Observers:让 ZooKeeper更具可伸缩性 | 时光机
戳蓝字“CSDN云计算”关注我们哦!

时光机:搭载这部时光机,带您回顾《程序员》大量优秀文章,重温经典技术干货,我们发现硬核技术永不过时,对于get要点、solve难题、提高自我,仍有非凡意义。
作者:Henry Robinson,Henry Robinson在纽约大学获得计算机科学学士学位,在剑桥大学获得语言。
译者:王旭
导读
时光机第02期,带您了解 ZooKeeper更具可伸缩性的优势。云计算时代,软件开发人员面临着越来越多分布式协作方面的问题。ZooKeeper是由Apache出品的一个分布式协作服务,新加入的Observer特性,进一步增强了ZooKeeper的可伸缩性。
ZooKeeper 是 由 Apache 出 品的一个分布式协作服务,用于实现锁和并发事务排队等协作原语。ZooKeeper 的一个优势是可伸缩性(Scalability)。五台或七台机器集群可以满足很多大型应用的需求。
最近我们给ZooKeeper增加了一个新的特性,进一步增强了它的可伸缩性—一种称为Observers的服务器。在这篇文章中,我想介绍一下添加这个特性的缘由,并解释这个服务器如何帮助我们的系统更具有可伸缩性。可伸缩性对不同的人意味着不同的事情,而在这里是说,如果我们的工作负载可以通过给系统分配更多的资源来分担,那么这个系统就是可伸缩的。一个不可伸缩的系统是无法通过增加资源来提升性能的,甚至会在工作负载增加时,性能急剧下降。
要了解Observers为何能影响ZooKeeper的可伸缩性,我们需要首先了解一下这个服务是如何工作的。宽泛地说,ZooKeeper 集群上的任何操作不是读操作就是写操作。ZooKeeper 确保了所有读和写操作在所有客户端看来具有完全相同的顺序,这样他们就不用再为操作的顺序而困惑了。
在提供强一致性保障的同时,ZooKeeper同时给出高可用性承诺,这可以被简单地解释为它可以在多台服务器失效的情况下仍然为客户端提供服务。ZooKeeper使用一个传统的手段来达到可用性——通过将数据读写分布到几台机器上来实现。这样一来如果其中一台机器失效了,其他的可以接管它的服务,而这一切对客户而言是不可见的。然而,一致性和可用性这两个属性是很难同时达到的。
目前,ZooKeeper必须确保集群中的每个副本都对读写操作是顺序性的。它通过一个一致性协议来达到这一目标。简单地说,这个协议由一个选定的领导者将新操作告诉其他服务器, 所有节点投票支持的方式反馈给领导节点。一旦领导节点收集到过半数的投票,它就认为投票已经获得了通过,并将进一步消息传送给服务器,以使它们可以继续工作,将操作提交到内存中。
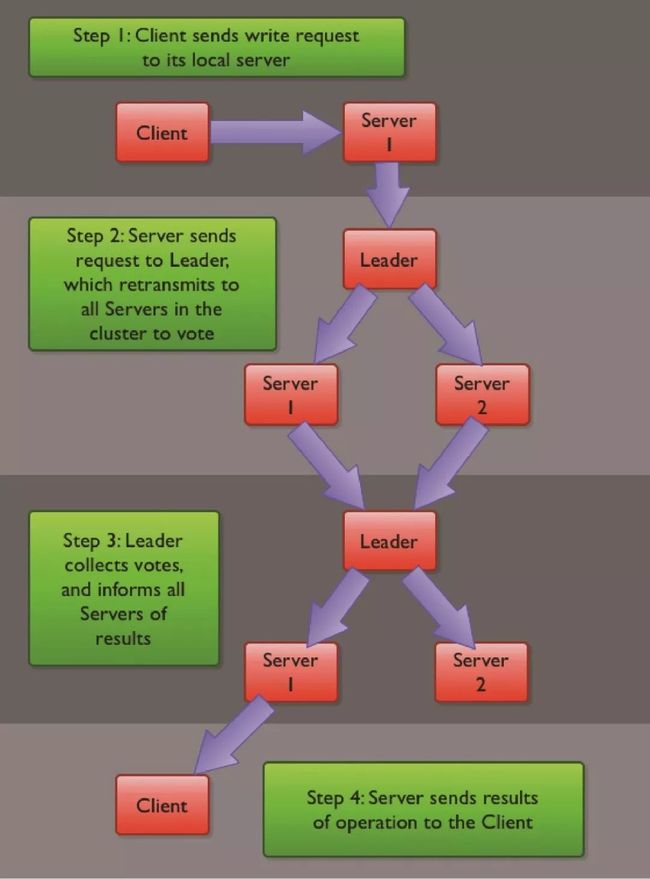
从始至终的数据流如图1所示。客户进程将一个值提交给它连接的服务器,服务器将消息转送给领导节点,并邮领导节点发起这个一致性协议,一旦最初的服务器从领导节点得到结果,它就可以返回给用户了。Observers的需求源于ZooKeeper服务器在上述协议中实际扮演了两个角色。它们从客户端接受连接与操作请求,之后对操作结果进行投票。这两个职能在 ZooKeeper集群扩展的时候彼此制约。如果我们希望增加ZooKeeper集群服务的客户数量(我们经常考虑到有上万个客户端的情况),那么我们必须增加服务器的数量,来支持这么多的客户端。
然而,从一致性协议的描述可以看到,增加服务器的数量增加了对协议的投票部分的压力。领导节点必须等待集群中过半数的服务器响应投票。于是,节点的增加使得部分计算机运行较慢,从而拖慢整个投票过程的可能性也随之提高,投票操作会随之下降。这正是我们在实际操作中看到的问题——随着ZooKeeper集群变大,投票操作的吞吐量会下降。所以,这让我们不得不在增加客户节点数量的期望和保持较好吞吐性能的期望间进行权衡。
为了打破这一耦合关系,我们引入了不参与投票的服务器,称为Observers。Observers可以接受客户端的连接,将写请求转发给领导节点。但是,领导节点不会要求Observers参加投票,所以,Observers不参与投票过程,而是和其他服务节点一起得到投票结果。
这个简单的扩展给ZooKeeper的可伸缩性带来了全新的景像。我们现在可以加入很多Observers节点,而无须担心严重影响写吞吐量。然而,规模伸缩并非无懈可击——协议中的一步(通知阶段)仍然与服务器的数量呈线性关系。
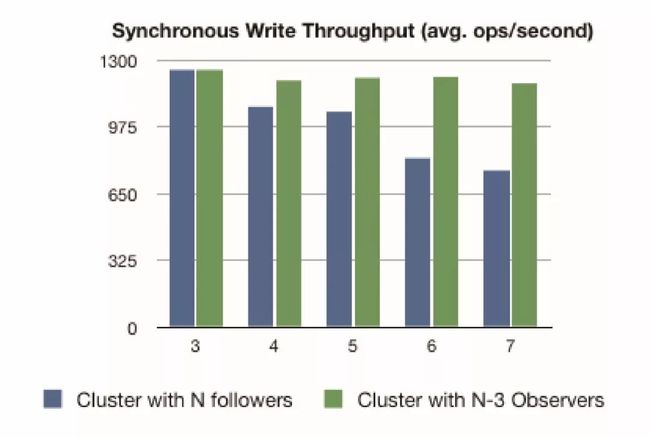
不过这里的串行开销非常低,我们可以认为在通知服务器阶段的开销无法成为主要瓶颈。图2显示了一个简单评测的结果,纵轴表示我能够从一个单一的客户端发出的每秒钟同步写操作的数量(一个调优的ZooKeeper可以得到更好的每秒钟操作数——这里我们更感兴趣的是相对值),横轴是ZooKeeper集群的尺寸。
蓝色部分表示每个服务器都是Voting服务器的情况,而绿色部分则只有三个是Voting服务器,其它都是Observers。测评结果显示我们扩充Observers,写性能几乎可以保持不变,但如果同时扩展Voting节点的数量的话,性能就会明显下降。Observers的有效性显而易见的,它们给集群带来了很多好处。
Observers同样提升读性能的可伸缩性
增加客户端的数量只是Observers的一个重要用例。作为一个优化,ZooKeeper 服务器可以直接读取它们的本地数据存储,而无须经过投票过程,这面临一定的“时光旅行”风险。可能在读到新值之后又读到老值,但这只在服务器故障时才会发生。事实上,在这种情况下客户端可以请求一个“sync”操作来保证下一个值是最新的。
因此,在大量读操作的工作负载下,Observers是个巨大的性能提升。写操作直接进入标准的投票路径,这样,与客户端可扩展性类似,提高投票服务器数量来承担读操作会影响写
性能。Observers允许我们将读性能和写性能分开。这适用于ZooKeeper的很多应用场景,大部分客户端很少写,但经常读。
Observers提供了广域网能力
Observers对于跨广域网连接的客户端来说是很好的候选方案。这有三个原因:首先,为了获得很好的读性能,有必要让客户端离服务器尽量近,这样往返时延不会太高。然而,
将ZooKeeper集群分散到两个集群是非常不可取的设计,因为良好配置的ZooKeeper 应该让投票服务器间用低时延连接互联——否则我们将会遇到上面提到的低反应速度的问题。
其次,Observers可以被部署在需要访问ZooKeeper的任意数据中心中。这样,投票协议不会受到数据中心间链路的高时延的影响,性能得到提升。投票过程中Observers和领导节点间的消息远少于投票服务器和领导节点间的消息。这有助于在远程数据中心高写负载的情况下降低带宽需求。
最后,由于Observers即使失效也不会影响到投票集群,这样如果数据中心间链路发生故障,也不会影响到服务本身的可用性。这种故障的发生概率要远高于一个数据中心机架间的连接的故障概率,所以不依赖于这种链路是个优点。
如何开始使用Observers
O b s e r v e r s 还 没 有 成 为 某 个ZooKeeper release 的一部分,所以要使用它,你需要从 Subversion trunk 获取源代码。
下面的内容提取自Observers用户手册,可以在源代码的d o c s /zooKeeperObservers.html 文件中看到。
如何使用Observers
注意,在ZOOKEEPER-578 解决之前,你必须在每个服务器的配置文件中设置electionAlg=0 。否则当你启动服务的时候会抛出一个异常。
原因:Observers并不参与领导节点的选举,它们依赖于投票 Followers 来获知领导的变动。目前,只有基本 选 举 算 法 启 动 一 个 线 程 来 响 应Observers确定当前领导的请求。其他JIRA 上的工作将会让其他所有的领导选举协议都支持这一功能。
设置ZooKeeper使用Observers非常简单,只需要在配置文件中有两处改动。首先是每个 Observer 的配置文件中都要有这么一行:
peerType=observer
这行让服务器作为一个 Observer 来工作。之后,在每个服务器配置文件中,你必须在服务器定义行,给每个 Observer加入observer。比如:
server.1:localhost:2181:3181:observer
这让每个其他服务器知道 server.1是一个 Observer,就不会期望它进行投票了。这就是要加入一个 Observer 的时候,所有你需要做的配置。现在可以将它作为一个正常的 Follower 来看待了。可以这样试试:
bin/zkCli.sh -server
localhost:2181
这里 localhost:2181 是 Observer 在每个配置文件中指定的主机名和端口号。你应该看到命令行提示了,这时就可以查询ZooKeeper服务了。
下一步工作
Observers特性还有很多工作要做。短期内,我们将致力于让Observers与ZooKeeper中的所有领导选举算法完全兼容 —— 我们希望这个可以在未来几天内完成。长期看,我们希望能研究一下进行性能优化,比如基于Observers的集群的批量和离线读取,来更好地利用Observers不像一般ZooKeeper服务器一样严格要求时延的好处。
我们希望Observers能进入明年年初的ZooKeeper3.3.0。此外我们会很高兴能听到你的反馈,不管 是 在 邮 件 列 表 里 还 是 直 接 发 送E-mail。ZooKeeper 长期招募贡献
者,我们有足够多的有趣的问题来解决。
![]()
福利
扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
VMware竟然出了一款防火墙
技术头条
你的 AI 老师已上岗
要成为年薪百万的技术大牛必经历这5个阶段, 收好这份超实用的技术进阶指南 | 技术头条
助力 Android 抗衡 iOS,华为发布方舟编译器!
程序员的黑砖窑,东南亚博彩骗局详解
售价910元!周志华等人英文新书《演化学习》出炉!