubernetes建议。此时,由Kubernetes管理的这些外部卷的快照属于路线图功能请求的类别,可能与Container Storage Interface(CSI)集成一致。因此,执行此类服务的备份将涉及特定于应用程序的pod内活动(这超出了本文范围)。在等待更好的对快照和备份工作流的Kubernetes支持的同时,你可以在VM而不是容器中运行数据库服务,并将其暴露给你的Kubernetes工作负载。
如果资源允许,集群分布式有状态服务(如Cassandra)可以通过使用本地持久卷来跨主机分割而受益。这将需要部署多个Kubernetes worker节点(可能是虚拟机管理程序主机上的VM)以在单点故障下保留仲裁。
10
其他考虑
日志和指标(如果收集并持续保留)对诊断中断很有价值,但鉴于可用的技术种类繁多,本文不会讨论这个话题。如果因特网连接可用,则可能需要在中心位置外部保留日志和指标。
你的生产部署应该使用自动安装、配置和更新工具(如Ansible、BOSH、Chef、Juju、kubeadm、Puppet等)。手动过程将具有可重复性问题、劳动密集、容易出错且难以扩展。经过认证的发行版可能包含一个用于保留更新中配置设置的工具,但如果你自己安装和配置工具链,则保留、备份和恢复配置工件至关重要。考虑将部署组件和设置保存在Git等版本控制系统下。
11
故障恢复
记录恢复过程的Runbook应该进行测试并保持离线状态,甚至可能打印出来。当一名待命工作人员在星期五晚上凌晨2点被召唤时,可能不是即兴发挥的好时机。最好从预先计划好的、经过测试的清单中执行——由远程和现场人员共享访问。
12
最后的想法
在商业航空公司购买机票既方便又安全。但是当你前往一个跑道很短的偏远地区时,没有商用空客A320飞机可选。这并不意味着没法飞了,而是意味着必须做出一些妥协。
航空业的格言是,在单引擎飞机上,引擎故障意味着坠机。使用双引擎,至少可以让你在哪里坠机有更多选择。少数主机上的Kubernetes是相似的,如果你的商业用例证明了这一点,你可能会扩展到更大的混合大型和小型车辆的车队(如FedEx、亚马逊)。
那些设计生产级Kubernetes解决方案的人有很多选择和决定。本文无法提供所有答案,也无法了解你的具体优先事项。我们希望提供一个需要考虑的事项清单,以及一些有用的指导。一些选项被忽略了(如运行使用自托管而不是静态pod的Kubernetes组件)。如果有兴趣,我们可以在后续跟进中涵盖这些内容。此外,Kubernetes的更新很快,如果你在2019年之后发现这篇文章,某些内容可能会过时。
完
投稿啦!!!
精彩继续
CSDN作为国内专业的云计算服务平台,目前提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、机器学习、智能算法等相关云计算观点、技术、平台、实践、云产业咨询等服务。CSDN 公众号也一直坚持「与千万技术人共成长」的理念,深度解读行业内热门技术与场景应用,致力于让所有开发者保持敏锐的技术嗅觉、对行业趋势与技术获得更广阔的认知。
文章题材
首先你需要关注我们的公众号“CSDN云计算”,这样你会更准确了解我们需要的文章风格;
侧重于云计算领域相关的文章,可以是技术、运维、趋势等方面的务实内容;
原创,要求文章有鲜明观点和看法。
投稿须知
稿费:根据原创性、实用性和时效性等方面进行审核,通过的文章会发布在本微信平台。一经采用,我们将支付作者酬劳。酬劳可能不多,这代表的是一个心意,更多是因为爱好,是有识之士抒发胸怀的一种方式;
字数要求:稿件字数以2K-8K为宜,少于2K或多于8K都会一定程度降低阅读愉悦感;
投稿邮箱:[email protected]。或者添加微信表明来意,微信号:tangguoyemeng。请备注投稿+姓名+公司职位。
如果咱们的合作稳定又愉快,还可以签订合同长期合作哦!